基于决策树的数据挖掘技术在就业信息管理系统中的应用研究
2019-09-19叶章浩
叶章浩
近年来,我国的高等教育事业不断的取得进步,各类高等学校也相应的增加了招生人数,这使得高等学校毕业生的就业压力和就业难度也在不断增加,解决好高校毕业生的就业问题,成为高校所必须面对的一个基本问题。如何更加清晰直观的了解学生的就业动向和就业趋势,制定下一步的就业政策,更是高校就业管理部门所关注的一个重点问题。这样一来,毕业生就业信息管理系统不仅需要对信息进行存储和查询,更是需要可以对就业数据进行挖掘,挖掘出毕业生就业的趋势和动向。在本文中,作者设计并开发了毕业生就业信息管理系统,并在此基础上使用了基于C4.5 决策树的数据挖掘技术,从而可以更好的挖掘学生的就业动向和就业趋势,为高校学生就业指导工作提出更好的建议和意见,也可以为学校相关部门的就业政策的制定和培养方案的制定提供决策支持。
1 就业信息管理系统的设计与实现
该系统基于B/S 模式进行构建,采用JSP 技术进行开发,使用MySql 数据库对数据进行存储。在功能实现方面,该系统由管理员模块、学生模块、用人单位模块三大模块所构成。
在管理员模块中,管理员可以进行以下操作:1)对学生信息进行管理,增加、删除、修改学生信息。进行学生信息的审核,导出学生在线签约的三方协议。2)对招聘信息进行管理,并对企业发布的招聘信息进行审核。3)对就业政策信息进行管理。4)对企业介绍信息进行管理。5)查看各专业就业率统计图和就业报表。6)对系统用户信息、个人信息等进行管理。
在学生模块中,毕业生可以进行以下操作:1)查看企业招聘信息。2)查看就业政策信息。3)查看企业介绍信息。4)查看个人就业基本信息及在线签约三方协议。
在用人单位模块中,用人单位招聘人员可以进行以下操作:1)查看应聘学生的个人信息,进行三方协议的在线签约。2)发布企业招聘信息。3)发布企业介绍信息。4)对企业用户个人信息进行修改。
2 数据挖掘技术的概述
2.1 数据挖掘的定义
数据挖掘(Datamining),也被称之为数据采矿或者资料勘探,数据挖掘可以从大量的数据中,通过算法来提取其中所隐藏的未知的并具有潜在价值信息[1]。数据挖掘可以将大量的数据转化为有用的信息和知识,在大量的数据中分析数据之间的趋势、关系和模式。数据挖掘主要是针对未知模式、关系的探索,从已有的数据中发现未知的潜在的具有价值的信息。采用数据挖掘,学校就业部门可以从大量的就业数据中获得学生的就业趋势和就业动向,从而为学生就业提供更好的决策支持。
2.2 数据挖掘的特点和内容
数据挖掘具有以下的特点:
1)数据量大。数据挖掘是从大量的数据中提取潜在的有用的信息。
2)数据挖掘具有较快的响应速度。数据挖掘中的数据是不断发生变化的,因此数据挖掘应该快速响应数据的变化,并做出相应的决策支持。
3)数据挖掘的规则基于大量数据样本,其规则有可能对某一条数据并不适用。
数据挖掘研究的内容有以下几个方面:进化运算、最优化、发现算法、可视化、信息检索、知识发现等[1]。
2.3 数据挖掘的方法
数据挖掘的主要方法包括:分类、聚类、关联规则、预测、估计、Web 数据挖掘、图形图像数据挖掘等[1]。
2.4 数据挖掘的过程
数据挖掘的过程如下:
1)确定目标。对数据挖掘的具体目标进行确定,定义数据挖掘的任务。
2)数据理解。对于所要挖掘的数据进行熟悉,了解数据的质量,发现数据的属性,对数据信息进行检查。
3)数据准备。将采集的数据进行转换、清洗、合并等,并选取所需要的数据,构建新的数据。
4)数据挖掘。采用合适的方法对数据进行分析,从而得到具有价值的信息。
5)分析和应用。将分析所得到的知识应用于具体的信息系统中,为信息系统提供决策支持。
3 C4.5 决策树算法在就业信息管理系统中的应用
3.1 C4.5 决策树算法的概述
决策树算法是数据挖掘中常用的算法之一,可以在海量的数据中对数据进行分类,并做出预测,发现数据之间的关系。决策树在本质上就是一棵树,它可以将相同属性的数据进行归类,在这棵树中,每一个叶子节点都代表着一个类别的属性,决策树可以从叶子节点上分析出所需要的具体数据[2]。当前最常用的决策树算法有ID3、C4.5、CART、ASSISTANT 算法等。
采用决策树进行分类时,可以按照以下的步骤进行:1)采集数据信息。对所需要分类的数据进行采集,并对数据进行清洗,形成数据训练集。2)构建数据模型,对数据进行泛化,构造决策树模型。3)采用构造好的决策树模型对数据进行分类。在进行分类的时候,在根节点开始对数据的属性进行测试,并顺着分支到达叶节点,该叶节点即为数据分类后所处的类。
对于C4.5 决策树算法的信息增益率,可以采用以下的方法进行计算:
1)设具有一个集合S={Ni|i=1,2,…,s},类标号属性集为{Ci|i=1,2,…,m},si为集合S 属于类别Ci的样本的数量,则集合S 的熵的计算公式如下所示:
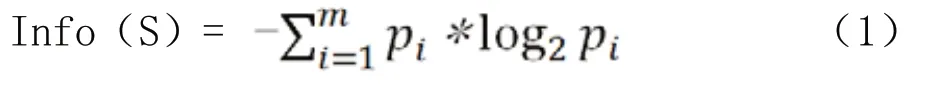
2)计算给定属性A 的信息熵、信息增益、信息增益率。
给定属性A,属性A 具有w 个不同的值{a1,a2,…,aw},则集合S 可以划分为w 个不同的子集,定义sk 为Sk 的样本数量,sik 为Sk 中类别Ci 的样本数量,则属性A 的子集的熵的计算公式如下所示:

由于熵值越小,纯度越高,则对于给定的子集,信息熵的计算公式为:

由此可得属性A 的信息增益公式为:

属性A 的信息增益率公式为:
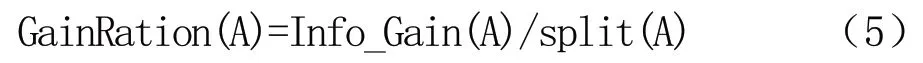
通过C4.5 决策树算法对属性的信息增益率进行计算,并对各个分枝进行划分,从而建立相应的决策树,并对属性数据进行分析预测。
3.2 数据的预处理
3.2.1 数据的采集
在毕业生就业信息管理系统中,包含了大量毕业生的基本信息,这些基本信息包括学生的院系、专业、综合成绩、英语水平、计算机水平等。在本文的研究中所需要采集的数据包括毕业生个人的学号、综合成绩、英语水平、计算机水平、科研水平、就业单位等信息。在系统管理员模块的“学生就业信息管理”功能中,可以对这些数据以excel 表形式进行导出。然后需要对数据进行合并、量化、转换、清理、集成等处理工作[2],即可获得所需要的数据。
3.2.2 数据的建模和泛化
对于获取的数据,可以采用一个五维向量N={N1,N2,N3,N4,N5}进行表示,其中N1 代表综合成绩,N2 代表英语水平,N3 代表计算机水平,N4代表科研水平,N5 代表就业单位情况。对于各数据的属性,可以做出如下的定义:
综合成绩(CJ)可以分为优秀和良好两个等级,可以将成绩泛化为1(优秀),2(良好)。
英语水平(YY)可以分为优秀和良好两个等级,优秀等级为通过英语六级考试,良好为通过英语六级考试以下水平。可以将英语水平泛化为1(优秀),2(良好)。
计算机水平(JSJ)可以分为通过计算机一级水平考试和通过计算机二级水平考试两个等级,可以将计算机水平泛化为1(一级),2(二级)。
科研水平(KY)可以分为优秀(有大量的实验室经历和大量优秀论文的发表)、良好(有少量的实验室经历和少量论文的发表)、差(无实验室经历,无论文发表)三个等级,可以将科研水平泛化为1(优秀),2(良好),3(差)。
就业单位(DW)可以分为国企(G), 私企(S),外企(W)。各类单位的层次可以分为好单位(H)和差单位(C)。由此可以将单位泛化为:好国企(HG),差国企(CG),好私企(HS),差私企(CS),好外企(HW),差外企(CW)。
3.3 决策树的构建
表1 即为本次实验所选取的就业数据样本训练集。其中就业单位为标识属性,综合成绩、英语水平、计算机水平、科研水平为决策属性。

表1 就业数据样本训练集
在就业数据样本训练集S 中,共具有20 组元组。我们按照单位类型进行决策树的构建,在这些元组中,好国企(HG),差国企(CG),好外企(HW),差外企(CW),好私企(HS),差私企(CS)所对应的子集中元组的个数分别为h1=6,h2=6,h3=5,h4=1,h5=2,h6=0。对各属性的信息增益进行计算可得:
综合成绩、英语水平、计算机水平、科研水平的信息增益率分别为:GainRation(综合成绩)=0.583,GainRation(英语水平)=0.254,GainRation(计算机水平)=0.244,GainRation(科研水平)=0.136。将各属性的信息增益率进行比较,信息增益率最大的为根节点,按上述步骤进行重复,对每个分支进行划分,建立最终决策树如图1 所示。
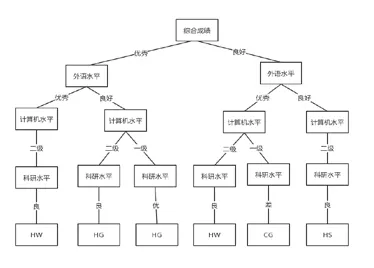
图1 基于C4.5构造的就业信息决策树
3.4 分类关联规则的获得
通过上述构建的决策树,可以对HG,HS,HW的分类规则进行提取,并可以获得以下的分类规则:
1)IF(综合成绩=“优秀”and 科研水平=“优秀或者良好”and 英语水平=“良好”)THEN(工作单位为好国企);
2)IF(英语水平=“优秀”and 计算机水平=“二级”)THEN(工作单位为好外企);
3)IF(综合成绩=“良好”and 计算机水平=“二级”)THEN(工作单位为好私企)。
通过上述分类关联规则可以看出,综合成绩优秀,科研水平优秀或良好,外语成绩良好的学生,工作单位一般为好国企;英语水平优秀,计算机水平二级的学生,工作单位一般为好外企;综合成绩良好,计算机水平二级的学生,工作单位一般为好私企。
由于不同的单位对于学生的要求并不尽相同,因此对于不同就业目标的学生,所制定的培养方案也是不相同的。对于就业目标为好国企的学生,需要有效地提高综合成绩、科研水平以及英语成绩;对于就业目标为好外企的学生,需要有效地提高其英语成绩以及计算机水平;对于就业目标为好私企的学生,需要有效地提高其综合成绩以及计算机水平。
通过上述数据挖掘结果,学校就业管理部门的相关工作人员可以根据学生的不同就业目标,制定相应的培养方案和就业政策,以便于有效的提高学生的就业水平和就业质量。
4 结束语
本文在毕业生就业信息管理系统的基础上,采用基于C4.5 决策树的数据挖掘技术对就业数据进行分析和预测,从而获得影响大学生就业的关键因素,为学生的就业提供了更好的指导,学生可以根据自身的就业需求和就业目标,学习相应的知识,提高相应的能力。学校相关部门也可以根据这些关联规则,制定相应的培养方案,从而使得高校毕业生的就业率得以有效地提高。
