基于行人分割与部位对齐的行人再识别
2019-09-10耿树泽于明岑世欣刘晓亮
耿树泽 于明 岑世欣 刘晓亮








摘要 为了解决行人再识别中由于视角变化和背景干扰造成的错位匹配(未对齐)问题,提出一种基于行人分割的部位对齐网络(SegPAN)的方法,该网络由3部分组成:1) 构建一种基于RefineNet的行人分割网络(TL-RefineNet),以获得多个局部对齐部位;2)基于分割的行人部位,提出一种行人部位对齐网络,以提取多个局部对齐特征;3)通过一种加权融合的策略将提取的局部对齐特征融合,提高视觉特征的判别能力。在此基础上利用特征之间的相似度实现行人再识别。实验在Market-1501和DukeMTMC-reID数据集上进行测试,R1的性能分别达到90.5%和80.3%。结果证明该方法不仅有效的缓解了错位匹配问题,而且减少了背景的干扰,提高了再识别性能。
关 键 词 行人再识别;行人分割;部位对齐网络;加权融合
中图分类号 TP391.41 文献标志码 A
A segmentation-based part alignment network for person re-identification
GENG Shuze1, YU Ming1, 2, CEN Shixin2, LIU Xiaoliang3
( 1. School of Electronic and Information Engineering, Hebei University of Technology, Tianjin 300401, China; 2. School of Artificial Intelligence and Data Science, Hebei University of Technology, Tianjin 300401, China; 3. State Grid Shandong Electric Power Company Weifang Power Supply Company, Weifang, Shandong 261000, China )
Abstract In order to solve the problem of misalignment caused by view changes and background interference in person re-identification, a Segmentation-based Part Alignment Network (SegPAN) is proposed. SegPAN includes three main parts: 1) A RefineNet-based segmentation network (TL-RefineNet) is developed to obtain multiple local alignment parts; 2) A part alignment network is put forward based on the segmentation of human body parts to extract the local alignment features; 3) A weighted fusion strategy is applied into the local alignment features to improve the discrimination of visual features, on which the similarity measure is leveraged to achieve person re-identification. Experiment shows that R1 performance achieves 90.5% and 80.3% respectively on Market-1501 and DukeMTMC-reID datasets. The proposed method not only alleviates the problem of misalignment effectively, but also reduces the interference of background and improves the re-ID performance.
Key words person re-identification; person segmentation; part alignment network; weighted fusion
0 引言
行人再識别是指在非交叠的视频监控中寻找与目标一致的行人,该技术可以应用于行人检索、交叉摄像机跟踪等视频监控领域[1-5],是视频智能分析的一个重要组成部分。但由于光线、姿势和视角的多样性,使得跨场景中的行人匹配极具挑战性。众多的影响因素中,错位匹配是导致行人再识别失败的一个重要因素,究其原因可分为两类:1)行人检测不准确。例如,当图像中包含大量的背景或行人部位不全时[6-8],很容易造成局部背景与行人某区域之间的错误匹配(图1 a));2)不同视角中行人姿态的变化。例如,同一行人在骑车与行走时产生的对应匹配,也会造成错位匹配(图1 b))。
为了解决行人再识别中的错位匹配,Zhang等[9]提出一个多分枝网络,每个分支对应行人图像中一个水平条区域,通过匹配对应的水平区域实现行人部位对齐,但当背景较大时,匹配效果并不理想。Su等[10]构建了一个深度对齐网络,网络不仅提取全局特征,同时对整个行人进行重定位,利用重定位的行人进行相似度比较以实现行人的对齐,但该方法并没有对行人部位进行细分,导致算法对行人姿态的鲁棒性会受到影响。此外,许多方法借助于行人关键点实现行人部位对齐[11-18]。Zheng[13]将行人划分为14个关键点,利用这些关键点把行人划分为若干个区域,同时为了提取不同尺度上的局部特征,还设定了3个不同的PoseBox组合进行映射矫正对齐。与方法[13]不同的是,Zhao[15]并没有用仿射变换来实现局部对齐,而是直接利用行人关键点来抠出多个行人部位,然后将这些区域和原始图像一并输入到对齐网络进行特征匹配。由于该方法的抠取方式过于简单使得算法无法获取精确的部位区域,不可避免地引入无关背景,并且关键点的检测并不可靠[19]。
为了解决行人未对齐,提高算法对姿态变化的鲁棒性,本文提出一种新的再识别方法,该方法不仅提取全局特征,同时还对行人的各个部分进行了区域划分,通过对应部位之间的匹配实现行人对齐,与其他方法[11-15]不同的是,本方法并沒有采用行人关键点进行行人区域划分,而是采用一种行人分割的策略完成图像中行人各部分的有效分割(头部、躯干、腿等),在此基础上进一步构建行人部位对齐网络实现行人部位对齐。此外,在融合部位对齐特征时,采用一种加权的策略以提高特征鲁棒性。通过该方法不仅能实现行人与背景的分离,消除背景的干扰,而且能有效地提高行人对齐效果(图2)。
本文主要的贡献可归纳为以下3点:
1)提出基于行人部位分割对齐的再识别网络,网络的输入不仅包含分割的行人区域,而且包含对应区域置信特征,该特征可以对分割的效果进行有效反馈,提高局部特征的可靠性。
2)为了获取良好的行人分割效果,提出基于过渡层(Transition Layer)的RefineNet网络(TL-RefineNet),以实现对行人部位的精确分割。
3)提出一种加权融合的方法,将提取的多个区域特征进行加权,实现多个对齐特征的有效融合,进一步提高特征的可区分性。
为了验证提出方法的有效性,在两个标准行人再识别数据集进行验证,分析其有效性及各部分的作用,并与其他主流方法进行性能比较。
1 本文方法
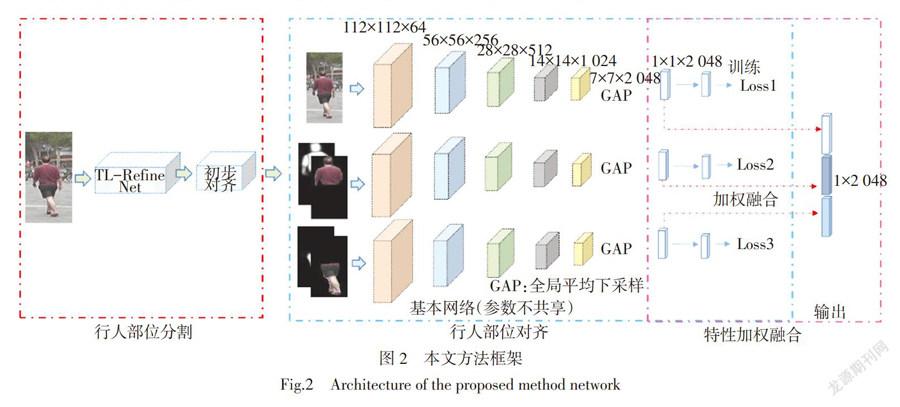
本文方法主要包括3个部分:行人分割、行人部位对齐以及行人对齐特征的融合(图2)。首先利用提出的TL-RefineNet网络将行人图像进行分割,得到多个行人分割区域,例如,行人上半区域和行人下半区域。然后基于分割的行人区域,构建行人部位对齐网络,提取部位对齐特征。最后通过加权融合的方式将提取的对齐特征进行融合,提高特征的鲁棒性。在该基础上计算特征之间的相似性,获得最终结果。
1.1 TL-RefineNet与行人部位分割
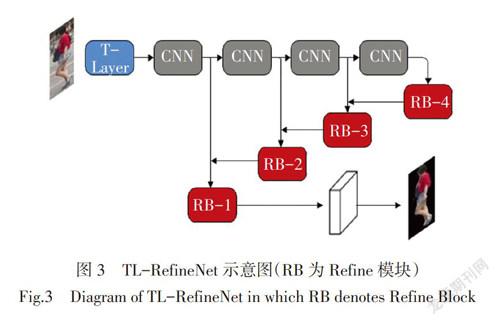
本研究目标是分割出行人对齐部位,然后将其应用到行人部位对齐网络,以解决行人错位匹配问题。但直接对re-ID数据集中的行人进行分割将面临两个主要问题:1)由于re-ID数据集没有语义分割标签,很难直接在re-ID数据集上训练分割网络;2)直接利用在非re-ID数据集(如Person Parts Dataset [20])训练的分割模型,用在re-ID数据集上进行分割,并不能获得理想的分割效果。其主要原因在于:在re-ID数据集中,行人图像的分辨率太低(尺寸小),使得图像分割目标过小,许多细节特征不足。但是,在re-ID数据集中,行人已被裁剪好,并且他们在图像中占据了绝大部分区域。因此一个合适的放大操作不仅能放大分割目标,而且因放大而导致的背景干扰也是有限的。基于此思路,本文提出一个过渡层嵌入到RefineNet分割网络中,以实现图像中行人各部位的良好分割。
具体的,过渡层由一个双线性差值构成,设插值像素值f (m, n)如公式(1)所示:
[fm,n=θ1θ2Q11Q12Q21Q22θ3θ4][,] (1)
式中:[θ1=m2-m,][θ2=m-m1,][θ3=n2-n,][θ4=n-n1,][Q11=m1,n1,][Q12=m1,n2,][Q21=m2,n1,][Q22=m2,n2]表示[fm,n]的4个近邻坐标。放大尺度参数设为α,该参数可通过网络训练获得。首先在Person Parts 数据集上训练基础的RefineNet,然后将T-Layer层嵌入到训练好的RefineNet(如图3所示)。最后通过固定RefineNet网络的其他参数,利用部分分割结果训练尺度参数。行人分割网络的输出为预定义的分割标签,即行人上半部分(包括行人头部、上臂和躯干)和行人下半部分(包括行人躯干以下及腿部,如图2所示)。
1.2 基于分割的行人部位对齐网络
为了缓解行人未对齐问题,本文基于分割的行人区域构建一个行人部位对齐网络。该网络针对每个行人部位构建一个分支网络,从而提取部位对齐特征。
此外,考虑到,当行人被严重遮挡时,行人的分割效果会受到一定的影响。为了弥补这一影响,本文将原始图像单独作为一个网络分支,合并到整个行人对齐网络中,共构建3个网络分支。每个网络分支的基本结构为Resnet50网络的pooling5层及以前的所有网络层结构。特别的,每个网络分支的输入除了分割后的RGB图像,由分割获得的对应的置信特征也被输入到对齐网络中,以提高分割结果的可靠度。将每个网络分支输出的1×1×2 048维特征作为部位对齐特征。具体结构如图2所示。
在训练时,由于不同数据集的行人数目不同,本文增加了一个全链接层以调整输出结果的维度变化。Softmax用来将每一个行人的预测值[ak]归一化到[0, 1]:
[pkx=expakk=1Kak][,] (2)
式中[K]表示数据集中行人的类别数目 (Person ID)。通过交叉熵来迭代获取每个分支网络的最小损失值:
[lossi=-k=1K(log(p(k|x))q(k|x))][,] [qy|x=1,y=k0,y≠k], (3)
式中:x表示网络输入特征;i =1,2,3对应3个网络分支;y为类别标签。此外,当行人图像检测不准确或者存在大量背景时,在输入对齐网络之前,本文通过双线性差值对分割结果进行裁剪、尺寸调整,从而实现行人初步对齐,如图4所示。
1.3 局部对齐特征的加权融合
为了反映不同部位在再识别过程中的重要程度,本文提出一种特征加权融合方法,来提高行人特征的鲁棒性。在此过程中,使用3个(1×1)加权卷积核对提取的3个对齐特征进行加权融合,然后通过一个全连接层,来调整融合后特征的输出维度(不同数据集中行人数目不同)。
考虑到单个线性权重层可能会对某些部位的特殊特征产生过大的响应[2], 为此,一个非线性函数被加入以均衡部位特征向量的响应。
具体的经过非线性变换的特征[hwi]以通過公式(4)计算:
[hwi=tanh(hi⊙Wi+Bi)][,] (4)
式中:[Wi]代表权重参数;[Bi]表示偏置向量,其维度与特征向量一致;符[号][⊙]表示2个向量的阿达玛积。输出的向量[hwi]为提取的加权特征。
同样的,在训练时,用Softmax将每个行人的预测值[ak]归一化到[0, 1]。网络中,3个网络分枝的损失之和作为特征融合网络的损失函数,通过交叉熵来计算融合网络的最小损失值:
[ losssum=-i=13k=1K(log(p(k|x))q(k|x))][,] [qy|x=1,y=k0,y≠k], (5)
式中:x表示网络输入特征;i =1,2,3对应3个网络分支;y为类别标签。融合后的特征作为最终的行人再识别特征,利用欧式距离计算特征之间的相似度,获取最终的再识别结果。
2 实验结果及分析
本文在两个行人再识别数据集上对提出的算法进行验证,并与当前主流算法进行对比。测试的数据集包括DukeMTMC-reID(Duke)和Market1501(如图5所示)。这些数据集的视角、光照、场景以及遮挡情况各不相同,能较好的反映行人再识别的真实场景。在训练测试时,随机选取数据集中一半行人进行训练,剩下一半行人进行测试。为了增加测试结果的可靠性,取10次测试结果的平均结果作为最终的测试结果。测试的评价指标采用累积匹配特性曲线(Cumulative Match Characteristic, CMC)和平均准确精度(Mean Average Precision, mAP)来评估模型性能。
Market-1501数据集包括(由6个摄像头拍摄到的)1 501个行人、32 668个检测到的行人图像。每个行人至少包含2个视角,并且在一个视角中可能具有多张图像。训练集有751人,包含12 936张图像,测试集有750人,包含19 732张图像。
DukeMTMC 数据集是一个大规模标记的多目标多视角行人跟踪数据集,一共有1 404个行人,36 411 张图像。其中测试集702人,共17 661张图像;训练集702人,共16 522张图像,验证集2 228张图像。
2.1 实验分析
2.1.1 TL-RefineNet的有效性分析
由于行人再识别数据集没有语义分割标签,不能直接利用交并比(Intersection over Union, IOU)指标进行性能测试,但是分割效果仍然可以通过视觉对比进行比较,具体结果如图6所示。
从结果可以看出,提出的TL-RefineNet能够有效的完成复杂场景中的行人部位分割。与RefineNet相比,TL-RefineNet的行人分割效果得到很大的提高,不仅提取到更多的行人细节,而且降低了的额外噪声。这表明,T-Layer对行人的分割是有效的,一方面可以提高局部区域的细节信息,另一方面为部位对齐网络提供了良好的对齐区域。
2.1.2 特征加权融合的有效性分析
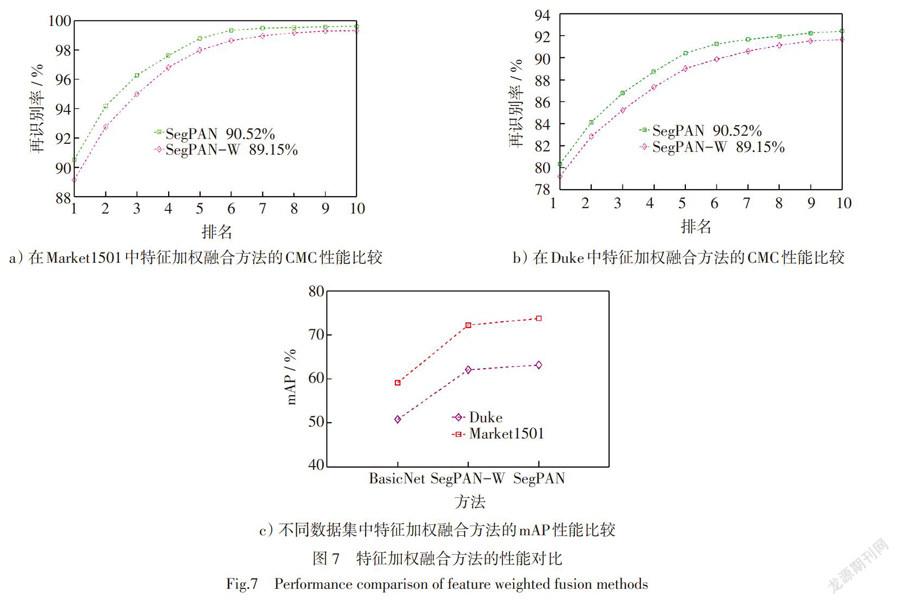
为了验证特征加权融合的有效性,本文首先采用加权模型进行特征加权融合(SegPAN),在两个数据集上进行实验,然后去掉加权模型,将提取的对齐特征直接拼接组成行人特征(SegPAN-W),作为对比实验,实验结果如图7所示。具体来说,在Market1501数据集上,SegPAN在R1(CMC曲线中,排名第1时的正确率)上的性能为90.5%,与SegPAN-W相比提高了1.4%。同样的,在Duke数据集中,加权融合后R1的性能相比没有加权融合的性能高1.1%。进一步,从整体性能(前R10和mAP)上看, SegPAN的性能也都高于SegPAN-W的性能。这些性能的提高主要归结于加权融合策略能根据行人姿态、场景等情况来分配不同的权重以提高特征的鲁棒性。
2.1.3 对齐效果的分析
为了验证本文方法对错位匹配的有效性,本文不仅对比了基本网络ResNet50[24],同时还对比了3个经典的解决错位对齐的方法:PSE[12]、PIE[13]和Pose-T[14], 具体结果如表1所示。
从结果可以看出本文方法的性能在R1和mAP上都取得了最好的效果,特别地,与ResNet50相比,本文提出方法有着更大的性能优势,在Market1501数据集上,SegPAN的性能分别为90.5% (R1)和73.7%(mAP),分别比基础网络ResNet50的性能提高了7.9%和14.6%。同样,在Duke数据集上,SegPAN的性能为80.3%(R1),相比ResNet50的识别率提高了8%,这些性能的提高可以充分说明本文方法对错位匹配的有效性,不仅避免了背景的干扰,而且能有效的实现了各个部位的对齐匹配,提高了再识别性能。
进一步,与对齐方法PSE(基于关键点构建的)相比,本文方法在R1和mAP上仍然有2.8%和4.7%的优势(Market1501)。主要原因在于相比基于行人关键点构建的对齐方法,本文方法能够更准确的获得行人的对齐区域,提高部位对齐效果。
2.2 与主流方法的对比
1)Market1501。在Market-1501中,SegPAN表现出最佳的再识别率:R1 = 90.5%,mAP = 73.7%。与Pose-T[14]相比,分别提高2.9%和4.8%。造成这些差距的主要原因是Pose-T是基于行人部位关键位姿点进行对齐,很容易将额外的背景引入到对齐区域中。相反,本文方法是基于分割策略来实现行人对齐,并提出了TL-RefineNet来提高分割性能。
2)Duke。在該数据集中,选择6种主流方法来对比。与Market1501数据集相比,Duke数据集具有更多的遮挡和更大的场景变换。从结果可以看出,SegPAN的性能依然是最好的,在R1和mAP上,相比方法PSE[12]的性能分别高0.5%和1.1%。此外,相比基于级联网络的T-S+d-II[23]有着4.8%的优势(R1),这些结果充分说明本文方法的有效性。
3 结束语
本文提出一种新的再识别方法来解决行人再识别中的未对齐问题,该方法采用一种分割的策略来获取行人对齐部位,不仅有助于行人部位的有效对齐,而且降低了背景的干扰。在特征融合方面进一步采用加权融合的方法,来提高对齐特征的鲁棒性。实验表明,在Market1501和Duke数据集中,本文方法分别获得了90.5%和80.3%的再识别率(R1),高于其他主流方法。
通过该研究,本文对行人未对齐问题有了更深入的认识,一方面通过行人分割对齐可以有效缓解行人未对齐现象;另一方面行人分割的准确性对再识别结果有着一定的干扰。特别是当行人图像出现严重遮挡或分辨率过低时,行人的对齐效果会受到更大的影响,该不足也将会成为我们未来研究的重点。
参考文献:
[1] 李幼蛟,卓力,张菁,等. 行人再识别技术综述[J]. 自动化学报,2018,44(9):1554-1568.
[2] 谭飞刚,黄玲,翟聪,等. 一种用于大型交通枢纽的跨摄像机行人再识别算法研究[J]. 铁道学报,2017,39(1):76-82.
[3] 王冲,王洪元. 基于跨场景迁移学习的行人再识别[J]. 计算机工程与设计,2018,39(5):1457-1462.
[4] GENG S,YU M,GUO Y,et al. A Weighted center graph fusion method for person re-identification [J]. IEEE Access,2019,7:23329- 23342.
[5] 蒋建国,杨宁,齐美彬,等. 区域块分割与融合的行人再识别[J]. 中国图象图形学报,2019,24(4):513-522.
[6] GENG S,YU M,LIU Y,et al. Re-ranking pedestrian re-identification with multiple metrics[J]. Multimedia Tools and Applications,2019,78(9):11631-11653.
[7] GUO Y,CHEUNG N M. Efficient and deep person re-identification using multi-level similarity[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT. New York,USA:IEEE,2018:2335-2344.
[8] CHEN Y,ZHU X,GONG S,et al. Person re-identification by deep learning multi-scale representations[C]// 2017 IEEE International Conference on Computer Vision Workshops (ICCVW). Venice. New York,USA:IEEE,2017:2590-2600.
[9] ZHANG Z,SI T. Learning deep features from body and parts for person re-identification in camera networks [J]. Journal on Wireless Communications and Networking,2018 (1):39-52.
[10] SU C,LI J,ZHANG S,et al. Pose-driven deep convolutional model for person re-identification[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Venice. New York,USA:IEEE,2017:3980-3989.
[11] ZHENG Z,ZHENG L,YANG Y. Pedestrian alignment network for large-scale person re-identification [J]. IEEE Transactions on Circuits and Systems for Video Technology,2018,4:1-11.
[12] SARFRAZ M S,SCHUMANN A,EBERLE A,et al. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT. New York,USA:IEEE,2018:420-429.
[13] ZHENG L,HUANG Y,LU H C,et al. Pose invariant embedding for deep person re-identification [J]. IEEE Transactions on Image Processing,2019,28(9):4500-4509.
[14] LIU J,NI B,YAN Y,et al. Pose transferrable person re-identification [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA. New York,USA:IEEE,2018:4099-4108.
[15] ZHAO H,TIAN M,SUN S,et al. Spindle net:Person re-identification with human body region guided feature decomposition and fusion[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu,HI. New York,USA:IEEE,2017:1077-1085.
[16] YAO H T,ZHANG S L,HONG R C,et al. Deep representation learning with part loss for person re-identification [J]. IEEE Transactions on Image Processing,2019,28(6):2860–2871.
[17] ZHANG W S,YAO H,GAO W,et al. Glad:Global-local-alignment descriptor for pedestrian retrieval[C]// ACM International Conference on Multimedia. Silicon Valley,USA,2017:420-428.
[18] 田萱,王亮,丁琪. 基于深度學习的图像语义分割方法综述[J]. 软件学报,2019,30(2):440-468.
[19] XIAO T,LI S,WANG B C,et al. Joint detection and identification feature learning for person search[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu,HI. New York,USA:IEEE,2017:3376-3385.
[20] LIN G,ANTON M,SHEN C,et al. Refinenet:Multi-path refinement networks for high-resolution semantic segmentation[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu,HI. New York,USA:IEEE,2017:1925-1934.
[21] ZHANG Y,XIANG T,TIMOTHY M,et al. Deep mutual learning[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT. New York,USA:IEEE,2018:4320-4328.
[22] YU R,DOU Z,BAI S,ZHANG Z,et al. Hard-aware point-to-set deep metric for person re-identification [C]// European Conference on Computer Vision. Munich,Germany,2018:196-212.
[23] HUANG Y,XU J,WU Q,et al. Multi-pseudo regularized label for generated data in person re-identification [J]. IEEE Transactions on Image Processing,2019,28(3):1391-1403.
[24] HE K,ZHANG X,REN S,et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas,NV,USA. New York,USA:IEEE,2016:770-778.
[25] ZHONG Z,ZHENG L,ZHENG Z,et al. Camstyle:A novel data augmentation method for person re-identification [J]. IEEE Transactions on Image Processing,2019,28(3):1176-1190.
[责任编辑 田 丰]
