基于PU与生成对抗网络的POI定位算法
2019-09-16田继伟王劲松
田继伟 王劲松 石 凯
(天津理工大学计算机科学与工程学院 天津 300384) (天津市智能计算及软件新技术重点实验室(天津理工大学) 天津 300384) (计算机病毒防治技术国家工程实验室(天津理工大学) 天津 300457)
随着互联网的蓬勃发展,个性化推荐技术已经成为学术界的研究热点之一.近年来,个性化推荐技术已经成功应用于多个领域,尤其是在广告推荐领域,它带来了巨大的商业价值.但是,个性化推荐技术的数据来源于人们在网络上产生的行为,这些网络行为往往是低成本的,由这些低成本的行为推荐来的广告虽然具有很大价值,但确有局限性.例如,经常在网络上浏览汽车的人虽然有很大可能性接受汽车类的广告推荐,但是相比之下,那些去4S店的人有更大可能性购买汽车,从而给商家带来真正的利润.考虑到推荐技术的这种局限性,对兴趣点(point of interest, POI)的定位和推荐技术就变得非常重要.另外,随着智能移动设备的快速普及,人们对基于位置的社交网络服务(location-based social networking service, LBSNS)的依赖性也越来越高.基于数据挖掘的POI定位和推荐技术已经成为一个重要课题.高榕等人[1]将POI、社交关联和评论信息融合起来,提出了一种GeoSoRev兴趣点推荐模型.Chen等人[2]研究了LBSNS中的连续个性化POI推荐问题,将时间关系融合到POI推荐中.Gao等人[3]将内容信息融合进了POI推荐系统中.Yin等人[4]考虑了用户在不同区域往往有不同的兴趣,研究了跨区域的POI推荐系统.但是,文献[1-4]的POI推荐系统都无法离开POI定位技术的建设.
目前,国内外许多研究已经利用无线网络来进行POI定位.其中,使用最多的方法是基于无线信号接收强度(received signal strength, RSS)的位置指纹技术[5-7],该技术已经广泛应用于移动通信领域,且可以在任何具有WiFi发射设备的地方推广应用.但是由于用户隐私问题,有POI标记的数据难以收集.一般来说,采集来的数据可以分为2类:一类是占比很大的没有标记POI的数据;另一类是占比很小的标记了POI的数据,即正样本数据.这就造成了正样本数据不足的问题,极大地影响了POI定位的准确性.目前很少有研究致力于解决这一普遍存在的问题.Matos等人[8]提出了一种模拟定位的方式去进行POI的识别.然而,这种识别系统的误差会随着系统计算量的增大而增加.此外,Moghtadaiee等人[9]提出了一种短距离RSS误差模型来提高POI定位效果,但累积误差的问题仍然无法得到有效解决.
本文基于现有数据,提出了一种基于PU与生成对抗网络(positive and unlabeled generative adversarial network, puGAN)的模型来进行POI的有效定位与识别.实验表明,本文提出的puGAN模型比传统的POI定位和分类模型具有更好的效果.本文工作的主要贡献有2个方面:
1) 将PU(positive and unlabeled)学习[10-11]和生成对抗网络(generative adversarial network, GAN)模型相结合,并应用到POI定位算法中,以此解决数据样本不足的问题,从而提高POI定位的准确性;
2) 理论证明了puGAN模型的普遍适用性.
1 相关研究工作
到目前为止,大部分POI定位模型都有着数据采集不足的缺陷.有2种方式可以解决这个问题:一种方式是覆盖所有的采集点采集充足的数据,但这种方式往往伴随着巨大的人力、财力和时间成本,通常来说是不可接受的;另一种方式是基于少量正样本和大量无标签样本,使用PU学习方法.下面简单介绍PU学习算法.
1.1 PU学习算法
PU学习作为半监督学习[12]的一个重要分支,逐渐成为了研究界的热点问题.PU算法对无标签样本的使用情况,可以概括成2个方面:
1) 基础模型的研究.通过单类模型(one-class, OC)对正样本数据进行学习,但是这种方式通常会浪费较多的数据特征,从而导致模型欠拟合.或者使用SVM等二分类模型,它们虽然能够利用到所有的数据特征,但无法避免无标签样本噪声过大而可能导致的欠拟合问题.
2) 基于高可信样本的挖掘.这种方法的核心是优先找到高可信的正样本或者负样本,从而基于此样本进行学习和分类.任亚峰等人[13]使用这种PU学习的方式,从大量无标签样本中识别出少量高可信的负样本,进行了识别虚假评论的研究.
PU学习虽然能够利用少量正样本以及大量无标签样本进行学习,但是正样本和无标签样本的样本量相差巨大,影响了模型学习的准确性和快速性.本文在利用PU学习算法的同时引入了GAN模型,一方面生成伪正样本弥补正样本不足的缺陷,另一方面学习无标签样本的分布,提高分类模型的准确性.下面简单介绍GAN模型.
1.2 GAN模型
2014年,Goodfellow等人[14]提出了GAN,并进行了一系列研究[15-16],解决了如何使机器学习的训练成果向着理想方向前进的问题.Odena[17]首次将GAN模型与半监督学习相结合来提高生成器的质量.
如图1所示,GAN模型针对正样本提出了生成器与判别器的概念.生成器通过不断学习真实样本数据的分布生成伪样本,从而尽可能欺骗判别器.而判别器则通过学习真实样本和伪样本的差异,尽可能区分出数据来源.
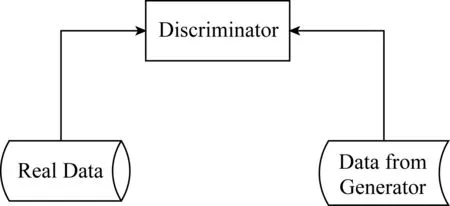
Fig. 1 The illustration of GAN model图1 GAN模型图
生成器和判别器不断博弈的过程就是数据不断生成和分类的过程.实验证明,GAN模型在训练样本不足的情况下,能够有效学习出原有数据的分布特征.与此同时,模型的判别器也能够准确地区分出样本是来源于生成器还是来源于真实的训练数据集.
另外,2017年,Arjovsky等人[18]提出了一种观点,即GAN中利用JS散度会导致纳什不均衡的问题,这会使模型训练不稳定.为了解决这个问题,他提出了WGAN模型,这种模型在提升稳定性与准确性上有很好的表现.本文提出的puGAN模型也使用了这一思想.
不同于传统的GAN模型,本文不仅将GAN模型应用于POI定位中,而且在模型中分别对正样本和无标签样本都引入了生成器和判别器.
2 基于PU与生成对抗网络的模型
本文将第1节的PU学习与生成对抗网络模型相结合,提出了基于PU与生成对抗网络的模型.下面将详细介绍puGAN模型的原理及理论分析.
2.1 puGAN模型
在本文中,Xp,Xu分别表示正样本数据集和无标签样本数据集;pp(x),pn(x),pu(x),p(x)分别表示正样本、负样本、无标签样本以及整个数据集合的分布;Gp,Gu分别表示puGAN模型中正样本生成器和无标签样本生成器;Dp,Du分别表示正样本判别器和无标签样本判别器;Dpu表示正样本无标签样本判别器.本文假设数据分布遵循的规则为
p(x)=pp(x)+pn(x),
pu(x)=θppp(x)+θnpn(x),
其中θp,θn都是0~1之间的小数,并且满足θp+θn=1.
基于上面的假设,本文设计了puGAN模型.如图2所示,描述了puGAN模型的训练过程.其中,判别器Du通过对真实的无标签样本与无标签样本生成器Gu生成的数据进行判别分类,从而调整学习得到无标签样本数据的分布特征.同理,判别器Dp通过对正样本进行判别分类,训练得到正样本数据的分布特征.
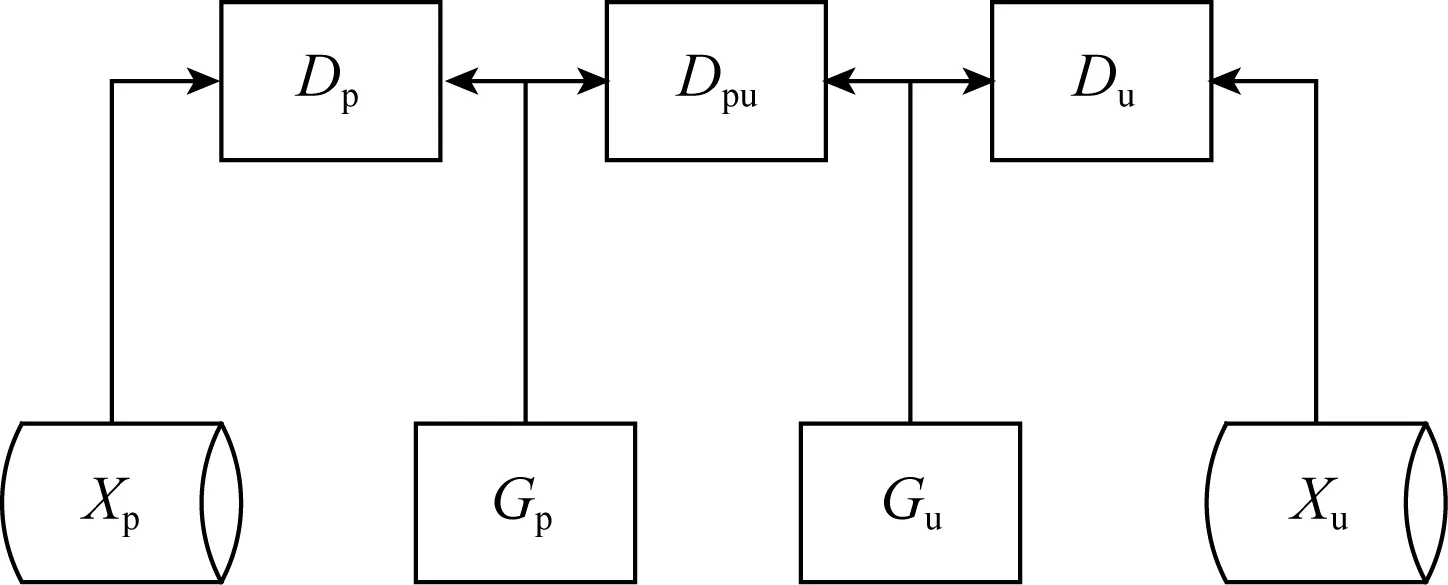
Fig. 2 The illustration of puGAN model图2 puGAN模型图
最终,puGAN模型的目标函数为
(1)
其中,α,β,γ均为大于0的参数.
判别器希望提高自己的辨别能力,能够准确分辨出样本是来源于真实样本集还是来源于生成器生成.而生成器则不断提升自己的“伪造”技术,希望能够生成可以“以假乱真”的数据.根据零和博弈的原则,将目标函数进行推导,可以得到
VGu,Du(G,D)=Ex~pu(x)lg(Du(x))+Ez~pzu(z)lg(1-Du(Gu(z))),
(2)
VGp,Dp(G,D)=Ex~pp(x)lg(Dp(x))+Ez~pzp(z)lg(1-Dp(Gp(z))),
(3)
VGp,Gu,Dpu(G,D)=Ex~pp(x)lg(Dpu(Gp(x)))+Ez~pu(z)lg(1-Dpu(Gu(z))).
(4)
在此训练过程中,正样本判别器Dp、无标签样本判别器Du、正样本无标签样本判别器Dpu、正样本生成器Gp和无标签样本生成器Gu均由深度神经网络训练得到.整个模型的训练过程如算法1所示.
算法1.puGAN模型训练算法.
输入:正样本数据集和无标签样本数据集;
① FOR 训练次数
② FOR 迭代次数
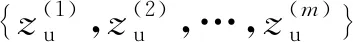
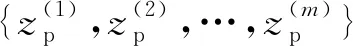
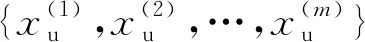
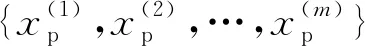
⑦ 计算无标签样本判别器的梯度值,并以此梯度进行梯度下降计算

⑧ 计算正样本判别器的梯度值,并以此梯度进行梯度下降计算
⑩ END FOR
在此训练过程中,噪声普遍存在于正样本和无标签样本数据中,因此,本文分别对正样本和无标签样本引入了生成器与判别器,从而调整并学习得到2个样本的分布特征.随后,使用无标签样本生成器和正样本生成器分别生成伪无标签样本和伪正样本数据,并根据此数据进行分类学习,最终得到了POI定位的分类模型.
2.2 理论分析
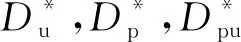
(5)
(6)
(7)
证明. 对于任何一个给定的生成器,分类器Du,Dp,Dpu的估值函数方程为
(8)
(9)
(10)
通过合并最优估值函数,可以得到结论:
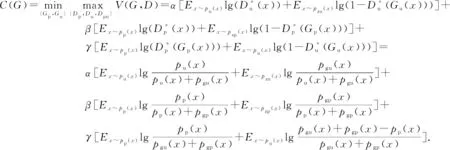
(11)
证毕.
定理1.当且仅当pu=pgu,pp=pgp,且2pp=φupgu+φppgp时,目标函数可以达到全局最小值.
证明. 当满足上述条件时,可以得到:
Ex~pu(x)[-lg 2]+Ex~pzu(x)[-lg 2]=-lg 4,
(12)
Ex~pp(x)[-lg 2]+Ex~pzp(x)[-lg 2]=-lg 4,
(13)
Ex~pzp(x)[-lg 2]+Ex~pzu(x)[-lg 2]=-lg 4.
(14)
将式(12)~(14)带入式(11),可以得到:
C(G)=α[-lg 4+JS(pp‖pgp)]+β[-lg 4+JS(pu‖pgu)]+γ[-lg 4+JS(pgp‖pgu)],
(15)
其中,JS为分布之前的JS散度.
所以,当满足条件pu=pgu,pp=pgp且2pp=φupgu+φppgp时,可以取得目标函数的全局最优值.
证毕.
3 实例分析
3.1 数据集
本文使用的是脱敏后某高校校园无线网络接入日志数据,日志提供了对设备信息加密后的唯一标识及扫描得到的WiFi信息列表.具体的WiFi数据格式为
〈id1,sig1|id2,sig2|…|idm,sigm〉,
其中,idi表示第i个发射WiFi信号设备的标识,sigi为第i个WiFi所对应的信号强度.
数据集共包含176 449条数据,覆盖了210个WiFi接入点和150个POI.其中,正样本15 888条,无标签样本160 561条.本文将有连接行为的数据标记为该WiFi接入点的正样本数据,并与对应的POI进行关联,将与其他POI关联的正样本数据作为该POI的负样本数据,将无连接行为的数据作为无标签数据.通常来说,一个POI可能对应多个WiFi接入点,同时每个WiFi接入点对应着多条正样本和无标签样本数据.通过对数据集进行初步分析,可以知道正样本大约只有总数据量的9%,而剩余的91%均为无标签样本.本文又对正样本数据进行深入统计和分析,得到了它的统计规律如图3所示:
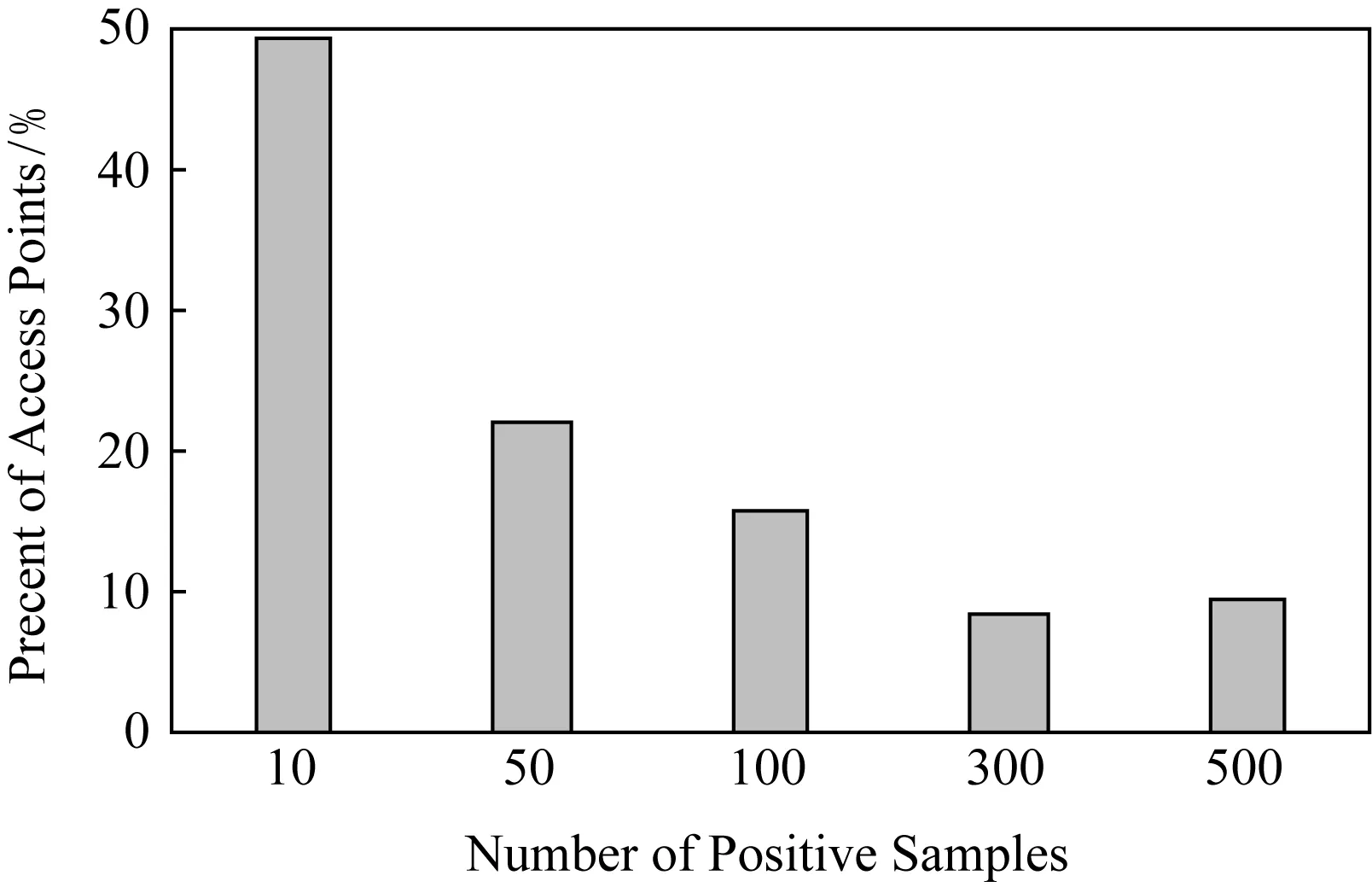
Fig. 3 The statistics of positive samples图3 正样本数据统计图
从图3可以发现, 47%的WiFi接入点拥有的正样本数在10条以下,而正样本数量在300条以上的WiFi接入点仅仅占比9%.由此可见,过半的WiFi接入点的正样本缺失情况严重.此情况在一个POI具有多个WiFi接入点的时候尤为明显.
在实验中,由于采集得到的负样本在物理空间中通常偏于一侧,为了避免训练结果出现偏差,本文使用正样本和负样本作为评估集,使用正样本和无标签样本作为训练集.
在训练过程中,由于数据本身特征维度相对较高,在样本偏少的情况下,传统的分类模型通常会因训练不足而难以得到理想的样本分布情况.为了证明puGAN模型的有效性,本文进行了2组对比实验:第1组实验对比了OC、SVM[19]、神经网络(neural network, NN)[20]以及puGAN这4种模型的效果;第2组实验对比了GAN模型在不同使用条件下的效果.下面将分别阐述这2组实验.
3.2 传统模型与puGAN模型对比
实验通过调整模型不同的超参数进行交叉验证训练,得到了不同准确率下对应的数据召回率.根据此准确率和召回率,使用ROC曲线来对模型效果进行比较与分析.如图4所示是不同模型在实验数据集上的表现.
图4中,横轴表示模型的召回率,纵轴表示模型的准确率,ROC面积越大表示模型效果越好.
从图4可以看出,单类模型的ROC面积为0.761,在准确率为80%时召回率不足60%,效果明显低于其他的几类模型.SVM与神经网络(NN)模型在ROC曲线的评估上效果相当,当准确率为80%时召回率均为77%左右.而puGAN模型在准确率为80%时召回率达到了85%左右,对应的ROC面积也明显高于其他模型.
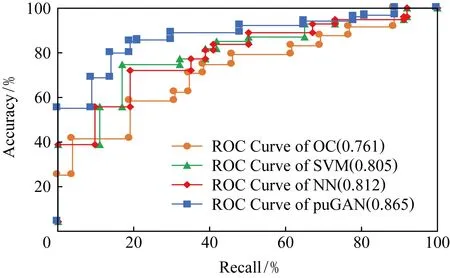
Fig. 4 Comparison of ROC curves among OC, SVM, NN and puGAN图4 OC,SVM,NN和puGAN的ROC曲线对比图
此外,我们还观察了这4种模型的训练误差和测试误差随迭代次数增加的变化,这种变化反应模型的拟合情况,如图5所示:
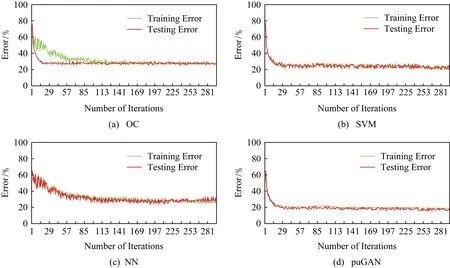
Fig. 5 Training error and Testing error among OC, SVM, NN and puGAN图5 OC,SVM,NN和puGAN训练误差和测试误差分析对比图
由图5可知,单类模型明显存在着欠拟合的情况,经过多轮的迭代,训练误差始终维持在26%左右,整体效果较差.SVM和神经网络的表现明显优于单类模型,训练误差维持在21%左右.但随着迭代次数的增加,由于神经网络结构复杂,它的测试误差不断上升,出现了过拟合的情况.puGAN模型在训练初始阶段,收敛速度会略慢于SVM以及神经网络,但在最终效果却明显优于上述2类模型,且模型表现稳定,训练误差和测试误差均维持在15%左右.
综上,由于单类模型在训练过程中只利用了正样本进行学习,而忽略了大量的无标签样本,所以整体实验效果均不佳.SVM与神经网络均使用了正样本和无标签样本进行二分类学习,SVM模型结构较神经网络简单,因此收敛速度较快,在准确率和召回率上二者差别不大.puGAN对正样本和无标签样本进行学习,生成伪正样本来弥补数据不足的问题,同时生成伪无标签样本来提高判别器对正样本的识别能力.因此,从ROC曲线以及模型拟合情况来看,puGAN的效果明显优于传统的机器学习模型.
3.3 3种GAN模型对比
第2组实验中,我们对比分析了puGAN模型与另外2种未校正模型在准确率、召回率以及训练误差、测试误差等指标上的表现情况.其中未校正的模型包括未对正样本建模(本文称GAN1)以及未对无标签样本建模(本文称GAN2)这2种情况.
如图6所示,puGAN模型的ROC面积略高于GAN1和GAN2这2种未校正的模型.在这3种模型中,GAN1模型面积最小,其值只有0.835.该模型由于未能够对正样本进行分布上的学习,使得训练得到的模型在准确率以及召回率上的表现不佳,得到的分类面也偏于无标签样本数据一方.GAN2模型虽然也受到了训练样本不均匀的影响,但是在准确率和召回率上的表现却略好于GAN1模型,原因是GAN2模型对正样本进行了建模和重采样,使其受到的正样本数据不足的影响略低于GAN1模型.
此外,我们也同样观察了上述3种模型训练误差和测试误差的变化,并对它们的拟合情况进行了分析.如图7所示为3种模型的训练误差以及测试误差随着迭代次数增加的变化情况.从图7中可以看出,GAN1模型在训练初期存在过拟合的情况,但随着迭代次数的增加,过拟合逐渐缓解,效果趋于稳定.GAN2模型在训练过程中整体效果较为稳定,但是误差较大,始终维持在20%以上.而puGAN模型最终训练误差和测试误均在15%左右且效果稳定.
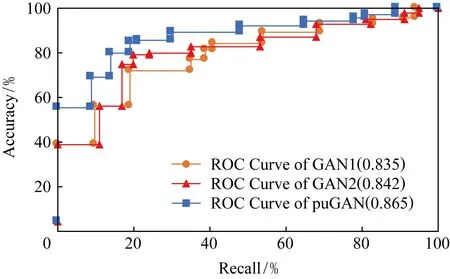
Fig. 6 Comparison of ROC curves among GAN1, GAN2 and puGAN图6 GAN1,GAN2和puGAN的ROC曲线图
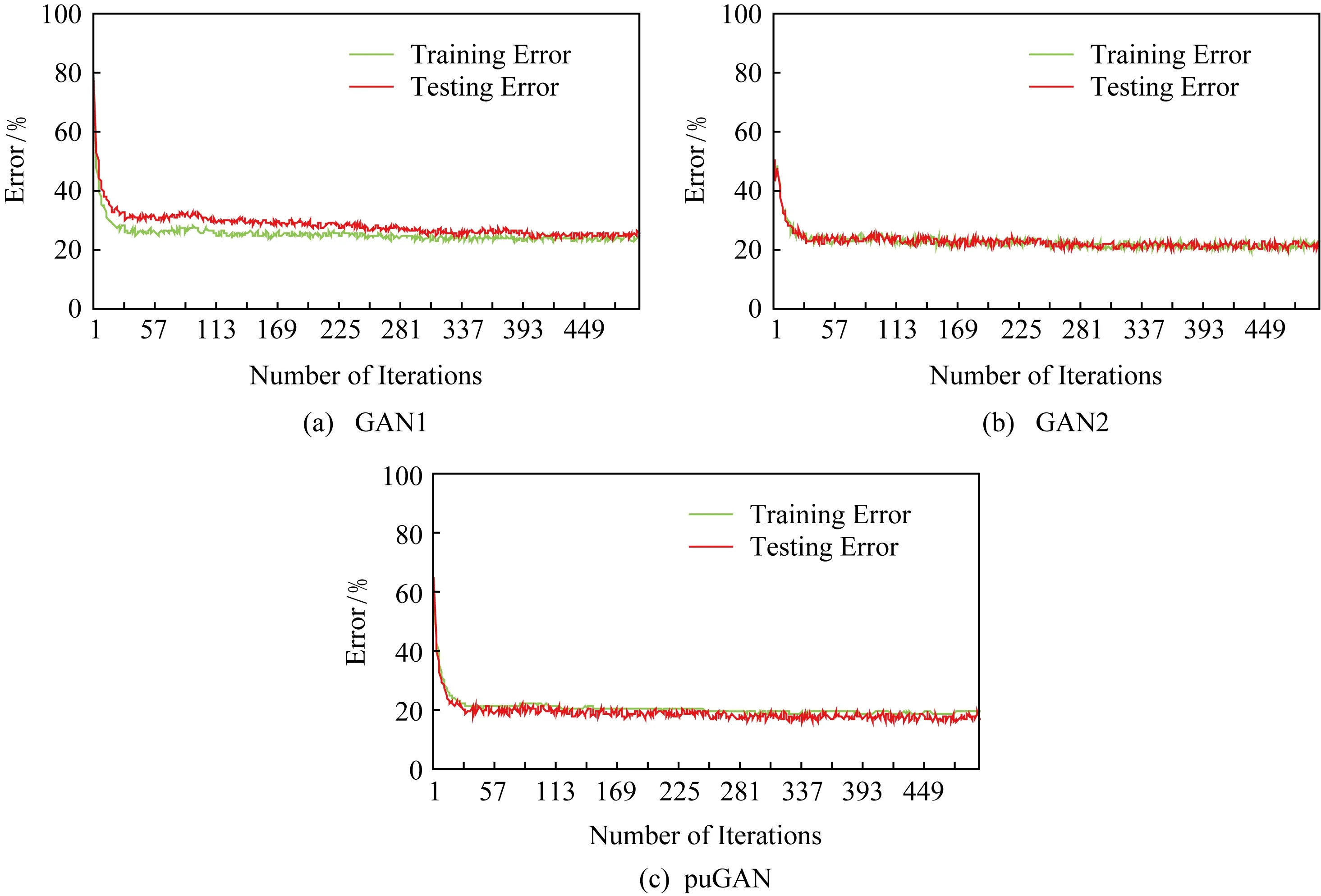
Fig. 7 Training error and Testing error among GAN1, GAN2 and puGAN图7 GAN1,GAN2和puGAN训练误差和测试误差分析对比图
综上所述,在GAN的3类模型中,puGAN模型在ROC面积以及稳定性上表现更为突出.
4 结 论
本文讨论了puGAN模型在POI定位中的应用.实验表明,该模型通过对正样本和无标签样本进行建模和生成,提升了POI定位的准确率和召回率,从而有效解决了数据样本不足以及半监督学习中噪声过大的问题.
实验还表明,该模型能够避免复杂模型所带来的过拟合问题,且具有更好的稳定性.此研究为现有的POI定位系统提供了新的指导意义.
虽然puGAN模型在准确率、召回率和稳定性上表现优秀,但是却存在迭代速度较慢的缺点.在大数据的背景下,提升模型训练速度也早已成为了一个重要的课题.在今后的研究中,我们会改进训练过程中最优化的方法来提升模型训练的效率.
