基于机器学习的光学符号识别模型
2019-10-14杜菲霏郝欧亚王思桐
杜菲霏,郝欧亚,王思桐
(1.华北理工大学数学建模创新实验室,唐山 063210;2.华北理工大学电气工程学院,唐山 063210)
光学字符识别(Optical Character Recognition,OCR)是指通过电子设备通过字符识别方法将图片文字抽取为可编辑文本的过程。由于图像数据往往都包含噪声,像素模式之间的关系极其复杂,使用计算机完成OCR 的过程很困难。基于此,需要设计一种图像文字识别算法,以完成光学字符识别任务。
1 机器学习模型概述
用于分类的机器学习模型建立与求解过程,首先训练集进行预处理,选取合适的方法进行训练后得到模型,然后使用测试数据对模型进行评测,如果结果较好则证明该模型适合解决该类问题。有多元线性回归模型、LightGbm 模型和 KNN 模型。
2 模型的建立求解
2.1 数据处理
首先使用Weka 软件对数据初步进行统计分析,从统计分析数据可以看出,数据集中并未含有异常值与缺失值,大部分在数据在0-15之间,分布较均匀。
统计分析之后,对数据集中的英文字符进行字典编码处理,首先建立字符字典,例如字典{A:1,B:2,C:3,D:4,E:5},然后进行字符映射,分别将数据集中的字符A,B,C,D,E 使用数字1,2,3,4,5代替,其它字符以次类推。
2.2 特征工程
由于字符在图像中主要由像素构成,得出字符所在矩形区域的水平、竖直位置、矩形区域的宽度、高度对字符识别作用较小,故将其剔除,后期实验表明剔除这四组特征后的效果优于原始特征。
2.3 模型求解
(1)多元线性回归模型。将预处理后的样本数据代入模型,使用Python 中的sklearn.linear_model.LinearRegression 库求出权重矩阵,用于光学字符检测。
(2)LightGbm 模型。将预处理后的样本数据代入模型,设置boost 类型为gbdt',叶子数为 100,学习率为 0.01,迭代5000次,使用Python 中的lightgbm 库得出模型,用于光学字符检测。
(3)KNN 模型。将预处理后的样本数据代入模型,使Python 中的 sklearn.neighbors 库得出模型,用于光学字符检测。
3 模型检验
准确率(Accuracy)、查准率(Precision)、召回率(Recall)、F1值都是评价模型好坏的指标,只是评测的侧重点不同,且各指标间有一定的关联。
3.1 Accuracy 值
Accuracy 为预测值中所有正确值的数量/真实值的数量,定义如式(1)。

3.2 F1 值
Precision 是指模型的查准率,定义如式(2)。

Recall 是指模型的召回率,定义如式(3)。

由于Precision 与Recall 是相对的,不能通过单一的Precision或Recall 来评测模型的优劣,F1 值可以用来量化的权衡关系,定义如式(4)。

3.3 评测结果
取70%数据集作为训练集,其余30%数据集作为测试集,不同模型的在测试结的测试结果如图1所示。
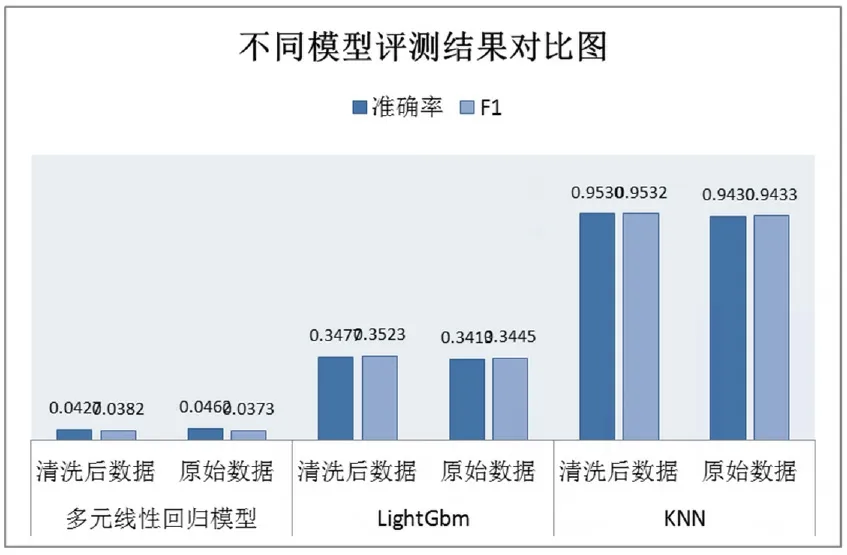
图1 模型评测结果对比图
由于单个模型数据清洗前后的差距较小,对比不明显,给出模型评测结果对比表。
4 结果分析
由图1可以看出,KNN 模型的准确率远远高于其它两个模型,在测试集的准确率达到95.3%,所以对于英文字符的识别,具有很好的效果;由于特征数目对于多元线性回归模型来说过多,所以效果很差;由于改数据集对于LightGbm 模型来说过小,所以效果较差。综上所述,KNN 模型最适合光学字符识别。
5 结束语
综上所述,KNN 是一种简单有效的机器学习分类算法,优点是训练代价较低、使用训练集的规模较小、更适合于多分类任务、准确率高、时间复杂度低,缺点是计算量较大、依赖于距离函数与K 值。KNN 模型不仅可以应用于光学字符识别,也可以应用于文本分类、用户产品推荐、疾病预测等方面。
