基于MapReduce的快消品电商网站热搜品牌TOP-N计算
2019-10-09
(福建工程学院 信息科学与工程学院,福建 福州 350118)
快消品,快速消费品(FMCG,fast moving consumer goods)的简称,是指那些使用寿命较短,消费速度较快的消费品。快消品牌商在线下渠道面临困境,从线下转向线上来寻求额外的销售增长,是行业内最显著的趋势。近年来,互联网快消品市场迎来迅速发展,涌现出一大批快消品电商网站,如阿里1688零售通、京东掌柜宝、掌合天下、惠民网、便利宝、易酒批、万全速配、中国邮政邮乐网等[1]。
因为快消品使用寿命较短、价格较为便宜,消费者的购买决策往往相对简单,更加热衷于品牌化、大众化。然而快消品牌种类成千上万,如果能从电商网站的搜索日志里挖掘出热搜品牌并推荐给用户,将大大降低用户的时间成本。但是,用户在搜索时输入的关键字往往不总是商品完整的品牌名称,所以如何从搜索引擎的每一条搜索日志里挖掘出与品牌检索热度间的潜在相关性成为问题的关键。
1 相关知识介绍
1.1 层面检索
层面检索(facet search),也称层面导航,是一种按照分类法进行存储和检索信息的技术[2]。层面检索能够在搜索关键字的同时,按照Facet的字段进行分组并统计,主要用于导航实现渐进式精确搜索,从而给用户提供更加友好的搜索体验。比如在京东或淘宝的搜索栏输入“笔记本电脑”进行搜索,在搜索结果页面上方会展示品牌、内存容量、屏幕尺寸等不同类目的相关查询结果。用户可以通过点击这些类目里的结果进行渐进式精确搜索。这里的品牌、内存容量、屏幕尺寸就是一个个Facet。目前绝大多数的电商网站搜索引擎都有提供层面搜索功能。而且常用的几大开源搜索引擎框架,如Apache Solr、ElasticSearch也都实现了层面搜索功能。层面搜索使得搜索引擎可对数据之间的内在联系进行挖掘,从而作为海量数据的统计工具。
1.2 MapReduce
MapReduce技术是Google公司于2004年提出的一种分布式编程模型,主要用于大规模数据集的并行计算[3]。MapReduce采用了分而治之的思想,将复杂的、运行于大规模集群上的并行计算过程高度地抽象到两个函数:Map和Reduce。谷歌的MapReduce运行在GFS(google file system,谷歌文件系统)上,Hadoop MapReduce是谷歌的MapReduce的开源实现,运行在HDFS(hadoop distributed file system,Hadoop分布式文件系统)上。如无特殊说明,本文所提的MapReduce均为Hadoop MapReduce。
数据本地化是MapReduce的核心特征,即采用“计算向数据靠拢”的设计理念[4],因为在大数据集群环境下,移动数据需要大量的网络传输开销,而移动计算则比移动数据更加经济。本着这个理念,在一个集群中,MapReduce框架会尽量让Map程序就近地在HDFS数据所在的节点运行,即尽量将计算节点与数据节点放在一起运行,从而大大减少了数据在节点间的移动开销,有效提升整体性能。
MapReduce极大地方便了分布式编程工作,它把计算过程分解为两个阶段,即Map阶段和Reduce阶段。程序员只需实现Map函数和Reduce函数,而如分布式存储、集群任务调度、节点通信、负载均衡、容错处理等并行编程中的各种复杂问题则由MapReduce框架负责解决。Map函数和Reduce函数都是以键值对

表1 Map和Reduce函数[5]Tab.1 Map and Reduce functions[5]
具体的MapReduce工作流程如图1所示,详细描述如下[4,6-11]:
(1)在Map阶段,将存储在HDFS上的输入文件逻辑切分为多个等大小的分片。每个分片即为一个块(Block)的大小,默认为128M。
(2)因为HDFS上每个块默认保存3个副本,Map任务会尽量就近读取输入数据分片,并从中解析出一个键值对集合,作为Map任务的输入。
(3)Map任务会根据用户自定义的映射规则,输出一系列的键值对
(4)为了让Reduce任务可以并行处理Map的输出结果,需要对Map的输出进行混洗(Shuffle),即进行分区(Partitioin)、排序(Sort)、合并(Combine)、归并(Merge)等操作,以得到
(5)在Reduce阶段,Reduce任务以一系列

图1 MapReduce的工作流程Fig.1 MapReduce workflow
实际应用中,很多复杂的问题很难用一轮MapReduce任务解决,需要将其拆分成多个MapReduce子任务去完成。由于后一个子任务要使用前一个子任务的输出结果,所以经常在一轮 MapReduce 任务执行完成之后,其输出并不合并成一个文件,而是直接作为下一轮MapReduce 任务的输入,从而构成迭代的MapReduce工作流[12-13]。
2 热搜品牌计算方法
用户在电商网站检索商品时,输入的关键字往往并不是商品的品牌名称,为了从用户的每次检索行为统计出品牌检索热度,本文在搜索引擎的检索日志里增加记录每次用户检索的结果集在商品品牌字段上的层面统计,格式如图2所示。

图2 品牌层面检索日志格式Fig.2 Log format of facet search on brand
日志文件中每行为一条检索日志记录,每条检索日志记录包含多个属性,各个属性由符号‘|’分隔。图2中第一个属性表示检索时间;第二个属性表示检索关键字;第三个属性“brandFacet”是品牌层面统计的标识,说明下一个属性表示本次检索的结果集在品牌字段上的层面统计;第四个属性表示层面统计,由若干个键值对组成,一个键值对中的键和值用符号‘:’分隔,键值对间用空格分隔。例如图2中第一行的含义为用户在2018-12-30 23:19:39输入关键字“康师傅”进行检索,本次检索在品牌层面的统计结果为“00006:66”,即共检索出66个品牌编码为“00006”(“00006”是康师傅的品牌编码,品牌名称与品牌编码的对应关系存储于字典表中)的商品。图2所示的检索日志格式还可以扩展为每行同时记录多维层面统计结果。
接下来根据每次检索的品牌层面统计结果计算出本次检索对该结果集中各品牌热度的贡献值。具体计算过程如公式(1)所示。

(1)
其中,Hi表示某次检索对品牌i的热度贡献值,Ni表示该次检索结果集中品牌i的商品数目,n表示该次检索结果集中品牌的数目。可见Hi的取值范围是(0,1],其值越大,表示本次检索对品牌i的热度贡献值越大。
最后,将某个时间段内的检索日志对各品牌的热度贡献值进行归并累加和排序即可得到该时间段内各品牌的搜索热度排行榜。
3 MapReduce工作流设计
从搜索引擎的检索日志统计热搜品牌需要进行三轮的MapReduce作业。第一轮MapReduce作业完成各个品牌的搜索热度的计算,输出一系列键值对<品牌编码,搜索热度>。第二轮MapReduce作业将第一轮作业的输出与品牌字典表进行连接操作,将品牌编码信息转换为“品牌编码|品牌名称”。第三轮MapReduce作业对第二轮作业的输出按value(即品牌搜索热度)的值进行降序排序输出。
3.1 第一轮MapReduce作业的算法设计
第一轮MapReduce作业的输入为搜索引擎的检索日志文件,读取日志里的每条品牌层面统计结果,在Map阶段按照公式(1)算出该次检索对检索结果集中各品牌的热度贡献值,在Reduce阶段对相同品牌的热度贡献值进行累加。第一轮MapReduce作业的map和reduce函数的具体实现代码如下:
map(LongWritable ikey,Text ivalue,Context context){
String readline = ivalue.toString();
/*取每行的第四个属性(即品牌层面统计),利用空白符进行分割得到一个字符串数组,如读图2第二行则brands数组包含两个元素:”00005:33”和”00028:13”*/
String[] brands = readline.split("\|")[3].split("\s+");
float sum = 0;
/*算出每次检索结果集中商品的总数量,如读图2第二行则sum=46 */
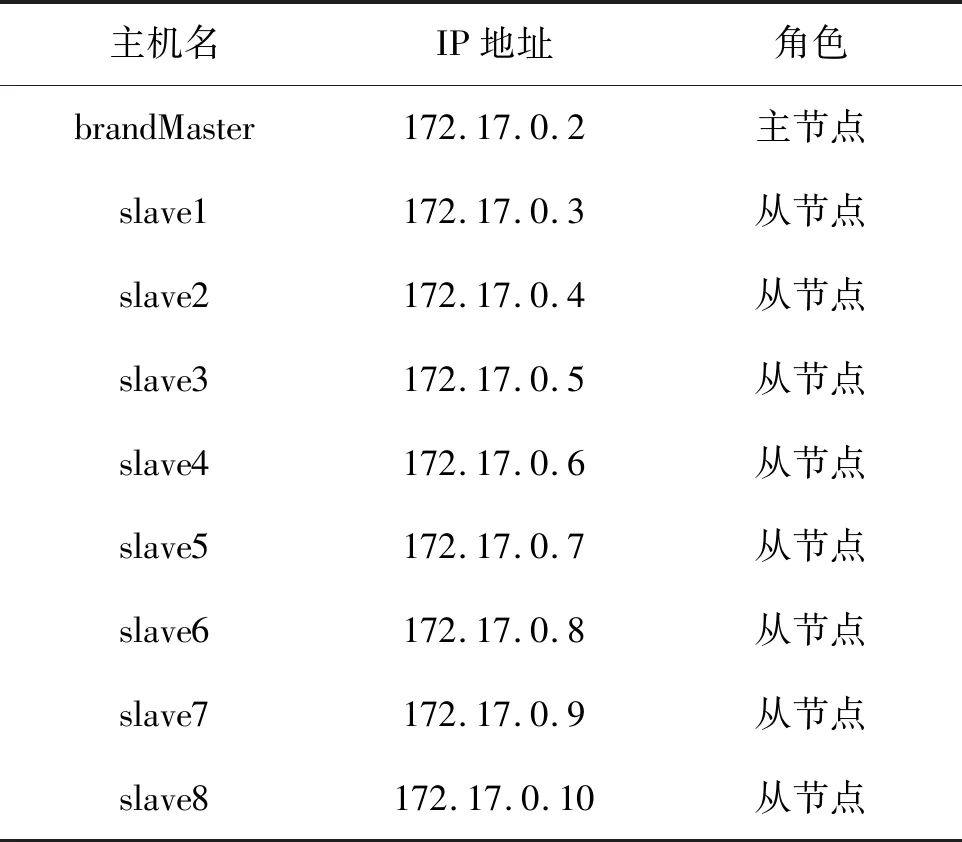
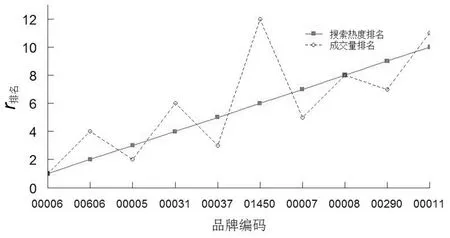
for(int i=0;i { if(brands[i].contains(":")) sum += Float.parseFloat(brands[i].split(":")[1]); else return; } /*算出每次检索对检索结果集中各品牌的热度贡献值,如读图2第二行则输出<”00005”,33/46>,<”00028”,13/46>*/ for(int i=0;i { String[] brand = brands[i].split(":"); context.write(new Text(brand[0]),new FloatWritable(Float.parseFloat(brand[1])/sum)); } } /*reduce函数:接收 reduce(Text _key,Iterable float sum =0; /*对品牌的搜索热度值进行累加*/ for (FloatWritable val :values){ sum += val.get(); } /*输出键值对<品牌编码,搜索热度>*/ context.write(_key,new FloatWritable(sum)); } 第二轮MapReduce作业实现将第一轮作业的输出与品牌字典表的连接操作。因为品牌字典表仅存储品牌编码与品牌名称的映射,其数据集足够小到可以完全放到缓存中,所以这里采用MapReduce提供的复制连接(Replication join)策略。复制连接常用于大数据集与小数据集的连接操作,它是一种Map端连接,省去Shuffle和Reduce的过程,大大降低了作业运行时间。复制连接的基本思路如下: (1)在main方法中调用Job对象的addCacheFile(URI uri)方法将品牌字典表复制到所有运行map任务的节点的缓存中。其中uri为品牌字典表在HDFS上的地址。 (2)在各个map任务的setup方法中调用context.getCacheFiles()从缓存中取出这个品牌字典表,装载到一个哈希表brandMap中。 (3)在map函数中遍历哈希表进行连接操作。 (4)输出结果(即没有Reduce阶段)。 第二轮MapReduce作业的map函数的具体实现代码如下: map(LongWritable ikey,Text ivalue,Context context){ Stringreadline = ivalue.toString(); /*读取第一轮MapReduce作业的输出并用‘ ’分隔得到的数组reads有两个元素,reads[0]表示品牌编码,reads[1]表示搜索热度*/ String[] reads = readline.split(" "); //如品牌编码不在字典表中,则不统计 if(brandMap.get(reads[0])==null)return; kout.set(reads[0]+”|”+brandMap.get(reads[0])); /*输出键值对<品牌编码|品牌名称,搜索热度>*/ context.write(kout,new FloatWritable- (Float.parseFloat(reads[1]))); } 第三轮MapReduce作业实现将第二轮作业的输出按照value(即品牌搜索热度)的值进行降序排序并取TOP-N。因为在Map端的Shuffle过程中会对map函数的输出按照key做升序的默认排序。现要按照value进行排序,所以第三轮MapReduce作业的map函数要实现将key和value互换,即输入 map(LongWritable ikey,Text ivalue,Context context){ String[] reads=ivalue.toString().split(" "); FloatWritable kOut=new FloatWritable(); TextvOuT= new Text(); kOut.set(Float.parseFloat(reads[1])); vOut.set(reads[0]); /*输出键值对<搜索热度,品牌编码|品牌名称>*/ context.write(kOut,vOut); } reduce(FloatWritable _key,Iterable /*输出键值对<品牌编码|品牌名称,搜索热度>*/ for (Text val :values){ //搜索热度值保留两位小数 context.write(val,new FloatWritable- ((float)(Math.round(_key.get()*100))/100)); } } 在上面的reduce函数中是把所有的键值对<品牌编码|品牌名称,搜索热度>都输出到HDFS,当然如果只需输出TOP-N,则可以定义一个变量充当循环变量,在for循环里输出N次即可。 在福建工程学院大数据教学服务器上虚拟化出9个节点,在这9个节点上搭建Hadoop分布式集群。实验放在该集群上运行,集群中每个节点的硬件配置为2核CPU,8G内存,操作系统为Ubuntu 16.04,Hadoop版本为原生的Hadoop 2.7.5,JDK版本为1.8。 集群中每个节点的主机名和IP地址如表2所示。 实验数据采用便利宝电商网站(www.wqblb.com)2018年12月份的检索日志数据,当月的检索日志共有3 327 413条检索记录,日志文件总大小为1 124MB。品牌字典表文件共含7 748条记录,文件大小为124 kB。 图3是分别在3、5、7、9个节点的集群环境下运行完整工作流的响应时间。从图3可以看出在9个节点的集群环境下响应时间只要28.64 s,满足批处理的响应需求。 表2 节点的主机名和IP地址Tab.2 Host name and IP address of node 图3 MapReduce工作流的响应时间Fig.3 Response time of MapReduce workflow 在实验中,设置N为10。获取到搜索热度TOP-10的品牌列表为{00006|康师傅,00606|悦巢,00005|可口可乐,00031|晨光,00037|心心相印,01450|保为康,00007|统一,00008|达利园,00290|伊利,00011|农夫山泉}。为了验证实验计算出的品牌搜索热度排名的准确性,可以和该期间各品牌产生的成交量排名对比,如图4所示。各品牌产生的成交量排名可以通过查询订单明细表,按品牌编码分组统计成交量排名。 从图4可看出,品牌搜索热度排名和成交量排名大致相当。从而验证了从搜索引擎日志里挖掘品牌搜索热度排名榜的可行性。 图4 品牌搜索热度排名和成交量排名对比Fig.4 Comparison of brand search popularing rankings and trading volume rankings 快消品电商网站搜索引擎的检索日志记录着用户的检索偏好,本文根据检索日志里的品牌层面统计结果挖掘出用户每次检索对检索结果集中各品牌的搜索热度的贡献值,设计一个迭代的MapReduce工作流用于计算网站某时间段内的各品牌的搜索热度总值排名,从而可以在网站适当地方向用户推荐热搜品牌。在未来的研究中,将引入Spark技术,以实现热搜品牌的实时个性化推荐。3.2 第二轮MapReduce作业的算法设计
3.3 第三轮MapReduce作业的算法设计
4 实验
4.1 实验环境
4.2 实验数据
4.3 响应时间

4.4 TOP-N分析
5 结语
