融合读者、相似度和位置信息的图书推荐系统模型研究*
2019-10-15郭苗苗吴了郭晨睿
郭苗苗,吴了,郭晨睿
融合读者、相似度和位置信息的图书推荐系统模型研究*
郭苗苗1,吴了1,郭晨睿2
(1.长沙学院,湖南 长沙 410022;2.洛阳师范学院,河南 洛阳 471934)
“新书推荐”“借阅排行榜”等图书推荐简单地将特定书目推荐给所有读者,忽略了读者之间的个体差异性。个性化图书推荐采用大数据和数据挖掘技术,预测读者的借阅行为,有针对性地向读者推荐图书,实现个性化服务。开发个性化图书推荐系统需要对影响图书推荐的各种因素进行数学建模。在现有技术的基础上,结合图书馆的应用背景,提出了一种融合读者、相似度和位置信息的图书推荐系统模型,该模型的建立有助于新一代图书推荐系统的开发。
图书推荐;系统模型;读者;位置信息
图书馆作为高校教学、科研的知识资源提供者,是在校大学生和教学科研人员获取知识的主要途径。但大多图书管理系统(ILAS、金盘等)一般不具备图书推荐功能,导致读者在面对海量信息资源时,如果采用传统的图书查找方法很难精准找到所需的图书;另一方面,当图书馆在新采购一批图书或数字资源后,感兴趣的读者并不能及时获取这一方面的信息,在一定程度上造成了图书资源的浪费。因此,图书馆需要综合考虑读者特性,利用数据挖掘技术,通过收集和分析读者的借阅习惯、喜好等信息,获取读者的阅读偏好,精准地向读者推荐图书,实现个性化推荐,提高图书的借阅率。个性化图书推荐系统结构如图1所示。
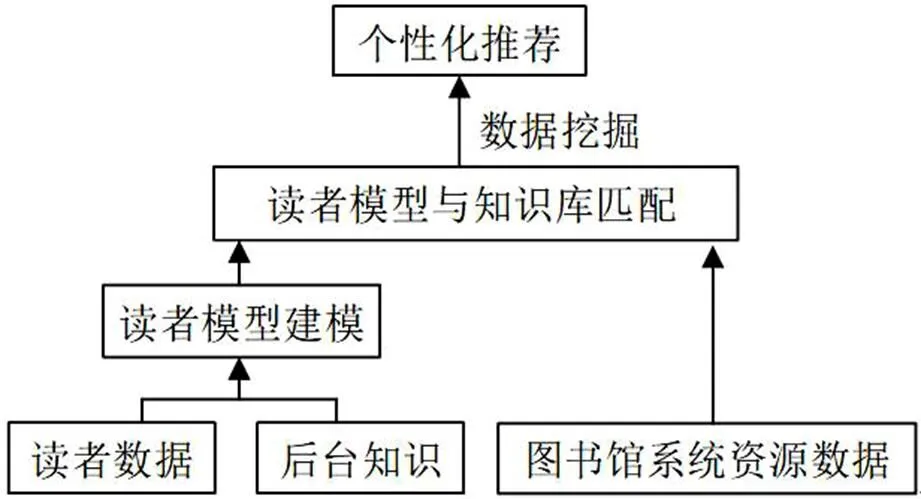
图1 个性化图书推荐系统结构框图
在进行个性化图书推荐时,需要在读者基本数据和后台知识的基础上建立读者模型,然后根据匹配规则对读者模型和图书馆的馆藏图书进行匹配,利用数据挖掘技术形成个性化推荐结果。由图1可以看出,在个性化图书推荐系统中,建立读者模型对推荐结果有较大的影响,因此,模型的建立至关重要。
1 常见的图书推荐算法
模型的建立离不开图书推荐算法。目前主要的图书推荐算法有:①基于内容的推荐算法,即根据读者过去的借阅习惯,为读者推荐与他过去借阅的图书内容相似的图书;②基于关联规则的推荐算法,即同一个读者借阅的不同图书可认为之间存在着某种关联,可以从借阅历史中搜索关联度最高的图书(图书集合)作为推荐的主要参考;③基于协同过滤的算法,即通过寻找当前读者借阅行为最相似的邻近读者,推荐邻近读者借阅的图书给当前读者[1-4]。
协同过滤算法是个性化推荐中较成熟的推荐算法之一。协同推荐算法一般分为基于用户的协同过滤推荐、基于模型的协同过滤推荐和基于项目的协同过滤推荐[5],其中“以用户为中心”的基于用户的协同过滤算法在推荐系统中获得了广泛的应用。传统的基于用户的协同过滤算法将两个用户之间的影响当作对称的影响,也就是说对于任意的两个读者,彼此的影响是相当量的。然而,在现实借阅中这种影响并不一定当量对称,例如教师可能会对新生读者产生较大的影响,但是新生读者对教师的影响却较小。因此,传统协同过滤算法还有改进空间。
协同过滤的另一个好处是可以通过聚合类似读者的行为来发现读者的隐含偏好[6]。假设有个读者和本图书,读者集合可以表示为={1,2,…,m},图书集合可以表示为={1,2,…,n},ij=1为读者i借阅过图书j,否则ij=0,则在推荐系统中,读者对图书的历史借阅数据就构成读者图书借阅矩阵∈mn。这样计算任意两位读者之间的相似性,就可以采用余弦相似度、Jacarrd相似度和Pearson相似度等方法。在上述3种方法中,当数据仅仅为0或1时,余弦相似度计算效果最佳。采用余弦相似度来计算读者之间的相似度,读者i与读者k之间的相似度ki计算如公式为:
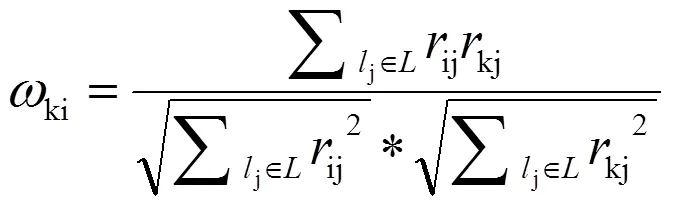
传统的基于用户(读者)的协同过滤算法计算读者i对图书j借阅的概率为:
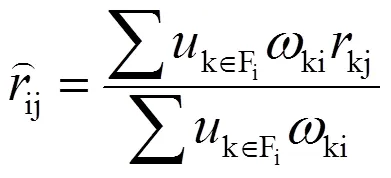
图书馆的藏书数量很大,一个普通高校的藏书就有上百万册,由于学科分布广泛,大量跨专业、跨学科以及新型学科和边缘学科图书的存在,造成传统的图书推荐系统模型的数据稀疏,降低了推荐质量。因此,本文综合考虑读者、相似度和位置信息,提出了一种改进的基于协同过滤算法的图书推荐系统模型。
2 融合读者、相似度和位置信息的图书推荐模型
要想提高推荐的准确性,使得推荐的书目尽可能地满足读者的借阅倾向,不仅仅要考虑读者的借阅历史,还要考虑读者的兴趣爱好等个体信息,本文在前人已有工作的基础上,给出一种融合读者、相似度和位置信息的图书推荐[7]。使用一种改进的基于读者的协同过滤算法——读者影响模型考虑并计算两个读者间的非对称影响,利用PageRank算法生成读者的全局影响因子;考虑读者间的专业和兴趣爱好等的相似度;利用图书、阅览桌等的位置信息,挖掘读者的实际借阅的位置特征,生成位置模型;将改进的读者影响、相似度影响和位置影响综合以建立图书推荐模型。
融合读者、相似度和位置信息的图书推荐系统结构如图2所示。
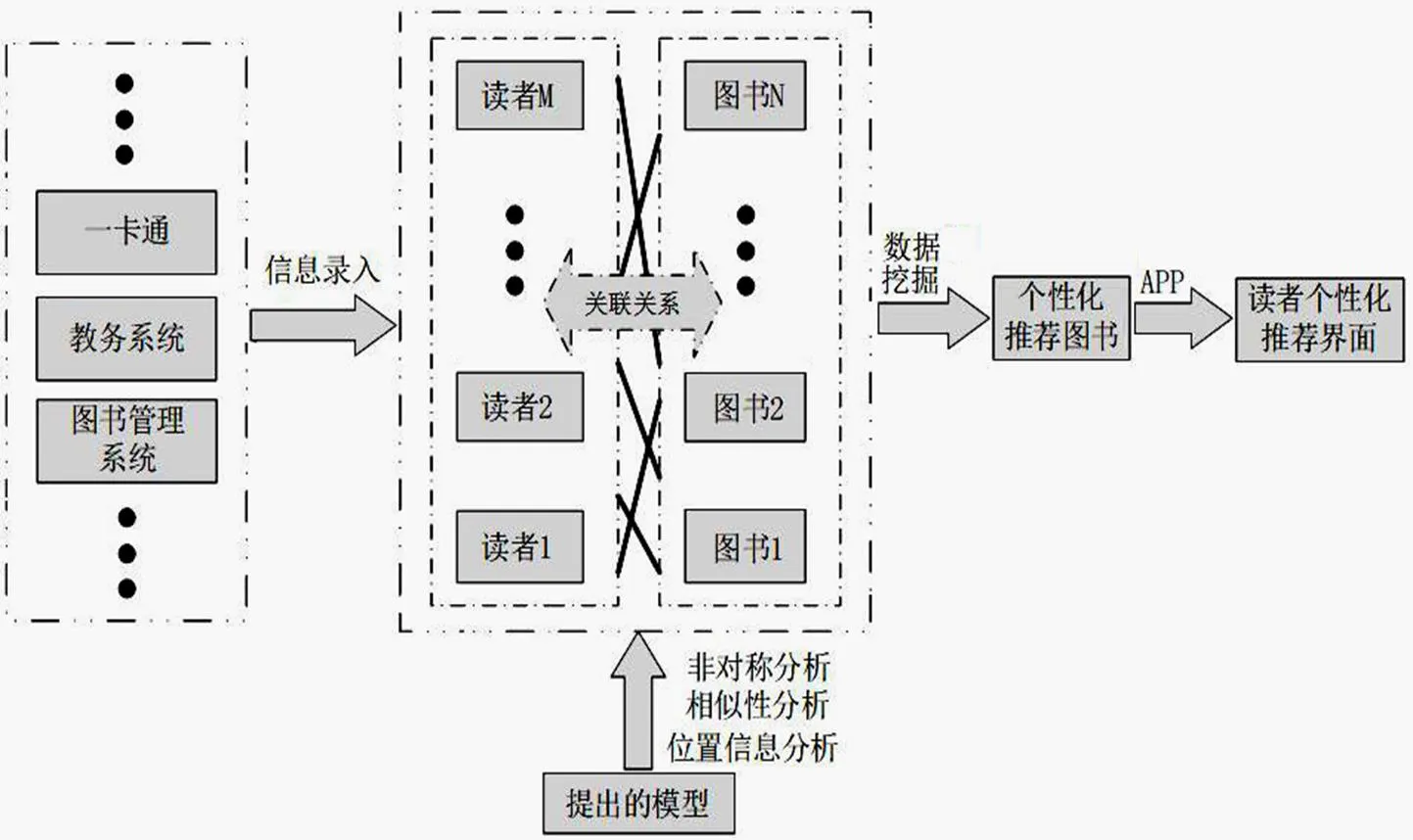
图2 融合读者、相似度和位置信息的图书推荐系统结构示意图
图2中最左边虚线框中的内容为每位读者录入的数据来源,包括一卡通、教务系统、图书管理系统的数据库等,反映了读者的专业、就业创业倾向、个人喜好、借阅历史等信息。第二个虚线框对读者间的非对称影响、相似度、借阅历史(阅览历史)的位置信息信息等进行分析,以提高图书推荐的精准度。
2.1 非对称读者影响分析
给定读者和图书的借阅关系矩阵:
=[ul]mn(2)
式(2)中:矩阵的第行、第列的ul为读者对图书的借阅次数(含续借);为读者的人数;为图书的数量。因为读者借阅图书的时长有限,当读者往往不能在一次借阅时间内完成图书的阅读与理解,会存在续借行为,在这里,图书的逾期未还行为视为一次续借。借阅(续借)次数越高,表明读者越喜欢图书,如果读者没有借阅过图书,则ul的值设置为0。
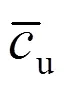
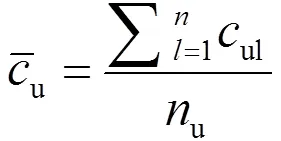
式(3)中:u为读者借阅过的图书的数量。
根据计算公式获得的布尔矩阵´构建非对称读者影响矩阵:
=[uv]mn(4)
式(4)中:uv为读者对读者的影响因子。
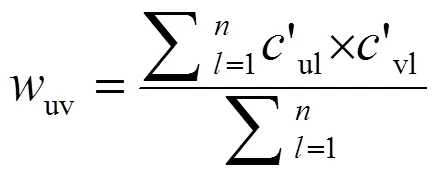
传统的基于读者的协同过滤算法中的读者关系矩阵是对称的,而本文中的读者影响矩阵是不对称的。
假设读者可以影响的其他读者越多,则读者在图书推荐系统中读者的全局重要性越高;如果有多个读者可以对读者产生影响,则读者更容易受到读者全局重要性越高的读者的影响。
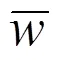

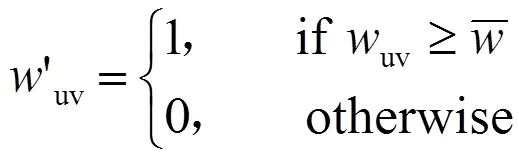
式(5)(6)中:()为一个函数,如果>0,则()=1;否则()=0。
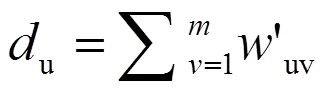
使用随机生成的值来初始化读者的PageRank值,并使用迭代模型得到最终的每位读者PageRank值。在每次迭代中,PageRank的值计算方法为:
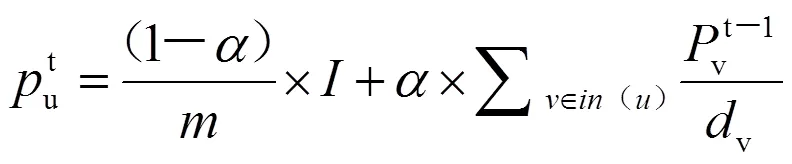
式(7)中:∈[0,1]为阻尼系数,表示其他读者对读者的贡献的缩放因子;()为可以影响读者的所有读者的集合。
在式(7)中,影响更多其他读者的读者,并受到更少其他读者影响的读者拥有更小的PageRank值,即具有越小PageRank值的读者越重要。
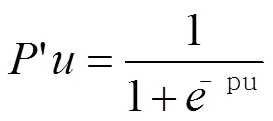
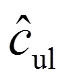
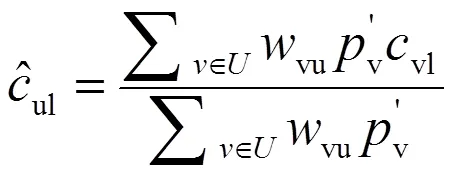
式(8)中:vu为读者对读者的影响值。
2.2 读者相似性的影响分析
读者的借阅行为可能会受到有其他读者的影响,例如共同考研、找工作的读者等。本模型使用专业、共同兴趣爱好、考研和创业就业倾向等来计算读者间的相似性。可以采用sigmoid函数将拥有相似专业、共同兴趣爱好或创业就业倾向转换为规范的相似性。同时,使用Jaccard相似度描述每对读者之间的相似性。然后使用超参数来平衡上述两种相似性。使用u表示与读者有关系的读者集,(,)表示读者和读者之间的相似度。读者∈u,则读者与读者之间的相似性定义如下:
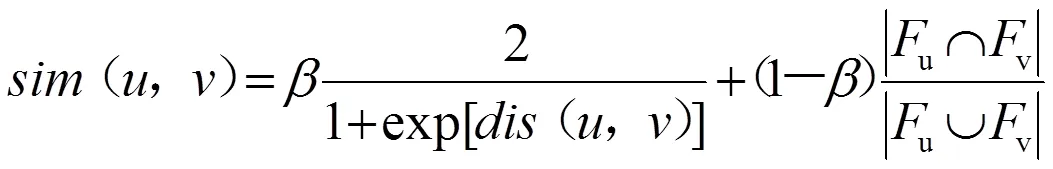
式(9)中:(,)为读者和读者之间的相似性;超参数∈[0,1]。基于上述读者之间的相似性,可以通过传统的基于读者的协同过滤算法预测读者借阅其未借阅过的图书的概率,计算公式为:
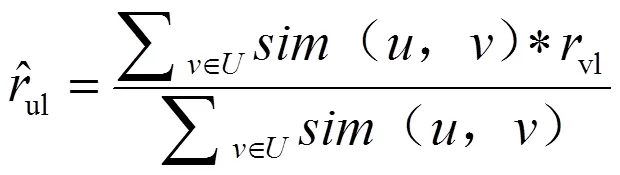
2.3 图书位置信息的影响分析
在图书馆读者更愿意借阅自己附近的感兴趣的图书。因此,为了将读者实时位置信息融入到图书推荐系统中,本文使用幂律分布来模拟读者从借阅一本图书到借阅同一个书库(书架)的另一本图书的距离函数作为读者可能借阅的概率,公式为:
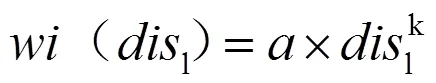
式(11)中:(l)为读者借阅不同于l的书架(书库)的图书的意愿;l为两本图书的距离;和为幂律函数的参数。
使用最大似然估计来计算两个参数和。具体方法是:在式(11)的两边取对数,即ln[(l)]=ln()+ln(l)。通过最小二乘法获得上的ln(l)线性函数。从而得到式(11)中的两个参数和。
假设:读者在借阅图书i,图书j是他将要借阅的候选图书,图书i与图书j之间的距离为l(i,j)。对读者的借阅概率进行建模,读者借阅图书j的概率与读者借阅在距离l(i,j)处的图书的意愿(l)成比例。
计算概率的公式为:

随着两本图书之间距离的增加,读者借阅的概率随之降低,表明读者不太可能借阅距离较远的图书。
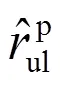
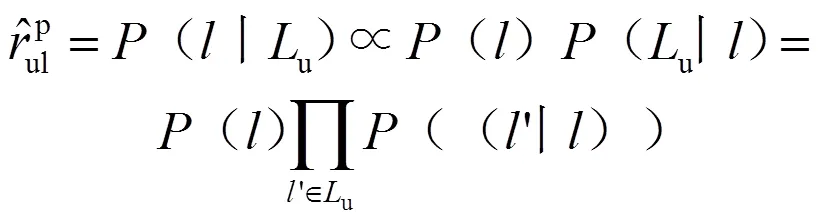

2.4 图书推荐模型建立
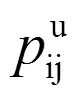
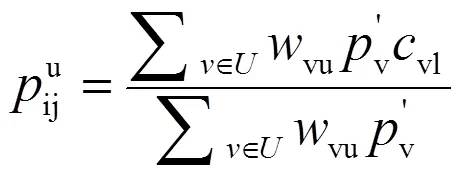
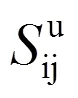
根据预测的借阅概率,可得到相应的分数,计算公式为:
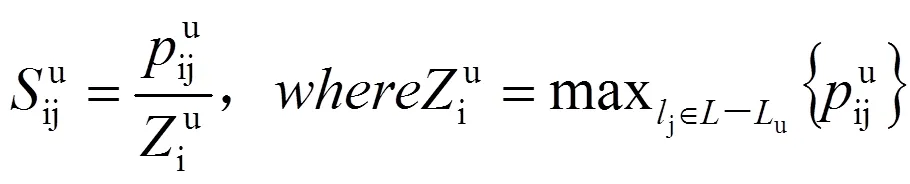
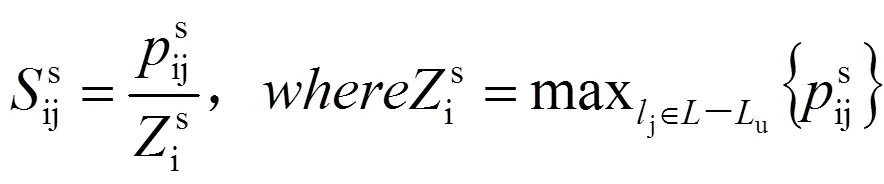
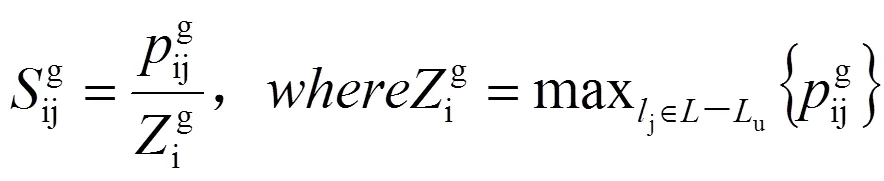
式(13)(14)(15)中:为所有图书集合;u为读者借阅过的图书集合。
在对读者进行图书推荐时,可以根据ij的值,向读者推荐可能感兴趣图书,不同于单单基于读者和单单基于内容的图书推荐系统,本文模型综合考虑了读者借阅历史、读者之间的相似性以及读者借阅产生的实时位置信息等,以向读者推荐其可能更加感兴趣的图书。
3 结束语
在海量的图书中,形成对读者的个性化推荐,需要综合考虑多种因素的影响,降低数据的稀疏性,本文综合考虑读者、相似度、位置信息等,提出了一种个性化图书推荐模型,提高推荐的准确度。图书馆馆员可以根据模型的推荐结果对藏书进行排架、倒架、下架等操作,为读者提供更好的服务,提高图书的利用率。
[1]黄立威,江碧涛,吕守业,等.基于深度学习的推荐系统研究综述[J].计算机学报,2018,41(7):1619-1647.
[2]孙鲁平,张丽君,汪平.网上个性化推荐研究述评与展望[J].外国经济与管理,2016,38(6):82-99.
[3]冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(8):720-734.
[4]李默,梁永全.基于标签和关联规则挖掘的图书组合推荐系统模型研究[J].计算机应用研究,2014,31(8):2390-2393.
[5]郭淑红,刘钊,徐玉梅.基于用户特征的高校图书馆个性化图书推荐研究[J].无线互联科技,2017(4):115-116.
[6]田磊,任国恒,王伟.基于聚类优化的协同过滤个性化图书推荐[J].图书馆学研究,2017(8):75-80.
[7]郭晨睿,李平.基于社交和地理信息的兴趣点推荐[J/OL].计算机工程与应用[2019-08-19].http://kns.cnki.net/ kcms/detail/11.2127.TP.20190705.1724.034.html.
TP391.3
A
10.15913/j.cnki.kjycx.2019.18.016
2095-6835(2019)18-0041-04
长沙学院人才引进项目和湖南省自然科学基金(编号:2019JJ50691)
郭苗苗(1987—),女,主要研究方向为图书馆现代化。吴了(1986—),男,主要研究方向为人工智能。郭晨睿(1992—),男,主要研究方向为数据挖掘。
〔编辑:张思楠〕
