基于注意力掩模融合的目标检测算法
2019-09-13董潇潇何小海吴晓红卿粼波滕奇志
董潇潇,何小海,吴晓红,卿粼波,滕奇志
(四川大学 电子信息学院,四川 成都 610065)
1 引 言
目标检测是结合了目标定位和识别2个任务的一项基础性计算机视觉任务,它的目的是在图像的复杂背景中找出若干目标,给出一个精确的目标边框(Bounding box),并判断该边框中目标所属的类别[1]。目标检测在人工智能和信息技术的诸多领域如机器人视觉、消费电子、自动驾驶、人机交互、基于内容的图像检索、智能视频监控[2-3]等有着广泛的应用。
目前,基于深度学习的目标检测算法主要分为两类,一是单阶段方法,二是两阶段方法。两阶段方法将检测问题划分为两个过程,首先产生区域建议(Region proposals),然后对候选区域进行分类和边界框回归,这类算法的典型代表是基于区域建议的R-CNN系列算法,如R-CNN[4]、SPPNet[5]、Fast R-CNN[6]、Faster R-CNN[7]、Mask R-CNN[8]等。一阶段方法采用基于回归的思想,跳过区域建议阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可得出最终的检测结果,故在检测速度上有更好的结果,其代表性算法有:YOLO[9]、SSD[10]、Focal Loss[11]等。SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用多尺度的特征图谱进行回归,既保持了YOLO速度快的特性,也保证了Faster-RCNN精度高的优点。随后为了进一步提高SSD的精度和对小目标的检测能力,各种不同的方法被提出来。Fu等[12]为了提高浅层特征的表征能力,将基础网络由VGG替换为ResNet,并借助反卷积模块以增加各层之间的上下文信息,提高了对小目标的检测能力,但是速度相对于SSD却大幅下降。Liu等[13]从人类视觉的感受野结构出发,提出了感受野模块(RFB),通过构建多分支卷积层和随后的空洞卷积层以加强网络学习到的深层特征。Zhang等[14]综合一阶段和两阶段目标检测的技巧,一方面引入两阶段中对包围框由粗到细的思想,一方面结合特征融合用于检测网络,取得了很好的效果。Liang等[15]利用多层卷积特征进行目标检测,其中利用浅层卷积特征实现目标定位,利用深层卷积特征实现目标识别,以充分发挥各层卷积特征的作用。
近年来,注意力机制在计算机视觉中的应用逐渐增加。现有的视觉注意模型可分为软注意模型和强注意模型。软注意模型以确定性的方式预测注意区域,由于它是可微的,故可以使用反向传播进行训练[16],让神经网络学到每一张新图片中需要关注的区域,因而形成了注意力。强注意模型随机预测图像的注意点,通常通过强化学习或最大化近似变分下界来训练。一般来说,软注意模型比强注意模型更有效,因为强注意模型需要抽样进行训练,而软注意模型可以进行端到端训练。Hu等[17]设计了目标关系模块,其注意力权重主要由外观特征权重和空间权重组成,通过联合其他目标的信息从而允许对它们之间的关系进行建模。Wang等[18]提出了一种基于Attention的残差学习方式,设计了一种可堆叠的网络结构,并从可堆叠的基本模块中引入了注意力机制,不同的注意力特征图谱可以捕捉到不同类型的注意力。Hu等[19]重点关注通道关系,显示地建模特征通道之间的依赖关系,自适应地重新校准通道特征响应,从而增强有用的特征而抑制冗余特征。综上,为了让目标检测重点关注有效信息,本文将注意力模型融入到目标检测中去,在SSD和RefineDet基础上提出了基于注意力掩模融合的改进的特征金字塔算法,主要用于改进当前目标检测算法缺乏视觉注意力信息的缺点。实验结果表明,本文算法进一步改进了目标检测的精度,同时也能保持高效的速度。
2 RefineDet
RefineDet的损失函数主要包含ARM和ODM两方面。ARM包含二进制分类损失Lb和回归损失Lr,ODM包含多类别分类损失Lm和回归损失Lr,ARM和ODM两部分的损失函数一起前向传播,损失函数如下:
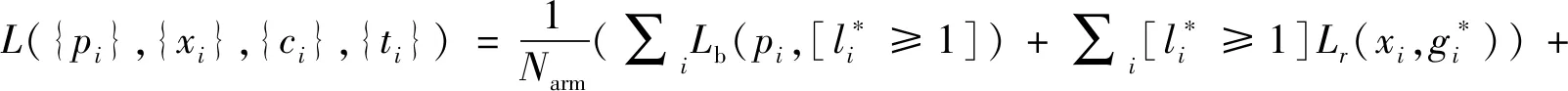
(1)
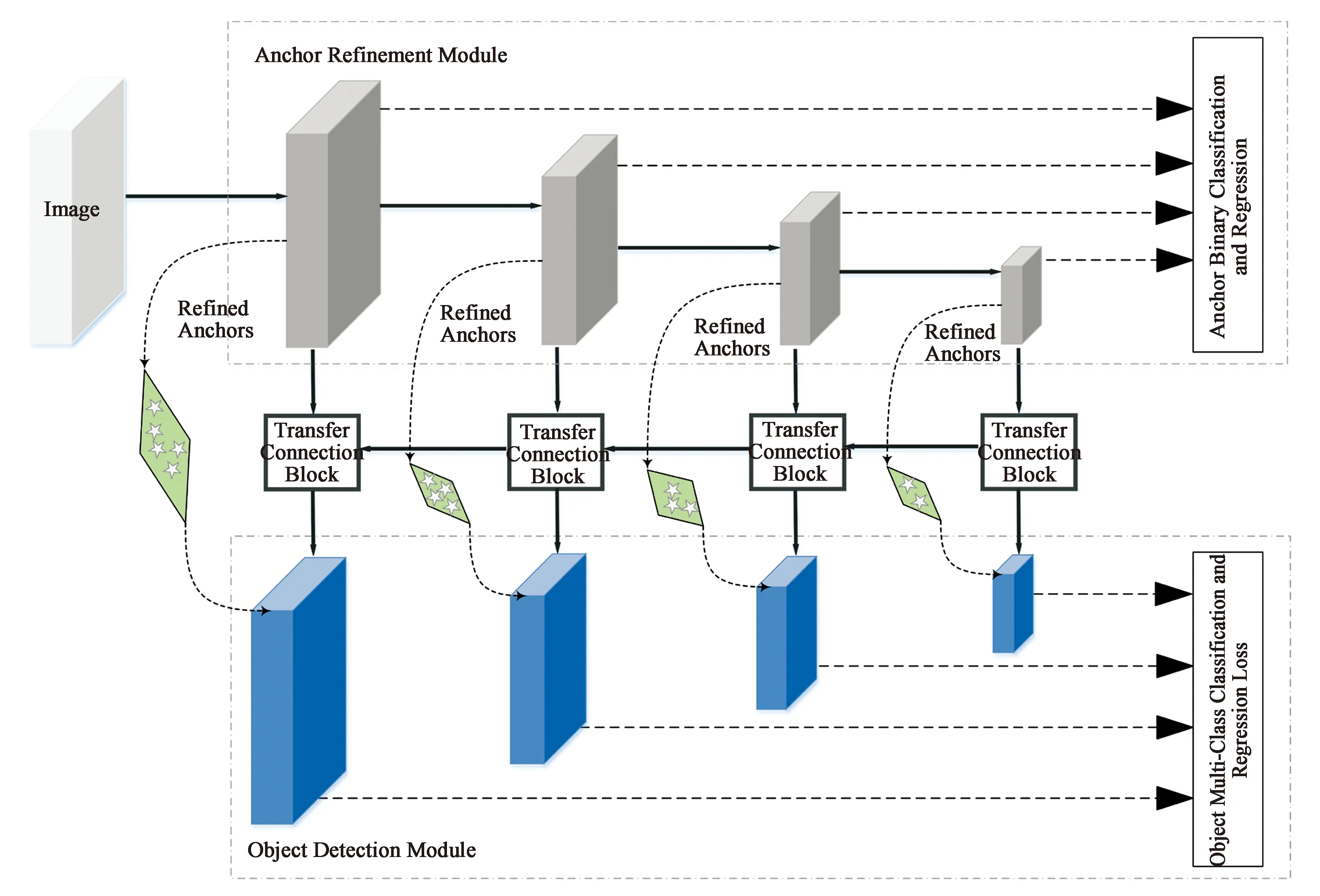
图1 RefineDet网络结构Fig.1 Network of RefineDet
3 本文算法
3.1 网络结构
算法的整体网络结构如图2所示。以输入尺寸为320×320的图像为例:
(1)使用基准网络VGG16[20]提取特征,经过卷积操作和6次下采样操作后,得到多尺度的卷积特征层。
(2)使用基本的卷积层conv4_3,conv5_3,fc7以及conv6_2进行初步的二分类和包围框回归操作,以得到预选框,减少负样本搜索。
(3)将注意力掩模模块Attention Mask Module(AMM)和特征金字塔结构结合起来,即将顶层特征同底层特征融合后,再辅之以注意力信息AMM,得到更加有效的特征P1,P2,P3,P4。
(4)最后将上述特征直接用于多分类和回归操作,不断训练迭代模型,得到最终的检测结果。
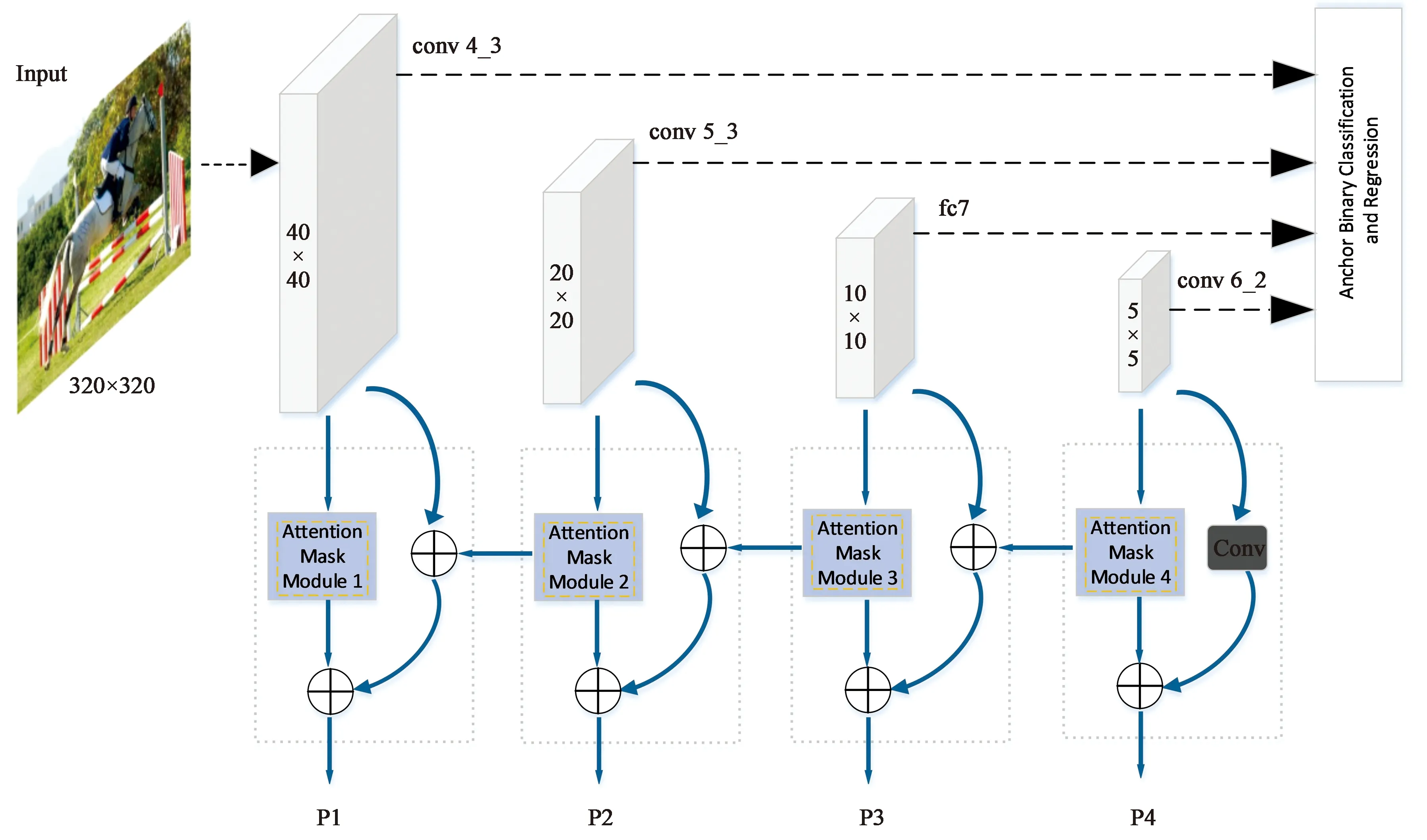
图2 本文算法网络结构Fig.2 Network of proposed algorithm
3.2 注意力掩模模块
观察一幅图片时,人脑并不均衡地关注整幅图片,而是带有一定权重分布的。对于深度学习中的目标检测任务而言,想要检测出相关的人或者特定物体,将其与背景天空等区分开来,同样需要有一定的选择性侧重。为此,引入文献[18]中的注意力模型,将原本的残差结构改为基本的神经网络结构,并去除了一些卷积层,以便更加适应本文的网络训练。
注意力掩模模块(AMM)的结构图如图3所示。在本文中,使用基本的卷积函数(conv),激活函数(relu)和池化函数(pool)来构建基本网络。每个注意力掩模模块分为两个分支:掩模分支和主干分支。给定输入x,主干分支经过卷积后得到输出G(x),掩模分支经过卷积和反卷积操作得到相同尺寸的输出M(x)。掩模分支中,首先经过两次conv,relu,pool操作,然后经过两次deconv操作得到特征图谱S(x),最后经过sigmoid函数得到输出的掩模:
在选取特征点匹配的算法时要考虑与其搭配的特征点提取算法,使用特征提取过程得到的特征描述符(DESCRIPTOR)数据类型有的是FLOAT类型的,比如说:SURF,SIFT,有的是UCHAR类型的,比如说有ORB,BRIEF。对应FLOAT类型的匹配方式有:FLANNBASEDMATCHER,BRUTEFORCE等。对应UCHAR类型的匹配方式有:BRUTEFORCE。所以ORB特征描述子只能使用BRUTEFORCE匹配法。另外还有一种相对于更加传统的SURF+FLANN的方法。
(2)
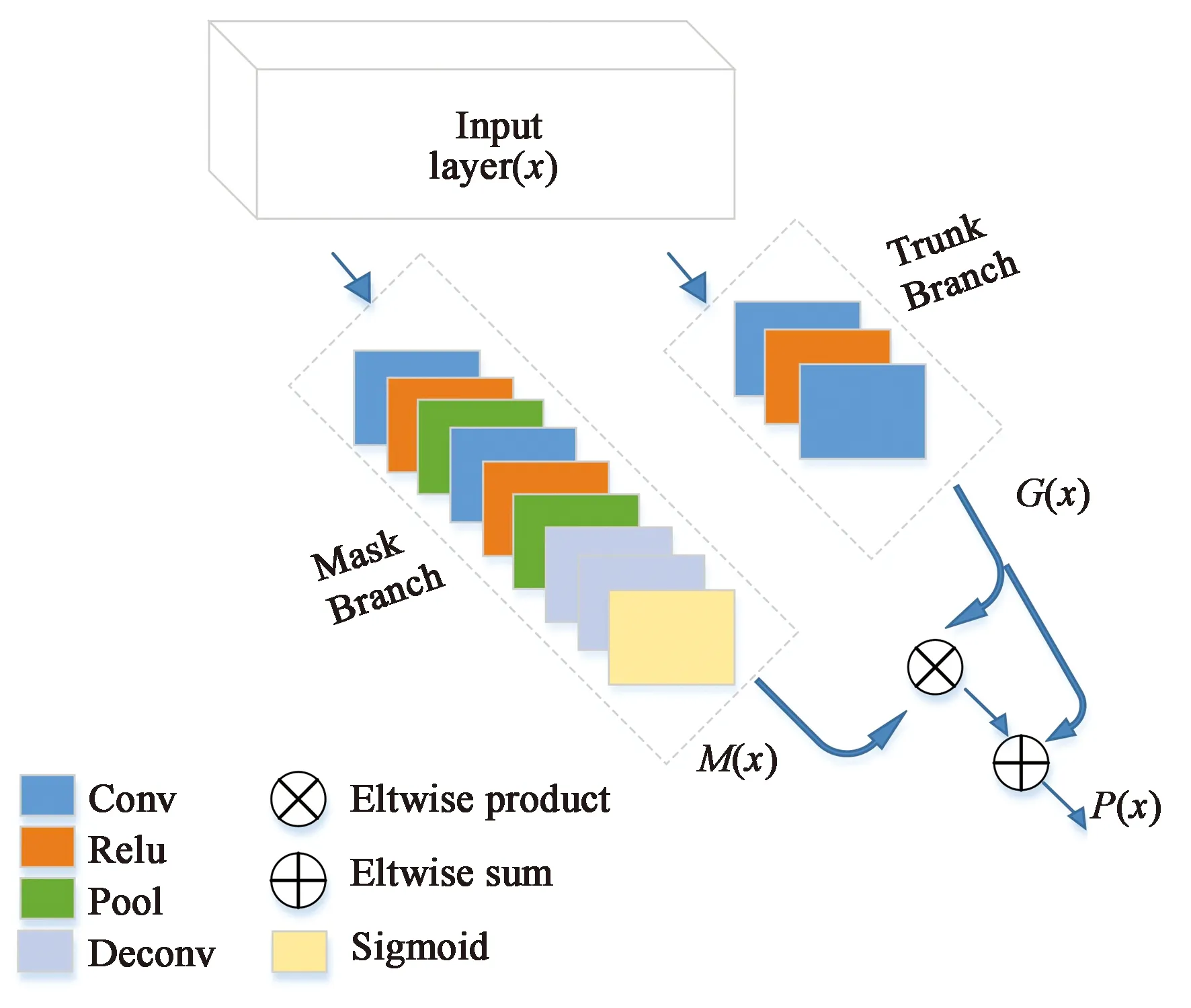
图3 注意力掩模模块Fig.3 Attention mask module
输出掩模类似于Highway Network[21]中的门控单元,控制着主干分支的神经元,可以自适应地学习到有效的特征并且抑制噪声。主干分支中,经过两次conv函数得到主干输出。最后输出的注意力模型P(x)公式如下所示:
Pi,c(x)=(1+Mi,c(x))*Gi,c(x),
(3)
式中:i代表神经元的空间位置,c代表神经元的通道位置。类似于残差网络中的恒等映射,M(x)的输出范围为[0,1],当M(x)接近0时,P(x)的输出接近原始的特征G(x)。
在注意力掩模模块中,注意力掩模不仅在前向传播中充当特征选择器,在反向传播中也能进行梯度更新。特征掩模的梯度如下所示:
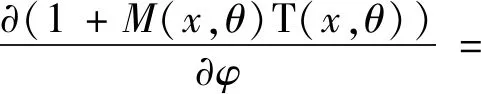
(4)
其中:θ是掩模分支参数,φ是主干分支参数。
3.3 改进的特征金字塔融合
SSD网络虽然取得了较好的效果,但由于其只在若干个特征图谱上进行检测,并没有结合不同尺寸的特征,导致低层的特征图谱缺乏语义信息,这样不利于小目标的检测。而RefineDet网络采取侧边连接的方法,将高层语义信息同低层定位信息融合在一起,可以进行多种尺度的检测,仍然缺乏注意力信息。本文提出了融合不同特征图谱与注意力掩模的结构,不仅能进行多尺度检测,还可以结合注意力模型关注感兴趣区域,从而有效地检测出所有尺度物体。具体网络结构如图4所示。
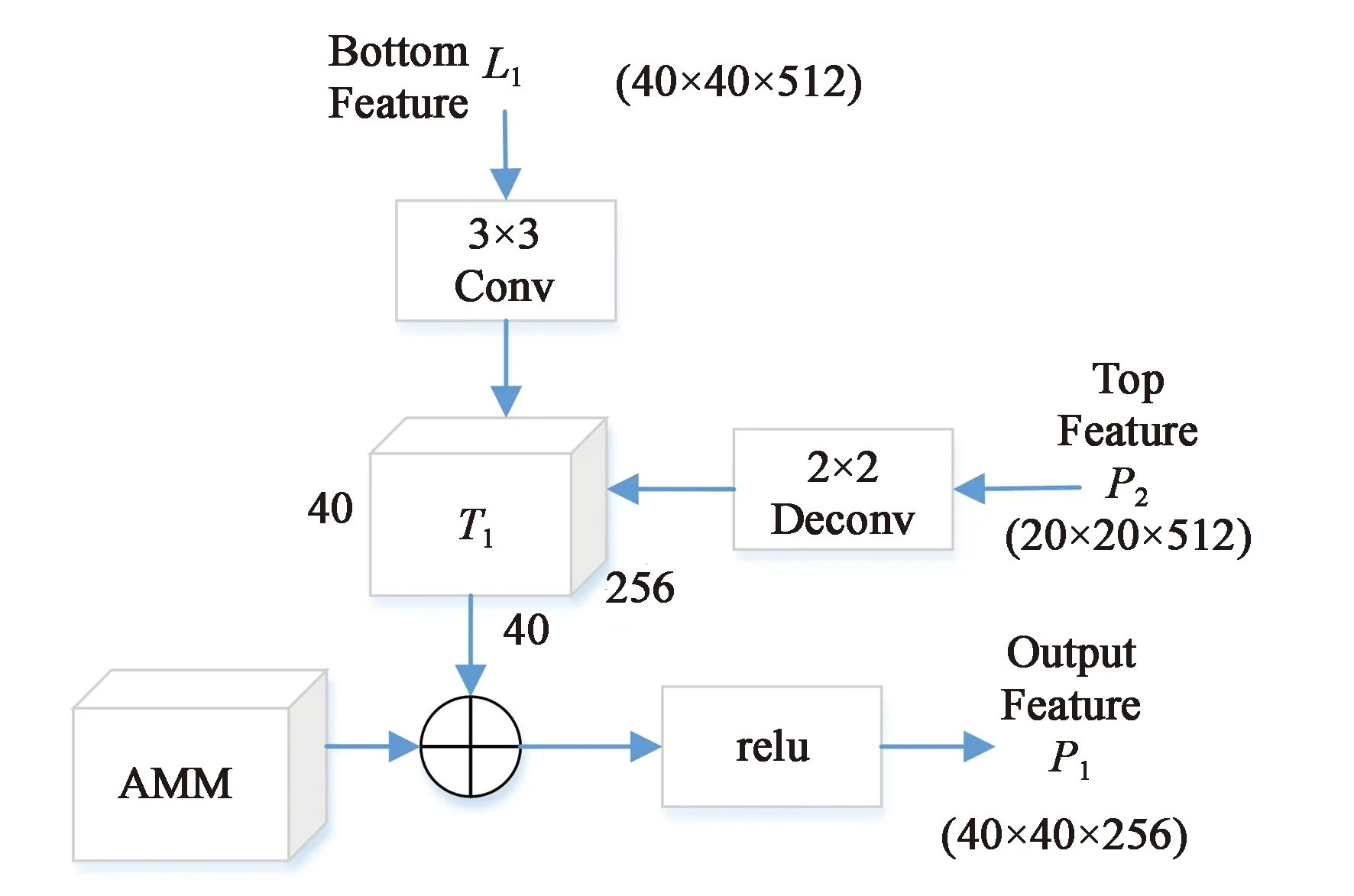
图4 特征金字塔融合结构Fig.4 Feature pyramid fusion structure
输入的特征图谱为(H×W×C),其中H和W代表高和宽,C代表通道的个数。对于底部特征L1,首先经过3×3的卷积层进行特征降维,将维度从512降到256,对于检测特征P2,经过2×2的反卷积操作,在扩大特征图谱同时也进行了降维的操作,得到的输出为(40×40×256);然后将上述输出进行eltwise sum操作,得到融合后的特征图谱T1亦为(40×40×256);最后将注意力掩模模块同T1融合以增加注意力信息,经过Relu层后得到的检测特征P1可应用于检测系统。
若图片中存在多种尺度的目标,低层的特征如P1和P2可以用来检测小目标,而高层的特征如P3和P4具有更大的感受野,负责检测大目标。
4 实 验
本次实验在以下两个公开数据集中开展:PASCAL VOC[22]2007和PASCAL VOC 2012。PASCAL VOC数据集包含20类物体,包括飞机、自行车、鸟等。本文的实验平台为:Ubuntu 16.04.5,Nvidia GTX 1080Ti GPU,Intel(R)Xeon(R)CPU E5-2686。采用的深度学习框架为Caffe,采用的精度评价指标为mAP(Mean average precision),速度评价指标为fps(Frames per second)。
4.1 VOC2007数据集
VOC2007数据集的训练集有5 011张,测试集有4 952张。本次实验在VOC2007 trainval和VOC2012 trainval上进行训练,在VOC2007 test数据集上测试。所有的方法在VGG16基准网络中进行预训练。如图2所示,使用conv4,conv5,fc7以及新增的conv6层进行定位和置信度的预测。使用Multistep方式来调整学习率,即在前80k次迭代中学习率设置为10-2,随后20k和40k次迭代中学习率分别设置为10-3和10-4。输入图片尺寸为320×320时,训练时batch size设置为16,GPU数量为1;当图片尺寸为512×512时,由于一块GPU显存不够,故采用两块GPU进行联合训练。测试时batch size设置为1。

表1 不同算法在VOC2007和VOC2012数据集上的测试结果Tab.1 Test results of different algorithms on VOC2007 and VOC2012 datasets
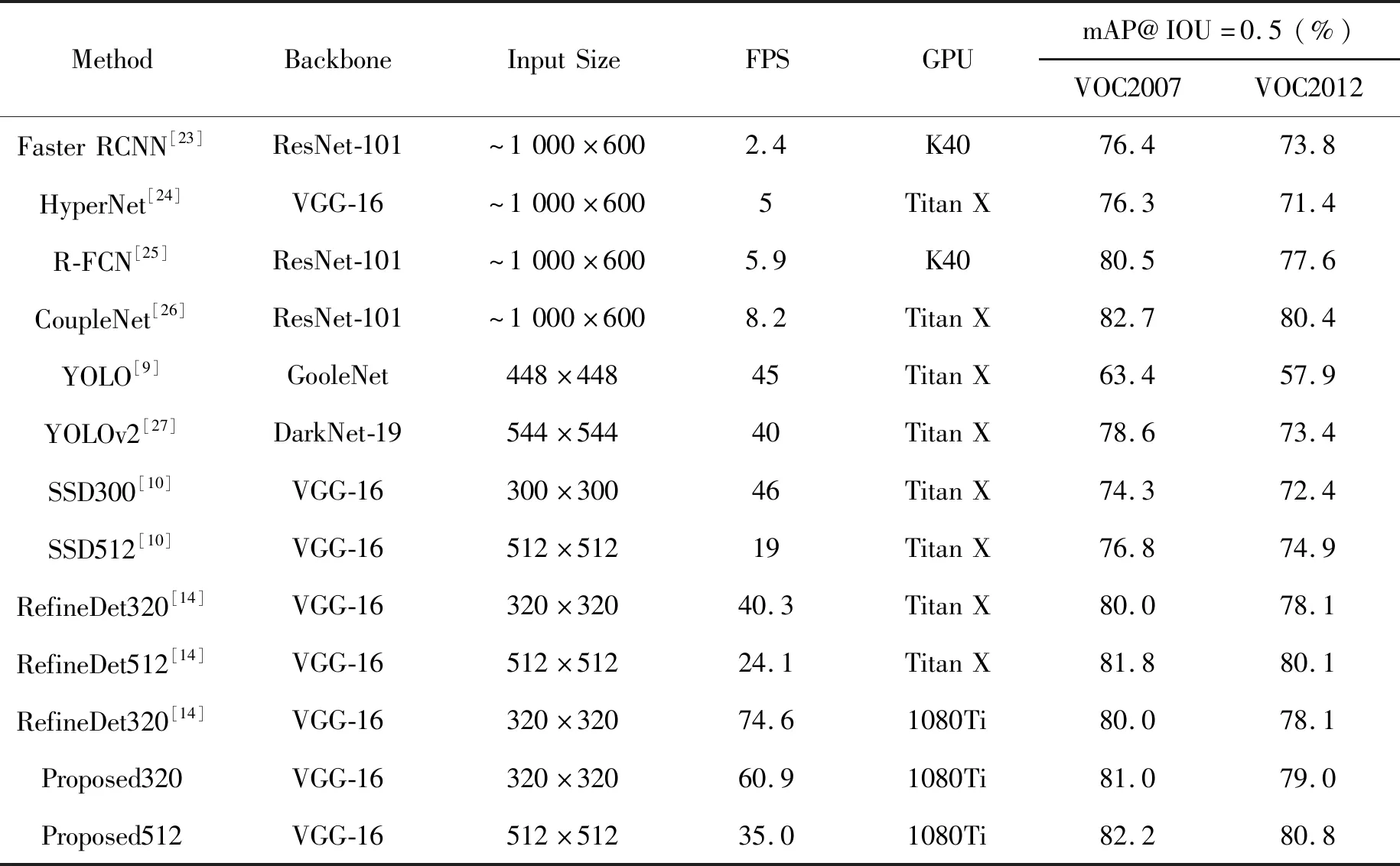
续 表
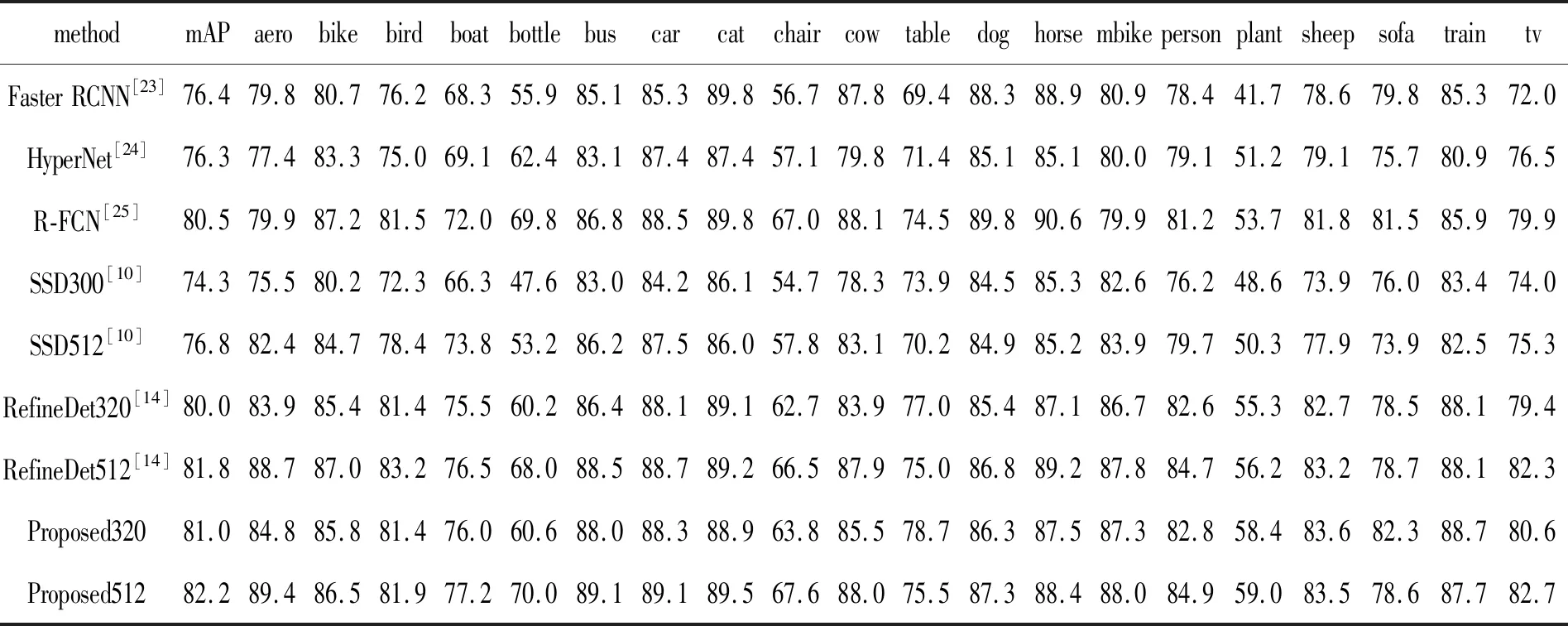
表2 不同算法在VOC2007数据集上20类别的AP比较Tab.2 AP comparison of 20 categoriesfor different algorithms on VOC2007 dataset
如表1所示,将本文的算法与其他主流的目标检测算法进行对比。对于320×320的输入,mAP达到了81%,与RefineDet 320相比提高了1%,与SSD相比提高了6.7%。由于本文测试所使用的GPU不同于RefineDet,故将RefineDet中在VOC07+12数据集上训练的320×320的模型在1080Ti上进行测试,观察得到,本文算法的速度同其相比降低了18.4%。在速度和精度的均衡下,本文算法仍能取得较好的效果。对于512×512的输入,mAP为82.2%,比RefineDet的精度提高了0.4%,这也证明了本文算法的有效性。同精度更高的基于区域的目标检测方法进行比较,可以看到,本文算法在尺寸小于CoupleNet的情况下,mAP几乎能够达到CoupleNet的效果。
表2中列举出各类算法中20类目标的AP(Average precision),可以看到大部分类别的平均精度都有提升。
4.2 VOC2012数据集
VOC2012数据集的训练集有11 540张,测试集有10 991张。本次实验在VOC2007 trainval和VOC2012 trainval上进行训练,在VOC2012 test数据集上测试。使用Multistep方式来调整学习率,即在前160k次迭代中学习率设置为10-2,随后40k和80k次迭代中学习率分别设置为10-3和10-4。对于320×320和512×512的输入,训练的batch size设置为16,并且使用两块GPU进行训练。其余实验设定和4.1中相同。
如表1所示,Proposed320 mAP为79.0%,与RefineDet 320相比提高了0.9%,与SSD相比提高了6.6%。同二阶段方法相比,本文算法比精度最高的CoupleNet低了1.4%。Proposed512 mAP为80.8%,与RefineDet 320相比提高了0.7%,且精度超过了CoupleNet,为所提算法中最高的。
4.3 定性结果
图5给出了本文算法模型在VOC2007和VOC2012数据集上的具体测试结果。

图5 VOC2007和VOC2012数据集的测试结果。(a)VOC2007测试结果,强调检测的多尺度效果;(b)VOC2007测试结果,重点检测小目标;(c)VOC2012测试结果,强调检测的多尺度效果;(d)VOC2012测试结果,重点检测小目标。Fig.5 Test result on VOC2007 and VOC2012 dataset.(a)Test result on VOC2007,emphasizing the multiscale effect of detection;(b)Test result on VOC2007,focusing on small targets;(c)Test result on VOC2012,emphasizing the multiscale effect of detection;(d)Test result on VOC2012,focusing on small targets.
5 结 论
本文提出了一种基于注意力掩模融合的目标检测算法,通过神经网络提取特征得到多尺度卷积特征图谱,初步进行二分类和回归,在特征金字塔结构中结合注意力掩模模块进行多尺度的检测。实验结果证明:对于320×320的图片输入,本文算法在VOC2007和VOC2012数据集上达到了81.0%mAP和79.0%mAP,检测速度为60.9 fps;对于512×512的图片输入,本文算法在VOC2007和VOC2012数据集上达到了82.2%mAP和80.8%mAP,检测速度为35.0 fps,实现了精度和速度的均衡要求。
