基于pix2pixHD 的行人图像生成
2019-10-14程平
程 平
(四川长虹电器股份有限公司,绵阳 621000)
1 pix2pixHD
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。通常每一种问题都使用特定的算法如:使用CNN 来解决图像转换问题时,要根据每个问题设定一个特定的损失函数来让CNN 优化。这些方法的本质其实都是从像素到像素的映射。“翻译”常用于语言之间的翻译,就比如中文和英文的之间的翻译。但是图像翻译的意思是以不同形式在图与图之间转换。比如,一张场景可以转换为RGB 全彩图,也可以转化成素描,也可以转化为灰度图。一张夜景图也可以转化为这个地方的日景图。本文在GAN 的基础上提出一个通用的方法:pix2pixHD 来解决行人图像翻译问题。该网络采用一种完全监督的方法,即利用完全配对的输入和输出图像训练模型,通过训练好的模型将输入的图像生成指定任务的目标图像。在训练阶段,使用成对的行人姿态mask 和行人图像训练pix2pixHD 网络,在测试阶段将行人姿态mask 输入到训练好的pix2pixHD 网络中,得到基于mask 姿态的行人图像。
2 相关工作
大量研究者已经利用对抗学习来做图像到图像翻译[9],其目标在于翻译一个输入图像从一个域到另一个域,给定输入-输出图像对来作为训练数据。相较于常使得图像模糊的L1损失,对于大多图像到图像的任务adversarial loss 已经变得流行起来。因为判别器能够学到一个新的可训练的损失函数并且自动地适应目标域中生成的和真实的图片之间的差异。从另一方面来说,图像到图像翻译的出现在某种程度上是占了卷积神经网络的天时,卷积神经网络所带来的对图像特征的高层特征的抽取使得风格和内容的分离成为了可能。pix2pix 网络[1]提出了艺术风格的神经网络算法可以将图像的内容和图像的自然风格分离和再合并,它不再输入随机噪声,而是输入用户给的图片,但该网络需要成对的训练图像。CycleGAN 网络[2]通过使用成对的生成器和判别器,添加一致性损失函数,先将源于上的图像转换到目标域中,再将转换后的图像还原为原始的图像。解决了在没有成对图像的基础上,将源域图像转化为目标域图像的问题。pix2pixHD 网络[3]采取了金字塔式的方法,先输出低分辨率的图片。将之前输出的低分辨率图片作为另一个网络的输入,然后生成分辨率更高的图片。本文将采用pix2pixHD 网络,实现根据行人姿态mask 到行人图像的生成。
3 pix2pixHD 网络结构

图1 pix2pixHD
3.1 生成器结构
如图1所示,生成器由G1和G2两部分组成,其中G2又被割裂成两个部分。G1和pix2pix 的生成器没有差别,就是一个端到端的U-Net 结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。首先在低分辨率图像上训练残差网络G1,然后,G2接在G1的后面,在高分辨率图像上这两个网络进行联合训练。
G1 为全局生成网络,G2 为局部提升网络。生成器由G={G1,G2}组成,全局生成器网络在一张1024×512 分辨率上进行操作,局部提升网络输出一个比之前(每张图片维度的2倍)的输出多4倍的一张图。在一个很高的分辨率上进行图像合成。其全局生成网络由三个部分组成:一个卷积前向到端部分,一系列的残差结构,和一个反卷积后向到端部分。一个分辨率为1024×512的语义标签图连续经过这三个部分生成一个1024×512的图像。
局部提升网络也由3个部分组成:一个卷积前向到端部分,一系列的残差结构和一个反卷积后向到端部分。G2的输入标签图的分辨率是2048×1024,和全局生成器网络不同,残差块的输出是两个特征图的对应元素之和:卷积前向到端部分的输出特征图和全局生成器网络中的最后一层特征图。这有助于整合G1的全局信息到G2。
3.2 判别器结构
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样。将判别器分别称为D1,D2,D3。具体来说,我们对真实图像和合成图像进行2倍和4倍的下采样来创造3个尺度的图像金字塔,判别器D1、D2和D3分别由这三个不同尺寸的不同真实和合成图像进行训练,虽然判别器的结构都相同,但是最粗糙的尺度的那个有最大的感受野。这有着更多的图像全局视角信息,能够引领生成器生成全局一致的图像。另一方面,最精细尺度的判别器鼓励生成器能够生成更加精细的细节。这也使得训练由粗到细的生成器更加容易。
3.3 损失函数
pix2pixHD 网络中使用了三个判别器,每个判别网络分的输入是不同尺度的图片,原始的GAN 变成了一个多任务的GAN,因此GAN loss 如式(1)所示:

pix2pixHD 也加入了特征匹配技术,将生成的样本和真实样本分别送入判别器D 网络中除了输出层以外的所有层的特征图都拿过来对特征做Element-wise loss。因此其特征匹配损失函数如式(2)所示:
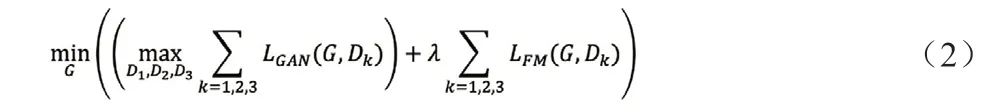
式中,k 表示第k 个D 网络;i 表示D 网络中的第i 层;s 表示待转换图片;x 表示转换目标图片;G(s)表示G 网络生成的目标图片。
加入特征匹配损失函数后,pix2pixHD 的损失函数如式(3)所示,其中λ 为特征匹配损失函数的权重:

4 实验
在网络的训练阶段,将行人姿态mask 输入到pix2pixHD 网络的生成器G 中用于生成行人图像。pix2pixHD 网络的判别器D用于判断行人图像为真实的行人图像还是生成的行人图像。通过pix2pixHD 网络的生成器和判别器进行联合训练,生成器和判别器不断博弈,优化。最终在测试阶段,只需输入行人姿态mask,pix2pixHD 生成器G 便能生成逼真的行人图像。由于Market1501等行人数据集中只有低分辨率的行人图像,没有高分辨率的行人图像,因此在实验过程中,我们的高分辨率图像和低分辨率图像是同一张低分辨率的行人图像。经过两个生成器后,我们可以看到生成的行人图像虽然分辨率不高,但是生成的行人图像的细节性更好。在参数设置中,我们将特征匹配损失函数的权重λ 设置为10。batchsize 设置为32。实验表明epoch 为104时,在测试阶段,pix2pixHD 生成的行人图像逼真,视觉效果最佳。图2为pix2pixHD 训练阶段的实验结果,图3为测试阶段的实验结果。

图2 pix2pixHD训练阶段的实验结果

图3 pix2pixHD测试阶段的实验结果
5 结束语
本文使用了pix2pixHD 网络实现了行人姿态mask 到行人图像的翻译。通过该网络我们可以生成具有目标姿态mask 的不同属性性质的行人图像。该网络实现了多尺度生成器-判别器结构,通过用了一种最新的生成损失adversarial loss 和特征匹配损失函数以用于提高行人细节的生成,从而使生成的行人视觉效果更加逼真。
