面向视频监控的距离度量行人再识别*
2019-09-11简佳雁方志军高永彬
简佳雁, 方志军, 高永彬
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引 言
行人再识别的主要任务是匹配来自无重叠视野区域摄像头的行人图片或视频[1],该技术广泛应用于视频监控、刑侦破案等领域[3]。
行人再识别任务大致为以下两个主流方向[4]:特征提取的方法和距离度量学习的方法。前者的目的是提取行人具有区别性的特征,如:显著性特征、中层特征、颜色特征等。后者主要寻找一个能更好度量行人特征的马氏矩阵,使得相同人之间的特征距离尽量小,不同人之间的特征距离尽量大。2006年,该任务研究开始于用单帧图像进行特征建模并完成一对一匹配的方法,到目前为止,单帧图像的方法已经成为该领域内较成熟的研究方向。但在实际智能视频监控环境中,光照变化、摄像机角度变化、行人服饰相似、背景复杂以及遮挡严重等因素导致行人再识别任务面临着巨大的挑战。若只考虑单帧图像的二维特征很难解决以上问题,而视频可以从时间和空间角度提供更多的特征信息,有助于进行行人匹配与再识别,因此基于视频序列的行人再识别研究应运而生。
目前,基于视频的行人再识别任务研究工作目前为数不多,早期的一部分工作是将其他研究领域的方法用在行人再识别任务上,例如文献[5]的行为识别方法动态时间规整(dynamic time warping,DTW)、文献[6]的视频分割方法等。另外,也有不少方法尝试提取视频中的三维数据来进行外貌表征,如文献[7]提出的HOGHOF,文献[8]的3D-SIFT等。但在新的特征空间下,面临的新问题是:由于运动特征相似,导致类间变化相似,即很难分辨不同的人,因此距离度量学习的研究工作在行人再识别任务中十分重要,2006年,Blitzer J等人[9]提出大间隔最近邻(large margin nearest neighbor,LMNN)分类度量学习算法。该算法最大的亮点在于使用三元形式(xi,xj,xk),对不相似的样本对进行约束,即y(xi)≠y(xj),y(xi)≠y(xk)。只要三元形式的样本尽量可能多地满足不等式d(xi,xk)≥d(xi,xj)+1就可以学习并且得到矩阵M。2008年,Mert D等人[10]在大间隔近邻分类基础上进行优化,提出LMNN-R算法,通过均值的引入,相应的约束比最初的LMNN更强。
本文输入视频序列,用HOG3D[11]提取时序动态特征,并融合颜色、纹理静态特征,结合PFMLNN[12](parameter free large margin nearest neighbor for distance metric learning)距离度量学习,缩小类内距离的同时,约束最近邻负样本对的距离。与LMNN算法相比,PFLMNN专注于增大类间特征距离,且只约束距离目标样本最近邻的负样本对距离,在减少参数量的同时,对于类间特征距离的约束力更强。在训练过程中,根据迭代次数分段给定损失函数的相应权重,在公开数据集iLIDS-VID和PRID-2011(multi-shot)上的实验达到了较好的行人再识别精度。
1 算法实现
1.1 特征提取
视频监控摄像头采集到的行人视频数据会存在很大的噪声,并且整段视频连续帧中部分帧存在遮挡或者分辨率低等问题,根据FEP[13,14](flow energy prole)自动挑选出最具鉴别性的视频序列片段作为输入,如图1所示。
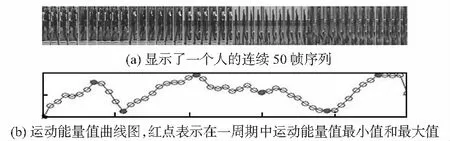
图1 挑选视频序列帧
如上图1所示,定义每一帧图像为I,则一个行人的视频序列定义为Q={I1,…,It},t表示视频序列的帧数。e表示单帧图像I的光流能量值,(vx,vy)表示单帧图像的光流区域,U为图像I下半部分的所有像素点。则FEP计算单帧图像的光流能量值为
(1)
选择光流能量值e最大的视频帧为中心帧It,取以It为中心的前10帧与后10帧,共21帧作为输入视频序列连续帧。
在视频序列上选择HOG 3D[12]提取时间运动信息及空间梯度信息,整合特征为1 200维。并随机选择一帧图像,基于文献[8],将图像裁剪为128×48,每帧图像分为8×16的子块,在水平和垂直方向上有1/2的像素点重叠,共有155个子块提取颜色和纹理静态特征,最终融合颜色和纹理特征向量为1 705维。以上两部分描述了视频中行人的动态特征和静态特征,两种特征互相补充辅助,共为2 905维。
1.2 距离度量学习
采用距离度量学习算法,通过学习到的距离尺度变换,使得同一行人特征之间的距离减小,不同行人之间的距离增大。
(2)
(3)
(4)
若最近负样本满足式(4),根据几何信息关系,则其他所有负样本都符合式(4)的条件。定义最小类间距离的问题
(5)
综上所述,结合式(3)和式(5),本文距离度量学习模型的目标函数为
(6)
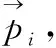
1.3 优化函数

(7)
结合式(2)和式(7),两个任意样本的特征距离表示为
(8)
结合式(5)和式(7)可得本文算法的损失函数为
(9)
对矩阵M正进行特征分解使其为半正定矩阵,并用随机梯度下降投影法优化M。计算最小类间距离时,在t次迭代,令M=Mt,当类内距离大于类间距离时,构造(i,j,k)为一个异常情况,i,j,k为异常情况的三个点,i,j来自同一个人,k来自不同的人,通过式(10)调整M消除异常情况,式(9)对M求偏导可得梯度函数为式(10),优化之后的Mt+1也应为正半定矩阵,对Mt+1特征分解为式(11),并不断更新去掉所有负特征值的矩阵Dt+1
(10)
(11)
2 实验与分析
2.1 实验环境与参数设置
实验环境中软硬件参数如下:CPU型号为Intel(R)Core(TM)i5—6 500,内存为8 GB,操作平台为Windows 7,实验平台为MATLAB R2014a。
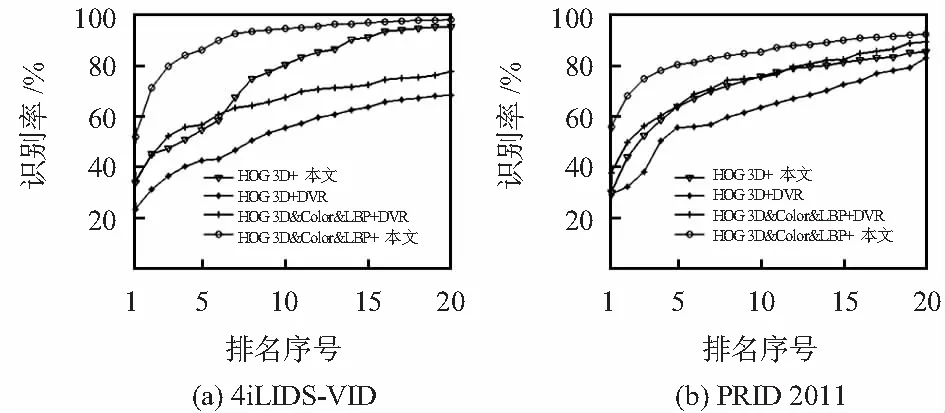
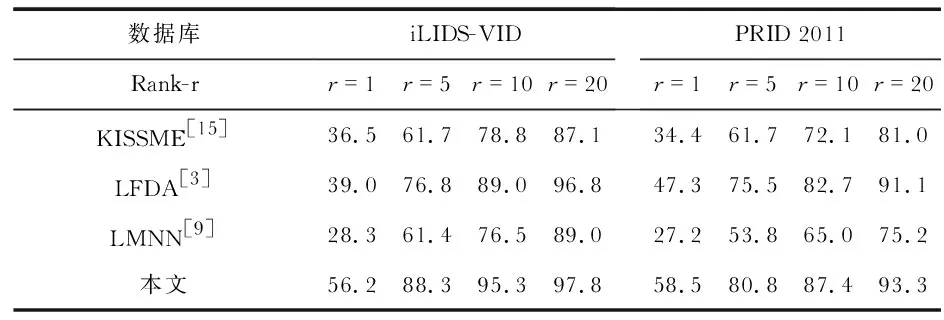
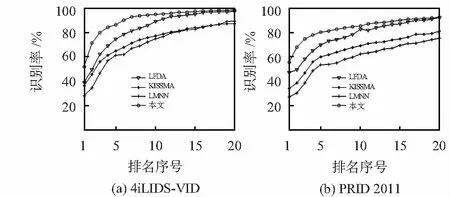
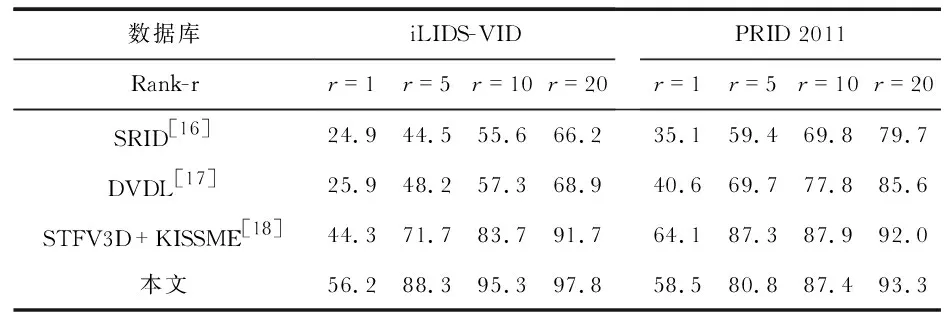
实验中,图片的大小为12 848,HOG3D提取到的时空特征向量为1 200维,颜色直方图和LBP提取到的颜色特征以及纹理特征组合特征向量为1 705维,从而得到行人的总特征向量为2 905维,结合度量学习模型,训练过程中迭代次数设置为1 000,损失函数中的参数λ采取分段训练的形式,当t≥200时,λ=0.25;当200 本文采用视频数据库iLIDS—VID和PRID 2011来评估文中算法,两数据库拍摄的行人图像分别如图2所示,数据库参数如表1所示。 图2 两个数据库图像 数据库行人数量/位摄像机数量/台平均帧数/帧图像尺寸/像素iLIDS-VID30027364×128PRID 2011200210064×128 iLIDS-VID数据库包括600个图像序列,采用两个非重叠摄像机随机拍摄的300位行人,每个图像序列的长度从23帧到192帧不等,平均帧长为73。由图2(a)可知,该数据集拍摄的场合背景复杂,遮挡严重,加上行人着装上的相似以及相机间视角的变化。 PRID 2011数据库包括400个图像序列,每个序列的长度为5~675帧,平均帧长为100帧。由图2(b)可知,该数据集拍摄场合为比较空旷的室外,没有遮挡且背景比较简单,然而摄像机角度变化非常明显,色彩空间差异较大,且其中一个摄像机中行人的阴影比较明显。 在实验中,为了平衡实验的效果,挑选出数据库PRID 2011中大于21帧的178个Multi-shot的行人作为实验数据。对于两个数据库,将数据随机的平均分为两部分,一部分用作训练,另一部分用作测试,即iLIDS-VID数据库各为150人,PRID 2011数据库各为89人。在测试时,设置摄像机Cama所拍摄的数据作为需要查找的目标,即查找集,摄像机Camb所拍摄的行人数据作为候选的对象,即候选集。实验重复10次,并测量平均的累计匹配特性曲线(cumulative matching characteristic,CMC)来评价算法的性能。 将查找的对象在候选集中按距离的远近由小到大进行排序,目标行人的排序越靠前,说明行人再识别的效果越好。假设总共由N个行人,即共进行次查询和排序,每次查询中目标行人的排序结果用r=(r1,r2,…,rN)表示,则CMC曲线表示为 (12) 分别对两个数据库采用排序在前r=1,5,10,20处的分数进行算法评估比较。 2.3.1 特征方法比较 基于视频的行人再识别的问题相比单帧图像的方法而言,最大的不同点在于:视频处理的特征是三维数据,并且视频存在时间相关性的特征。但行人再识别问题不同于行为识别问题,行人的走路姿势区分性不大,如果只用HOG 3D提取时序信息与空间梯度信息,则视频的行人特征提取不完整。DVR[6]中介绍了基于HOG 3D特征的重排序模型,实验在公开数据库iLIDS-VID和PRID 2011上,分别基于本文的度量学习模型和DVR[6]的重排序模型,分析比较只提取HOG 3D特征和组合静态颜色、纹理特征后对最后行人匹配精度的影响。实验结果如表2所示,CMC曲线图如图3所示。 表2 特征提取方法比较 图3 特征提取结果 实验结果表明,融合了静态的颜色和纹理特征后,在数据集iLIDS-VID上,基于本文度量学习模型的行人再识别精度比单独提取HOG 3D特征的Rank-1结果提高了22.4 %,基于DVR排序模型Rank-1结果提高了11.2 %。在数据集PRID 2011上,两种模型Rank-1结果分别提高了28.7 %和8.7 %。说明不同于行为、动作识别等问题,基于视频的行人再识别问题不能只考虑时间上的运动信息,融合动态与静态特征可以较明显提高行人再识别的匹配精度。 2.3.2 度量学习方法比较 为证明该度量学习方法可以有效提高行人再识别的匹配精度[9~15],实验在HOG3D&颜色&纹理相同特征基础上,比较分析几个比较主流的度量学习方法。由于每个行人走路的姿势相似,视频中不同人之间的模糊性会更高,如2.2节所述,PFLMNN度量学习方法着重于增大负样本对的距离。在公开数据库iLIDS-VID和PRID 2011上,分别基于相同的特征条件,分析比较KISSME[15],LFDA[3],LMNN[9]与PFLMNN的度量学习方法,实验结果如表3所示,CMC曲线图分别如图4所示。 表3 度量学习方法比较 图4 度量学习结果 实验结果表明,在相同特征基础的条件下,PFLMNN度量学习方法在两个数据库上明显优于KISSME[15],LFDA[3],LMNN[9]方法。由表3结果分析发现,在数据集iLIDS-VID上,该方法rank-1的结果比KISSME[15]提高了19.7 %,比LFDA[3]提高了17.2 %,比LMNN[9]提高了27.9 %;在数据集PRID 2011上,Rank-1的结果分别提高了24.1 %,11.2 %,31.3 %。由以上可得,基于PFLMNN的度量学习模型比较适合基于视频方法的行人再识别任务。 2.3.3 整体方法比较 为了表明实现的整体方法在视频行人再识别的问题上表现较好,实验对比了近年来在数据库iLIDS-VID和PRID 2011 三个比较先进的方法,包括SRID[16],DVDL[17],STFV3D+KISSME[18]。实验结果如表4所示。 表4 整体方法比较 实验结果表明,时空特征融合+PFLMNN度量学习方法在数据库iLIDS-VID和PRID 2011上对比SRID[22],DVDL[23]均有明显优势,尤其是在数据库iLIDS-VID上性能提高较为明显。 与STFV3D+KISSME[24]方法比较发现,该方法在数据库PRID 2011上的结果低于STFV3D+KISSME[24],但在数据库iLIDS-VID上Rank-1结果提高了11.9 %。由表5可得,本文整体方法在数据库iLIDS-VID和PRID 2011上均有较好的行人再识别精度,且比较适合基于视频的行人再识别任务。 实验结果表明:该方法在公开数据集iLIDS-VID和PRID 2011上取得了较好的匹配精度,分析结果发现,对于遮挡严重、背景复杂的数据集该方法提升效果较为明显。2.2 实验数据与评价指标


2.3 结果与分析

3 结 论
