基于流式处理的Web漏洞攻击检测技术研究
2019-09-13谢江涛卜文娟
◆谢江涛 卜文娟 王 阳
基于流式处理的Web漏洞攻击检测技术研究
◆谢江涛 卜文娟 王 阳
(信息工程大学数学工程与先进计算国家重点实验室 河南 450001)
随着互联网与国家发展的联系日益紧密,网络安全已经成为关系国家政治稳定、经济社会发展以及国防军队建设的“第五疆域”。而Web安全作为网络安全的重要组成部分,也越来越受到人们的重视。本文就基于流式处理的Web漏洞攻击检测技术进行了研究,供相关读者参考。
网络安全;Web漏洞;攻击检测
随着互联网与国家发展的联系日益紧密,网络安全已经成为关系国家政治稳定、经济社会发展以及国防军队建设的“第五疆域”。而Web安全作为网络安全的重要组成部分,也越来越受到人们的重视。在网络安全领域,针对Web漏洞攻击的检测是防范APT攻击的重要步骤。目前,Web的攻击检测系统有基于策略[1],基于行为说明[2],基于特征以及基于异常的检测。前两种检测方式对于持合法访问权限的攻击方式检测能力较差,应用较少;基于特征的检测由于对特征库依赖性高,容易导致无法检测未知攻击,漏报率较高,同时,过大的特征库也会导致检测系统的实时性下降。基于异常的检测由于对正常行为模型依赖性强,容易导致正常行为被误报,误报率较高。
随着网络流量的不断增长以及Web应用种类,流量特征的不断增多,现有攻击检测技术呈现出实时性差,泛化能力弱以及难以同时降低误报率与漏报率的问题,不能较好地适应日益增长的安全防护需求。因此,研究一种实时性强,泛化能力强以及低误报率,低漏报率的Web攻击检测技术就显得非常必要。
1 研究现状
现有检测技术主要分为两种:一是基于特征的Web入侵检测,二是基于异常的Web入侵检测。
(1)基于特征的Web入侵检测系统从大量已知攻击中提取特征,建立模型,与特征匹配的行为即可被判定为入侵行为,不匹配的则为正常行为。目前,基于特征的Web入侵检测技术发展时间较长,技术也较为成熟,主流的Snort,Bro IDS都是基于特征的。但由于攻击识别依赖特征库,因此无法检测未知攻击,漏报率较高。且由于特征库的不断增大,导致了检测效率降低。现有基于特征的入侵检测系统所采用的检测方法有模式匹配,专家系统,状态转换分析等。
(2)基于异常的Web入侵检测技术是基于正常行为的检测方法,通过将当前用户行为与过去观察到的正常行为进行比较,当前行为与正常行为之间存在重大偏离时,即判定为入侵行为,否则判定为正常行为。这种检测的优势是能够对未知的攻击进行检测,有着一定的泛化能力。但由于基于异常的检测起步较晚,检测模型构建往往不够完善,误报率往往偏高。基于异常的检测技术主要分为两种:一是基于统计分析的Web入侵检测,二是基于机器学习的Web入侵检测。
2 Web漏洞
Web应用指采用B/S 架构、通过HTTP 或HTTPS 协议访问的各种应用服务统称。目前的Web应用访问中,大多涉及服务器端的动态处理,因此各种应用攻击问题不断呈现。此外,由于开发人员安全意识不强,对用户参数输入检查不严格,也导致了Web应用安全问题的出现。常见的Web漏洞有以下几类:(1)信息泄露漏洞;(2)目录遍历漏洞;(3)命令执行漏洞;(4)文件包含漏洞;(5)SQL注入漏洞;(6)跨站脚本漏洞。SQL注入漏洞和跨站脚本漏洞出现最多,利用最广泛,造成的危害也最大。Web漏洞攻击检测问题的本质是二分类问题,在利用单一特征进行检测时,可作为一个线性分类问题,多特征检测时则作为线性不可分问题。
3 模型构建流程
根据基于流式处理的Web漏洞攻击检测技术需求,设计Web漏洞攻击检测模型构建流程。构建流程分为两大部分,第一部分是数据准备阶段,第二部分是模型训练验证阶段。第一部分从数据集处理开始,经过样本数据分类标记,特征参量提取,可完成前期的数据准备工作。接着将准备好的数据按照7:3的比例随机分为两部分,训练数据用于模型训练,训练完成后通过测试数据对模型进行验证,若不满足预期效果,则对模型进行调整优化。选取合适特征是构建攻击检测模型的重要步骤。仅通过人工筛选容易造成特征的遗漏,而仅通过算法筛选则可能会混入无用信息。因此,通过采用基于Apriori算法与人工分析结合的方式,提高挖掘的准确性与完整性。
Apriori算法,是经典的关联分析算法,用于挖掘数据内涵的未知的数据关系。核心思想是基于两阶段频集思想的递推算法。算法的第一阶段是对频繁项集进行挖掘,第二阶段是产生关联规则。
首先介绍有关支持度,置信度和频繁K-项集的概念: 1.支持度:设有事件A,B,其支持度代表事件A,B同时发生的概率。即:
(1)支持度:设有事件A,B,支持度代表事件A,B同时发生的概率。
(2)置信度:设有事件A,B,置信度代表事件A发生的前提下发生事件B的概率。
(3)频繁K-项集:设事件A包含K个元素,称为K-项集事件A。若该事件满足最小支持度阈值,则称为频繁K-项集。
Apriori算法步骤如表1所示(其中sup表示支持度,conf表示置信度)。

表1 Apriori算法
XSS攻击中,存在着一定数量的敏感词集。为了准确全面地挖掘出词集,本文首先对样本集中的单词利用符号集进行分割,接着通过Apriori算法,挖掘其中的关联规则。最后通过人工分析去除无效的关联规则,得到敏感词集。
由于无法直接识别样本集,需要逐行将样本向量化,按照一定分割符将其分割成单词向量,根据XSS语句中单词之间常见的分割符及相关编码变形,设定如表2分割符集并使用正则表达式对XSS语句进行分割。
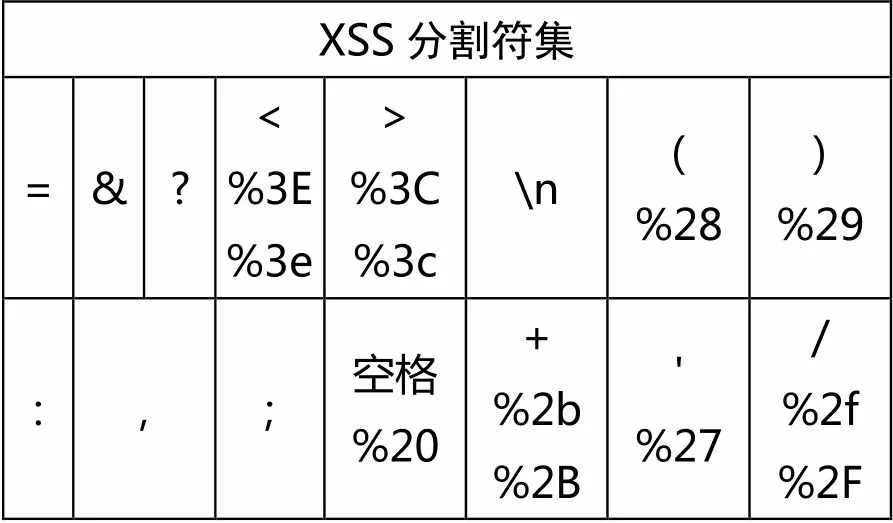
表2 XSS分割符集
表2包含了常见的单词分割符,可自定义添加新的分割符,对分割规则进行拓展。
接着对单词向量集使用Apriori算法进行关联规则分析,首先对最小支持度为0.1,最小置信度为0.6的情况做分析,第三项数值代表二者的置信度,置信度越高,说明二者关联性越强。
从以上结果中可以发现,由于最小支持度较高,导致结果主要集中在经常出现script,alert等单词中,部分出现概率较小语句的关联关系没有被挖掘出来。接着通过降低最小支持度,提升最小置信度进行挖掘,挖掘出现概率较低的强关联关系。这样就克服了词频统计法无法挖掘出现概率较小的单词向量的问题。最终取置信度为0.8以上的关联关系,再次人工筛选后得到敏感词集为:alert,script,onerror,onchange,onclick,onload,eval,src,prompt。
与XSS攻击类似,SQL攻击中同样存在敏感词集。因此,本文采用与XSS敏感词集挖掘同样的方式对SQL敏感词集进行挖掘。观察样本集。设定分割符集并使用正则表达式对SQL语句进行分割(表3)。
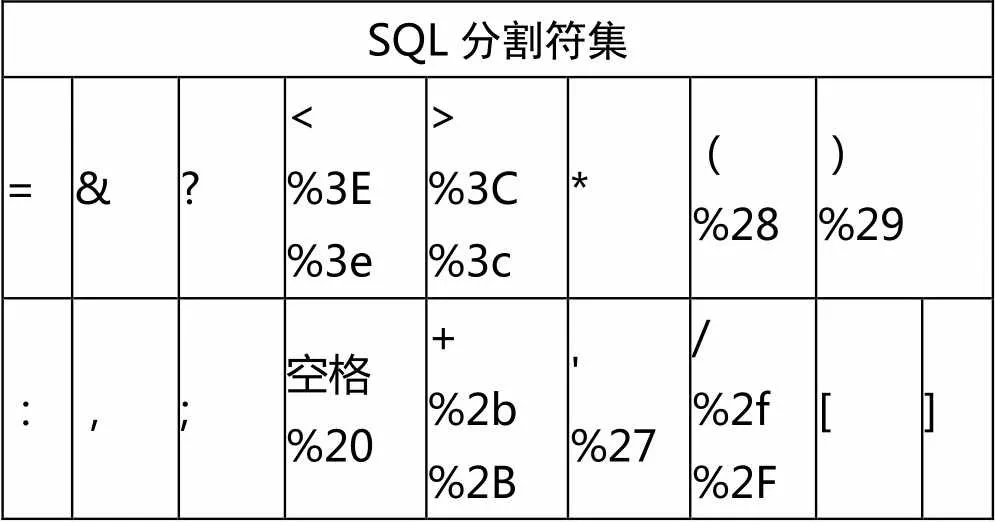
表3 SQL分割符集
接着调整最小支持度与最小置信度进行多次挖掘。最终取置信度为0.8以上的关联规则,结合人工筛选后得到敏感字符集为:and,or,xor,version,substr,len,exists,mid,asc,inner join,xp_cmdshell,exec,union,order,information_schema,load_file,information schema,load data,database,group,contact。
4 检测构建模型与测试
在实际检测中,往往无法做到对攻击行为的完全检测。Kumar和Stafford提出检测结果和实际情况之间存在以下四种可能:
(1)真阳性(True Positives,TP),指的是一个攻击行为,检测系统检测出该行为是攻击。
(2)真阴性(True Negatives,TN),指的是一个正常行为,检测系统检测出该行为是正常的。
(3)假阳性(False Positives,FP),指的是一个正常行为,检测系统认为该行为是攻击行为并产生报警,也就是所谓的误报。误报会影响正常流量的通讯。
(4)假阴性(False Negatives,FN),指的是一个攻击行为,检测系统认为该行为是正常行为,不进行报警,也就是所谓的漏报。漏报会影响网络和计算机系统的安全。
以上四种情况亦如表4所示:

表4 检测情况分类
为了表征检测模型的性能,根据上文所述检测结果和实际情况之间的四种可能,需要引入召回率(Recall Rate,RR),精确率(Precision Rate,PR)以及综合评价指标F1的概念。
综合评价指标F1:是统计学用于衡量二分类模型精确度的一种指标,对精确率和召回率求调和平均数,从而兼顾了二者对分类模型的影响。
核函数在SVM中的作用是将初始低维线性不可分样本映射到高维特征空间中再构建最优分类平面进行分类。确定恰当的核函数,可以在不增加复杂度的前提下实现高维空间的线性分类。不同的核函数,产生的最优分类平面不同,产生的分类模型也不同。核函数的选择是决定分类性能的重要因素之一。目前SVM中主要选用的四种核函数是:
线性核函数(Linear):该函数适合对低维空间的线性可分样本进行分类。主要优点是复杂度低,缺点是但复杂特征条件下的样本一般是低维空间线性不可分的,应用范围有限。
多项式核函数(Polynomial):多项式核函数主要针对低维空间线性不可分问题进行分类。主要优点是可以根据特征空间维数确定核函数维数。缺点是高维空间下计算复杂度高,效率低,分类器易受偏离较远的样本影响。
径向基核函数(RBF):径向基核函数拥有较好的局部性能,对于距离较近的点分类效果较好,能够有效降低误漏报率。
Sigmoid核函数:该函数与二层神经网络等效,优点是全局收敛性好,缺点是存在局部极值问题。
根据上述核函数特点,结合Web漏洞攻击检测实际,本文选用径向基核函数作为核函数。原因如下:
Web攻击种类较多,针对防护的变形复杂,具有特征维数大,样本数量不一的特点。RBF函数不受样本数量和特征维数限制,适用性强。
5 总结
目前Web漏洞攻击检测技术中存在实时性差,泛化能力弱以及误报率与漏报率难以同时降低的问题,不利于在高速复杂流量条件下开展Web攻击检测。
针对上述问题,本文研究基于流式处理的Web漏洞攻击检测技术,通过研究基于Apriori算法的攻击流量特征关联分析技术,结合人工分析,完成了攻击流量特征挖掘;通过研究基于SVM的模型构建技术与基于网格搜索与K折交叉验证的参数调优技术,完成了Web漏洞攻击检测模型构建;通过将模型部署至流式处理平台,最终实现了基于流式处理平台的Web漏洞攻击检测技术。经实验验证,该技术能具备较强的实时检测能力与一定的泛化能力,同时有效降低了误报率与漏报率。
[1]Dorothy E.Denning. An Intrusion-Detection Model[J]. IEEI Transactions on Software Engineering,1987:222-232.
[2]Juan José García Adeva,Juan Manuel Pikatza Atxa. Intrusion detection in web applications using text mining[J]. Engineering Applications of Artificial Intelligence,2006,20(4).
[3]Garcia V H,Monroy R,Quintana M.Web attack detection using ID3[OL]. http://homepage.cem.itesm.mx/raulm/pub/id3-ids,2013-12.
[4]温凯.自适应WEB入侵异常检测技术的应用研究[D].江西师范大学,2012.
[5]Kumar S.Classification and detection of computer intrusions[D]. West Lafayette:Purdue University,1995.
[6]Callegari C, Cyprus N. Statistical approaches for network anomaly detection[J]. ICIMP Conference,2009,169(1):1-20.
[7]Cao L C. Detecting Web-Based Attacks by Machine Learning[C]//Machine Learning and Cybernetics, 2006 International Conference on. IEEE,2006:2737-2742.
[8]G.Kumar. Classification and Detection of Computer Intrusion. Purdue University,1995.
[9]曹杰.基于SVM的网络流量特征降维与分类方法研究[D].吉林大学,2017.
