深度学习在汉语语义分析的应用与发展趋势
2019-09-28王睿怡罗森林吴舟婷潘丽敏
王睿怡,罗森林,吴舟婷,潘丽敏
(北京理工大学 信息系统及安全对抗实验中心,北京 100081)
0 引 言
人工智能的发展可分为感知智能和认知智能两个阶段。近年来,随着大数据技术和以深度学习为代表的机器学习技术的迅猛发展,人工智能在感知智能阶段进展飞速,在图像识别、语音识别等任务中均可达到人类专家的水平。然而,在认知智能阶段,尤其是在自然语言理解方面的发展仍较为有限。与人类丰富的语言经验、语言知识储备相比,仅仅依靠基于数据驱动的深度学习很难产生真正的智能。为了打破深度学习的性能瓶颈,尝试进行语义分析与深度学习模型的结合,将成为人工智能在认知功能方面的下一个突破口。
为了将语言知识运用到机器学习的算法当中,首先需要将现有的语言知识量化为可直接与计算机应用相结合的量化模型,即开展语义体系、语义知识库构建等工作。研究者借鉴国外的经典语义理论,结合汉语自身的语义学基础,研究出适合中文的汉语语义体系。汉语语义知识库是通过利用汉语语义体系对原始语料库的加工、以形式化结构来描述汉语语言的一种语义资源库。例如,董振东的知网(HowNet)、袁毓林的论元系统、起源于格语法的谓词-论元结构、汉语语义依存分析和汉语句义结构分析等。
汉语语义分析是从海量的中文文本信息中挖掘语义信息,以此提供智能的知识服务。研究者选取特定的汉语语料、结合语义体系的标注规则来完成相应汉语语义知识库的构建工作,并结合统计知识进行汉语语义自动分析。早期,汉语语义分析遵循传统机器学习的步骤,即进行特征构建、特征抽取、特征选择和传统机器学习模型的训练。随着训练数据量的增大以及计算机计算能力的提高,研究者发现深度学习模型可以从大量原始数据自动提取构建特征,而不需要进行特征工程,并在特定领域任务中有很好的效果。因此,研究者开始尝试将深度学习模型应用到汉语语义自动分析的研究上,利用深度学习模型来自动提取有效的特征,从而完成汉语语义自动分析任务。
虽然目前深度学习模型在自然语言处理的多个任务中取得了不错的效果,但是深度学习模型的不可解释性以及缺乏标签数据的问题也一直无法得到解决。在深度学习模型中融合语义分析的基础研究,能够为任务提供更深层的语义先验信息,增强深度学习模型的可解释性和泛化性,让机器更好地理解人的语言,为人类提供更智能的服务。因此,研究者对在深度学习模型中融合先验语义信息、提高深度学习模型可解释性做了很多新的尝试,将融合多元知识库应用在深度学习模型中,为解决分析系统的可扩展性进行很多新的探索。
文中将按照汉语语义分析发展的主线,概要介绍汉语语义分析中的语义体系及其对应的语义知识库,重点阐述汉语语义分析的自动分析方法的研究情况,并介绍融合先验语义信息的深度学习模型的应用研究,最后对汉语语义分析存在的问题和发展进行分析和展望。
1 汉语语义知识库
研究者对汉语语义结构进行研究,得到各具特点的汉语语义体系,并希望通过这些语义体系制定的规则,将汉语的语义转换成计算机可处理的结构化信息。计算机想要通过这些结构化的语义信息学习到语义体系的规则,就需要通过统计学习的方法、利用大量的语义知识库来实现。因此,汉语语义体系的研究和语义知识库的构建至关重要。不少研究者一直致力于这两方面的研究,并获得了可喜的成果。例如,董振东开发的知网、袁毓林构建的中文网库、山西大学创建的汉语框架语义网库(Chinese FrameNet,CFN)、美国宾州夕法尼亚大学建立的中文命题库(Chinese proposition bank,CPB)、哈尔滨工业大学的语义依存树库和北京理工大学的汉语句义结构标注语料库(Beijing forest studio-chinese tagged corpus,BFS-CTC)。下面将对这些基于相应语义体系建立的汉语语义知识库进行介绍,其中汉语语义知识库对比分析如表1所示。
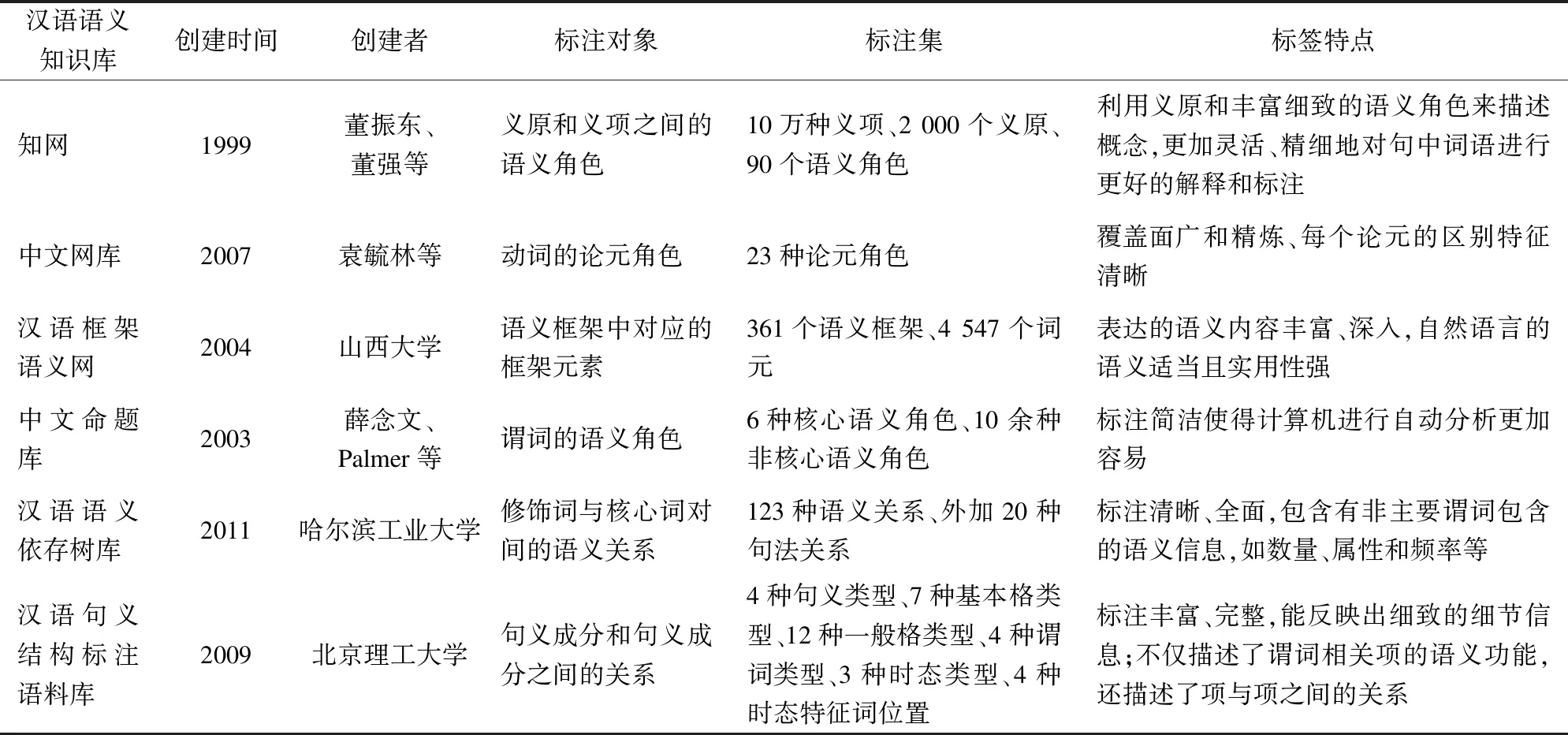
表1 汉语语义知识库对比分析
1.1 知 网
知网是董振东和董强组织建立的常识知识库。采用《分类体系》、《事件角色与典型演员》、《对义表》和《公理关系与角色转换》等多种理论作为它的理论基础。它的基本思想是以汉语和英语的词语所代表的概念为描述对象,并且揭示概念与概念之间以及概念所具有的属性之间的关系。知网利用义原和丰富细致的语义角色来描述概念,可以更加灵活精细地对句子中的词语进行解释和标注。然而,知网仅依赖单个词语的语义知识,没有考虑词语相互之间的关系。同时,标注过程不是在句法分析的基础上进行的,因而标注结果缺少句法关系的信息。
1.2 中文网库
中文网库是北京大学袁毓林教授在北大汉语句法分析树库的基础上,对新闻语义真实文本进行论元角色标注的语料库。采用国内外的论元结构理论、生成语法、格语法和配价语法作为构建该语料库的理论基础。袁毓林总共定义了23种论元角色,并根据这些论元角色提出对应的层级关系,如图1所示。与知网相比,中文网库的标注过程是在句法分析的基础上进行的,给标注结果增加了一定的句法信息;但由于中文网库只标注句法成分上标定动词的论元角色,因此对句子的语义分析结果缺少一定的完整性。
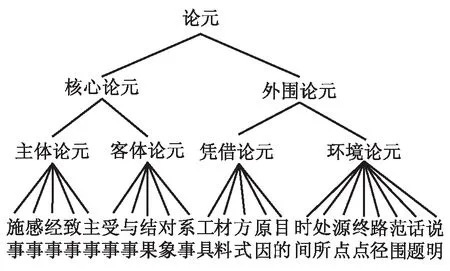
图1 汉语动词论元角色的层级关系
1.3 汉语框架语义网
汉语框架语义网是由山西大学在2004年开始建立的、架构参照了英文框架网(FrameNet)的汉语词汇语义数据库。采用Fillmore的框架语义理论为其数据库构建的理论基础。该数据库用框架来描述词义、句子意义和文本含义,其中框架中的框架元素类似于语义角色。汉语框架样例如表2所示。汉语框架语义网的优点在于将框架与框架之间的关系展示出来,使语义的表达层次更加丰富,同时,框架元素表达的语义内容深入和实用性强。但是,汉语框架语义网对语义的刻画过于细致,给计算机完成框架元素的自动分析增加了难度。
1.4 中文命题库
中文命题库是薛念文和Palmer等基于“谓词-项”论元结构、参照英文命题库(proposion bank,PB)在宾州中文树库(Penn Chinese treebank,PCT)的句法分析树的基础上进行语义角色标注的语料库。中文命题库中一个句子的标注实例如图2所示。中文命题库的优点在于简洁的标注使得计算机进行自动分析更加容易。同时,它考虑了名词也可以作为谓词的情况,在一定程度上克服了论元结构仅以动词作为考察对象的缺点。但是,中文命题库只使用数个标记来表示语义角色,标记没有清晰的语义信息,使得语义角色不够丰富和统一,并且在标记时容易造成混淆。

表2 汉语框架样例
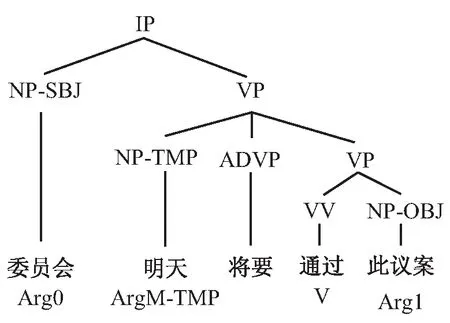
图2 中文命题库中一个句子的标注实例
1.5 汉语语义依存树库
汉语语义依存树库是由哈尔滨工业大学的研究者们采用依存语义分析构建的能够完整地对句子语义进行分析的语义知识库。2011年,哈工大社会计算与信息检索研究中心与北京语言大学合作推出了一套依存语义体系——HIT语义依存。该体系是以依存分析为基础,将知网的语义框架与袁毓林、鲁川的语义体系相结合。汉语语义依存树库就是利用这套体系完成句子的标注,对句子进行深层的语义分析,从而更好地表达句子的结构信息和语义信息。
1.6 汉语句义结构标注语料库
汉语句义结构标注语料库是北京理工大学信息安全与对抗技术实验室根据句义结构模型(Chinese sentential semantic model,CSM)构建的语料库。汉语句义结构模型以中文语言学家贾彦德提出的《汉语语义学》为理论基础、研究句子句义成分及各成分之间关系的句义结构表示模型。该模型分别由句型层、描述层、对象层和细节层组成,其中每一层所包含的句义成分如图3所示,句义成分之间的关系包含了谓词间关系、基本项和谓词之间的关系以及一般格与各句义成分之间的关系。句义结构模型不仅能够提供更为丰富的汉语语义特征,而且是一个能够完整地反映出句义成分以及成分组合关系的模型。
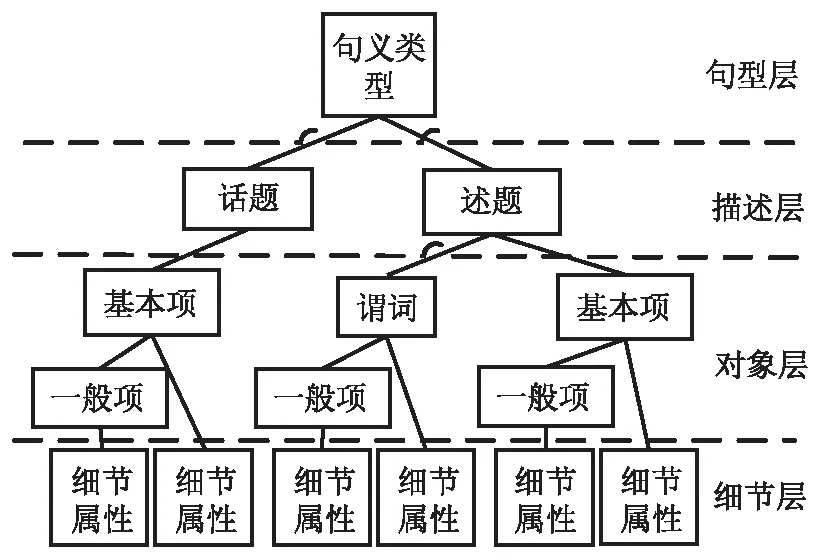
图3 句义结构模型的基本形式
2 汉语语义深度分析
早期,汉语语义自动分析是运用传统机器学习方法自动分析汉语句子的语义结构。其中,在特征构建时,人工总结规律构建特征的过程必不可少。然而,随着深度学习的发展,研究者发现可以利用深度学习模型自动提取特征,从而取代传统机器学习中人工构建特征的步骤。同时,深度学习模型学到的上下文特征更加完备和有效,可以包含句子中更深层的含义。近年来,汉语语义自动分析的研究开始从人工构建特征进行传统机器学习的语义分析转向利用深度学习模型完成端到端的语义分析。
根据对语义分析程度的深浅不同,可以将汉语语义分析分为浅层语义分析和深层语义分析两种。浅层语义分析只要求标注与句子中的谓词相关的语义成分。深层语义分析不再以谓词为中心,而是将整个句子转化为某种形式化表示。两种语义分析方法的对比分析如表3所示。
其中,浅层语义分析方法主要有语义角色自动标注方法和框架元素自动标注方法,方法特点和研究进展如表4所示。

表3 汉语语义自动分析方法对比

表4 浅层语义分析的研究方法
深层语义分析方法主要有汉语语义依存分析和汉语句义结构自动分析,方法特点和研究进展如表5所示。

表5 深层语义分析的研究方法
然而,传统的方法在系统性能上严重依赖于领域知识,并且需要人工选择特征来完成特征工程,同时,人工选择特征的有效性和完备性无法保证。随着训练数据量增大、计算能力提高,深度神经网络在多个自然语言处理任务上都取得了非常好的效果,因此也受到语义分析研究者的关注。研究者尝试将深度神经网络应用到浅层汉语语义分析的研究上,利用深度神经网络能自动提取有效的特征,解决浅层汉语语义分析在特征选择上的限制问题。例如,党帅兵[15]利用深层神经网络进行基本块识别,并将隐层向量作为基本块的分布表征,让其与角色识别任务的神经网络模型的中间层做级联,提高了汉语框架语义角色识别模型的标注性能;赵红燕等[16]利用深度神经网络自动学习目标词上下文特征,来提高语义角色标注中框架识别的准确率;王宇轩[17]对丁宇利用规则和SVM构建依存图的方法进行改进,提出一种基于转移的分析器,使用list-based arc-eager算法的变体对依存图进行分析,同时提出了两种有效的神经网络模块,分别用于获得转移系统中缓存和子图更好的表示。该系统在中英数据集上都取得了很好的效果,并且还能通过简单的模型融合方法进一步提高性能。尽管复杂的特征被设计,但是在句子中长距离的依赖关系很难被构建,因此有研究者尝试利用BRNN(bidrectional recurrent neural networks,双向循环神经网络)解决语义标注中两个方向的依赖关系无法捕获的问题。Wang等[18]利用了基于LSTM的BRNN完成中文语义角色标注任务,解决语义分析中长距离依赖关系难以构建的问题。
3 深度学习与汉语语义的结合
如今,深度学习在自然语言处理的多个任务中取得了不错的效果,深度神经网络的不可解释性以及缺乏标签数据的问题也随之暴露。因此,将先验语义信息加入到深度学习模型中,可以增强深度神经网络的可解释性和泛化性,让机器更好地理解人的语言,为人类提供更智能的服务。
下面主要介绍在深度学习模型中融合先验语义信息来提高深度学习模型可解释性的应用成果,以及融入多元知识库后,解决了单一特定标注集运用在深度学习模型中可扩展性受限的问题。
研究者对在深度学习模型中融合先验语义信息、提高深度学习模型可解释性做了很多新的尝试和探索。2017年,牛艺霖等[19]在word2vec中的Skip-Gram模型的基础上提出SAT(sememe attention over target model)模型。与Skip-Gram模型相比,SAT模型不仅考虑了上下文信息,还考虑了单词的义原信息,借助义原信息使模型更好地“理解”单词,从而验证了分布式表示学习与义原知识库之间的互补关系。同年,谢若冰等[20]综合利用矩阵分解和协同过滤两种手段,利用词汇表示学习模型,对新词进行义原推荐,辅助知识库标注工作。2018年,曾祥楷等[21]尝试利用词语表示学习与知网知识库进行词典扩展。通过实验表明,引入义原信息能够使层次分类效果得到提升。
同时,研究者还发现引入语义角色标签和标注模式不同、但表达潜在语义相同的异构数据(heterogeneous data)可以解决单一语义知识库规则不完备导致分析系统扩展性受限的问题。例如,2015年,Wang等[18]引入异构数据—中文网库来预训练词向量。他们基于中文网库学习LSTM-RNN模型,利用从中文网库中获得的预训练的词向量来初始化一个新模型,最后用中文命题库来训练。实验结果表明,该方法引入异构数据解决了单一标注集扩展性受限的问题。2016年,Li等[22]利用RNN模型做汉语语义角色标注。他使用英文主题库去提高汉语语义角色标注的性能。实验结果表明相对于先进的方法有显著提升,F1值能达到78.39%。2017年,Xia等[23]提出一种渐进式的神经网络模型(progressive neural network,PNN),并发布了一个新的中文语义角色标注数据集——Chinese SemBank作为异构数据。PNN模型能够充分地容纳和利用异构数据更好地完成语义角色标注任务。
4 发展趋势
汉语语义分析发展日趋成熟,但对它的研究还有很多值得深入探索的问题。在该部分,根据目前的研究现状指出汉语语义分析存在的问题,并对其改进方案和发展趋势作简要的介绍。
(1)目前,汉语语义知识库已经有足够大的规模,但随着信息时代的日新月异,汉语语义知识库需要相应的改变和适当的扩展。然而,知识库在不断更新的过程中,容易出现标注不一致的现象。因此需要探索以深度学习为代表的数据驱动和以知识库为代表的专家驱动相结合的技术,让计算机能够辅助人类专家更及时高效地完成标注知识库的工作。并且,在不断优化和扩充语义体系的同时,也能提高人类专家标注知识库的一致性。
(2)在语义分析模型训练的过程中,数据收集昂贵,并且只用一份标注规则相同的语料库训练模型是对语料库的浪费。因此,在后续工作中,考虑将主动学习应用于深度汉语语义分析任务中,从而大幅减少达到最先进结果所需的数据量。同时,也可以考虑将多种语义知识库进行融合,训练得到语义信息更加丰富的模型。这种通过融合不同知识库的语义信息来提高汉语语义自动分析系统性能的研究将成为语义分析的下一个研究热点。
(3)目前,通过结合深度学习模型,汉语语义分析效果有明显提升,利用深度学习模型自动提取特征取代了传统机器学习中需要人工构建特征的过程,提升了特征选择的有效性和完备性。同时,随着注意力机制在自然语言处理任务中的广泛应用,尝试利用注意力机制学习更多标签潜在的依赖信息,从而提升语义分析的效果。这也将成为今后研究的热点。因此,在标注语料达到一定规模的情况下,使用深度学习模型自动提取特征进行语义分析将成为汉语语义深度分析的研究趋势。
(4)分布式表示(distributed representation)在可解释性方面能力较弱,另一方面,利用端到端(end-to-end)框架训练得到分布式表示的效率较低且需要极大的训练语料。因此,在利用深度学习框架完成语义分析任务时,仍然需要加入语义知识库来为系统提供更多的先验知识,从而提高系统的分析效率和结果的可解释性。因此,如何在分布式表示中引入语义知识库作为先验知识是未来的重要挑战性问题。同时,如何利用先验知识实现无监督学习,使得较少标注数据通过先验知识的加入也可以训练出很好的模型,也将成为汉语语义分析中新的发展趋势。
5 结束语
文中在充分调研和深入分析的基础上对汉语语义分析的研究进展进行了总结。对目前常用的汉语语义知识库,如知网、中文网库、汉语框架语义网、中文命题库、汉语语义依存树库以及汉语句义结构标注语料库进行了说明;在对汉语语义自动分析方法的研究中,依据对句义分析的深浅程度的不同,将分析方法分为浅层语义分析和深层语义分析两种方法。对这两种方法的特点和研究进展进行列举,指出存在的问题,并对运用深度学习模型自动提取特征完成语义分析的方法进行介绍。在汉语语义分析的应用中,主要介绍了在深度学习模型中融合先验语义知识提高深度学习模型可解释性的应用成果,以及融入多元知识库后,解决了单一特定标注集运用在深度学习模型中的可扩展性受限的问题。最后,指出目前汉语语义分析存在的问题,对每个问题提出可行的解决办法,并对深度学习与汉语语义分析结合的应用进行了展望,希望对该领域的其他研究者有所启发。
