基于深度学习的桥梁裂缝检测算法研究
2019-10-14李良福马卫飞
李良福 马卫飞 李 丽 陆 铖
近年来,我国的公路桥梁建设取得了空前发展,特别是在《国家公路网规划2013 年–2030 年》和《十三五规划纲要》的推动下,中国的桥梁总数已稳居世界第一[1].随着桥梁的建成通车,桥梁的维护和管理成为保障桥梁安全运营的关键.桥梁的质量安全关系国计民生,关系千家万户.桥梁垮塌的原因往往都是由于没有进行科学及时的桥梁病害检测,因此,必须选择科学合理的方法对桥梁病害进行检查,定期对其健康状况进行评估[2].裂缝作为最主要的桥梁病害之一,严重影响着桥梁的安全运营,甚至会发生桥毁人亡的事故.因此,对桥梁裂缝进行有效的检测识别至关重要.随着计算机技术的高速发展,特别是图像处理、模式识别与计算机视觉技术的发展,基于图像的无损检测技术已经成为国内外桥梁缺陷检测的研究热点.近年来,为了从影像中准确、快速、高效地提取裂缝,国内外学者对此进行了广泛而深入的研究,并且取得了一些研究成果.Oh等针对路面裂缝的检测和提取,提出了一种迭代阈值分割的方法[3];Li 等为了从影像中准确地提取裂缝,提出了一种基于相邻差分直方图的裂缝分割算法[4];这类基于阈值分割的裂缝识别方法虽然简单易用,但是并没有考虑影像表面环境的变化以及光照、噪声、纹理对于裂缝识别的影响,因此,很难取得稳定的效果.针对此问题,Anders 等结合形态学处理和逻辑回归算法对裂缝进行检测,利用统计学分类方法滤除噪声,提高检测精度[5];Varadharajan等基于对路面纹理、颜色和局部信息的分析,对城市路面的裂缝进行了研究[6];Jahanshahi 等通过融合裂缝的深度信息,提出了一种新的裂缝检测和评估方法[7];Amhaz 等和Zou 等针对路面裂缝的对比度低、连续性差等特点,提出了一种基于最小代价路径搜索的路面裂缝检测算法[8−9];Oliveira 等构造了两个分类器,然后,用这两个分类器分别对路面裂缝进行检测和分类[10];Tien 等在综合考虑裂缝的亮度和连通性之后,提出了一种用于道路裂缝检测的算法,简称FFA(Free-form anisotropy)算法[11].除了上述这些主流的裂缝检测算法之外,还有很多其他的裂缝检测算法[12−19].但是,桥梁裂缝图像不同于传统的路面裂缝、岩石裂缝图像,它具有很多复杂的特性,比如背景纹理多样复杂、噪声种类繁多、分布无规律等.因此,传统的裂缝检测算法不能很好地对桥梁裂缝进行检测.
深度学习,特别是深度学习中的卷积神经网络(Convolutional neural network,CNN)最近在图像识别、视频识别、语音识别中取得了巨大成功[20−21].但是,经典的深度学习模型主要是针对大尺寸、整体目标的分类模型或者检测模型,比如AlexNet[22]、GoogLeNet[23−24]、Faster R-CNN 系列模型[25−26]等,例如采用Faster R-CNN 模型检测到的目标如图1(a)和图1(b)所示.如果将这些模型直接用于如图1(c)所示的桥梁裂缝,由于它是具有拓扑结构的线性目标,效果将不会理想,只能得到一个目标区域块,而得不到裂缝的具体位置,如图1(d)所示.因此,本文提出了一种基于深度学习的桥梁裂缝检测算法.该算法首先利用滑动窗口算法将桥梁裂缝图像切分为16 像素×16 像素大小的切片,并将所有的切片分为桥梁裂缝面元和桥梁背景面元.然后,根据对这些面元图像的分析,提出一种基于卷积神经网络(CNN)的DBCC(Deep bridge crack classify)分类模型,用于桥梁背景面元和桥梁裂缝面元的识别.最后,结合改进的窗口滑动算法在整幅桥梁裂缝图像中对桥梁裂缝进行检测.同时,为了满足桥梁裂缝检测算法实时处理的要求,采用图像金字塔和ROI 区域相结合的搜索策略对算法进行加速.大量实验数据表明,与传统算法相比,本文算法具有更好的识别率和更强的泛化能力.
1 基于人工扩增的数据集预处理方法
使用深度学习中的卷积神经网络(CNN)进行桥梁裂缝检测,需要大量的、带类别标签的桥梁裂缝图像作为训练集、验证集和测试集.但是,到目前为止,全球还没有公开的、带类别标签的、用于深度学习的桥梁裂缝图像数据集.如果直接用人工的方式去采集大量的桥梁裂缝图像,这将是个非常严峻的问题.本文在对采集来的2 000 张桥梁裂缝图像研究的基础之上,提出一种基于滑动窗口算法,专门用于桥梁裂缝图像数据集的人工扩增方法.

图1 经典深度学习模型和桥梁裂缝特点示意图Fig.1 Schematic diagram of classical depth learning model and bridge crack characteristics
该人工扩增方法首先将采集来的桥梁裂缝图像归一化为1 024×1 024 分辨率的桥梁裂缝图像.然后,使用W ×H固定大小的窗口在桥梁裂缝图像上不重叠地进行滑动.同时,把窗口覆盖下的桥梁裂缝图像的小切片作为一个ROI 感兴趣区域.其中,把不包含桥梁裂缝小切片的图像称为桥梁背景面元,把包含桥梁裂缝的小切片称为桥梁裂缝面元,具体过程如式(1)所示.
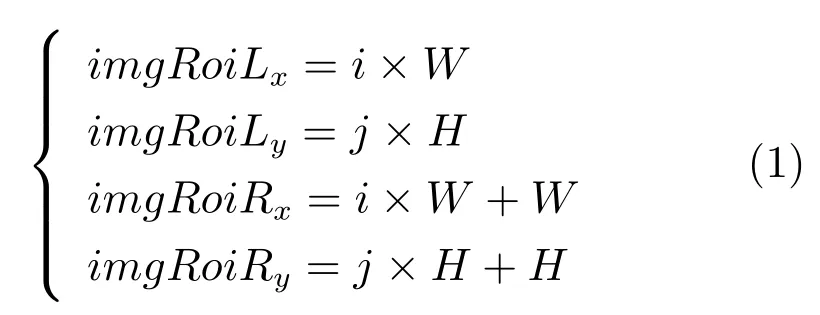
其中,W和H为滑动窗口的宽和高,并且取W=H=16 像素;坐标(imgRoiLx,imgRoiLy)为ROI 区域左上角的角点坐标,坐标(imgRoiRx,imgRoiRy)为ROI 区域的右下角角点坐标,i和j的取值范围分别为(0,1,2,···,srcImgw/W)和(0,1,2,···,srcImgh/H).srcImgw和srcImgh分别为被窗口滑动的桥梁裂缝图像的宽和高,令srcImgw=srcImgh=1 024 像素.最终,整个数据集人工扩增的过程如图2 所示.
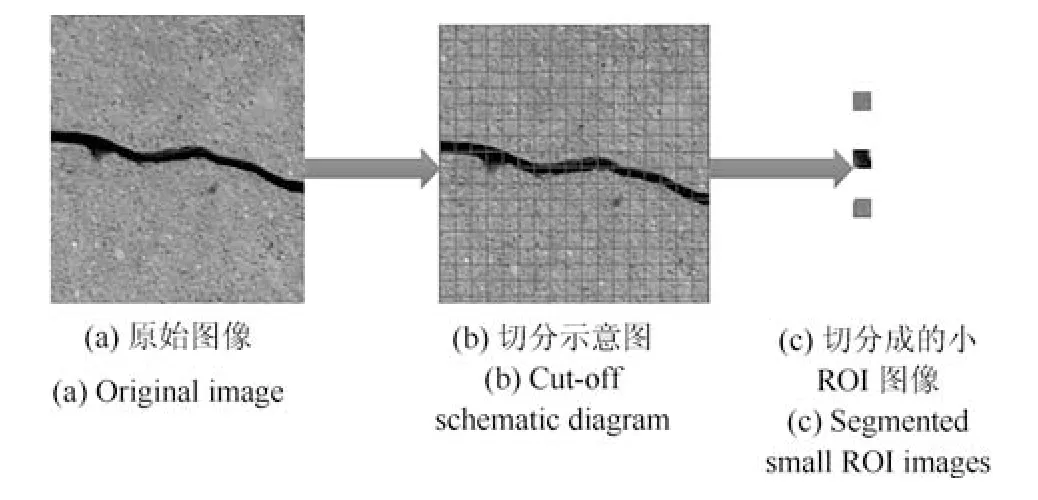
图2 桥梁裂缝面元数据集人工扩增方式示意图Fig.2 Schematic diagram of manual expansion of bridge crack surface metadata set
通过将采集来的2 000 张桥梁裂缝图像随机地划分为两个集合,每个集合包含1 000 张桥梁裂缝图像,并且将这两个集合分别命名为A集合和B集合.对A集合中的1 000 张桥梁裂缝图像使用上述的数据集人工扩增方式进行数据集扩增;然后,从这个巨大的、扩增之后的数据集合中手动地挑选出7 000 张桥梁裂缝面元图像构成桥梁裂缝面元数据集合,手动地挑选出48 000 张桥梁背景面元图像构成桥梁背景面元图像的数据集合.最后,将桥梁裂缝面元集合和桥梁背景面元集合拆分为训练集和验证集.其中,训练集包含6 000 张桥梁裂缝面元图像,44 000 张桥梁背景面元图像;验证集包含1 000 张桥梁裂缝面元图像和4 000 张桥梁背景面元图像.在训练集和验证集中,桥梁背景面元图像所占的比例大于桥梁裂缝面元图像所占的比例,之所以这样划分,是因为在一幅桥梁裂缝图像中,桥梁裂缝区域所占整幅图像的比例小于桥梁背景区域所占整幅图像的比例.训练集和验证集构建成功之后,分别对训练集和验证集中的桥梁裂缝面元图像和桥梁背景面元图像构建相应的类别标签.剩下B集合中的1 000张桥梁裂缝图像构成最终算法的测试集合.此外,本文为了推动桥梁裂缝自动检测与识别技术的进一步发展,对本文使用的所有数据集进行了公开.
2 基于CNN 深度学习的DBCC 分类模型及构建方法
2.1 DBCC 模型提出的原因分析
由图3 可知,桥梁裂缝图像具有背景纹理复杂多样、噪声种类繁多、分布无规律的特点,因此,主流的裂缝检测方法对于桥梁裂缝的检测,其效果不甚理想.由于深度学习中的卷积神经网络具有非常强大的特征提取能力和目标识别能力.因此,本文提出了一种基于CNN 深度学习的BDCC 分类模型,用于识别桥梁裂缝面元和桥梁背景面元.

图3 桥梁裂缝图像特点示意图Fig.3 Image characteristics of bridge cracks
数据集扩充之后,数据集中的桥梁裂缝面元和桥梁背景面元如图4 所示;其中桥梁裂缝面元有效地表达了桥梁裂缝的局部结构信息,而桥梁背景面元则表示除桥梁裂缝结构信息以外的其他任何信息和桥梁图像中有可能出现的噪声信息;这些面元的分辨率均为16 像素×16 像素的小图像.

图4 桥梁裂缝面元和背景面元示意图Fig.4 Schematic diagram of bridge crack surface and background surface
在深度学习中,对于小图像的识别通常使用CIFAR10[27]模型.但是,此CIFAR10 模型并不适用于桥梁裂缝的检测,其原因如下:1)CIFAR10模型是一种专门针对32 像素×32 像素分辨率图像的识别模型,并不能识别16 像素×16 像素分辨率的小图像.如果通过像拉普拉斯金字塔这样的图像处理技术强制将16 像素×16 像素分辨率的小图像拉伸为32 像素×32 像素分辨率的图像,然后,再用CIFAR10 模型进行识别,这样将会使得CIFAR10模型的识别率降低,达不到桥梁裂缝检测的要求.原因在于:把16 像素×16 像素分辨率的图像通过拉普拉斯金字塔向上重建为32 像素×32 像素分辨率图像的过程中,该图像会出现一定程度的失真.2)如果直接将CIFAR10 模型用于桥梁裂缝的检测,首先使用32 像素×32 像素大小的滑动窗口将桥梁裂缝图像切分为32 像素×32 像素大小的桥梁裂缝面元和桥梁背景面元;然后,使用这些图像训练一个基于CIFAR10 的分类识别模型;最后,基于这个模型去检测桥梁裂缝.那么,这将会导致最终在整幅桥梁图像上检测出来的桥梁裂缝十分不准确,具体检测结果如图5(a)图所示,图5(b)为基于DBCC 模型检测的结果.3)本文之所以提出DBCC 模型而不使用CIFAR10 模型,不仅因为基于DBCC 模型所检测出来的桥梁裂缝更加逼近真实的桥梁裂缝区域;而且也因为桥梁裂缝面元的面积越小,桥梁裂缝面元中所含有的噪声信息也越少.但是,桥梁裂缝面元的选取也不能无限小,桥梁裂缝面元太小,不仅不利于桥梁裂缝面元对于裂缝结构信息的表达,也会导致识别网络模型难以构建,识别网络模型的网络深度过低,这些最终都会严重降低模型的识别准确率,这也是本文将桥梁裂缝面元选定为16 像素×16 像素分辨率的依据.

图5 CIFAR10 模型和DBCC 模型检测结果的示意图Fig.5 Detection results of CIFAR10 and DBCC model
基于以上原因,提出一种专门用于桥梁裂缝这种具有拓扑结构的、线性目标的检测识别模型十分必要.本文在对CIFAR10、AlexNet、GoogLeNet等模型研究的基础之上,提出了一种针对16 像素×16 像素分辨率的桥梁裂缝面元和桥梁背景面元的分类识别模型DBCC 模型.
2.2 DBCC 模型的构建
对于DBCC 模型的具体构建,本文将主要从以下几个方面展开:DBCC 模型的全模型网络结构、使用更小的输入图像、使用更大的卷积核、加深网络深度、每层使用更多的卷积核、添加LRN 层、使用Dropout 层.这个顺序同时也是本文通过实验逐步构建DBCC 模型的顺序.
2.2.1 DBCC 全模型
DBCC 模型使用了4 层卷积层(C1∼C4),3层池化层(P1∼P3),2 层全连接层(FC1∼FC2),最后采用Softmax 函数(S)作为损失函数.在C1、C4、P2、P3、FC1 后面各加一个激活函数(RELU);同时,在第一卷积层后面添加LRN 层,FC1 后面添加Dropout 层.最后一层输出桥梁裂缝面元和桥梁背景面元这两类面元相应的识别概率值.卷积核数目从32 开始,每经过一次卷积层,卷积核的数目翻倍,直到256 为止.偏置项值初始化为0.1.DBCC 模型的整个网络结构示意图如图6 所示.其中In 表示输入的图像数据,C 表示卷积层,P 表示池化层,FC 表示全连接层,S 表示Softmax 函数,Out 表示输出,RELU 表示激活函数,LRN 表示局部响应值归一化层,D 表示Dropout 层.
2.2.2 使用更小的输入图像
由于桥梁裂缝是一种典型的线性目标,并且具有一定的拓扑结构.如果识别模型的输入图像选用32 像素×32 像素的分辨率,即桥梁裂缝面元的分辨率选用32 像素×32 像素的分辨率,那么最终由桥梁裂缝面元组成的桥梁裂缝将会十分不准确,如图5 所示.因此,本文选用了更小分辨率的输入图像作为桥梁裂缝面元和桥梁背景面元分类识别模型的输入图像,并且在研究CIFAR10 模型的基础之上,提出了DBCC-A 模型,具体的模型构建参数如表1和表2 中的第2 行所示.
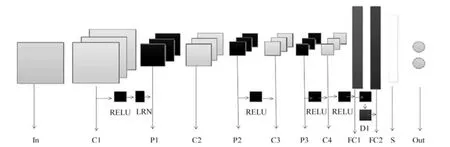
图6 DBCC 模型的网络结构示意图Fig.6 Network structure of DBCC model
2.2.3 使用更大的卷积核
DBCC-A 模型输入图像的分辨率和CIFAR10模型输入图像的分辨率相比,减小了一半.因此,DBCC-A 模型各层的卷积核尺寸也按一定的比例进行了减小.但是,提出DBCC-A 模型的目的主要是为了识别桥梁裂缝面元,而使用更大的卷积核不仅有利于提取桥梁裂缝面元中裂缝的结构信息,而且还有利于忽略掉和桥梁裂缝结构无关的其他噪声信息.因此,本文对DBCC-A 模型做了进一步改进,并且提出DBCC-B 模型.在DBCC-B 模型中,各卷积层使用了相对较大的、5 像素×5 像素分辨率的卷积核,并且为了保证识别模型的卷积层数不会随着卷积核分辨率的增大而减少,DBCC-B 模型为各卷积层的特征映射图添加了大小为了2 的扩展边距.其中DBCC-B 模型具体的构建参数如表1 和表2 中的第3 行参数所示.
2.2.4 加深网络深度
实验结果表明,网络的深度在一定条件下越深结果越好[23,28].因此,针对本文中16 像素×16 像素分辨率的桥梁裂缝面元和桥梁背景面元,为了尽可能地加深网络结构的深度,DBCC-B 模型为各卷积层的特征映射图添加了大小为2 的扩展边距,而且本文为了进一步加深网络结构的深度,对DBCCB 模型中池化层的池化窗口做了进一步的缩小.在此改进的基础之上,提出了DBCC-C 模型.其具体构建的参数如表1 和表2 中的第4 行参数所示.
2.2.5 每层使用更多的卷积核
在卷积层中,每一个卷积核都可以被看成一个特征提取器,卷积层中每一幅输出的特征映射图(Feature map)都可以被看成输入图像经过一个卷积核进行特征提取之后的结果,但是通过对各卷积层的输出结果进行可视化对比可知,并不是每一个卷积核都可以成功提取输入图像的特征,从而得到有效的特征表达(特征映射图).如图7(a)为DBCC模型第一卷积层的可视化结果,图7(b)为第4 卷积层前128 个特征映射图的可视化结果.因此,为了增强卷积层的特征表达能力,对输入图像的特征进行充分的提取,本文在DBCC-C 模型的各卷积层中使用了更多的卷积核,并且基于这一改进,提出了DBCC-D 模型.其具体构建的参数如表1 和表2 中的第5 行参数所示.
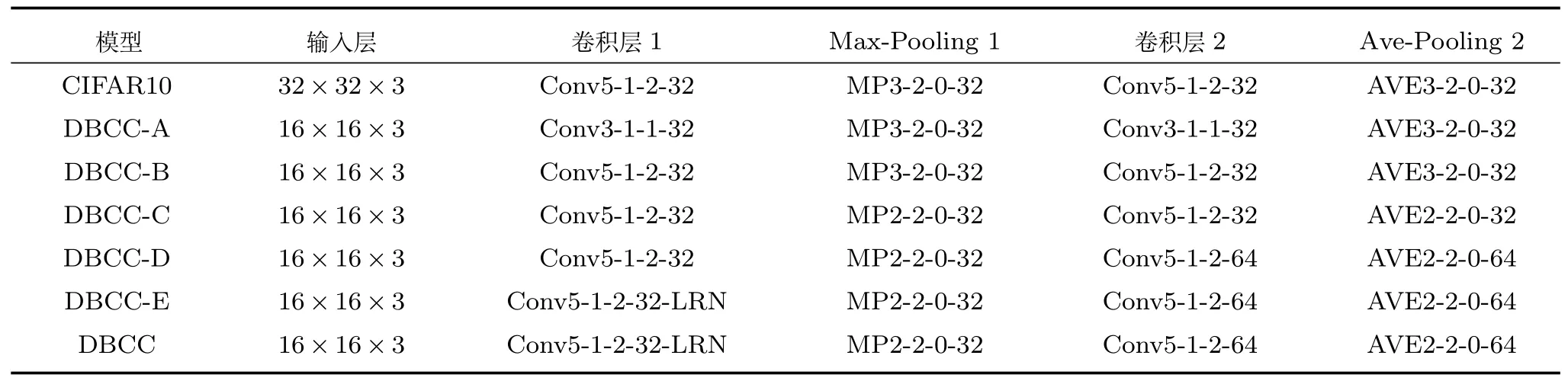
表1 DBCC 模型的输入层至第2 池化层各层的具体模型构建参数Table 1 Modeling parameters from the input layer to the second pool layer of the DBCC model
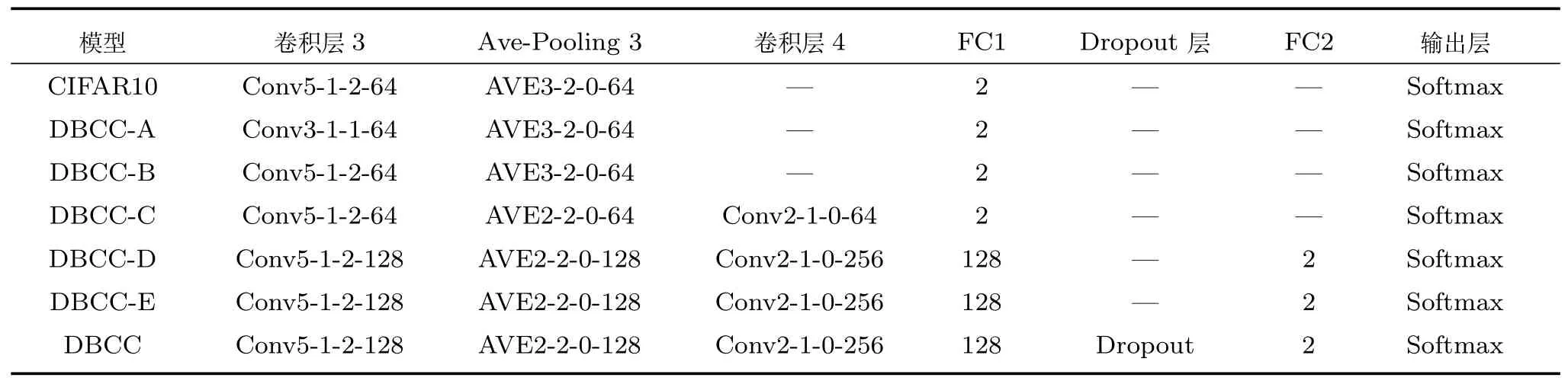
表2 DBCC 模型的第3 卷积层至输出层各层的具体模型构建参数Table 2 Modeling parameters from the third volume accumulated layer to the output layer of the DBCC model
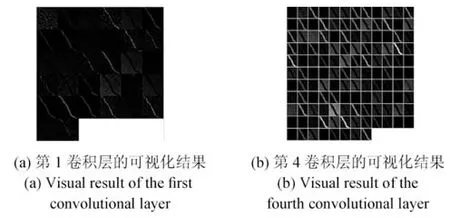
图7 卷积层可视化结果示意图Fig.7 Visualization results of convolution layer
2.2.6 添加局部响应值归一化层(LRN)
局部响应归一化层(Local response normalization,LRN)完成了一种“邻近抑制”操作,对局部输入区域进行了归一化.可以用于图像的明亮度矫正,而桥梁裂缝图像由于光照、阴影等因素,会出现图像亮度不均的问题,因此,本文在DBCC-D 模型的第1 卷积层之后添加了LRN 层,并且基于这一改进提出了DBCC-E 模型.其具体构建的参数如表1和表2 中的第6 行参数所示.
2.2.7 使用Dropout 层
Dropout[29]是指在训练模型时,随机地让网络中某些隐含层的节点暂时不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它们的权值保留了下来(暂时不更新),而在下次样本输入的时候,随机地进行选择,它们可能又可以工作.所以,每一次的样本输入,都相当于随机选取了一个不同的网络结构进行训练,但是这些不同的网络却共同训练出了共享的权值.因此,Dropout 可以看作是不同学习模型之间组合的一种替代方法,而使用不同的模型训练同一样本又是防止过拟合的一种方法,因此,对DBCC-E 模型添加Dropout 层,可以有效地防止过拟合.由于训练模型的数据集较小,因此,采用更大概率的Dropout 进行补偿,Dropout取值0.55,本文基于对DBCC-E 模型的这一改进,最终提出了DBCC 模型.其具体构建的参数如表1和表2 中的第7 行参数所示.
2.2.8 DBCC 模型的网络深度和卷积层数确定的依据
本文在构建DBCC 模型的过程中,除了依据以上的几点逐步构建出DBCC 模型之外,DBCC 模型中各卷积层和各池化层的输入特征映射图和输出特征映射图的分辨率还必须满足式(2)所表述的计算关系,这也是最终确定DBCC 模型网络深度和卷积层个数最主要的依据之一.
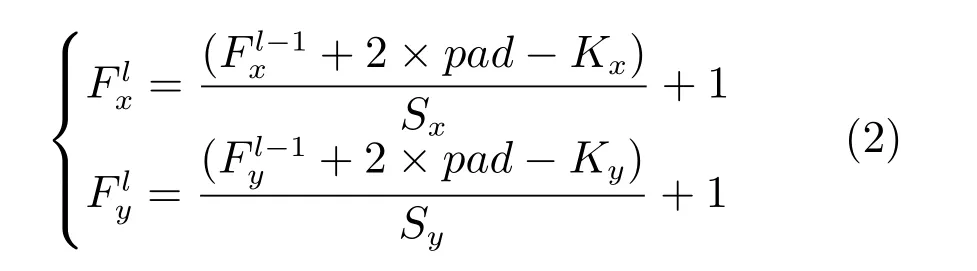
其中,(Fxl−1,Fyl−1)为前一卷积层或者池化层输入到本层的特征映射图;(Kx,Ky)为本层卷积层卷积核的大小或者池窗口的大小;Sx和Sy为卷积核或者池化窗口在特征映射图上滑动的步长;pad为给当前特征映射图添加的边界宽度;则为当前层的特征映射图经过卷积或者池化之后输出的特征映射图.
3 改进的窗口滑动算法
DBCC 深度学习模型实现了针对16 像素×16像素分辨率这样小尺寸的桥梁裂缝面元图像和桥梁背景面元图像的分类识别,但是如果想要最终检测出整幅桥梁裂缝图像中的桥梁裂缝,还需要结合本文改进的窗口滑动算法.本文改进的窗口滑动算法如图8 所示.
如果直接使用传统的窗口滑动算法和DBCC模型结合检测桥梁裂缝,则有可能检测出过多的桥梁噪声面元.其原因在于,DBCC 模型最后使用了一个Softmax 函数,分别输出在本次识别过程中桥梁背景面元和桥梁裂缝面元的概率Pb(x)和Pc(x),然后,对两者的概率进行比较,具体的计算过程如式(3)所示.其中f(x)为0,表示当前的图像为桥梁背景面元图像,f(x)为1,表示当前的图像为桥梁裂缝面元图像.
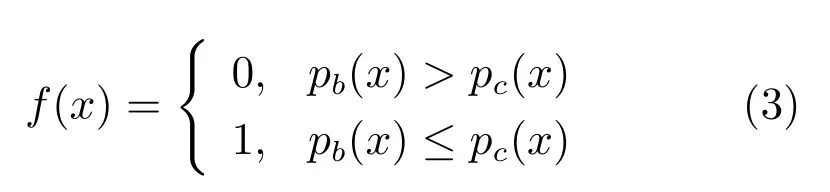
如果只根据Pb(x))≤Pc(x),就认为当前的桥梁面元图像为桥梁裂缝面元图像,那么在整幅桥梁裂缝图片识别的时候,有可能将某些桥梁噪音面元误识别为桥梁裂缝面元.因为很多桥梁噪音面元最终识别出来的概率也有可能大于桥梁背景面元的概率.针对这一问题,对窗口滑动算法进行了改进.具体做法是对式(3)进行了改进,改进后的公式如式(4)所示:

图8 改进的窗口滑动算法示意图Fig.8 Improved window sliding algorithm
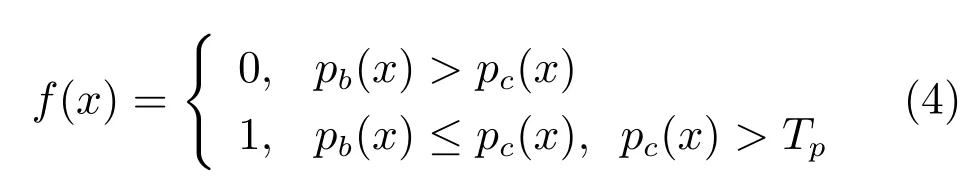
其中,Tp为一个概率区分阈值.根据实验,Tp一般可以取(0.90,0.99)之间的数.
4 算法的加速策略
为了降低算法的时间复杂度,加速算法的处理速度,满足桥梁裂缝检测实时处理的要求,必须采用多种措施来提高算法的执行效率.本文主要采用图像金字塔和ROI 区域相结合的策略对本文的桥梁裂缝检测的算法进行加速.由DBCC 模型结合改进的窗口滑动算法对桥梁裂缝的检测过程可知,算法的运行时间主要取决于检测目标图像的大小.针对这一问题,提出一种基于图像金字塔和ROI 区域相结合的加速策略.即首先针对要识别的桥梁裂缝图像构建图像金字塔,如图9 所示.然后,在低分辨率的图像上使用检测算法对桥梁裂缝进行检测,同时对识别出来的桥梁裂缝面元的横纵坐标进行排序,求出包含裂缝的矩形区域的左上角坐标和右下角坐标,然后将求出来的坐标代入式(5)确定在高分辨率图像上包含裂缝的矩形区域,并且将这一矩形区域设为ROI 区域.最后,使用检测算法对ROI 区域的桥梁裂缝图像进行检测.具体的算法加速策略可以参考图9.

图9 图像金字塔和ROI 加速策略示意图Fig.9 Schematic diagram of image pyramid and ROI acceleration strategy
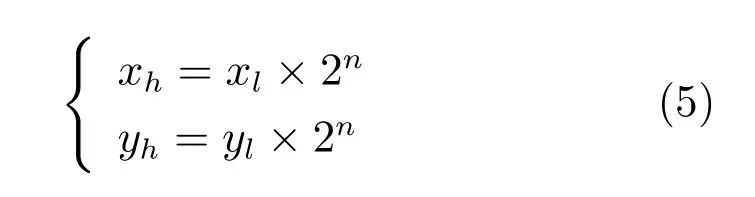
其中,坐标(xl,yl)为低分辨率图片上确定的位置坐标,(xh,yh)为高分辨率图片确定的位置坐标.n为桥梁裂缝图片通过高斯图像金字塔向下采样的次数.
5 基于桥梁裂缝面元的裂缝提取和定位算法
桥梁裂缝图像经过本文中上述算法的处理,其结果已经十分逼近桥梁裂缝的真实区域和面积,并且已经成功地将桥梁裂缝图像中的噪声隔离于桥梁裂缝之外,如图10 所示.但是,为了更加准确地提取桥梁裂缝和确定桥梁裂缝在桥梁图像中的位置,本文提出了一种基于桥梁裂缝面元的桥梁裂缝提取和定位算法.该算法可归纳为以下三个步骤:
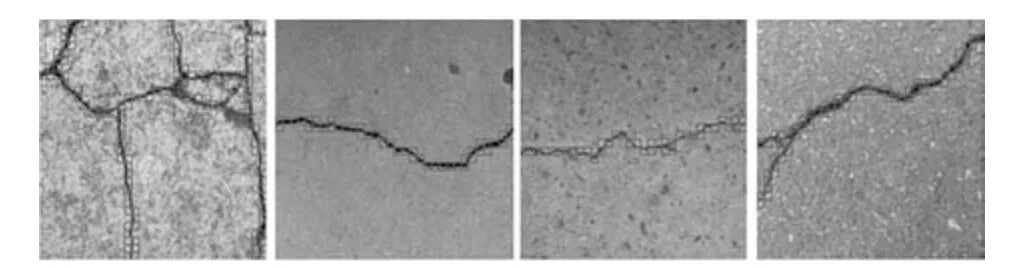
图10 DBCC 模型桥梁裂缝检测结果的示意图Fig.10 Schematic diagram of DBCC model bridge crack detection results
1)采用已经训练好的DBCC 模型和改进的窗口滑动算法对桥梁裂缝图像进行检测,识别出桥梁裂缝图像中所有的桥梁裂缝面元,并且将识别出来的桥梁裂缝面元使用相同分辨率的标识框标记出来,最终桥梁裂缝检测的结果如图11(b)所示;
2)使用Otsu 阈值化算法求解出桥梁裂缝图像全局的分割阈值T,并且根据这个求解出来的阈值T对每一个桥梁裂缝面元进行固定化阈值分割;由于现在的桥梁裂缝面元已经十分逼近桥梁裂缝,并且已经将干扰噪声排除在外,因此,基于桥梁裂缝面元和求解出来的阈值T可以十分准确地提取出桥梁裂缝面元中的桥梁裂缝,所有基于桥梁裂缝面元提取出的桥梁裂缝最终组成整幅图像的裂缝提取结果,如图11(c)所示;
3)本步对上一步骤中提取的桥梁裂缝中所有的像素点的X坐标和Y坐标分别进行排序,将最小的X坐标和Y坐标组成的坐标点作为裂缝区域的左上角点坐标,将最大的X坐标和Y坐标所组成的坐标点作为裂缝区域的右下角点坐标;最后,标记出由这两个坐标点所确定的矩形区域,这个区域即为桥梁裂缝的位置.
6 实验结果与分析
本文采用真实的桥梁裂缝图像数据进行试验,桥梁裂缝图像是由大疆无人机Phantom 4 pro 自带的CMOS 面阵相机采集的,具体的采集方法是让无人机在桥梁裂缝的附近进行悬停,然后通过无人机上的云台调整面阵相机的姿态,使得相机的镜头平行于桥梁裂缝的表面,并且要求相机的镜头距离桥梁裂缝的表面30 cm,调整好相机的姿态和距离后,让无人机从悬停状态转换为沿着裂缝方向平稳飞行,连续拍照.本文一共采集了2 000 张桥梁裂缝图像,并且将这2 000 张桥梁裂缝图像分为两个集合,将这两个集合分别称为A集合和B集合.其中,A集合中的1 000 张图像结合数据集人工扩增方法用于构建训练DBCC 模型的训练集、验证集;B集合中的1 000 图像用以构建本文算法的测试集,用于测试本文算法中的各项参数以及算法的性能,并且B集合中的1 000 张图像在实验结果和分析部分统一从原来1 024×1 024 分辨率的图像下采样为512×512分辨率的图像.本文算法的程序基于主流的深度学习开源框架Caffe 和计算机视觉开源库OpenCV,使用C/C++、python 语言开发;程序的运行环境为Ubuntu14.04,CPU 3.3 GHz,RAM 8 GB.
为了验证本文提出算法的有效性和准确性,本文分别设计了8 组对比实验,用以验证本文算法的各个方面.其中,第1 组实验用于测试数据集人工扩增方法对于DBCC 模型识别准确率的影响.第1 组实验的设计步骤分为3 步.首先,直接使用A集合中1 000 张桥梁裂缝图像、不经过数据集人工扩增方法构建DBCC 模型的训练集、验证集,用以训练DBCC 模型;然后,使用A集合中1 000 张图像,并使用数据集人工扩增方法对这1 000 图像进行扩增,使用扩增之后的数据集构建训练集、验证集,用以训练DBCC 模型.最后,再从B集合中随机地选取数幅桥梁裂缝图像并将其切分为16 像素×16 像素大小的小图像,随机地选取500 张桥梁裂缝面元图像用以测试训练好的DBCC 模型.测试的具体结果如表3 所示.
由第1 组实验结果可知,利用数据集人工扩增方法扩展之后的数据训练的DBCC 模型对于桥梁裂缝面元识别的准确率得到了极大提高;没有经过数据集扩增的数据训练的DBCC 模型识别准确率之所以低,主要是因为DBCC 模型没有得到充分的训练,出现了欠拟合现象.
第2 组实验用于对比CIFAR10 模型和DBCC模型对于桥梁裂缝最终检测结果的影响.第2 组实验包含3 个小实验.实验1,先使用32 像素×32 像素分辨率的滑动窗口扩增的数据集训练CIFAR10模型,再使用训练好的CIFAR10 模型对于B集合中的桥梁裂缝图像进行检测.实验2,使用DBCC模型对于B集合中的桥梁裂缝图像进行检测;实验3,先使用16 像素×16 像素分辨率的滑动窗口对桥梁裂缝图像进行滑动,然后使用拉普拉斯图像金字塔,将每一个16 像素×16 像素的小图像面元向上重建为32 像素×32 像素的小图像面元,最后将重建的图像面元送入CIFAR10 模型进行识别.三种方式的检测结果如图12 所示.
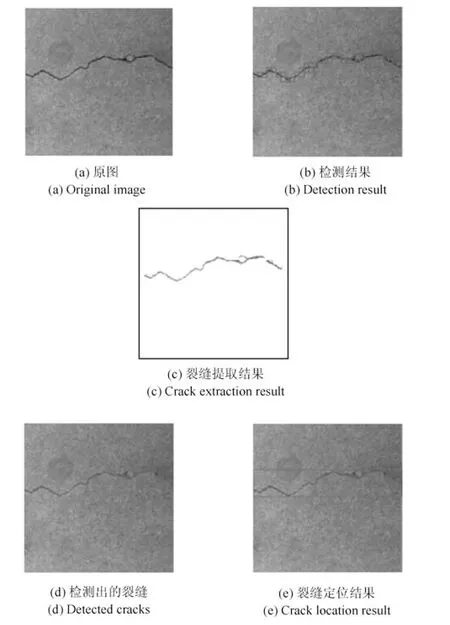
图11 基于桥梁裂缝面元的裂缝提取和定位算法流程示意图Fig.11 Flow chart of crack extraction and location algorithm based on bridge crack surface element
其中图12 的第1 行为实验1 的检测结果;第2 行为实验2 的检测结果;第3 行为实验3 的检测结果.由实验结果可知,基于DBCC 模型的桥梁裂缝检测结果十分逼近桥梁裂缝的真实区域,也能够较好地表达桥梁裂缝的拓扑结构;而直接使用CIFAR10 模型的检测结果,相对于DBCC 的检测结果来说,十分不准确.实验3 的结果说明,如果先用16 像素×16 的滑动窗口滑动桥梁裂缝,再将窗口覆盖下的小图像面元通过拉普拉斯金字塔这样的图像处理方法强制拉伸为适合CIFAR10 模型识别的面元,这将会导致CIFAR10 模型的识别率降低.因此,提出一个专门用于桥梁裂缝检测的深度学习模型是极其必要的.

表3 人工数据集扩增方法对于DBCC 模型识别准确率的影响Table 3 Effect of artificial data set amplification on recognition accuracy of DBCC model
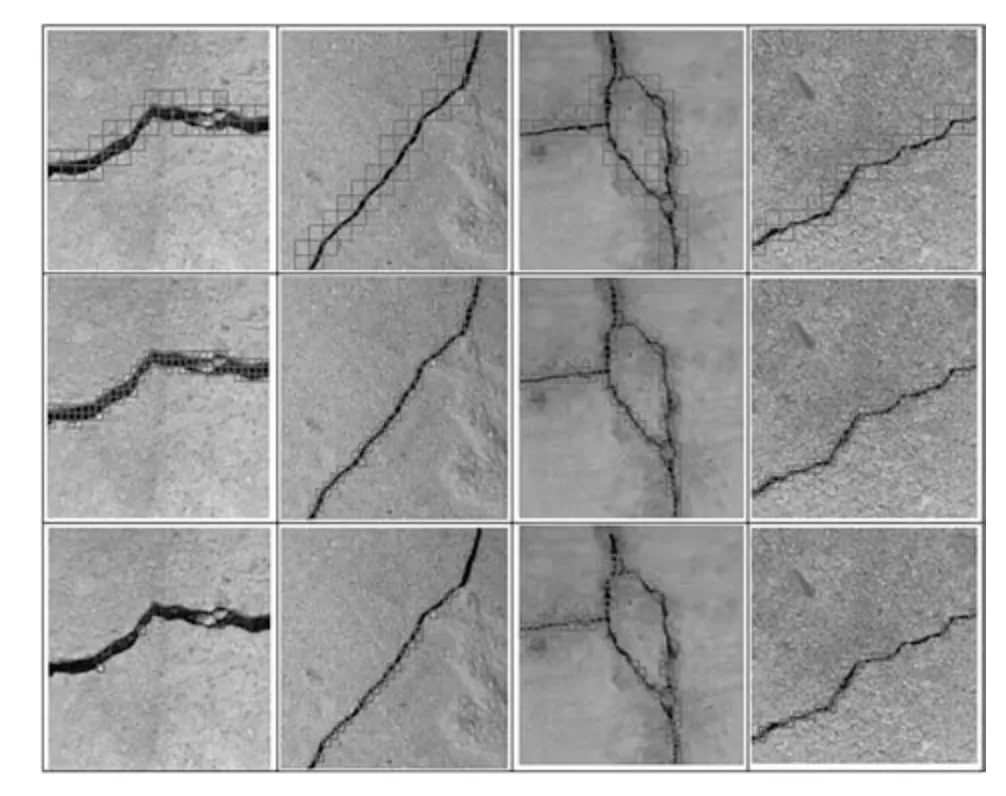
图12 CIFAR10 模型和DBCC 模型对于桥梁裂缝检测结果的对比Fig.12 Comparison between CIFAR10 model and DBCC model for bridge crack detection
第3 组实验用于测试CIFAR10、DBCCA、DBCC-B、DBCC-C、DBCC-D、DBCCE、DBCC 模型对于桥梁裂缝面元识别的准确率以及CIFAR10、DBCC 模型在不同尺寸滑动窗口下对于桥梁裂缝面元的识别率.其中各种模型的训练集使用的是A集合经过人工数据集扩增之后的训练集.测试集合是随机从B集合中选取数幅图像,使用表4 中每行模型对应的相应尺寸的滑动窗口切分,然后从切分的集合中随机地选取1 000 张桥梁裂缝面元用于测试各种模型.最终具体的实验和实验结果如表4 所示.
通过DBCC-A 模型和DBCC-B 模型的结果对比可知,使用更大的卷积核有利于识别模型准确率的提升;由DBCC-B 和DBCC-C 的结果对比可知,虽然识别模型的准确率确实有提升,但是提升较小,这主要是因为DBCC-C 相对于DBCC-B 模型的网络深度加深较小所致;由DBCC-C 和DBCC-D的结果对比可知,识别模型的准确率提升较大,这说明在一定条件下,增加每个卷积层的卷积核数量,有利于识别模型提取到更多有关桥梁裂缝的特征信息,这将会增加识别模型对于桥梁裂缝面元的识别能力;由DBCC-D 和DBCC-E 的结果对比可知,为第1 卷积层增加LRN 确实有利于准确率的提升;由DBCC-E 和DBCC 在同样尺寸滑动窗口下的识别率对比可知,为模型添加Dropout 层,同样也可以提升模型的识别准确率.由第0 行和第8行的结果可知,当滑动窗口尺寸取值过小时,无论是CIFAR10 模型还是DBCC 模型均不能对滑动窗口覆盖下的桥梁裂缝面元图像进行很好的识别,这主要是因为较小的滑动窗口覆盖下的桥梁裂缝面元图像包含的像素信息太少,已经不足以表达裂缝的结构信息,从而导致此情况下的识别率极其低下;由第1 行、第2 行、第9 行的结果对比可知,如果不构建新的模型,而是使用CIFAR10 模型直接对16 像素×16 像素大小滑动窗口覆盖下的桥梁裂缝面元图像进行识别,其识别率将会十分的不理想,这主要是因为在将16 像素×16 像素大小的桥梁裂缝面元图像通过拉普拉斯图像金字塔向上重建为32 像素×32 像素大小、适合CIFAR10 模型的识别图像时,会丢失桥梁裂缝的一部分结构信息所导致的;由第2 行、第9 行的对比结果可知,虽然两者识别准确率几乎持平,但是由图5 和图12 的对比可知,第2 行情况下,基于CIFAR10 模型的桥梁裂缝检测结果远不如第9 行情况下DBCC 模型的桥梁裂缝检测结果,而且由于第2 行对应的滑动窗口为32 像素×32 像素,这也就意味着最终的检测结果中将会包含更多的噪声,而基于第9 行DBCC模型的检测结果,由于是16 像素×16 像素大小的滑动窗口,这种情况下的检测结果不仅更加逼近真实的桥梁裂缝,而且对于噪声的排除和抑制能力更强,这说明本文提出的DBCC 模型在针对桥梁裂缝检测这一特定问题上的性能完全优于CIFAR10 模型,也进一步说明,针对桥梁裂缝检测,提出一种新的识别模型是十分重要的.
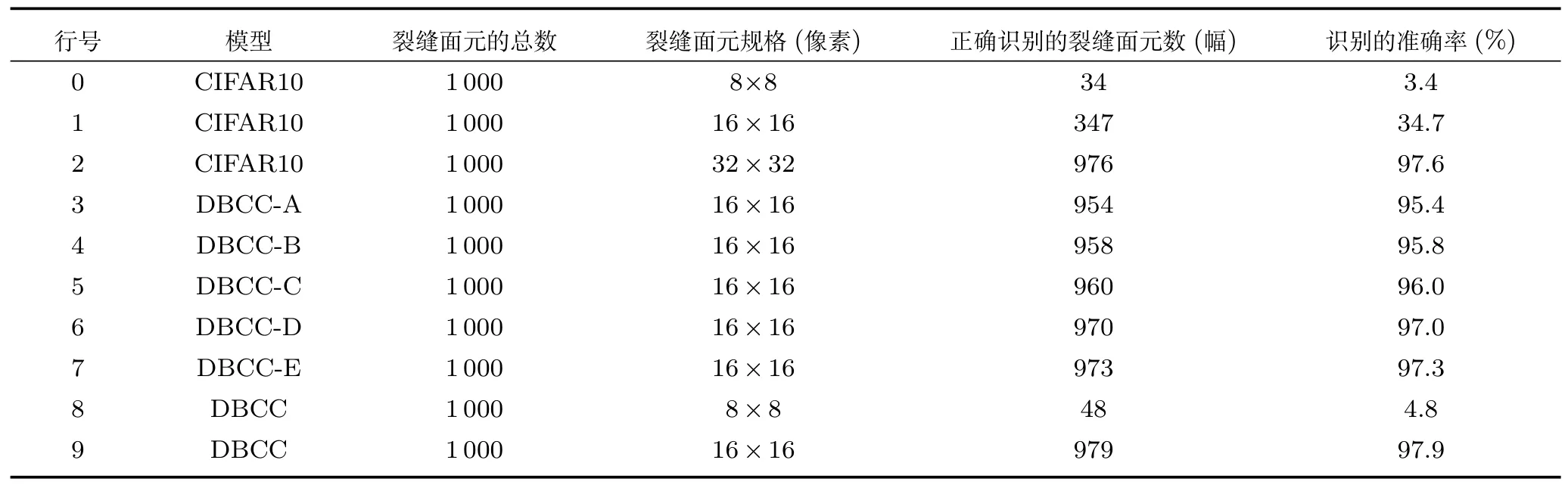
表4 各模型对于桥梁裂缝面元识别的准确率Table 4 Accuracy of each model for bridge crack surface element identification
第4 组实验用于测试改进的窗口滑动算法在对桥梁裂缝图像进行桥梁裂缝检测时,概率区分阈值Tp对于桥梁裂缝检测效果的影响.具体的检测结果如图13 所示.
由图13 可知,当概率区分阈值Tp的取值较小时,会有大量的桥梁面元噪声被检测出来.根据实验可知:当Tp的取值在0.9 到0.99 之间时,桥梁裂缝检测的结果可以满足检测的要求.因此,在本文的所有实验中,令Tp的取值为0.96.
第5 组实验用于测试本文提出的算法加速策略对于桥梁裂缝检测算法处理速度的影响.具体的实验分为2 个独立的实验.实验1,不使用算法的加速策略,直接使用本文提出的桥梁裂缝检测算法对桥梁图像进行裂缝检测;实验2,结合算法的加速策略,对桥梁图像进行裂缝检测.这两个实验所使用图像的分辨率均为1 024 像素×1 024 像素.两种方法的耗时如表5 所示.
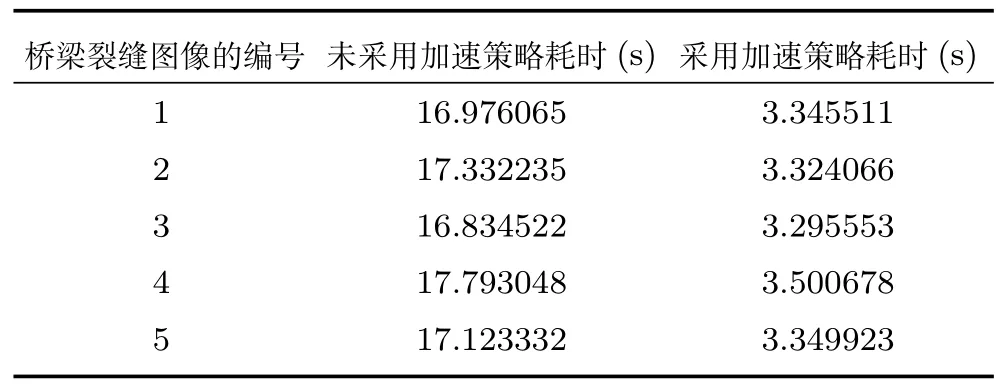
表5 算法加速策略对于本文识别算法的影响Table 5 Effect of algorithm acceleration strategy on the recognition algorithm in this paper
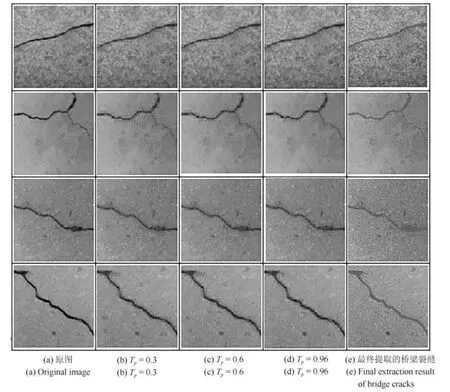
图13 概率区分阈值Tp对于桥梁裂缝识别效果的影响Fig.13 Effect of probability discrimination threshold Tpon bridge crack identification
通过对第5 组实验结果的对比可知,在本文中提出的算法加速策略可以极大地提高桥梁裂缝检测算法的检测速度.
第6 组实验用于测试基于桥梁裂缝面元的桥梁裂缝提取算法对于桥梁裂缝检测最终结果的影响.首先,本文从1 000 张用于桥梁裂缝检测的五类不同材质的图像集合中,随机地选取100 张不同背景纹理的桥梁裂缝图像.然后,使用这些桥梁裂缝图像对该算法进行测试,测试的部分结果如图14 所示.
通过对图14 的第2 列图像和第4 列图像的对比可知,基于桥梁裂缝面元的裂缝提取算法将会使得最终的桥梁裂缝检测结果更加准确.通过对第1列的图像和第3 列的图像对比可知,基于桥梁裂缝面元的裂缝提取算法结合本文中提出的其他算法,最终可以比较准确地提取出桥梁裂缝图像中的裂缝.图14 中的第5 列图像则为根据提出来的裂缝对图像中的裂缝定位的结果;裂缝所在的位置,即为矩形区域所标注的位置.另外,表6 给出了桥梁裂缝所在矩形区域的坐标点,本文就是利用这两个坐标点确定的桥梁裂缝位置.对图14 中的第一列图像从上到下进行编号,编号为1∼4,最终的坐标点位置如表6所示.
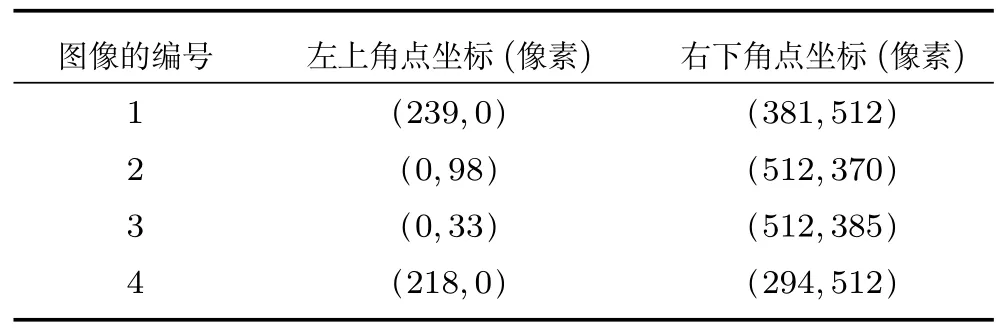
表6 桥梁裂缝定位的位置坐标Table 6 Position coordinates of bridge crack location
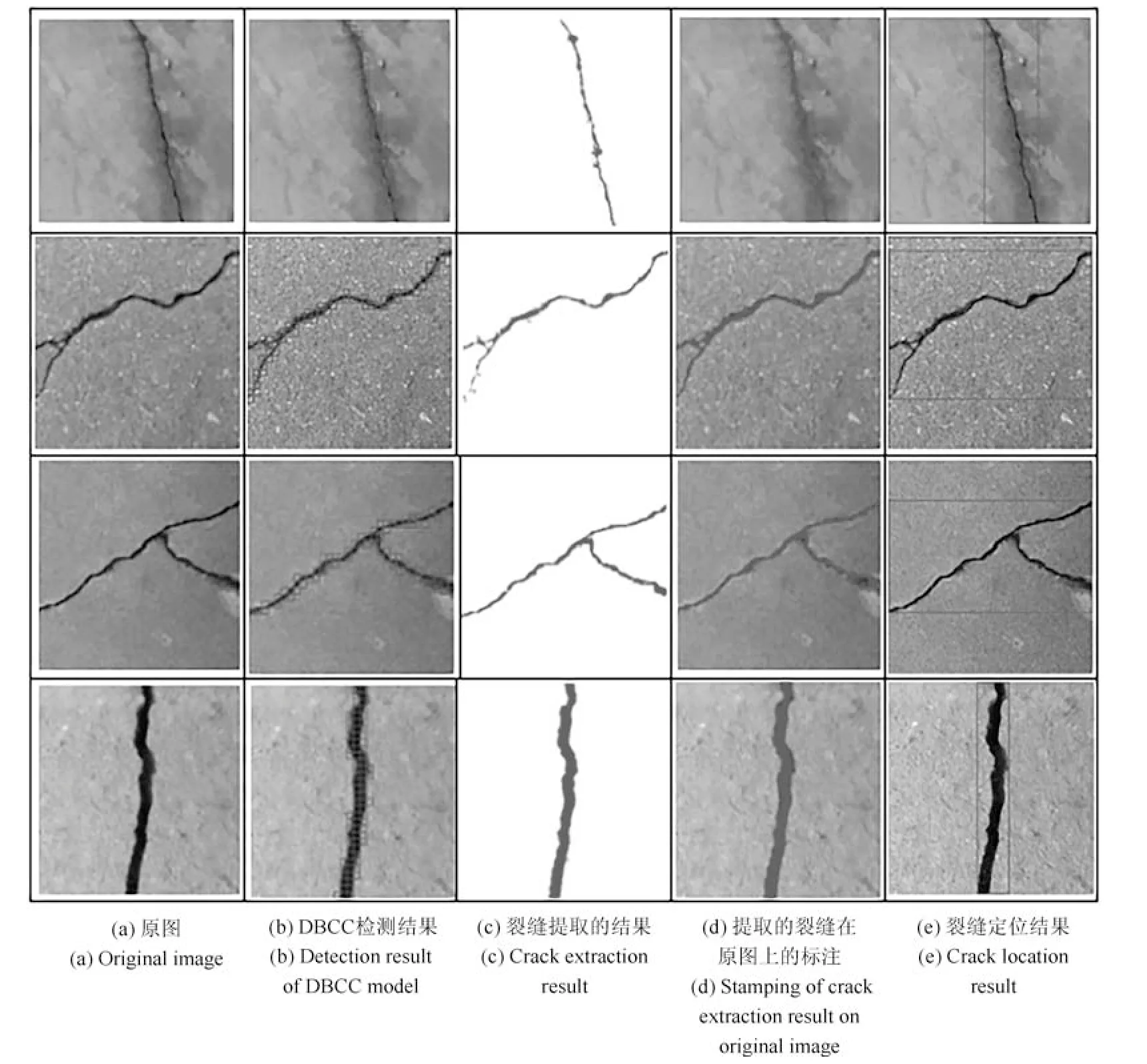
图14 基于桥梁裂缝面元的桥梁裂缝提取算法对于检测结果的影响Fig.14 Influence of the bridge crack extraction algorithm based on bridge crack surface element on detection
第7 组实验用于测试各种裂缝检测算法对于最终裂缝定位准确度的影响.具体的实验步骤如下所示:首先,本文从1 000 张用于桥梁裂缝测试实验的图像集合中,随机地选取500 张桥梁裂缝图像,并且在这些图像上,手动地标记出裂缝的外接矩形并记录外接矩形的左上角点坐标和右下角点坐标,如图15 中的第6 列图像所示;然后,使用不同的裂缝检测和提取算法提取出桥梁的裂缝;最后,使用本文的裂缝定位算法基于上一步的结果,对图像中的裂缝进行定位;图15 给出了定位实验中具有代表性的一组定位结果.
在第6 组和第7 组实验的基础上,为了对本文提出的桥梁裂缝定位算法进行更加深入的分析和评价,本文引入了桥梁裂缝定位准确度指数S,用于对裂缝定位的效果进行量化和分析.其中,S表明了裂缝真实的外接矩形和使用裂缝定位算法定位出来的外接矩形的偏差度;若两个外接矩形所定位的裂缝位置完全重合,则S为0;否则S越大,表明裂缝定位算法定位的裂缝位置越不准确;(x,y)和(,)为用裂缝定位算法定位出来的裂缝外接矩形的左上角点坐标和右下角点坐标;(r,c)和(,)为在选取出来的500 张桥梁裂缝图像上手动标记出来的桥梁裂缝实际外接矩形的左上角点坐标和右下角点坐标.桥梁裂缝定位准确度指数S的具体公式如式(6)所示;各种裂缝检测算法在定位准确度S一定的条件下,定位出来的裂缝位置在准确度S范围内的准确率如表7 所示.
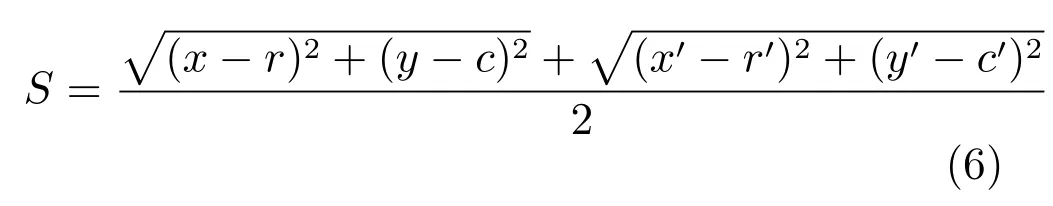
通过量化实验可知,如果设定定位算法定位出来的裂缝外接矩形与真实裂缝外接矩形的偏差度保持在10 个像素以内认为定位准确,则基于各检测算法的裂缝定位合格率为表7 中的第2 列数据所示;由表7 可知,准确度S的容忍越大,则基于各个检测算法的定位合格率递增;但是,观察整个量化实验的数据可知:基于本文提出的桥梁裂缝检测算法最终裂缝定位的合格率最高,并且算法运行时间也最短.基于本文提出的桥梁裂缝检测算法之所以会取得比较好的裂缝定位的准确度,其原因在于:本文在桥梁裂缝检测的过程中,在桥梁裂缝面元的识别阶段,已经排除了大量的干扰噪声,在桥梁裂缝的检测阶段已经将桥梁裂缝所在的区域锁定在一个比较靠近桥梁裂缝位置的区域,而后续的桥梁裂缝提取算法和桥梁裂缝定位算法都是在这一很小的桥梁裂缝区域内进行的运算,因此,本文所提出的桥梁裂缝检测算法是一种性能可靠、稳定的桥梁裂缝检测算法,这对于桥梁裂缝的检测、提取和定位来说都是极其重要的.
第8 组实验用于测试本文算法和其他主流裂缝检测算法的对比.为了说明本文算法相比于其他主流的裂缝检测算法,具有更好的识别效果和更强的泛化能力.该组实验从B集合的1 000 张桥梁裂缝图像中选取了5 类不同材质不同背景纹理的桥梁裂缝图像,且特意选取为带有复杂背景和严重噪声的桥梁裂缝图像,如图16 中的第2 行至第5 行图像所示.然后,利用本文提出的算法与迭代阈值分割算法[3]、FFA 算法[11]、最小路径选择算法[8]相对比,进一步说明本文算法的性能.
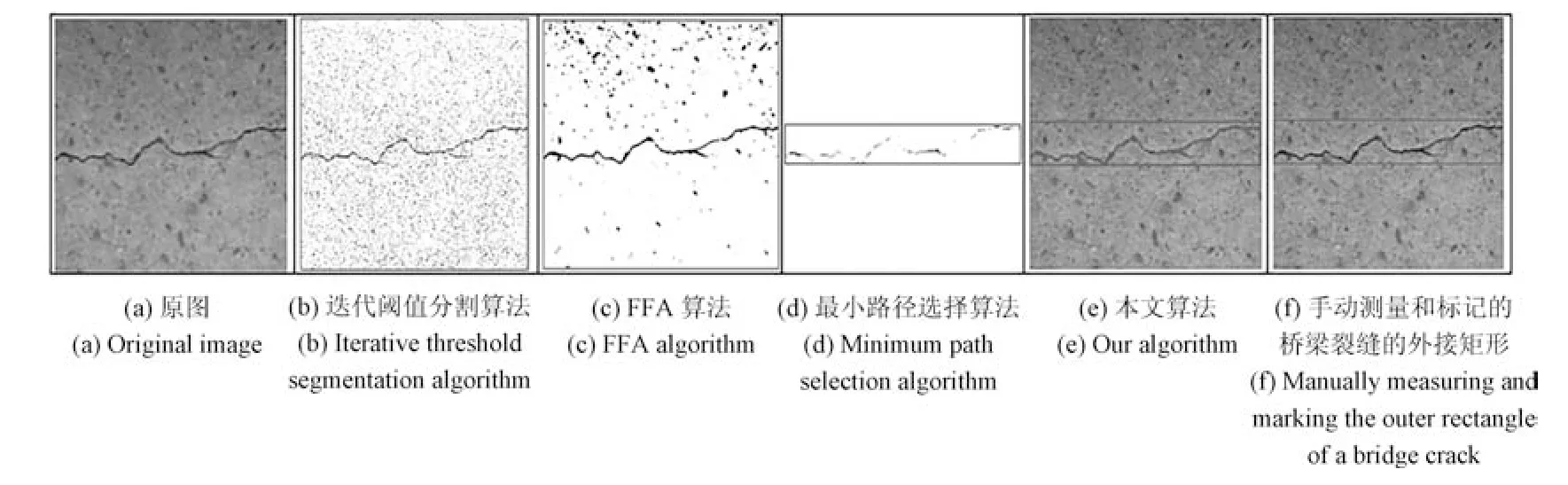
图15 各种裂缝检测算法对于桥梁裂缝定位准确度的影响Fig.15 Influence of various crack detection algorithms on accuracy of bridge crack location

表7 桥梁裂缝定位准确度的量化分析Table 7 Quantitative analysis of location accuracy of bridge cracks
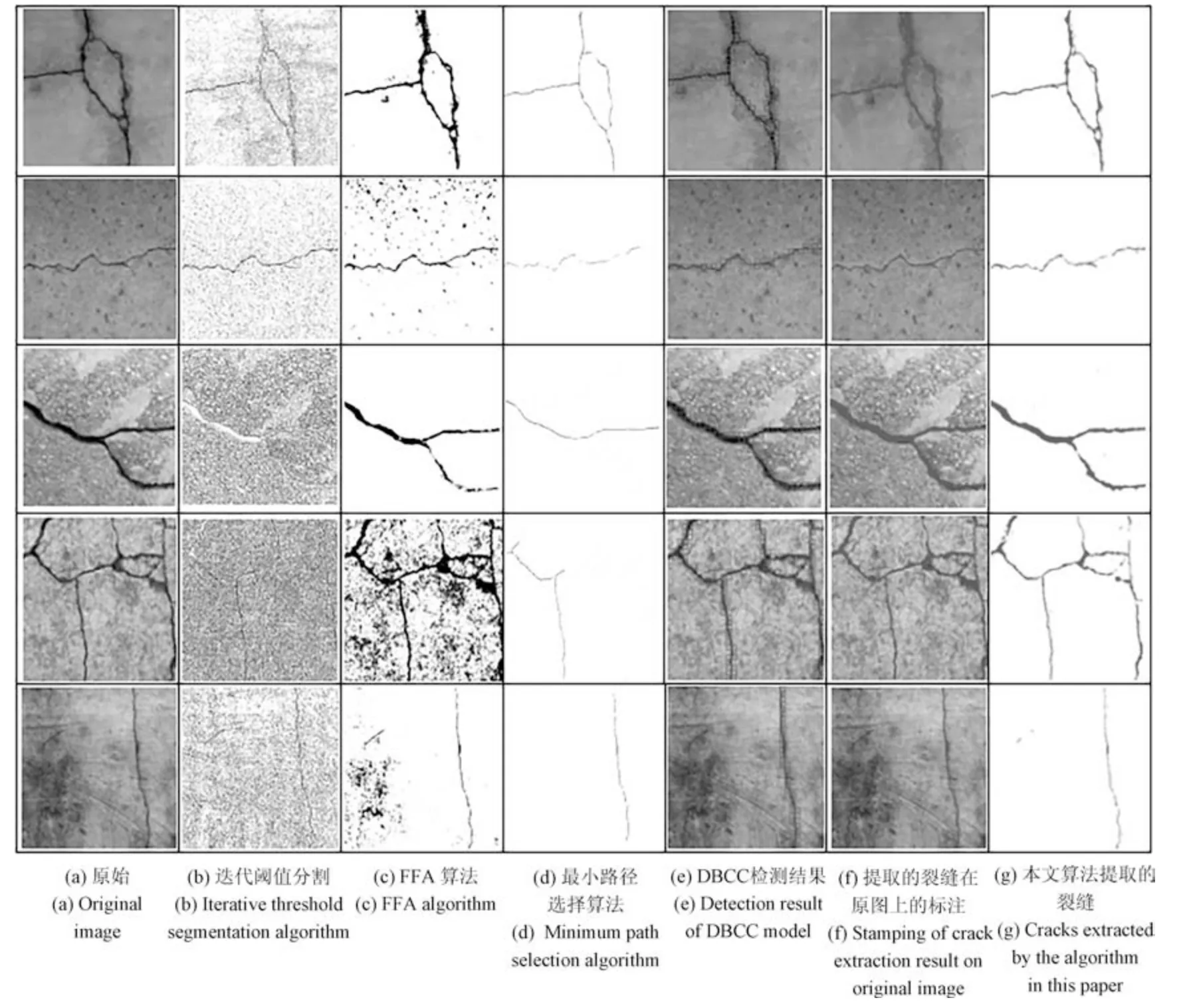
图16 主流裂缝检测算法和本文算法对于桥梁裂缝检测的效果图Fig.16 Detection results of the main stream crack detection algorithm and our algorithm for bridge cracks image
由实验结果可知,迭代阈值分割算法的检测结果会产生大量的噪声,并且这些噪声几乎覆盖了桥梁裂缝.FFA 算法虽然对于某些桥梁裂缝图像的裂缝提取效果不错.但是,当图像背景变得复杂的时候,在提取裂缝的同时也会产生大量的噪声,如图16 的第3 列图像所示.基于最小路径选择的裂缝提取算法,在大多数情况下可以比较准确地提取出裂缝,但是,该算法最大的缺点就是有可能提取出来的桥梁裂缝不完整,如图16 中的第3 行、第4 行的第4 列的图像所示;而且,该算法提取出来的裂缝也不能准确地表达裂缝的宽度.但是,通过图16 中的第5 列到第7 列图像可知,本文提出的桥梁裂缝检测算法可以很好的对不同类型的桥梁裂缝图像进行裂缝的检测和裂缝的提取,提取出来的桥梁裂缝也能够比较准确地表达裂缝的宽度.即使在面对背景复杂、噪声严重的桥梁裂缝图像时,本文提出的算法也能够很好地完成桥梁裂缝的检测和提取,如图16 的第5 行、第6 列和第7 列图像所示.
在上述实验结果比较的基础之上,为了对本文提出的桥梁裂缝检测算法和桥梁裂缝提取算法进行更加深入的分析和评价,本文引入了裂缝准确度指数Pre和裂缝召回率指数Rec用于对裂缝的检测和提取效果进行量化的分析和评价.其中,裂缝准确度指数Pre用于描述准确被检测提取出来的裂缝区域的像素数量TP占被检测提取出来的像素数量(TP+FP)的比例;裂缝召回率指数Rec用于描述被正确检测提取出来的裂缝区域的像素数量TP占应该被检测提取出来的裂缝区域像素数量的比例.裂缝准确度指数Pre和裂缝召回率指数Rec具体的计算公式如式(7)和式(8)所示.
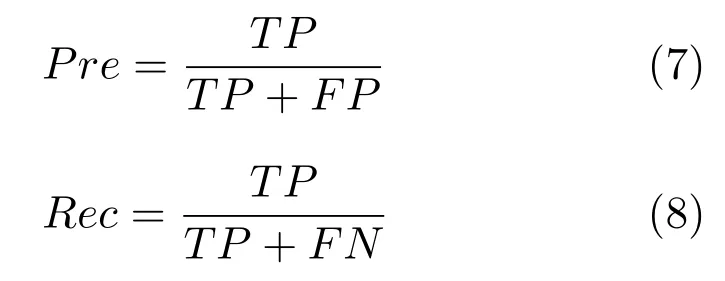
其中,TP代表被正确检测提取出来的裂缝区域像素的数量,FP代表被误判为裂缝区域像素的数量,FN代表属于裂缝区域的像素但是没有被检测出来的像素的数量.图16 中、第1 行到第5 行的5 幅桥梁裂缝图像所对应的迭代阈值分割算法、FFA 算法、最小路径选择算法以及本文所提的桥梁裂缝检测提取算法的量化分析和运行时间如表8 所示.
通过量化实验可知,虽然迭代阈值分割算法在时间效率上十分具有优势,但是Pre指数和Rec指数十分低下;FFA 算法和最小路径选择算法虽然在某些情况下,效果较好,比如第1 幅图像,但是在大多数情况下,其Pre指数和Rec指数相对来说不是很理想;而本文提出的桥梁裂缝检测和提取算法不仅在时间效率上表现出相对较好的结果,尤其是在Pre指数和Rec指数上效果稳定且很理想.
通过以上的实验和量化分析结果对比,说明本文提出的桥梁裂缝检测算法和其他主流的裂缝检测算法相比,具有更好的识别效果和更强的泛化能力.
本文最终对B集合中的1 000 张不同背景纹理、不同材质的桥梁裂缝图像进行了检测,下面给出了基于本文算法进行桥梁裂缝检测的部分结果,具体的桥梁裂缝检测结果如图17 所示.
7 结论
本文提出了一种基于深度学习的桥梁裂缝检测算法.讨论了桥梁裂缝数据集的人工扩增方法,详细介绍了本文提出的DBCC 模型和对窗口滑动算法的改进,同时采用一定的加速策略对桥梁裂缝检测算法的执行时间进行了一定的优化.实验结果表明,和传统的裂缝检测算法相比,本文提出的算法具有更好的识别效果和更强的泛化能力.
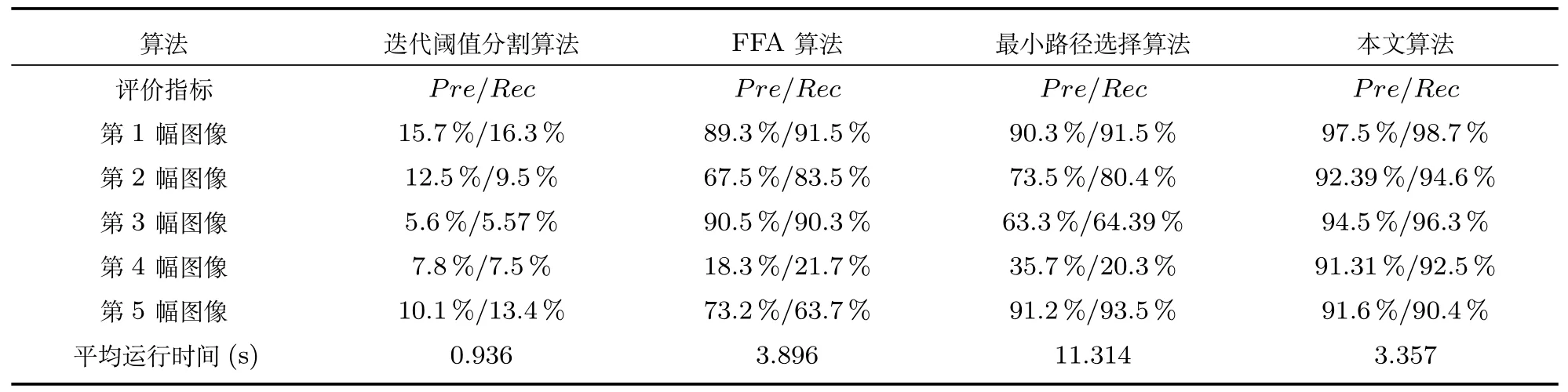
表8 桥梁裂缝检测提取算法的量化分析对比Table 8 Quantitative analysis and comparison of bridge crack detection and extraction algorithm
图17 基于本文算法进行桥梁裂缝检测的部分结果Fig.17 Partial results of bridge crack detection based on our algorithm
未来进一步研究的重点是:在不断提高算法的抗干扰能力和检测准确率的情况下,进一步提高算法的处理速度,以便算法在实际的应用过程中,表现出更好的性能.针对这一问题,可以使用CUDA、MMX、SSE、SSE2 等策略对算法进行优化.
为了推动本文算法的进一步改进和方便其他研究者使用本文算法进行对比和实验,本文对论文中所使用的桥梁裂缝图像数据集合、DBCC 模型的网络配置文件、超参数配置文件进行开源.相应的数据集和文件可在如下的链接中得到,具体的链接为:https://github.com/maweifei/Bridge_Crack_Imag e_Data.
