面向海量目标源代码数据比对样本的源代码特征值提取算法
2019-10-09刘帅
文/刘帅
最近几年随着开源软件项目的数量与质量的不断提升,越来越多的企业也开始倾向于采取开源方案构建自己的软件系统。但在使用开源软件项目的源代码过程中,企业也隐性地承担了因为软件项目管理不善、程序员使用不当等因素所引入的由开源软件许可证所带来的法律风险。因此,对源代码进行同源性检测,让软件企业了解其软件代码中包含的开源代码成分,并分析这些开源代码可能带来的问题(知识产权风险、安全漏洞风险等)是目前规避上述风险的主要手段。然而,对于完成上述目标的代码同源性检测将面临着巨大的技术挑战——不仅需要解决如何在海量的开源项目中提取并存储用于比对的源代码样本数据信息,而且还需要达到快速、准确地完成针对被比对软件源代码组成成分的检测任务。为解决以上问题,本文将介绍一种面向海量目标源代码数据比对样本的源代码特征值提取算法,能够基本满足在存储容量与检测准确度、效率上的对于源代码同源性检测的要求。本文中采用了Java语言的开源项目及其源代码作为主要研究对象,既具有代表性,同时也兼顾了实际应用价值。
1 已有源代码同源性检测技术
1.1 基于文本的方法
将代码直接进行文本或字符串比较。将程序代码当做文本进行分析,利用字符串匹配算法将代码划分为一系列子串,然后对每个子串进行哈希运算,并筛选出部分哈希值作为程序指纹。
1.2 基于词法的方法
对源代码进行词法分析,将源代码按照某种粒度转化成Token序列,通过检测Token序列中的重复序列来判定代码克隆。这类方法的关键在于Token的提取和比较算法的设计, 筛选的Token特征应当能够应对代码混淆,不能被简单混淆破坏掉。
1.3 基于语法的方法
分为基于树的方法和基于度量的方法。基于树的方法将代码变换为AST,并利用树匹配算法对子树进行检测,但是树的创建和比较具有较高的时空复杂度,因此代码搜索效率较低,这种子树搜索或节点间匹配的方法难以应对代码重排及控制流混淆。因此,后续很多研究是将AST转换成Token序列或字符串来处理。
1.4 基于代码特征值方法
在面向海量目标源代码数据比对样本的问题下,由BlackDuck提出了codeprint的概念,其采用纯文本方案计算代码特征值,不仅实现了快速检索,而且在一定程度上解决了对代码进行修改导致精度失效的问题,但纯文本提取方案在故意修改源代码的情况下会导致相似度分析准确性不足,而且如果采用较细粒度来提取特征值将耗费比较大的存储空间。另外,有一种将AST后缀树各子节点作为特征值提取依据的算法,大幅度提升了对于故意修改源代码进行相似度分析的准确性,但很难将一颗完整AST后缀树的所有子节点的结构进行哈希计算后进行存储。
2 核心算法设计
从上一章节可以看出当前没有完全倾向于面向海量目标源代码比对样本的同源性检测技术,因此,本文提出了一种源代码特征值提取算法,通过该算法能够对样本代码进行切片后的特征值计算,提取后的特征值能够基本满足在存储容量与检测准确度、效率上的要求。算法基于AST,其核心思路是将AST转换为纯文本内容,再将特征值的提取问题简化为处理海量文本去重的问题上来。下面将对每个算法步骤的具体实现进行详细说明:
2.1 消除代码噪音步骤
该步骤实现识别并剔除代码中的噪声内容。有一些代码噪声很容易被有意的添加在代码片段中用于干扰检查结果,造成基于文本或Token方法的源代码同源性检测结果精度降低,如对目标源码中夹杂一些无用的声明。通过该过程将一些人为混入源代码中的无用代码片段过滤掉,从而达到消除噪音的目的。
2.2 代码切片步骤

图1:Token替代效果示意图

图2:结构属性多级聚类排序处理效果示意图
代码切片的目的是为了对源代码选取一个合适的切分粒度,得到一系列的切片,最终为每个切片计算特征值,以细化比较的粒度,从而更加有效的进行检索和分析。本算法采用以方法为粒度进行源代码的切片处理。
2.3 Token替代步骤
借鉴成熟的Token替代方案,将通过对AST进行分级处理后的各节点结构体相关内容进行结构信息Token符号替代,将参数、变量等名称按结构信息相关规则使用Token符号进行代替,以实现Token化,从而消除“人为修改类、变量、方法等名称但保持代码逻辑”的干扰情况。Token替代算法的主要思想是利用AST对每个参数、变量在操作符两端出现的次数以及在关键Block节点出现的次数进行统计,并根据统计信息合成其Token化后的名称,处理后的效果如图1所示。
2.4 结构属性多级聚类排序处理步骤
每一个AST方法节点都是一棵子语法树,筛选其AST各节点单元结构属性,根据排序策略,完成多级聚类排序处理,从而在打乱代码部分行顺序但实现相同逻辑的情况下,可以尽量得到一个相同的结果,整个算法过程可以简单地视为一个对所有Method子语法树下Block节点语法树内各个节点结构属性的聚类后排序处理,并存储为对应的Struct结构体对象的过程。处理后的效果如图2所示。
2.5 特征值计算步骤
特征值计算将主要采用Simhash算法,并在加权计算方面加以改造。Simhash是Google用来处理海量文本去重的算法,可以得到局部敏感的代码特征值。根据对普遍的Method节点层数及计算后准确性的验证,哈希值长度选取128位,权重一般可考虑取Method节点的基数权重为10,子节点为父节点的70%,依次计算。经过大量实验,当海明距离小于20时,代码相似度较高,可参考以下相似度查询表(如表1所示)。

表1:相似度查询表
3 检测系统设计
如图3所示,开源项目元数据采集系统完成从开源社区采集源代码、元数据及许可证等数据信息,实时对所获取数据进行处理分类,进行代码特征值的分析与提取,并进行持久化存储,为同源性检测提供必要的检索素材与条件。代码同源性检测系统完成对待检测源代码的代码组成成分与许可证风险进行检查。通过对目标源代码的特征值和分组信息的提取完成对海量代码特征值库的检索。
4 测试结果与分析
本次测试中使用从Github开源社区上下载的开源代码进行算法的测试,测试内容主要分为两部分,以验证算法可以基本满足面向海量目标源代码数据比对样本场景下的代码同源性检测需求。
4.1 准确性验证测试
随机选择一个Github开源项目Tron(https://github.com/tronprotocol/javatron),将其包org.tron.common.storage中的DepositImpl.java源代码文件中的getStorage方法作为本次准确性验证的基准源代码样本。与基于文本的三种比对工具Beyond Compare、WinMerge和TextDiff进行比对,可以看到本算法的准确性较高,结果如表2所示。

表2:相似度检测结果比对表
4.2 存储容量验证测试
同样使用Tron项目,将本算法在提取特征值以及检索必要信息后的存储容量同源文件与文本特征值提取算法进行比较,可以看到本算法所占的存储容量相对较小,如图4所示。
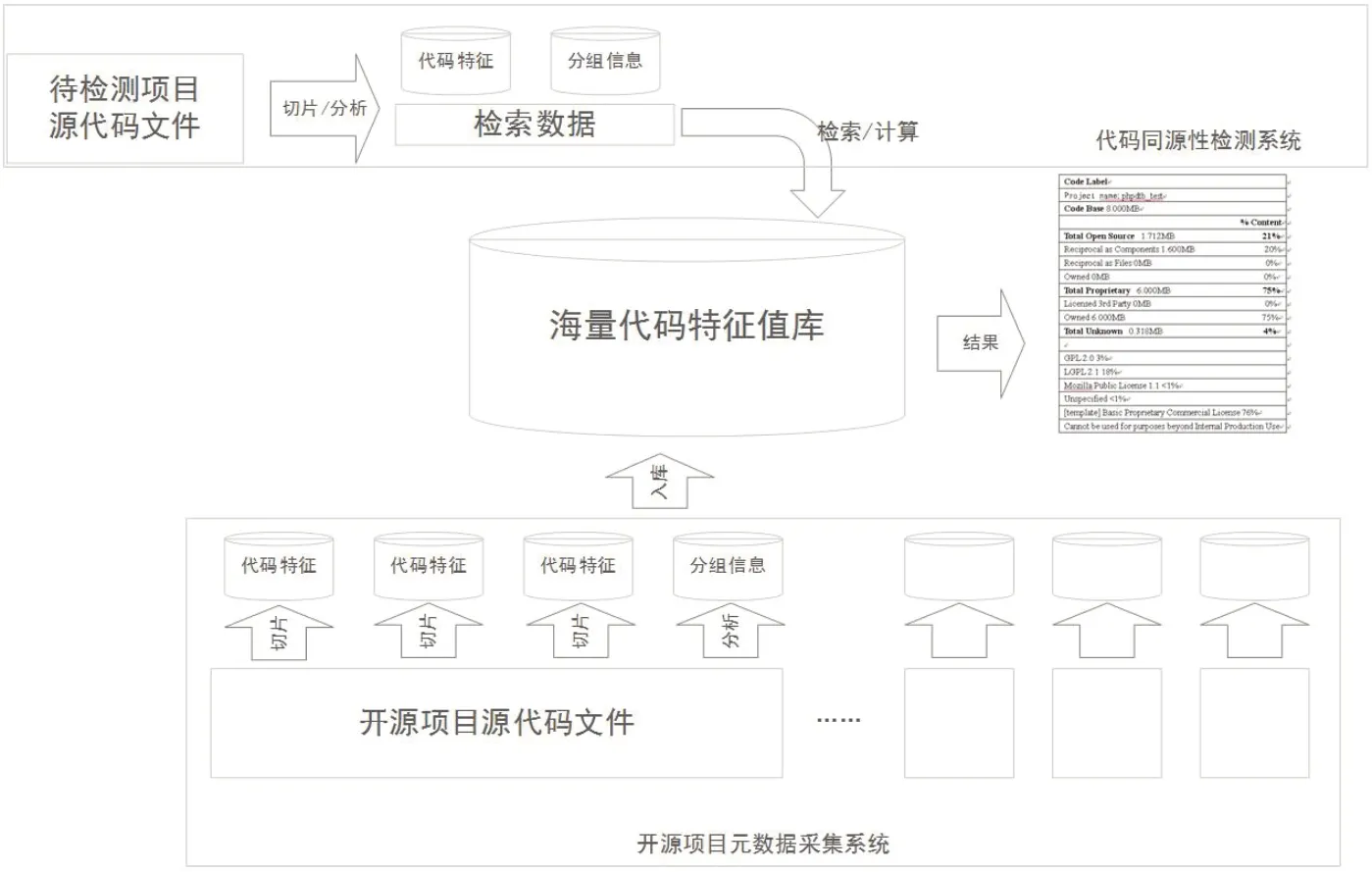
图3:检测系统设计图
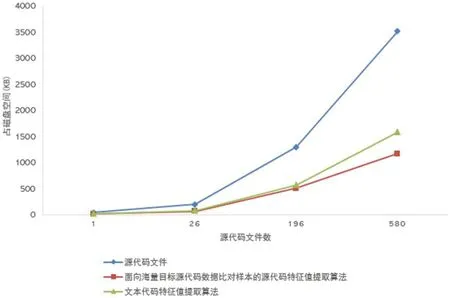
图4:存储容量对比图
5 结束语
本文提出了一种源代码特征值提取算法来满足面向海量目标源代码数据比对样本场景下的同源性检测需求,在此基础上对检测系统进行了设计,并使用该算法对构造的各种抄袭类型进行检测并同工具检测与其他算法结果进行比较,证明本算法可以应用到真实环境中并具有一定的使用价值。
