时态JSON数据模型及查询语言处理
2019-10-11胡章兵左良利
胡章兵,左良利
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
随着网络技术的发展和普及,各个领域的数据都呈现指数级的增长。中国云计算大会网站2018年发布的数据量增长报告显示,2020年的互联网数据量将是目前的44倍。正是由于各个领域的数据量不断增长和软硬件计算能力的提升,云计算、大数据、机器学习等智能技术得以迅猛发展和应用。由此,利用这些智能技术来挖掘出在大量数据的背后所隐含的发展趋势和规律就显得极具有价值和必要[1]。
时间属性作为自然界数据表达的一种重要衡量维度,挖掘出在大量数据发展过程中的时态规律,逐渐得到学术界和工业界的广泛关注和研究。时态数据挖掘算法(temporal data mining)就是在这一背景下逐渐被研究和应用的成果[2]。时态数据挖掘算法是对观测到的时间属性数据进行分析,然后发现未知的知识和以时间数据拥有者可以理解且对其有价值的方式来总结时间知识。由于现实世界总是按照时间不断发展变化的,大多数信息都包含有时间属性,例如股票的波动,超市的交易,天气的变化,文档的编辑,含时间的实验数据等。因此,在数据知识领域,如何对现有的随时间变化的数据进行时态建模,一直是学者们的热点研究方向。
1 相关工作
文中的主要工作与时态数据库和时态XML非常相似。接下来分别从这两个领域介绍其相关工作。
1.1 时态数据库
首先,在时态数据库发展过程中,如何在传统的数据库模式中引入时态信息得到了众多学者的广泛研究。自20世纪80年代,E.F.Codd提出的关系数据库模型得到广泛应用之后,Jensen等就随即提出了基于关系表模式的时态关系数据库[3],并给出了时态数据库的概念定义和词汇表。James Clifford通过将时间属性添加到关系表模型,提出了历史关系数据库模型[4],当需要跟踪来自数据的所有更改并具有建模现实的完整历史时,其时间标记数据值可以体现数据在时间维度上的历史变化过程。在文献[5]中,将时间关系模型主要分为两类:非分组记录(ungrouped)和分组记录(grouped)。非分组记录模型在记录后面添加表示该记录的有效时间属性(有效开始时间vstart和有效结束时间vend)。而分组记录是根据记录在时间上的发展变化过程对记录中的每个属性进行时间分组标记。表现形式的区别用一张员工表展示,如图1所示。
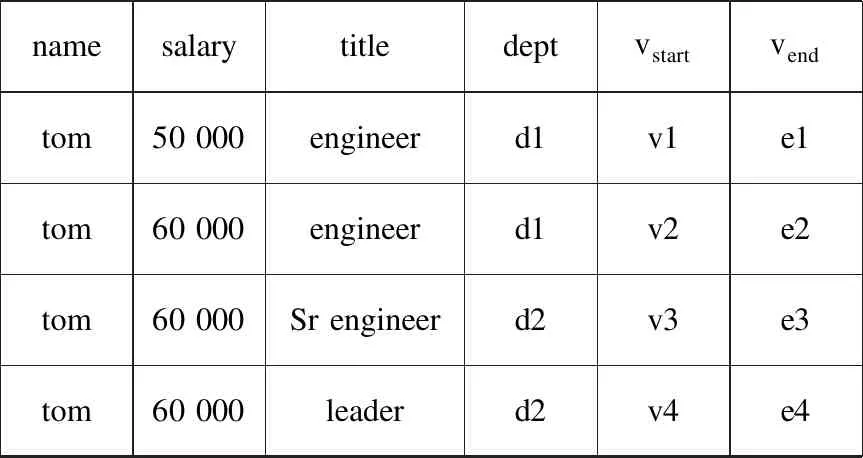
namesalarytitledeptvstartvendtom50 000engineerd1v1e1tom60 000engineerd1v2e2tom60 000Sr engineerd2v3e3tom60 000leaderd2v4e4

(a)ungrouped record
(b)grouped record
图1 非分组记录和分组记录
随着单时态数据库的不断深入研究,其在时态表达方面的缺点就逐渐显现出来。不论是单时态有效时间数据库还是单时态事务时间数据库,都仅能够表达数据在某一个时间维度的信息。由此,双时态数据库逐渐成为学者们研究的热点方向。Knolmayer等给出了双时态关系数据库的模型定义和具体实现[6],其在关系数据库模型中同时加入有效时间(数据在现实世界中真实有效的时间区间)和事务时间(数据在存储介质世界的有效时间区间),得到了能够在现实世界维度和物理介质维度都能体现数据在时间线索上的发展变化历史模型。此外,Dayal等实现了一个基于面向对象的时态数据库系统[7],在面向对象模型中加入有效时间维度,扩展了面向对象数据库数据对象在时态语义表达的功能。Zheng等提出了一个基于图数据库的时态图模型[8]。
1.2 时态XML
关系型数据库模型和查询语言SQL(structure query language)虽然能够很好地表达和处理结构化数据,但是现有的很多应用领域需要处理半结构化的数据,但关系数据模型和SQL对半结构化数据模型表达的灵活性差,因此半结构化模型和查询语言处理逐渐成为数据库,网络数据传输,元数据等领域的研究热点。特别的,随着现代计算机应用(例如社交网络,协作web信息系统等)的迅速发展,要求网络上的数据交换具有较高的传输效率。XML(extensible markup language)自20世纪80年代被万维网联盟(W3C)拟定,因其自描述、易理解等优点已经成为了W3C的推荐标准。但是由于非时态XML模型既不能支持时态语义表达功能,也不能体现XML文档在随时间更迭过程中的数据变化过程等缺点,时态XML逐渐吸引了众多学者的研究。Amagasa等针对非时态XML的XPath模型,通过在每条边上添加有效时间戳,以表示子节点是否有效存在[9]。另外,Wang等在其管理系统中,为了支持多个客户端编辑XML文档进行协同工作,利用时态XML模型来管理文档在协同编辑过程中的版本变化[10]。同时,Grandi为了高效地管理XML格式的法律文献,实现了一个时态XML模型,通过时态模型中的发表时间,有效时间,效力时间,事务时间四个时间维度表示法律文献的演变历史[11]。同样,为了更好地突出模型在时态表达和模型一致性等方面的特性,双时态XML在许多应用领域也日益成为研究对象。Wang等提出了在双时态XML领域中较为普遍的实现方案,通过在标签属性中加入有效时间区间和事务时间区间来表达数据在双时态维度的体现[12]。另外,汤娜等讨论了在双时态XML查询中now语义失真的研究和扩展[13]。一般的,在由时态XML模型到时态XML文档的转化中,时态文档通过时态属性或时态标签来表示数据的时间信息。属性的时间过程同样用属性元素来表示。
2 非时态JSON数据模型
XML虽然得到了广泛的应用和研究,但是随着需求的不断增加和复杂,XML的缺点也逐渐显露出来,如冗余度高,数据插入修改困难,处理大量数据时效率低下,客户端浏览器解析困难等。2006年,Douglas Crockford把JSON(JavaScript Object Notation)提交给Internet Engineering Task Force (IETF),JSON因相比XML易读写,同时也易于机器解析生成等特点得到了广泛应用。自JSON数据格式提出以来,针对JSON和XML在实用性、传输效率、安全性等方面进行了深入的讨论研究和实验[14-16],都一致认为JSON在传输效率和浏览器解析等方面都比XML更加的实用和高效。因此,数据交换格式在WEB领域中逐渐从XML转为JSON。2009年,权重民等利用JSON实现了一种高效、安全访问远程数据库的方式[14]。2018年,王东兴等提出基于JSON的GeoJSON在异构地理信息数据集成中的应用[16]。但是在非时态JSON得到广泛应用时,针对JSON的理论研究和模型定义却鲜有成果。
2.1 JSON语法及文档示例
JSON语法定义,JSON文档是由键值对组成的字典,其中的值又可以是一个JSON文档,从而JSON模型允许任意级别的嵌套。完整的JSON规范定义了七种类型的值:分别是字符串,数字,对象,数组,true,false和null。文中给出了一个来自某论坛网站用户信息的简单JSON文档示例,如下:
{
"name":{"firstname":"Tom","lastname":"Doe"},
"age":18,
"hobbies" ["fish","tennis"]
}
2.2 JSON文档树
根据JSON文档的语法定义,可以用树型结构来描述JSON文档的信息,如图2所示。

图2 JSON树
2.3 JSON树模型
定义1(节点):假设J是一个JSON文档,其中V(J)是文档J的节点集,则V(J)有六种节点:根节点、字符串节点、数字节点、布尔类型节点、数组节点和对象节点,分别标记为r,vs(J),vn(J),vb(J),va(J),vo(J)。为了简化讨论,null暂不做考虑。满足:
V(J)=r∪vs(J)∪vn(J)∪vb(J)∪va(J)∪vo(J)
定义2(边):E(J)是文档J的所有边的集合,其中每条边可以表示为(p,c),其中p=r,c∈ve(J)或p∈ve(J),c∈ve(J)或p∈ve(J),c∈vt(J)或p∈ve(J),c∈va(J)或p∈va(J),c∈vt(J)。
定义3(文档):JSON文档J=(V(J),E(J),r)。
3 时态JSON数据模型
随着时间的更迭,用户的数据不断发生变化。该用户在2017年12月1号创建,基本信息如图2所示。此后,在2017年12月15号其“firstname”变更为“Alen”,在2018年1月1号加入“vip”属性,并且成为该论坛的VIP用户,在2018年1月1号新添了爱好“yoga”,在2018年1月5号删除爱好“tennis”,在2018年1月23号,其年龄由18增长为19。
由于非时态JSON模型不能很好地表达数据对象在时间上的变化过程,通过对非时态JSON模型进行时态扩展得到了时态JSON模型。
3.1 时态JSON模型
定义4(边):将有效时间属性加入到边的定义中,以此反映这条边尾部节点的有效时间区间,得到TE=((p,c),t)。其中(p,c)与非时态模型的定义一致,而t表征该边的时态信息,t是一个时间区间,由有效开始时间和有效结束时间构成-[vstart,vend],如:
[2017-12-01,2018-01-15]。2017年12月1号到2018年1月15号是该边尾部对应节点的有效时间范围。
定义5(文档一致性):若一个节点有很多孩子节点,其有效时间为t,连接双亲节点和孩子节点的边分别为:
((p,c),t1),((p,c),t2),…,((p,c),tn),则:
(2)t1∩t2∩…∩tn=∅(数组除外)。
根据用户信息的变化过程,可以用图3所示的时态模型表示文档的演变进程。
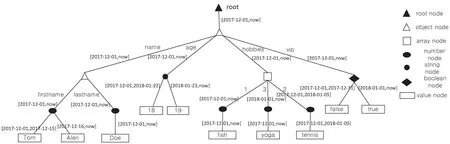
图3 时态JSON模型
3.2 JSON Schema
JSON Schema是用来规范JSON文档的属性结构的,JSON Schema本身也是一个JSON文档。JSON文档的schema如图4所示。

图4 JSON Schema
但是,随着JSON文档的变化,JSON文档的Schema 也同样会发生变化。例如,文档加入了属性“vip”之后,原本的Schema不能够表达JSON文档的结构了。但是由于Schema也是JSON文档,因此采用同样的方法,可以用类似图3所示的时态JSON模型来表征JSON Schema的变化。
3.3 模型到文档的映射算法
Algorithm:Temporal Model Translation
Input temporal model root nodeR
Output temporal document
1.DgetDocument(R)
2.getDocumetn (N) {
3.if(Nis object) :
4.getDocument(N)
5.else :
6.If(Nis array) :
7.for each edge:
8.p1createKVpair(N.attribute,N.text)
9.p2createKVpair(“validtime”,time)
10.else :
11.for each edge:
12.p1createKVpair(N.attribute,N.text)
13.p2createKVpair(“validtime”,time)
14.}
15.createKVpair(key,value) {
16.kv.set(key)
17.kv.set(value)
18.retrun kv
19.}
根据上述提出的时态模型到时态文档的映射算法,可以得到如图5所示的时态JSON文档。

图5 时态JSON文档
3.4 时态文档查询语言
非时态JSON查询语言目前还没有标准规范,但是对于非时态JSON文档,已经有JSONPath,JSONip,N1QL等处理方法。文中时态文档的查询语言综合上述几种方式的特点进行时态扩展。首先,在JSONPath表达式中添加时态属性扩展支持,可以满足大部分检索需求,例如普通的JSONPath从2.1节文档示例中查询用户的名字,可以用如下JSONPath表达式:
$.name.firstname或$[“name”][“firstname”]
但是要检索出在图3时态文档中的名字,需要对其进行时态扩展,结合JSONPath和JSONip,提出了时态查询语言。例如要检索出在2017年12月5号该用户的名字,可以用如下表达式:
let $name=collection.find("name")
return{
"firstname"=$name("firstname")[@from eq 2017-12-05 and @end eq 2017-12-05]
}
其中,“@from”属性表示开始时间,“@end”表示结束时间,“eq”表示相等,用“=”表示作用一样。另外,如果要检索该用户注册为VIP的有效时间,可以用自定义time()函数获取,表达式如下:
let $vip=collection.find("vip")[@value=true]
return time($vip)
4 结束语
目前,针对JSON时态信息建模和时态查询语言处理的理论研究非常少,文中提出了时态JSON数据模型。根据时态JSON模型,对传统的查询语言做了简单的时态扩展,但目前仅能支持一些相对简单的查询,后续会进一步提出类似TempSQL能完成连接、分组、排序等更高级的时态查询处理。另外,还提出了一个由时态模型到时态文档的映射算法,解决了从模型到文档的映射方法,后续会根据提出的时态模型和针对映射后的文档解决其在存储方面的问题,因为存储的性能好坏直接影响查询性能。
