直播平台弹幕信息智能分析与识别系统设计与实现
2019-10-08文淑华曹议丹王瑞锦房翊翔卢学能
文淑华,曹议丹,王瑞锦,房翊翔,卢学能,杨 珊,易 黎,张 翔
(电子科技大学 信息与软件工程学院,四川 成都 610054)
电子科技大学信息与软件工程学院的综合课程设计III针对高年级学生开设,要求学生在学习相关课程后参与一个具有一定难度的小型软件工程项目,利用软件工程的思想完成整个项目周期的所有阶段,并能对结果进行预测和模拟。为了培养学生综合设计能力和创新能力,将“直播平台弹幕信息智能分析与识别系统”设计作为综合课程设计III的课题,旨在培养学生使用软件的工程思想。采用爬虫算法、机器学习、自然语言处理和 Web应用编程技术,培养学生综合设计和实现一个完整系统的能力,为学生的课题执行提供指导。
1 课题背景和研究意义
直播平台要想获得长足发展,需不断升级专业内容制作能力,提高用户体验感,其中在弹幕不良信息识别中大有可为。直播平台弹幕信息智能分析与识别系统面向直播平台,直播平台的管理人员可通过该系统获得各大著名直播平台的弹幕数据,反馈这些弹幕信息中的不良信息(广告、虚假信息、情色信息等)及弹幕发出者名单,帮助直播平台改善直播体验。
基于当今热门的机器学习、LDA模型[1-3]等自然语言处理技术、基于Taf RPC协议与Websocket协议的爬虫算法[4-5],并使用负载均衡策略的 B/S网络架构、基于 Web设计与实现直播弹幕不良信息识别系统,全面培养学生根据软件系统的应用场景,选择合适的开发环境、工具与技术标准进行软件系统的设计和开发,培养学生解决复杂软件工程问题的能力和创新意识,符合综合课程设计III的要求。
2 系统总体设计
用户登录直播平台弹幕信息智能分析系统后可以选择对某个平台的房间进行一定时间的弹幕的爬取及分析,通过在网页中输入房间号及弹幕来源(斗鱼或虎牙)进行弹幕数据及分析。用户提交输入后,前端获取数据值,根据选择的弹幕来源将值通过ajax传递给后端,后端调用爬虫算法对房间进行爬虫后调用信息识别算法,前端将结果进行处理后进行呈现,用户可以在网页上看到对应房间里爬取的实时弹幕数据,以及这些数据里的不良信息和不良信息对应分类、经常发送不良信息的 ID统计。另外,用户还可以看到自己选择爬虫的历史信息。系统的功能架构见图1。
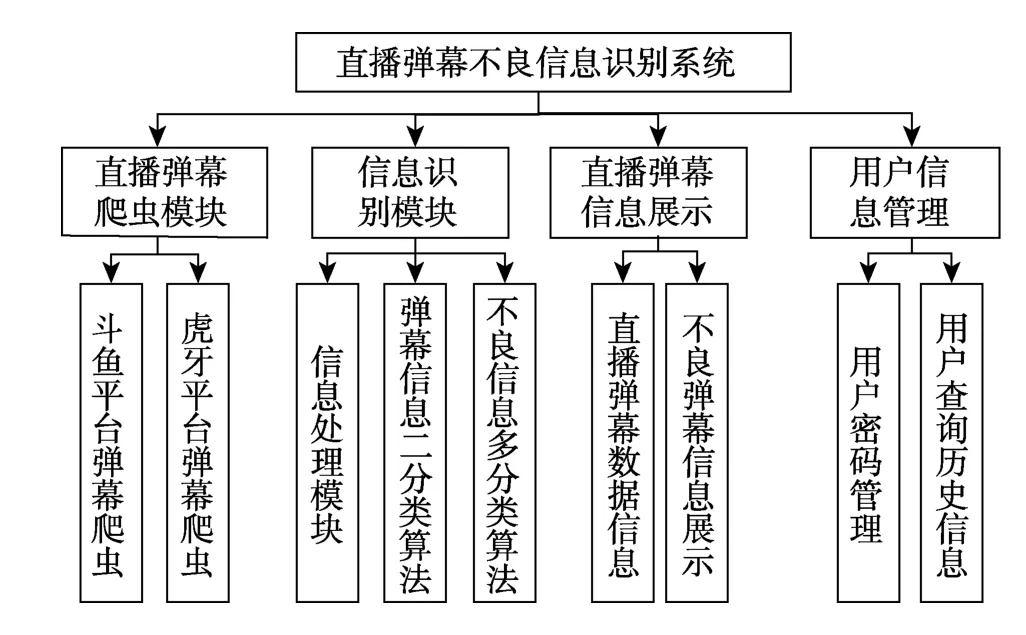
图1 直播平台弹幕信息智能分析系统架构框图
3 核心技术设计
直播平台弹幕信息智能分析系统中主要功能模块为直播弹幕爬虫模块、信息识别模块等,主要技术为爬虫算法、机器学习算法、自然语言处理算法技术。
3.1 直播平台弹幕爬虫的设计
直播平台的弹幕数据是实时的,不像传统的视频网站(如B站)是将弹幕存在一个XML文件里面发送给客户端,所以需要与弹幕服务器连接。使用Python Socket的连接方法,并且由于弹幕协议是建立在TCP长连接服务上的,为了管理这些长连接,保证及时销毁无用的连接以及释放资源服务于有需要的用户,直播平台后台需要与客户端保持心跳,每隔一段时间客户端需要向服务端发送一条心跳信息以保证其对应连接的后续可用性。心跳信息就是在客户端或服务器间定时向通信的另一方发送自己当前状态的一个自己定义的命令,以某个时间间隔发送,类似于心跳。
3.1.1 Wireshark结合虎牙前端源码爬虫的设计。
由于虎牙没有提供API,对于虎牙的爬虫可以先获取直播状态,然后获取弹幕服务器地址与房间信息,之后开启Socket连接并认证,最后持续发送心跳包和接受弹幕信息。
(1)寻找WebSocket地址。使用Chrome浏览器查看网页WebSocket连接,并通过二进制帧流初步猜测4条弹幕服务器地址,虎牙前端会选择其中一条。因为是二进制帧,消息很有可能经过加密或者编码,然而弹幕并没有加密的必要,而且计算速度较快的对称加密技术也会增加服务器负担和复杂度。于是猜测为某种RPC编码协议,遂直接使用Websocket抓包查看帧结构和数据。通过抓包分析结构,发现有意义的ASCII字符,说明这不是加密,而是某一种通信结构体的编码。
(2)分析源码进行解析。通过开发者工具的Performance工具开始记录前端事件并查看日志。得到数个关键函数调用的堆栈,通过不断调试初步得出函数调用流程和弹幕获取,以及解码的流程,然后使用TAF对消息体进行解析。
3.1.2 斗鱼爬虫模块设计
斗鱼提供 API,可以根据其应用层协议,构造请求报文和数据,进行登录和连接,也可以根据其文档协议解析响应报文,较为方便。斗鱼后台协议头见图2。

图2 斗鱼后台协议头
3.2 基于自然语言处理及机器学习的弹幕信息识别
3.2.1 弹幕信息数据处理
弹幕信息是中文文本。对文本进行有效识别,需要使用自然语言处理[6-7]中一些方法对文本数据进行相关处理,从中提取出有效信息,进行模型训练。
目前的分类算法要求特征都是相对独立的,因此为了切断上下文耦合,降低词序的影响,实现特征的相对独立性,对获取的文本信息进行分词。但是,从直播平台获取的数据信息中存在许多表情符号,会影响分词的效果,在分词前先进行分词的粗处理。在结束分词后,为保证特征提取有效性,对分词后数据做去停用词处理。
3.2.2 基于 SVM 和朴素贝叶斯算法的不良信息和良性信息分类算法设计
对于良性信息和不良信息分类时,首先尝试直接对数据进行无监督二分类后,发现效果并不明显。为了进行不良信息识别、保证识别的准确,采用对获取的弹幕信息进行监督学习二分类,对于二分类得到的不良信息再使用分类方法进行分类。二分类常用算法有logistics回归、SVM[8-9]、朴素贝叶斯[10-11]。logistics回归算法更依赖于特征的提取,需要特征量大。SVM可以解决小样本下机器学习的问题、模型的泛化性能高。朴素贝叶斯算法常用于文本的二分类算法,在监督式学习的样本集中能获得非常好的分类效果。综合考虑,采用 SVM 和朴素贝叶斯进行分类,在比较两种算法的精确度后选择精确度高的算法。
3.2.3 基于 LDA模型和 LSI模型的不良信息多分类算法设计
本课题目标是实现不良信息包括广告、虚假信息以及情色信息识别,是对文本的多分类。LDA模型是一种无监督的贝叶斯模型,是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。由于 LDA是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量即可,是一种典型的词袋模型。LSI模型[12]是一种简单实用的主题模型,基于奇异值分解(SVD)的方法来得到文本的主题。LSI的基本思想是文本中的词与词之间存在着某种语义关系,通过对样本数据的统计分析,让计算机发掘出这些潜在的语义关系,并把这些语义关系表示成计算机可用的模型。LSI可以消除词匹配过程中的同义和多义现象,可以将传统的 VSM 压缩到一个低维的语义空间中,在该语义空间中计算文档的相似度等。换句话说,LSI模型利用词语间潜在的语义关系实现对 VSM 模型的降维,进而达到提高分类效果的目的。
4 核心技术实现
4.1 Wireshark结合虎牙前端源码爬虫的实现
通过WireShark来抓哪一个是申请包。通过弹幕流推送,开始网上找本机的发包,找到一条可疑的包,如图3所示。
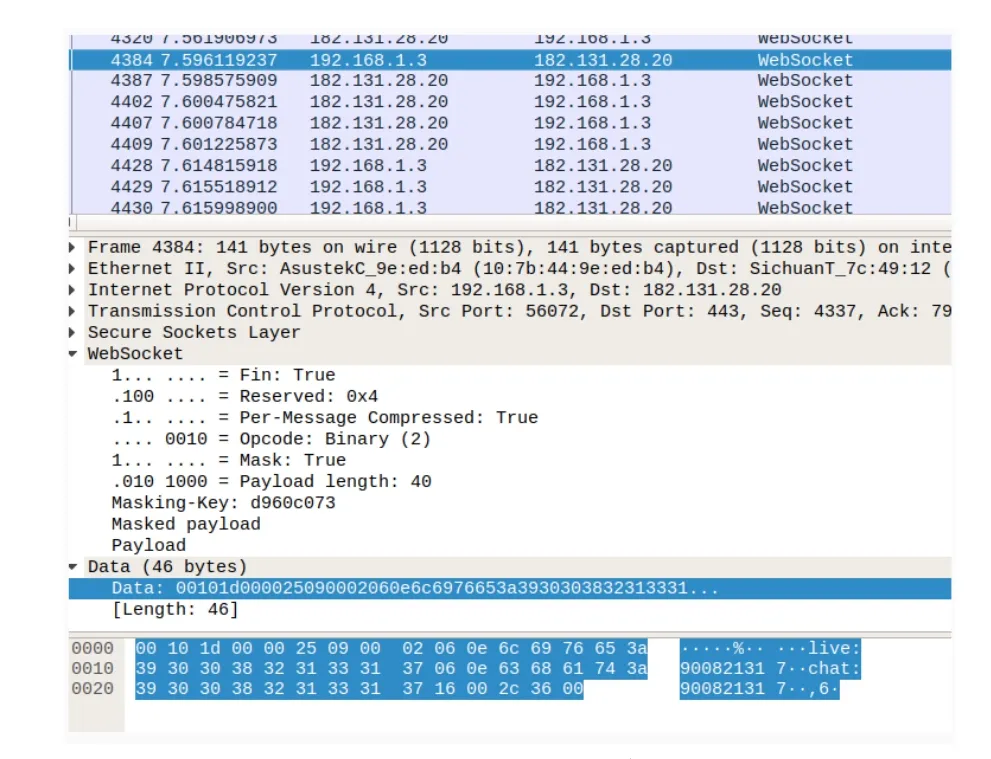
图3 Wireshark抓包结果
根据 Wireshark抓包结果分析虎牙弹幕源码,发现sRegisterGroupReq结构体就是弹幕数据信息所在,把该结构体解析后重新封装一下,关键代码是:wsRegisterGroupReq.vGroupId这个数组里面的值,往里面添加"chat:" + presenterUid一个字符串即可。关键代码如下:

4.2 斗鱼爬虫的实现
斗鱼平台由官方提供给第三方、使用Socket而非WebSocket的弹幕平台和协议,这样不必要抓包以及分析,直接参照文档构建。发送指定的申请包和心跳包,即可收到弹幕,图4为斗鱼爬虫流程图。

图4 斗鱼爬虫流程图
4.3 弹幕信息识别算法实现
使用训练数据进行 SVM模型训练,核函数选择linear,对训练完的模型进行如下精确度计算:
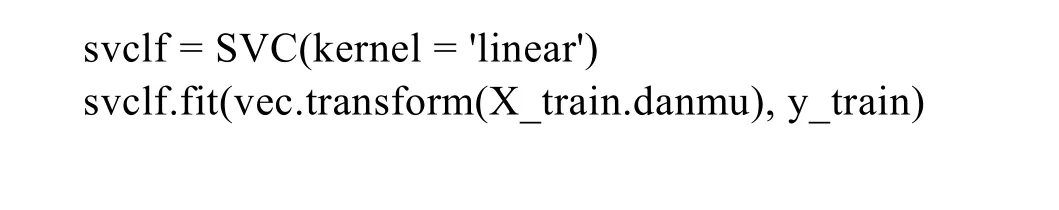

LSI模型在训练前需要计算tf-idf。tf-idf是一种统计方法,用以评估一字/词对于一个文件集或一个语料库中的其中一份文件的重要程度。字/词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。根据 tf-idf数据训练LSI模型如下:

5 实现效果
实验仿真和实际测试表明,本系统能成功实现账号的注册、登录,并实现直播平台弹幕信息智能分析与识别,通过依据弹幕流设计的爬虫算法对各大著名直播平台直播弹幕信息进行实时监测,基于 SVM 模型以及 LDA模型等自然语言处理技术实现弹幕的全方面不良信息识别。图5为管理员登录该系统后对虎牙平台主播 UZI直播房间弹幕爬虫的结果,分别展示了弹幕信息,及爬取的不良信息。
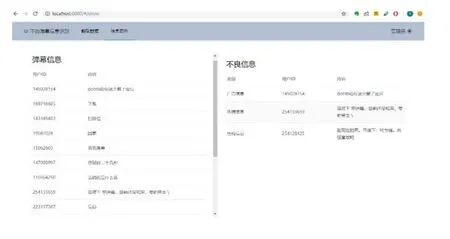
图5 直播平台弹幕信息智能分析结果展示
6 结语
该综合设计课题能培养学生使用爬虫技术、机器学习、自然语言处理等技术综合设计与实现系统的能力,符合综合课程设计III的毕业要求。
