基于人工神经网络的鼾声相关信号的分类
2019-10-09侯丽敏刘焕成施晓宇张新鹏
侯丽敏,刘焕成,施晓宇,张新鹏
(上海大学 通信与信息工程学院,上海 200444)
鼾声相关信号的分类是利用鼾声辅助诊断睡眠呼吸暂停低通气综合征(Sleep Apnea Hypopnea Syndrome, SAHS)过程中重要的前端工作[1-3].Lei等[4]对录音的呼吸声和非呼吸声分类中提取了基于频谱相关的特征,结合Mel倒谱系数(Mel-Frequency Cepstral Coefficients, MFCC)特征作为特征集,用支持向量机(Support Vector Machine, SVM)和径向基函数(Radial Basis Function, RBF)神经网络等分类器融合来实现分类.Mlynczak等[5]在手机端运用多层感知机模块对鼾声和呼吸声做分类.Swarnkar等[6]提取包括声音的基频、MFCC和能量等特征用多层感知机对鼾声与非鼾声进行分类.对低信噪比的录音,Emoto等[7]用人工神经网络(Artificial Neural Network, ANN)的方法来区分低信噪比下的鼾声事件和非鼾声事件.Karunajeewa等[8]用最小误差概率决策准则,对包括鼾声、呼吸声和静音的声音片段做分类.Rosenwein等[9]提出了鼾声、呼吸声和噪声的分类系统,构造的声学特征集共351维,用随机森林分类器对鼾声、呼吸声和噪声分类的平均正确率达到91%.
本文提出了基于ANN对鼾声、呼吸声和其他噪声分类的方法.该方法提取每个声音片段的频谱相关特征集作为ANN的输入特征,用小批量训练和Adam学习率自适应等深度学习策略来优化ANN结构的参数,该方法区分鼾声、呼吸声和其他噪声的平均召回率、平均精准率和平均F1值都在95%以上.
1 数据和声学特征
本文的实验数据均来自上海市第六人民医院耳鼻喉科睡眠监测病房里打鼾者的整夜录音.患者鼾声信号的录音与患者做多导睡眠(Polysomnography, PSG)监测诊断同步进行.睡眠记录仪采用伟康Alice 4,录音设备为Dell Inspiration 570,声卡型号为Creative Audigy 4 Value,麦克风为Sony ECM-C10,采样率为16kHz.研究对象为上海市第六人民医院耳鼻喉科提供的接受PSG诊断的受试者.PSG报告给出了受试者的睡眠呼吸暂停低通气指数(Apnea Hypopnea Index, AHI)等相关诊断结果.AHI值(λAHI)表示平均每小时测试者睡眠呼吸暂停低通气事件的次数,单位为次·h-1.λAHI对应着睡眠呼吸暂停低通气综合征的严重程度,可分为4种不同的级别:λAHI<5为单纯打鼾者(Non-SAHS, N),5≤λAHI≤15为轻度SAHS患者(Mild-SAHS,L),15<λAHI≤30为中度SAHS患者(Moderate-SAHS, M),λAHI>30为重度SAHS患者(Severe-SAHS, S).
实验数据包括了不同SAHS级别患者的整夜录音.受测的打鼾者中有单纯型11人,轻度SAHS型11人,中度SAHS型10人,重度SAHS型10人,共计42人.表1是这些受试者的年龄、性别和PSG诊断的AHI值的统计分布,还包括我们从录音中人工切割鼾声和非鼾声片段(包括呼吸声和其他噪声)的数量.鼾声有46517个片段,呼吸声有25357个片段,其他噪声有12966个片段,所有切割的片段数量共计84840个.
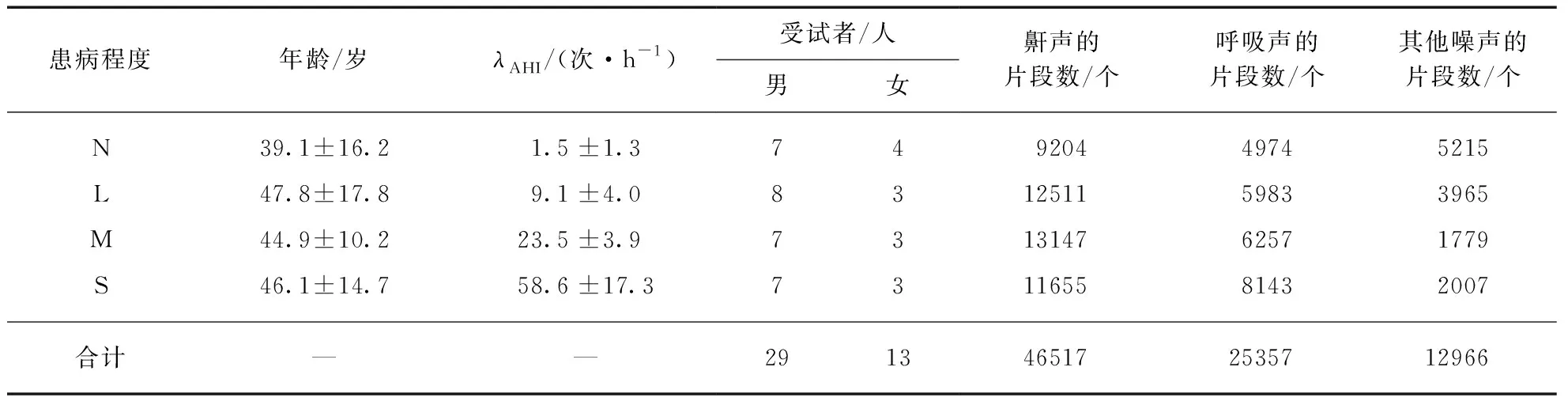
表1 实验数据统计
注: 3类声音的总片段数为84840个.

表2 声学特征集
表1中鼾声的切割方法是用整夜录音的鼾声信号同步PSG标记的鼾声,对准切割出录音的鼾声片段.呼吸声和其他噪声的数据是通过3个工作者主观试听之后切割的.其他噪声包括生物噪声(语音、咳嗽声、闷哼声等)和非生物噪声(音乐声、被子摩擦声、关门声等).
1.1 声学特征集
鼾声、呼吸声和其他噪声在频谱分布上有明显的差异性.为了恰当描述这些差异性,我们对每个声音片段提取了43维的特征集,主要包括4个方面: 频谱能量类相关特征集(Spectral Energy related feature, SE),22维特征[10];基频类相关特征集(Pitch Related feature, PR),3维特征[11];Mel倒谱系数相关特征集(MFCC related feature, MF),2维特征;频谱余弦相似度特征集(Spectral Cosine Similarity feature, SCS),16维特征.表2给出了这些声学特征参数.
1.2 声学特征提取
修正的频谱质心是指对频谱质心计算中的频谱幅度修正为频谱能量,提取所有帧的修正后的频谱质心的均值和差分作为特征.子带能量特征是在频域8000Hz内均匀划分出16个子带,提取16个子带的归一化能量的均值和提取相邻时间段的16个子带能量的差分作为特征.在频谱幅度值包络下归一化面积特征.频谱熵特征是分别从时间方向和频率方向对声谱图计算熵,得到两个熵值.
基频是由声源的周期性振动造成的,是声音信号的最小周期的倒数.现在有倒谱法、线性预测法、自相关法等多种方法计算基频,本文使用自相关法来提取声音的基频,提取声音片段的基频均值、基频方差和基频密度,其中基频密度表示一个声音片段在持续时间内具有基频的比例.
对于Mel倒谱类特征,取MFCC维数为16,计算MFCC0~MFCC16.在此基础上提取动态MFCC距离来描述信号Mel频域的稳定性,MFCC特征子集中只保留第0维系数MFCC0.
频谱余弦相似度(SCS)相关特征集共包括4种余弦相似度的相关特征: 宽度为31.25Hz子带的频率方向频谱余弦相似度(Frequency Detail SCS, FD);宽度为500Hz子带的频率方向频谱余弦相似度(Frequency Overall SCS, FO);宽度为31.25Hz子带的时间方向频谱余弦相似度(Time Detail SCS, TD);宽度为500Hz子带的时间方向频谱余弦相似度(Time Overall SCS, TO).提取每种余弦距离的均值(1阶原点矩)、方差(2阶中心距)、偏度(3阶中心距)和余弦距离的熵作为频谱余弦相似度相关特征集.
2 基于ANN的分类设计
2.1 分类器架构
ANN的每层神经元与下一层神经元全互连,神经元之间不存在同层连接,这种结构通常被称为多层前馈神经网络模型.训练过程可分为前向传播过程和误差反馈传播过程.我们对鼾声及相关信号的分类使用ANN[12],分类流程如图1所示.
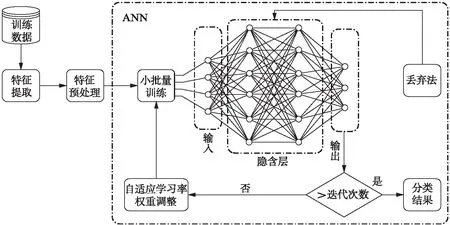
图1 ANN分类训练的流程图Fig.1 The flow chart of ANN classification training
在训练阶段,用表1中数据选取合适的训练数据集,提取特征后对特征进行预处理,利用小批量训练的方式将特征放到ANN中进行训练,在训练过程中运用丢弃法和自适应学习率的策略;在测试阶段,从数据集中选取与训练数据不重叠的测试数据,在提取特征和预处理后放入训练完成的ANN模型中得出测试集的分类结果.选取表1中80%患者的声音片段作为训练数据.
2.2 小批量训练
用整个训练集数据进行训练的方法的梯度估计比任何子集所得到的方差要小,且收敛性好.但这种训练耗资耗时,还可能导致高度依靠参数初始模型,收敛到局部最优,但并非全局最优的情况.对于训练数据,每次选取一定数量的样本放入神经网络中,选取每一次输入样本的代价函数的均值作为代价函数对模型进行收敛.这种方法有助于加快模型训练的速度,并训练出一个更好的模型,称为小批量(minbatch)方法[13].本文使用小批量训练的方法,并结合随机梯度下降(Stochastic Gradient Descent, SGD)法[14].小批量训练会从训练数据中抽出小批量的数据并基于此估计梯度.
我们用取样随机化(sample randomization)的策略保证样本的独立同分布性.每一轮训练时,随机打乱训练集后对索引重新排序,根据排序后的索引数组抽取样本数据.这种做法保证了每一轮次的完整训练中每个样本只用来训练一次,并不会影响数据分布,从而保证学习输出模型的一致性.
目前自适应学习率的算法很多,主要是通过一些策略使得学习率随着训练次数的增加逐步递减,比较流行的有RMSProp(Root Mean Square Prop)和Adam算法[15].这些算法针对不同的网络模型表现出的性能相当.本文采用Adam算法.
2.3 参数优化调试
为保证生成模型的泛化效果,将对全部的训练集重复训练的次数记为迭代轮数,记测试集snore,breath和other的分类错误率的均值为测试集错误率(r错误),将随着迭代轮数测试集错误率的变化结果作为评价模型的标准.调整的方法是: 首先确定一个初始参数模型,在初始模型上,控制其他参数不变,依次调节隐含层层数,隐含层节点个数、学习率、每次迭代选取的样本个数(minbatch)和每层随机丢弃的比例(dropout)[16],最后得到最优化结果.
隐含层的层数多有助于提升模型的表示能力,随着隐含层层数的增加,训练集的拟合效果越来越好.但是一旦模型表示能力过强,则会造成过拟合的后果,与此同时,隐含层层数的增加会增加训练时更多的内存代价,因此需将隐含层的层数调整至合适的层数.图2(a)是不同隐含层训练时的测试集错误率.结果显示,当隐含层为2和3层时,模型收敛最快.隐含层节点个数的调整与隐含层层数一样.图2(b)是不同节点数训练时的测试集错误率.当每层隐含层节点数为80个时,模型收敛速度最快,测试集错误率最低.
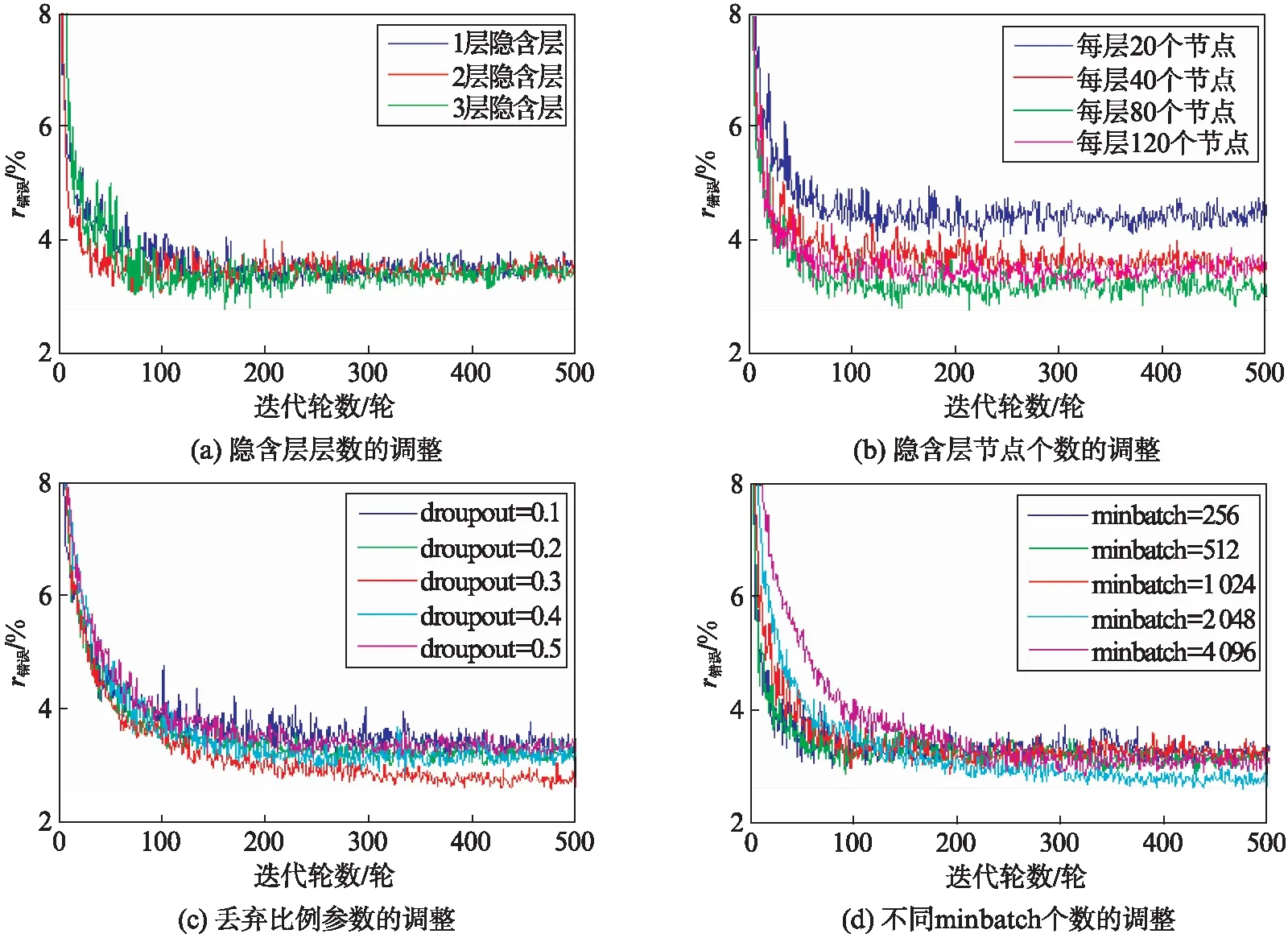
图2 参数调整的迭代图Fig.2 The iteration diagram of parameter adjustment
丢弃法的目的是防止过拟合.由于神经网络模型的复杂性,网络模型往往会对训练集过拟合,故在每一次训练过程中对网络的每一层随机丢弃一定比例的节点不进行激活,而在测试时利用完整的节点进行测试,可以提升模型的泛化效果.图2(c)给出了丢弃比例参数的调整.当丢弃比例为0.3时,测试集错误率最低.图2(d)是不同minbatch个数的测试集错误率.从图中可以发现,当minbatch数量为2048时,测试集错误率最低.学习率和迭代次数等参数优化调节过程与以上参数调试类似,不再一一陈述.
3 结果及讨论
我们切割的各类声音片段的总数如表1所示,分别为46517,25357,12966,按八二比例将它们分为训练集和测试集.划分有3种方案,如表3(@@@534页)所示.第1种保持八二比例的原始数据,显然鼾声、呼吸声和其他噪声片段的数量相差较大,鼾声片段的数量远远大于呼吸声和其他噪声片段的数量.针对这种类别数据不平衡的问题,第2种方案是直接对训练集里的多数类别的样本进行下采样(downsampling),即去除多数类别中多余的样本量,使得各类样本的数量接近.第3种方案是对训练集中的少数类别的样本进行上采样(upsampling),即增加一些少数样本的数量,使得各类样本的数量接近.第3种方案对于训练集中样本数量较少的呼吸声和其他噪声片段,通过加入白噪声的方式,合成新的信噪比为20dB的“呼吸声”和“其他噪声”加入训练集的对应类别中,使得训练集的呼吸声与其他噪声片段同鼾声片段的数量一样.3个方案中测试集相同.本文分别对训练集进行下采样和上采样处理以解决类别不平衡问题.详细数据见表3.
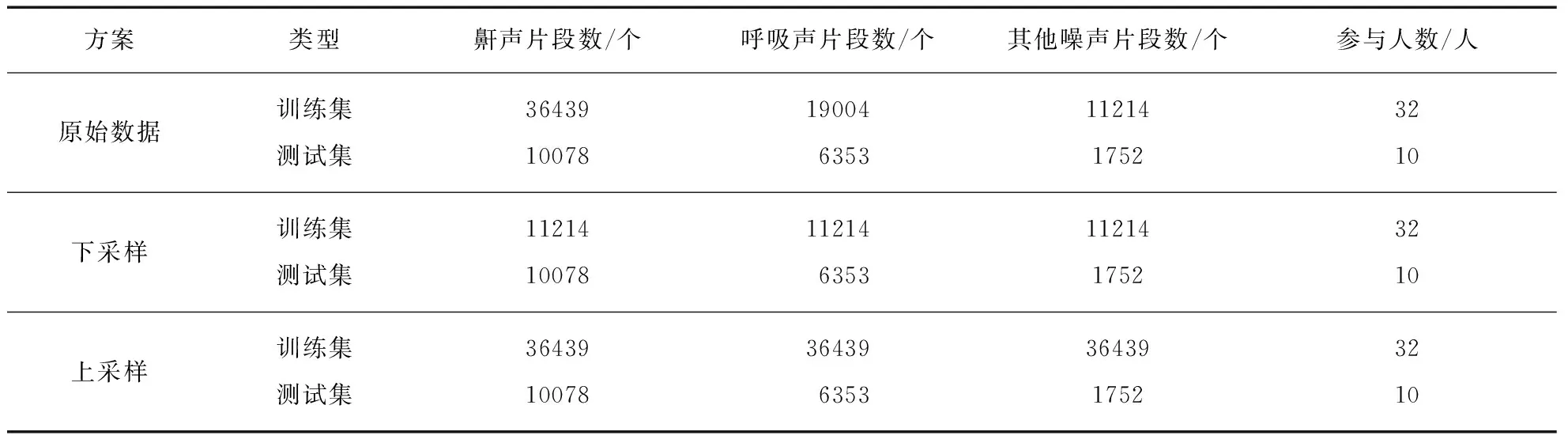
表3 训练集和测试集的设置方案
对第1种方案,通过类似代价敏感学习的方式,训练时,提升少数类别损失在整体代价函数中的权重,使得分类效果相对平衡.利用图1设计的模型,对3种方案分别做了测试.我们用召回率(recall rate)R,精准率(precision)P和F1值等指标作为测试的结果,如图3所示.对鼾声和呼吸声测试的R,P和F1值均达到了98%以上,而对其他噪声测试的结果略弱一些,R,P和F1值在89%~95%之间.原因可能在分类的对象上: 鼾声和呼吸声自身的泛化效果较好,声音差别不大,共性多,较容易训练;而其他噪声本身内部的声学特征有较大差异,而且数据量相对较少.
使用下采样或上采样数据量均衡方式对部分指标的正确率有所帮助.下采样中R最高,达到99.7%,但P却最低,为89%.上采样方式的效果最为稳定,无论是R,P还是F1值都有较高的正确率,对其他噪声进行判断得到的R,P和F1值均达到最大,分别为93.09%,93.04%和93.07%.从模型的稳定性来看,使用上采样方式的结果总体上要优于使用下采样的结果.
使用原始数据、下采样和上采样3种方案的平均R分别为96.61%,97.04%和96.80%;平均P分别为96.35%,95.45%和96.72%;平均F1值均在96%.从模型的均衡性的角度来看,训练数据越多越好.下采样由于削弱了训练数据量,使得R与P之间难以保持一致.而上采样用合成新的声音的方式对训练集中样本量少的类别加大数量来提升其丰富性的方法有一定的作用,所以,上采样的方案对提升整体分类效果较为明显.
由于鼾声和呼吸声的数据量相对其他噪声的要多,这种数据数量的不平衡易导致哪类的数据量越大,哪类的区分效果就越好.因此,不平衡的数据以及小数据量如何更好地用在人工神经网络上,这是未来我们要深入研究的问题.
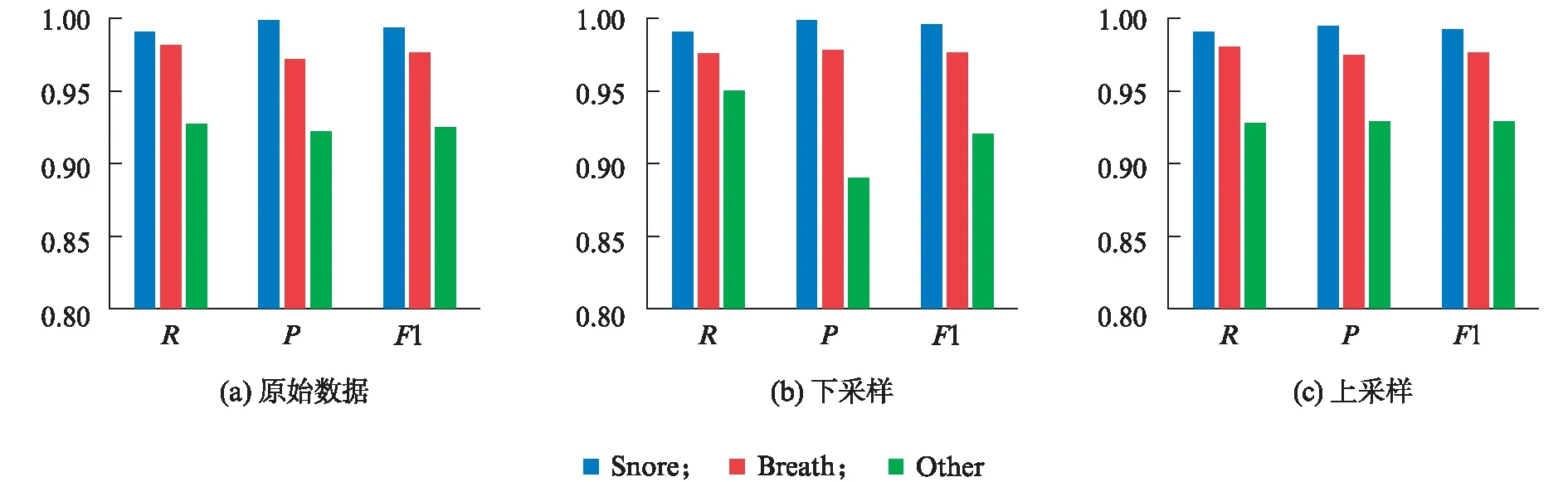
图3 3种测试方案的召回率、精准率和F1值的结果Fig.3 Results of recall rate, precision and F1 value for three test schemes
4 结 语
本文提出了利用ANN对鼾声、呼吸声和其他噪声进行分类的方法.设计了小批量训练与梯度下降结合的方案,采用随机丢弃法和自适应学习率的策略,分别通过下采样、上采样和直接使用原始训练集等方式对分类器进行了训练,均获得较好的分类效果,其中上采样方式训练得到的模型最优.本文方法对鼾声、呼吸声与其他噪声能实现有效的分类.
致谢:感谢上海第六人民医院耳鼻喉科的医生和护士们对鼾声数据采集的大力支持和帮助.
