基于Scrapy的分布式爬虫采集软件的实现
2019-09-19翁绍菲廖翔宇祝光仪范雅静甘宇健
翁绍菲 廖翔宇 祝光仪 范雅静 甘宇健
摘要:近年来,随着互联网的迅速发展,人们对于数据的挖掘与应用越来越重视。为了让程序自动浏览互联网中的海量网页,把用户需要的信息进行收集整理,转化成便于阅读的形式并存储起来,方便用户的理解和使用。研究了分布式爬虫和Scrapy框架,将Scrapy和Redis相结合,设计并实现了一个基于Scrapy框架的分布式网站采集系统。结果表明该系统操作简单,可以降低编写爬虫的难度,同时分布式的采用也提高了爬虫采集的效率。
关键词:爬虫软件;C#;Scrapy框架;分布式;Redis
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)20-0073-03
开放科学(资源服务)标识码(OSID):
Abstract: In recent years, with the rapid development of the Internet, people are paying more and more attention to the mining and application of data. To make the program automatically browse the massive web pages on the Internet, and collect the information needed by users and then convert it into a form that is easy to read and store, so than it can convenient for people to understand and use. distributed crawler and Scrapy framework is studied, A distributed website collection system by combine the Scrapy and Redis is designed and implemented . The result shows that the system is simple to operate, which can reduce the difficulty of writing crawler script, and that the distributed structure improves the efficiency.
Key words: crawler; C#; Scrapy; distributed system; Redis
1 背景
在如今这个大数据的时代,人们手动利用搜索引擎来寻找大量特定数据效率极低,而且针对性差,无法进行系统的处理和展示。如果能够将互联网中的庞大的信息数据收集起来,经过数据挖掘、数据清洗和数据分析后,它们可以变成具有参考和借鉴价值的信息,为人们提供灵感来源或决策参考的数据支持。因此,如何高效准确地获取所需的信息数据资源成为一个极其关键的问题。
本文研究的主要内容是设计并实现一个分布式爬虫采集软件,该软件能够适用于绝大多数的网站。即使非技术人员也可以通过简单的学习和分析轻松运用本软件爬取简单的目的信息数据;对于专业人士而言,本系统可以减轻他们的工作量。
2 研究现状
随着20世纪90年代搜索引擎的出现,网络爬虫也随之出现。网络爬虫,又被称为网页蜘蛛,是一种根据设定的规则,自动地抓取网页信息的程序或者脚本[1]。随着分布式网络爬虫的出现,爬取效率得到了很大的提高。分布式网络爬虫可以看成是由多个集中式网络爬虫构成, 分布式系统中的每个节点都可以看作一个集中式网络爬虫[2],Web Gather和Google搜索引擎所使用的网络爬虫系统就是分布式的爬虫。现在网络爬虫已经深入到了生活中的各个领域,如在金融方面徐翔等博士编写设计的网络爬虫可用来分析网络舆情与上证指数涨跌幅的关联性[3];农业方面刘晓刚教授开发了网络爬虫进行网上农产品的大数据抓取[4]。
3 工具简介
3.1 Scrapy
Scrapy是Python开发的一个快速、高层次的屏幕抓取和WEB抓取框架,用于抓取WEB站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试[5]。
3.2 Scrapy-redis
Scrapy-Redis是使用Scrapy框架和Redis数据库工具组合实现的一个网络分布式抓取开源项目[6]。虽然Scrapy框架本身并不支持分布式爬虫,但是搭载了Redis数据库后形成的Scrapy-Redis模式可以很好的解决这个问题,它的原理是将Scrapy自身待抓取的网页URL队列替换成Redis的数据库内的队列,使得要爬取的请求存放在同一个Redis服务器。开始分布式任务后,多个爬虫程序便可以去同一个Redis的数据库里获取请求队列的URL,分别采集任务,再把数据存入同一个Redis数据库里。
4 系統总体设计
本软件是一个简单易操作的爬虫采集软件,使用了热门的框架和技术,亲和性适用性强,运行和维护不需要太多的成本;建立任务过程简单易学,无需太多人力投入。
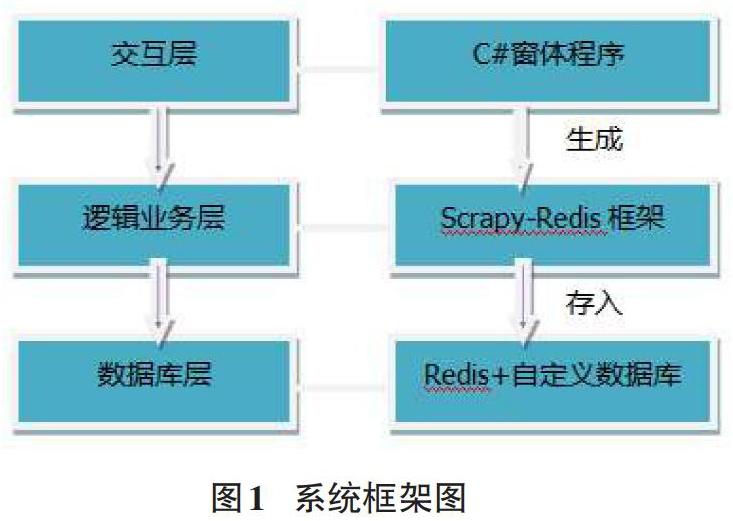
软件分成三个模块,系统框架图如图1所示。C#窗体程序负责和用户的交互,Scrapy-Redis框架负责爬取数据,Redis数据库和用户指定数据库负责存储数据。系统的任务由一个至多个层构成,每一层是一个独立的方法,代表一个逻辑层的网页。在每一层里,可以通过添加不同属性的Xpath等信息爬取该层网页中的不同内容。通过添加网站的起始URL、层Xpath和每层的属性信息,系统将自动生成爬虫来采集网页并将采集到的内容存入数据库。
4.1 交互层——窗体模块设计
交互层主要负责软件操作页面展示和进行人机交互。系统的设计可以分为四个模块:主页面模块、创建与编辑任务视图模块、服务端视图模块和客户端视图模块。
1)主页面模块,使用者可以查看所有任务的信息列表,具体包括每个任务的任务名、采集网址、模式(单任务、分布式)、类型(服务器/客户端/单机)、状态、开启时间等信息。针对每个任务,使用者可以选择对其进行开始、暂停、停止、编辑、前往根目录等操作。
2)创建与编辑任务视图模块,使用者可对任务进行模式选择,填写任务基础信息和编辑任务的操作。编辑任务的界面分为可视化界面和代码界面。在可视化界面,用户可以通过一些可视化的操作增删改查爬虫的层和每层的属性信息,选择该层爬虫是否需要分页处理;在代码界面,用户可以预览生成的代码。经过一些可视化的流程和少量修改,使用者可完成针对性的爬取任务。
3)服务端视图模块,使用者可以监听客户端接入请求、查看各个已接入客户端的信息、开启Redis数据库监听、将任务发送至客户端、开启和停止采集任务。
4) 客户端视图模块,使用者可以通过客户端视图模块查看是否成功连接服务端,接收服务器任务和开始客户端采集任务。
4.2 逻辑业务层——爬虫模块设计
逻辑业务层是本系统的核心,它主要用于实现对具体业务的操作,在本例中主要用于实现根据交互层提交的任务数据进行爬虫生成,网站爬取然后将采集结果存入数据库。
爬虫提取网页内容的核心方法主要有Beautifulsoup、正则表达式和Xpath三种。Beautifulsoup是Python自带的一个Html的解析库,它的优点是更符合人们直观理解的语义。系统将需要分页的页面使用BeautifulSoup解析 “下一页”字段所对应的URL地址,如果没有对应的完整网址,则将任务的采集网址和找到的URL地址的组合作为下一重的URL地址。正则表达式是对字符串进行过滤处理的一种逻辑公式,虽然正则表达式能使爬虫处理速度更快,并且比起Xpath功能更为强大,但它复杂且容易出错,增加普通人的学习难度和使用难度。Xpath 是一门在 XML 文档中查找信息的语言, 灵活易学,便于非编程人员的学习及使用。综上考虑本系统将采用Xpath作为系统的爬取核心[7]。
4.3 数据库层设计
数据库层用于实现系统对数据库的操作,本例中主要体现在系统自动创建数据库、删除数据库和将数据插入数据库的操作。为了方便用户信息存储,系统需要在爬虫存储模块创建一个原始数据库,使得用户只需将数据库类型、数据库名、帐号、密码填入配置文件,运行代码后系统会自动在目标数据库自动创建表和存入信息。系统为每个任务的每层创建一个单独的表,创建表的表名为任务名_层数,表中每一列的字段名为任务的属性名称。这种结构有利于直观的区分每一层和显示每一层的表单数据。
5 系统主要实现
5.1 爬虫脚本
系统使用Python作为开发爬虫的语言。爬虫主要使用Scrapy-Redis框架,除了解决了分布式处理的难题,这种框架最大的优点还有方便的去重处理和程序中断处理。由于URL存放在同一个服务端,服务端可以经过统一去重后再分配给各个客户端进行抓取,并且,当程序出现中断后,数据库中仍存在请求队列, 当系统再次启动时任务将会继续爬取[8]。
对于爬取动态JS处理的网页,系统采用无头浏览器抓取单个网页并进行渲染,解决了传统HTTP爬虫抓取单页应用难以处理异步请求的问题[9]。为了提升爬取页面爬虫的运行速度,代码默认是禁用Css图片的,如需加载,手动将相应代码删掉即可。
5.2 窗体程序搭建
软件使用C/S架构。服务器和客户端之间通过Socket进行数据传输。Socket是一个网络通信接口,它采用的TCP/IP协议可以唯一的标识网络中的一个进程,使得服务器可以安全准确地传输数据至客户端[10]。
交互界面使用C#窗体程序进行开发。系统开始任务后将解析编辑文件过程生成的Xml格式任务数据和原始的爬虫代码相结合,利用字符串处理技术自动生成目标爬虫代码,调用Cmd执行命令执行爬虫程序。执行完任务后,任务状态将更新为已完成,同时数据库获得爬虫程序存入的对应任务采集数据。
5.3 数据库层的实现
为了提高数据的安全性,防止误删,也为了便于分布式系统的存储,系统采用Redis数据库和用户设计数据库并行储存系统爬取下来的数据。配置完数据库的文件后,爬虫存储模块通过调用已编写封装好的DLL(动态链接库文件)来帮助创建和存入数据库。基于数据库兼容性的考虑,系统支持TXT文本和Mysql、SqlServer等数据库。
6 结束语
这套系统,可在通过一些可视化的操作后,完成爬虫的爬取。使用它用户可以更加简单快捷地爬取网站。同时,爬虫的设计基本上解决了一般爬虫的去重、分页处理、动态JS加载、存入数据库等问题,满足了爬虫人员的一般需要。分布式爬虫的功能解决了单台机器爬取大型网站速度慢的问题。未来还将继续完善本系统的研究,解决初始数据库设计缺陷、反爬虫处理等问题。
参考文献:
[1] 百度百科. 网络爬虫[EB/OL]. [2019-04-17]. https://baike.baidu.com/item/网络爬虫/5162711?fr=aladdin.
[2] 刘洋, 崔翠, 李立新. 一种基于python语言的网络爬虫研究[EB/OL].https://www.xzbu.com/8/view-7493419.htm.
[3] 徐翔, 靳菁, 吕伟欣. 网络舆情作为社会传感器对股票指数的影响——基于LDA主题模型的挖掘分析[J]. 财务与金融, 2018(6): 1-9.
[4] 刘晓刚. 农产品大数据的抓取和分析方法探索[J]. 农村经济与科技, 2018, 29(19): 304-305.
[5] 百度百科. Scrapy[EB/OL]. [2018-12-05].https://baike.baidu.com/item/scrapy/7914913?fr=aladdin.
[6] 邓万宇, 刘光达, 董莹莹. 一种基于Scrapy-Redis的分布式微博数据采集方案[J]. 信息技术, 2018(11): 59-62.
[7] lingojames. python爬虫里信息提取的核心方法: Beautifulsoup、Xpath和正則表达式[EB/OL]. [2017-06-01] https://blog.csdn.net/lingojames/article/details/72835972.
[8] 黎玉香, 于伟. 分布式网络爬虫系统的基本原理与实现[J]. 花炮科技与市场, 2018(4): 45.
[9] 裤裤他爸. 2018-08-16面试题-无头浏览器[EB/OL]. [2018-08-16] https://www.jianshu.com/p/35a9e566e6d6.
[10] Xiao__Tian_. 基于TCP协议的网络通信(socket编程)[EB/OL]. [2016-07-28] https://blog.csdn.net/xiao__tian__/article/details/52050863.
【通联编辑:谢媛媛】
