基于堆栈稀疏自编码与整体嵌套的乳腺病理图像细胞识别
2019-10-11唐奇伶方全夏先富杨济榕
唐奇伶,方全,夏先富,杨济榕
(中南民族大学 生物医学工程学院,武汉 430074)
乳腺癌是世界范围最常见的慢性肿瘤之一[1],以病理图像为基础的诊断被视为金标准,需耗费病理医生极大的时间.高速发展的计算机诊断能够帮助医师减少工作量,提高诊断效率.细胞识别是计算机诊断中一个重要基本问题.
在病理图像的细胞识别中,受细胞核类型和疾病恶性程度等因素影响,细胞核的外观差异较大.现有基于细胞或细胞核的识别方法均利用分割算法来实现,包括区域增长法[2]、自适应阈值法[3]、非监督的颜色聚类法[4]、水平集法[5],形态学基础方法[6]、基于监督的颜色纹理方法[7]、分水岭算法.而对于细胞分割,需要待处理的病理图像本身背景十分清晰,无杂质干扰,否则很难达到理想的效果.
本文提出的基于堆栈稀疏自编码与整体嵌套结合的细胞识别方法,与现有先分割[8]后识别细胞的方法不同首先利用堆栈自编码器提取细胞结构的高层特征,训练检测器,并加入整体嵌套优化网络结构,再利用检测器与滑动窗口实现自动细胞识别.新的算法使用无监督学习,易于获取训练样本,通过滑动窗口,能够更好地遍历图像信息,提高算法的准确性.
1 堆栈稀疏自编码模型
深度学习是近年来的一个新领域,在模拟人脑的基础[9]上进行多层神经网络学习算法.深度学习可通过逐层训练学习获得所输入数据的主要特征变量,以无监督训练算法学习和多层网络去映射单元提取出主要的结构信息.
自动编码器[10]是一种常见的无监督的特征提取算法,其目的是通过相关的数据,获得到更好的高维信息的数据特征.基本上,自动编码器拥有多层神经网络,训练过程包括前向传播和反向传播.利用反向传播算法,试图减少输入和重建之间的差异,尽可能通过学习得到一个编码器和解码器,即自动编码器模型.自动编码器模型见图1.
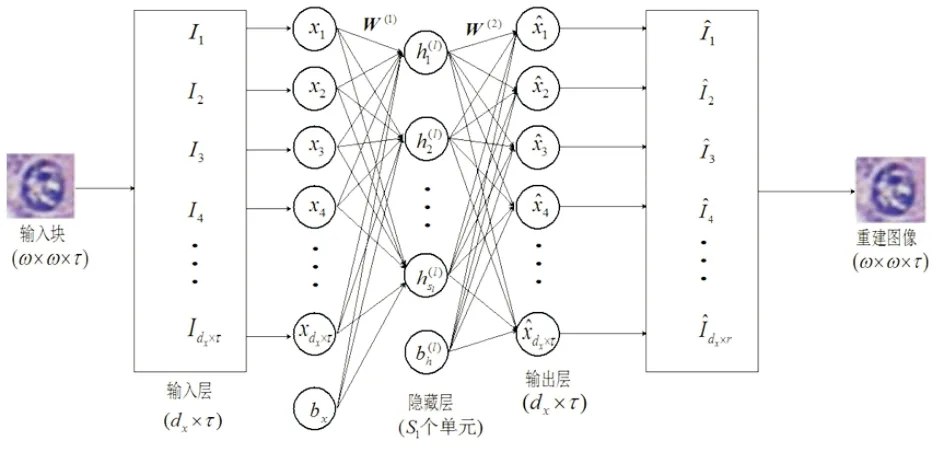
图1 基本自动编码器模型
自编码的学习过程分为两个方面:一方面是网络的隐藏层输出作为由学习得到的特征;另一方面是由学习得到的参数权值W,作用于其他部分.
1.1 基本自动编码器AE
设X为训练集图像块X=(x(1),x(2),…,x(N))T,k⊂{1,2,…,N},其中N标记训练集中图像的个数,dx表示每幅图像中包含的像素个数,ω表示图像的行列数,τ表示图像的色彩通道个数,使用的RGB三个通道.h(l)(k)=(h(l)1(k),h(l)2(k),…,h(l)dh(k))T,k⊂{1,2,…,N},表示利用自动编码器提取到的高维特征,表示第k个图像的第l层特征,dh表示在当前第l层中隐藏单元的数目本文中用上标表示当前层,小标表示当前层中的第几个隐藏单元.
一般来说,编码部分包括输入层和输入层到隐藏层的转化,特征提取后得到特征h.从特征h到输出层为解码部分,输出原输入的重建数据,训练解码即为使重建数据与输入数据尽可能相似,而训练自动编码器是最小化它们之间的差异,得到一组最优参数,可用一个损失函数表示:
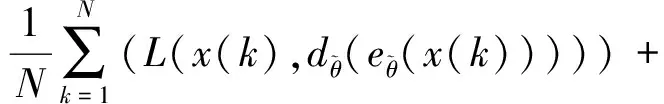
(1)
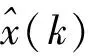
(2)
式中:W为dx×dh大小的的权重矩阵;bh⊂Rdh是偏置向量,其中W表示为:
(3)
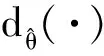
(4)
式中:WT为dx×dh大小的的权重矩阵;bx⊂Rdx是偏置向量;s(·)是s型逻辑激活函数,表示为:
(5)
其中z是神经元的输入值.
故解码权重参数表示为:
(6)
自编码器最后输出层的输入值y可表示为:
(7)
原数据的重建x表示为:
(8)
总的来说,自编码器的训练就是为了最优参数,使得式(1)结果最小化.式(1)中第二项为权重衰减项,目的为了防止权重过大出现过拟合,具体公式为:
(9)
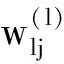
1.2 堆栈稀疏自编码SSAE
在基本自动编码器AE的基础上加入了稀疏约束项,构成稀疏自编码器模型[11].因为一般隐藏层神经元数量较大,通过给自动编码器网络添加一些限制条件来发掘出数据中隐藏结构信息,因此将公式拓展为:

(10)
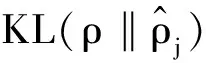
(11)
本文使用堆栈稀疏自编码器由多个基础稀疏自编码器组成的神经网络,前面网络的输出作为下一层网络的输入,后面网络的构建以此类推.经过实验比对等,使用两层的稀疏堆栈自编码模型[12-14].堆栈稀疏自编码器模型见图2.

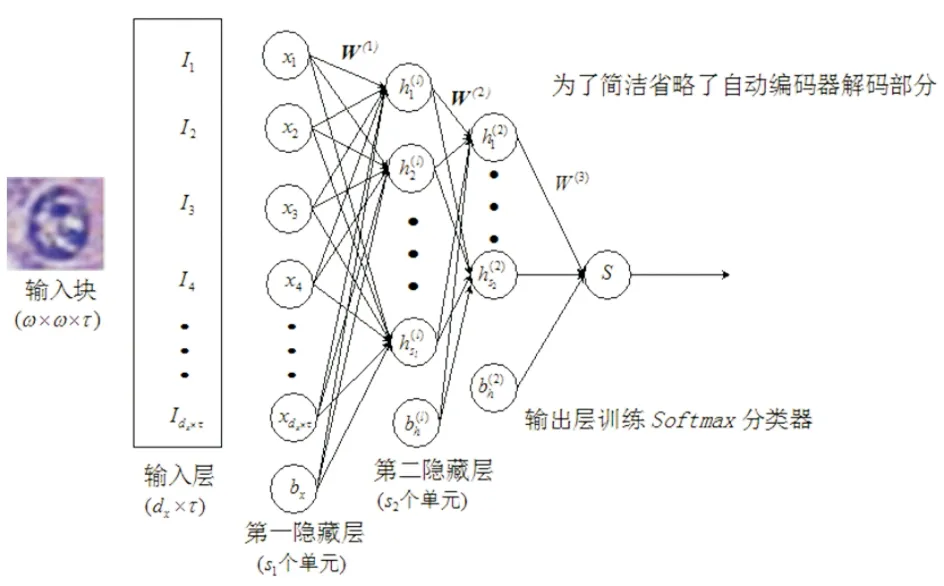
图2 堆栈稀疏自编码器模型
2 整体嵌套结构
本文采用了一种新的网络结构,称为整体嵌套结构(Holistically-nested network)[15].它被运用于边缘检测,由于这种结构同样适用于深度学习及自编码相关内容,本文将这种结构进行改动并优化运用到细胞识别里.
2.1 主要网络结构
深度学习在自编码方面具体算法结构见文献[14],多尺度下的深度学习分为4种[16]:多流学习结构,跨层网络学习结构,多输入的单模型结构,独立训练网络结构.本文采用的网络结构与以上4种存在一定差异,见图3整体嵌套结构,它由独立训练网络结构演化而来,类似一个相互独立多网络多尺度预测系统.输入图像首先进入第一层结构,将结果存储为两个相同的部分,一部分送入下一层结构进行类似的处理.经过多层结构处理进行后,保留每一层的结果输出.最后添加一个新的融合层,将多层输出组合成一个单一深度网络.该方法不仅可以克服一个loss函数单一回归预测的缺点,同时使用到的训练样本相对于之前有很大优化,多层结构提取到的细胞图像特征实现了多尺度和多水平的需求.
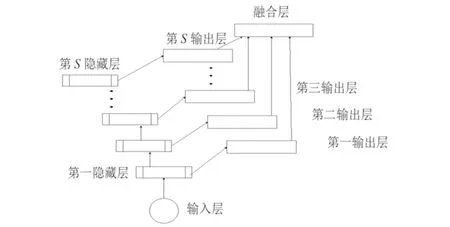
图3 整体嵌套网络结构
2.2 整体嵌套式堆栈稀疏自编码
本文提取了一种新的方法,将传统堆栈稀疏自编码和整体嵌套结构进行结合来完成细胞的识别,首先通过编码器提取细胞和非细胞图像的高层特征,然后将每一层得到的输出特征训练对应的Softmax分类器和各层对应的权值,再将训练好的分类器和权值用于细胞识别.与传统细胞识别方法相比,本文在1.2的基础上,同时将两层编码器的输出结果分开使用,训练两个Softmax分类器,最后将分类器应用于训练集,得到输出通过权值融合层得到两层权值,使结果进行融合完成实验.
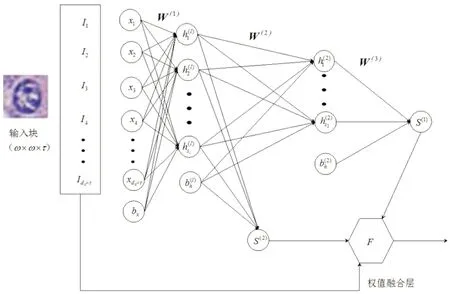
图4 堆栈稀疏自编码与整体嵌套的结合
融合层对权值的融合同样通过BP算法进行,目标函数表示为:
(12)

(13)
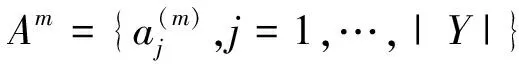
3 实验结果
3.1 数据集
本文采用的数据来自于美国凯斯西储大学(Case Western Reserve University)附属医院病理研究所,共选取了49名乳腺癌患的537个病理切片,他们H&E染色淋巴结呈阴性,雌性激素受体呈阳性这些病理切片在高倍扫描仪器下放大40倍成像,每一张大小为2200×2200,每张图片约包括1500个细胞.从数据库中选取37张图片用于训练,500张图片用于测试.37张用于训练的图片引入了滑动窗口进行处理先将图片中每个细胞核中心标记一个点,再使用一定大小的滑动窗口,设置滑动步长,对整张图片进行扫描,获得图像块,为了使图像块能尽量包含一个完整的细胞核,除选取34×34大小外(见图5b),还选取了3种其它规模的滑动窗口.
手工选取获得的图像块,被标记为细胞核的图像块尽量包含一个完整细胞核,非细胞核块不含有或仅含有一部分的细胞核.从中一共挑选出6 000张图片作为训练集,将细胞核与非细胞核图像块分别标记1和0.由于手工处理500张图片太过繁琐,在图片中随机选取400×400大小的部分图像(见图5a)通过滑动窗口进行扫描,从中选取2000张图像块作为测试集.
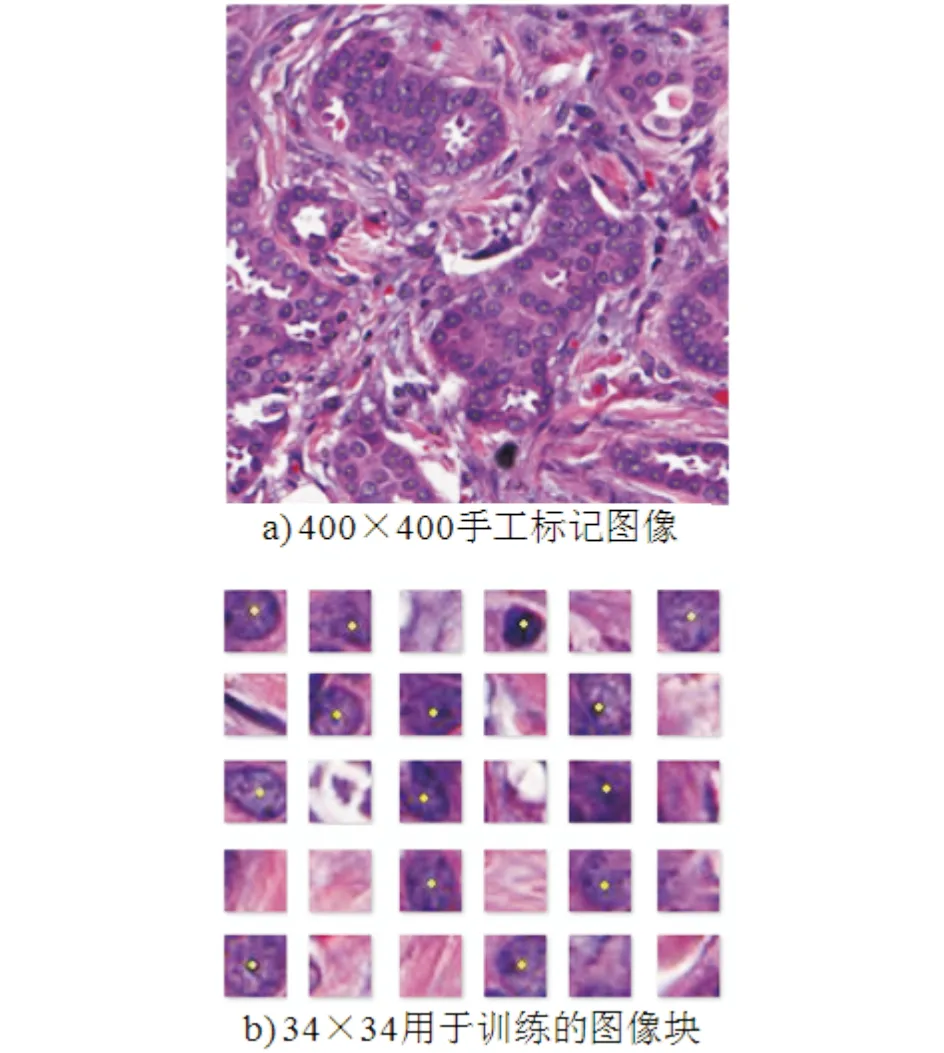
图5 处理过程中收集的图像集
3.2 参数设置
实验要求所选择的图像块尽量能包含完整的图像块,由于图像中细胞的大小出现差异,一共获得了4组不同大小的图像块.因为细胞的差异,不同大小的滑动窗口均有一定的缺点和优点,分别为34, 41, 33, 25.
所有的图像块为RGB彩色图像,均含有三个通道.首先讨论34×34大小的图像块,在SSAE第一层即输入层中,输入层的神经元个数等于输入图像的像素个数34×34×3;第二层即第一隐藏层中的神经元个数设置为12×12=144;第三层即第二隐藏层中的神经元个数设置为10×10=100.

图6 使用SSAE的输入像素强度学习的高级特征的可视化
3.3 对比模型设计
为展示SSAE+SMC+HN结构的优越性,实验中一共选取了8组其它的对比模型,其方法和描述结果见表1.表1中SSAE+SMC+HN对比基于手工设计特征的识别方法包括:最大期望值算法(EM)[17]、蓝色比率阈值算法(BRT)[18]、彩色去卷积算法(CD)[19].SSAE+SMC+HN对比其他特征的分类器识别[20]方法包括:不经过特征提取,直接将原图像块当SMC分类器的输入,直接训练SMC检测器.验证了加入稀疏项约束后的特征提取的有效性.在STAE+SMC+HN模型中,去除了稀疏有效性.SSAE+SMC+HN对比不同层数的方法包括:一层稀疏自动编码器+Softmax分类器+嵌套(SAE+SMC+HN),三层稀疏自动编码器+Softmax分类器+嵌套(TSAE+SMC+HN).对比运用不同层数的SAE构建方法对细胞识别准确度的最终影响.SSAE+SMC+HN中嵌套结构的优越性:与非嵌套结构的稀疏堆栈自动编码器+Softmax分类器(SSAE+SMC)进行比较.
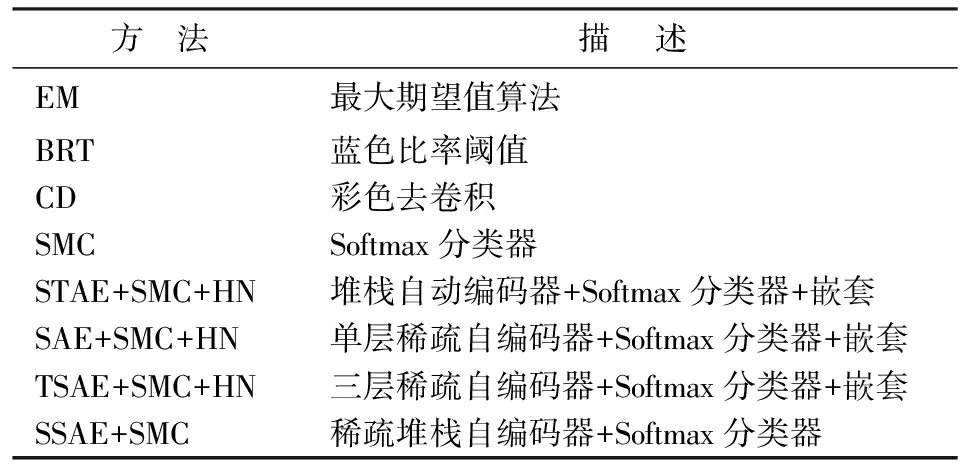
表1 采用的实验方法对照
为了进一步研究准确性,设计了实验采用的4种滑动窗口大小对模型检测效率和准确度的影响.同时考虑到滑动窗口步长的大小也会影响检测的效率,所以在保持其它条件不变情况下,调节滑动窗口步长观察变化.
3.3.1 评价方法
针对细胞识别的评价,本文采用准确率(Precision)、召回率(Recall/TPR)、综合评价指标(F-measure)、平均准确率(AveP)四个指标来衡量,分别定义为:
(14)
(15)
(16)
(17)

(18)
式(14)~(18)中:TP表示真阳性,即细胞图像块被识别为细胞的数量;FP表示假阳性,即非细胞图像块被识别为细胞的数量;FN表示假阴性,即细胞图像块未被识别为细胞的数量;Precision指准确率,是衡量识别系统信噪比的指标,即识别的正确细胞与识别出的全部正确细胞的百分比;Recall指召回率,是衡量某一检测系统从数据集中检测出相关内容成功度的指标,即识别的正确细胞与全部细胞的百分比;F值是精确率与召回率的调和均值;平均准确率Avep表示在[0,1]区间内p(r)的平均值,p(r)是关于Recall的函数,它实际计算了Precision-Recall曲线下的面积,面积越大表示该方法性能越好.
3.4 实验结果分析
各模型在全部识别图像上准确率、召回率、综合评价指标、平均准确率的平均值结果见表2.
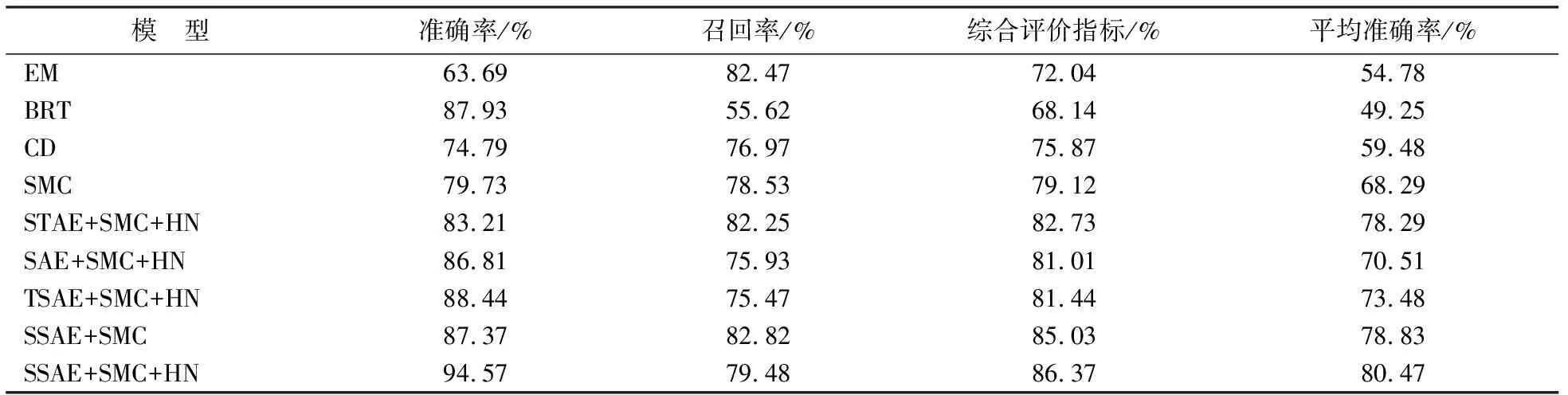
表2 对照实验结果
图7是各大模型ROC曲线的对比图,ROC曲线用来评价分类器的性能,每个点的横坐标是FPR (false positive rate),称为(1-特异度),所有实际负例中,错误得识别为正例的负例比例;纵坐标是TPR(true positive rate),称为灵敏度,所有实际正例中,正确识别的正例比例.通过测试分类结果可算得TPR和FPR的一个点对曲线在对角线左上方,离得越远说明分类效果越好.
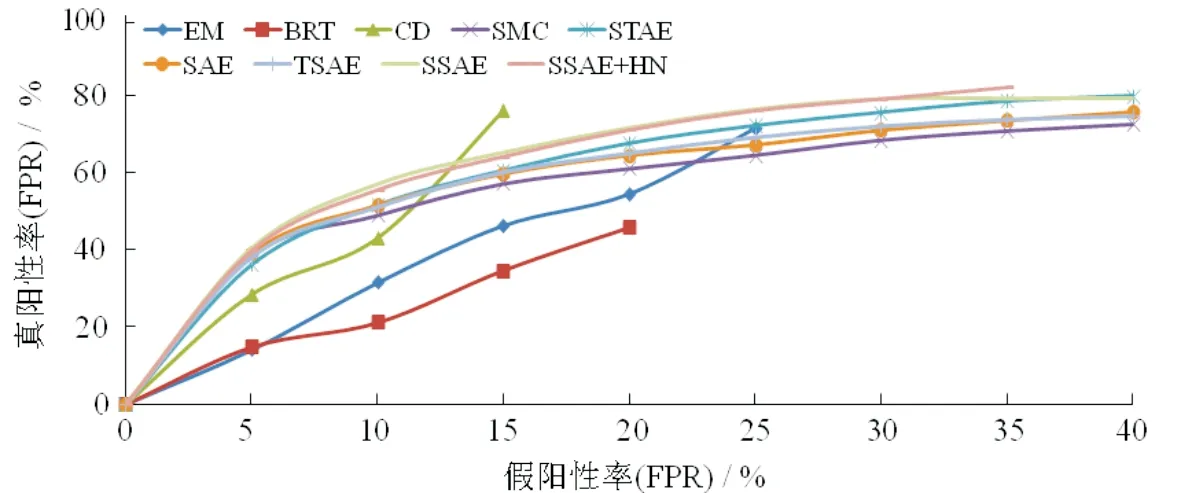
图7 实验ROC曲线图
综上,本法利用SSAE+SMC+HN堆栈稀疏自编码和整体嵌套结构的结合,先提取图像特征,再训练多个Softmax分类器,再利用融合层完成融合,用于细胞识别.对比其他常见的细胞识别方法,本文提出的模型具有最高的准确率,能准确地识别细胞.
4 结语
细胞自动识别是病理图像分析中的挑战性基本问题,为后续的定量分析提供基础.针对这一问题,在深度学习的基础上,使用堆栈稀疏自编码模型对图像高级特征的提取和细胞识别具有良好的效果.本文将堆栈稀疏自编码与整体嵌套结构相结合应用于细胞识别,为验证框架的有效性,分别比较了SMC, STAE, SAE, TSAE与SSAE等类似方法;为验证稀疏约束性的有效性,对比了EM, BRT, CD等流行的方法.定性和定量评估结果都表明:该模型在细胞别精度方面胜过了许多不同的先进方法,如缺少整体嵌套结构的堆栈自编码、单层自编码、三层堆栈自编码及非深度学习算法等.堆栈稀疏自动编码器框架与整体嵌套式结构融合其他更有效的信息值得进一步提高性能,更好地识别乳腺组织病理图像细胞.
