高铁建设对人们出行选择的影响分析
2019-09-10许菁贾亚茹赵东婕
许菁 贾亚茹 赵东婕








摘要:随着现代中国“新四大发明”之一高铁的问世,使得国人出行的方式与手段日趋多元化,在生活中的长途旅行不再局限于民航这一种方式价格稍贵的出行方式,而中短途旅行也不仅限于长途客车这种并不十分舒适的方法。在此基础上,人们的出行不再一味追求“到达”这一个目的,对于出行方式的合理化选择更加看重。而近年来由于国人旅行热潮的掀起以及假期时间集中的原因,导致假期高速公路“大堵车”的情况频频出现。基于以上现状,高铁的发展在一定程度上减缓了普通客车的运行压力,也减弱了高速公路的运行压力。
对于第一问,通过搜集资料数据,找到能够反映高铁运行与开通情况以及高速公路客流压力的相关指标,通过相关性分析以及可视化手段,初步判断两者之间是否存在着某种联系;进而通过调查典型路段的指标数据,对于长途、中途和短途路段的高铁与公路关系进行分类研究,通过引入挤出效应的概念,利用阈值回归的方法,结合可视化图表分析,进一步得出高铁开通对于高速公路压力的缓解的模型。从而发现,在中长途运输中高铁对于高速公路的挤出效应最为明显,而由于短途公路运输方式的灵活性,这种效应在短途运输中并不显著。
对于第二问,随着出行方式的多元化,市场中出行方式所对应的目标群体变得更加明确。在已知客运需求的基础上通过对用户出行方式选择进行建模,进一步精准预测未来的高铁客运量,并根据各地以及临接站点之间线路的客流量分析,选择枢纽型铁路站点,搜集并处理相关数据指标,利用混合遗传算法的约束条件以及影响因素,求解出当地客流的准确判断以及分析。再结合复杂网络以及图论对站点与站点、站点之间铁路客流图的分流问题构建模型进行分析,通过分析具体某一条线路上站的分布情况,进而给出该地高铁线路配置数目合理分布的最优解。
关键词:阈值回归分析;logit模型;层次分析;混合遗传算法;车站分流网络
一、问题重述
随着人们生活质量的不断提高,几乎每家都拥有了私家车,这也就造成了每当节假日来临,高速公路就会出现拥堵情况的原因之一。但是随着中国现代“新四大发明”之一的高铁迅猛发展,给人们的出行带来了极大的便利,因此原图履行的人民也逐渐将高铁作为自己出行的首选交通工具,高铁的修建一方面能够缓解普通列车的压力,另一方面对高速公路的运行也起到了减压的作用。
请你搜集相关资料,完成以下两个问题
(1)高铁的开通,一部分人们变回选择高铁出行,从而会使得高速公路的车辆有所减少,请你选取合适的指标,分析高铁的开通对该高速公路的车辆通行压力是否有所减缓,并分析是否显著。
(2)高铁既便捷,又舒适,但是相对于普通列车出行价格相对昂贵,因此不同地域的人出行方式的选择将会有所差异,请你选择发展不同的城市,尝试给出你所选城市高铁配置的最佳数量。
二、问题分析
2.1 问题一分析
对于问题一,通过搜集相关统计数据,筛选出合适的指标,用来描述高铁的开通情况以及反映高速公路客流拥挤程度。进而对数据进行整理,通过可视化以及相关性分析的方法,确定这些指标确实存在着某种关系(相关性的强弱以及正负相关情况),进而验证高铁的开通的确对相应高速公路的车辆通行压力有所减缓。
根据相关性分析结论,对于国内长途、中途以及短途路段的高速高铁数据进行进一步整合分析,利用通过引入阔值回归模型来分析高铁对高速公路运输客流的影响,主要针对三个时间段的路程进行研究,分别为高铁运行4小时内、4-8小时、8-12小时。通过以北京-太原、上海-温州、北京-上海、廣州-郑州、成都-武汉、广州-重庆这些路段来分析高铁开通前后对民航客流量的影响。
通过模型结果本文得出高速铁路的开通对于航空客运具有负面的挤出效应,并且该挤出效应根据耗费时间的长短在不同的路段上有不同的表现。中长途运输中的挤出作用最为明显。短途客运中,航空运输显示了自身的优势,高铁的出现对其没有任何影响甚至出现了短途公路运输客运量在高铁出现之后仍然大幅增长的情况。
由此可见,挤出效应与耗费时间(或出行距离)成反比,中长途客运高铁对公路客运的挤出较大,特别是在一些地形复杂的区域(如山区等),高铁的相对运输距离小于客车的公路运输距离,高铁的运斤速度增加,高铁对于公路客运的优势更加突出。但随着高铁运输时间的减短,短途公路客运的灵活性优势开始显现出来,挤出效应逐渐减弱。
2.2 问题二分析
针对问题二高铁配置数量的求解,由于结果需要得到具体的配置数值,则需要对具体的城市作分析,故此选择了三个发展不同的市级城市,分别为西安、兰州和宝鸡,则问题转变为对这三个城市的高铁配置数量的求解。配置数量的目的需要实现减压高速压力同时并实现对配置资金的节约和综合利润的最大化,则需求解出最优的配置数量,此问题便转化为最优化问题。
对于优化问题,采用了混合遗传算法,即将遗传算法的全局搜索能力与模拟退火算法的局部搜索能力结合起来,在遍历性过程中提高寻找最优结果的效率;求解过程中,根据现实问题建立出相应的条件约束,并确定对应的最优化函数,接下来便可进行模拟实验,由于模拟实验需要各种约束对应的数据,则需要对所需数据进行获取,此处获取方式有调查问卷和网络查询;对于高铁建设,需要考虑到人口数量的增长性,故需要预测未来几年内的出行人数的数目,故此处添加了logit预测模型,并通过其对三个城市的未来数据进行了预测。
在获取到各种数据之后,进行模型模拟仿真实验,并得出相应城市对应的高铁配置最优数量。由于高铁数量只是理想化的数值,终需施工建设,为检验数量结果的正确性,便对目的城市作出了路网模型,模拟得出新增路线对客运量分担流的效果,并根据分担流得到最优数目的合理性与实际性。
三、符号说明
四、模型假设
1、假设模型所选相关因素即为全部影响因素(其他指标影响忽略不计);
2、假设所有影响因素相互独立;
3、假设阈值回归模型中的阈值变量是已知的;
五、模型的建立与求解
5.1 模型一的建立
根据问题背景,结合现实情况,通过搜集全国高铁以及高速年鉴数据,初步采用Pearson相关性分析的方法,两个变量X、Y的Pearson相关性定义如下:
其中,相关系数的绝对值越大,相关性越强;反之则越弱。通常情况下通过以下取值范围判断变量的相关强度:相关系数为0.8-1.0则为极强相关,0.6-0.8为强相关,0.4-0.6为中等程度相关,0.2-0.4为弱相关,0.0-0.2为极弱相关或无相关。将原数据进行可视化如下图所示:
可以初步观察到,当高铁建设日益发展(里程数增加)时,高速的客流量正在逐年下降,呈负相关关系。
为了判断高铁的出现对公路客流量的具体影响,采用阈值转换模型,以选取的具体某段高铁的通车时间作为阈值参数,分析高铁出现前后的情况。采用阈值回归模型[1]。该模型提出时主要分析动态面板模型中的阈值影响,重点介绍其估计与检验的方法。阈值回归模型强调特别的样本值可以根据观测变量的不同分为不同的类别。该模型包括最小二乘法、用来形成参数直线区间而衍生出来的渐进分布理论以及用来估计阈值影响显著性的boostrap方法。
在估计γ的过程中,为了防止阈值将样本分割过于几段从而造成某个结构包含的样本数量过小,可以设定每个结构中的样本占总样本量的最小比例(如1%或5%),也可以直接通过设定每个结构样本数量的最小值(5或10)来实现。
一旦γ被估计出来了买就可以估计出斜率系数 ,残差向量为 ,残差方差为:
在阈值模型汇总主要存在两个问题:第一个问题时检验情况数,即检验阈值的具体情况;第二个问题时对阈值变量的选择。由假设三可知,阈值变量是已知的,则不收阈值影响的原假设可以通过线性约束表示为:
这个假设表示阈值变量无影响。在H0的假设下,原模型等价于线性模型。模型变为:
通过(11)式减去均值后变为:
回归参数β1通过OLS估计,估计值为 ,残差记为 ,残差平方和记为 ,H0的近似似然比检验的F统计量为:
这里 是指对 的收敛估计。F1的渐进分布是不标准的,而且严格服从卡方分布。通过boostrap方法来模拟F1统计量的渐进分布,该方法的主要原理及步骤叙述如下:
1)将xit和qit看作已知,并在重复的boostrap样本中保持不变。回归残差 组合成为 ,样本 作为实证分布并运用boostrap方法;
2)有重复地从实证分布中取出n个值作为一个样本,将这些样本作为H0假设下的boostrap样本。在零假设方程(12)下估计样本并计算似然比统计量F1;
3)将这个过程重复大量次数(如1000次),得到1000个统计量F1的值,将其按照顺序进行排列,就可以得到各个分位点的临界值,进而计算估计统计量超过实际值的比率,从而得到在假设H0下统计量F1的渐进值p;
4)如果p值小于预定的临界值,则拒绝无阈值影响的原假设。
如果F1相关的p值拒绝了线性假设,那接下来就可以判断是一个还是两个阈值,该似然比检验的F统计量如下:
这里 和 是指在三种情况下模型的阈值估计, 是指相应的残差平方和。相应的似然比同级量记为F3定义如下:
这里 指四种情况三种临街模型中的残差平方和。
公路、铁路和民航是当前中国居民出行的三大交通方式,其中民航客运主要以短途为主,而中短途旅行的竞争主要集中在铁路和公路两个领域。高铁的运行速度为200-350km/h,而公路運输的速度一般为80-120km/h,二者的运输速度存在较大的差异,因此有必要深入分析二者之间的替代和互补的效应,以高速公路的客运量作为被解释变量,以铁路客运量作为解释变量,高铁的出现时间作为阈值来分析高铁的出现对公路客运压力的缓解情况。基于阈值转换模型基本原理建立模型如下:
其中,Git表示某路段公路客运量的同比增长率,Rit表示运段铁路客运量同比增长率,t为时间参数,γi为阈值参数,εit表示扰动项。
在速度保持不变的情况下,运输距离与运输时间有着基本恒定的正相关关系,而时间是影响人们出行的直接因素。因此,主要针对三个时间段进行研究,分别为高铁运行4小时以内、4-8小时以及8-12小时。截止2014年底,中国高铁已经覆盖主要大众城市为突出分析的代表性,4小时以内的公路客运主要集中在较大城市,故对应高铁的分析也应该相应地聚焦这些城市,所以选取北京到太原、上海到温州两个运段作为分析对象;4-8小时运段的分析属于较长时间的运输,结合高铁的运行速度,该种情况的运输主要存在于跨度较大、横亘南北的城市,故选择北京到上海、广州到郑州两个运段作为分析对象;而对于8-12个小时的运输时间,相应高铁运行距离应为2000-3000公里,然而受地理环境的影响,高铁的速度在地形复杂的地区(尤其是山地)中并不高,因此这种客运主要发生在我国东西贯通的线路中,最终选取成都到武汉、广州到重庆两个运段作为分析对象。通过搜集相关数据,我国高速铁路建成情况如附录1所示。
5.2 模型一求解
根据公式(1),可以得出如表5.1所示相关性结果如下:
则可以得出,高铁的开通运行情况与公路客流确实存在强负相关的结果。
5.2.1 短途分析
根据高铁运行时间,两个运段——北京到太原、上海到温州的高铁客运进行分析,其对应公路客运情况如图5.2所示:
如图所示,自2001年到2009年,北京到太原、上海到温州的公路客运均保持较高的增长速度,北京到太原段在2004年同比增长速度甚至达到100%,上海到温州段较为稳定的增长。三个运段客运量自2009年后均有不同程度的下降——自2009年初,北京到太原段开始下滑;2010年,广州到武汉段下滑。这与表5.1中所列高铁通车时间基本相符,但由于2008年全球次贷危机等因素影响的可能性,并不能以此确定客运量的下滑主要来源于高铁开通的影响。北京到太原段高铁客运量同比增长率如图5.3(a)所示:
从图中可以看出,在2008年之前北京-太原段高速客运量基本维持在正增长,高铁出现之前的铁路增长起伏波动较大。2008年之后高铁客运量呈曲折上涨的态势,而铁路的发展仍保持稳定上涨,但增长峰值并没有超过2008年前的增长峰值。图(b)反映了近年来上海-温州段的高铁与高速客运量同比增长率的情况,可以看出,自2008年后,高铁的增长率基本远超高速增长率,且高速正增长了在2008年之后逐渐趋于零,即不再增长。由此看出,短途旅行情况下高铁的开通对于高速客流量的影响并不显著,甚至在高铁出现后,高速客流量依旧呈现出增长的情况。
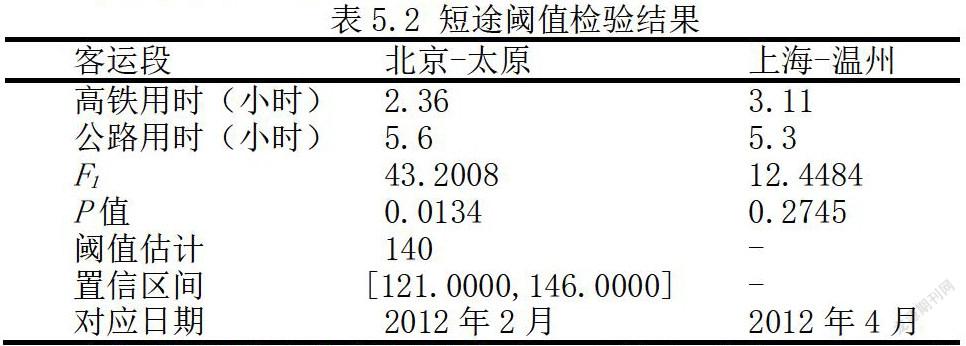
通过基与阈值转化模型检验方法,首先对各运段航空客运量增长率进行非线性检验,原假设H0:α1 = β1,置信度为95%,当P值小于5%时,拒绝原假设。表5.3为各运段通过统计量F1检验结果,计算得到北京到太原、上海到温州的P值分别为2.24%、17.5%、,北京到太原的P值小于5%临界值,原假设被拒绝;而上海-温州运段的F1统计量值较大,P值超过5%临界值,原假设成立,该回归无阈值转换,为线性回归。运用bootstrap方法,将时间参数依次作为估计值代入进行OLS回归,估计值为140,分别对应日期2012年2月和2012年4月,基本与表3-9所陈述的各段高铁开通时间相匹配。高铁开通对于上海到温州的公路客运量增长几乎没有影响,主要原因是两地之间距离较近,而高速铁路乘坐复杂且票价更贵,对比公路客运没有明显的优势。
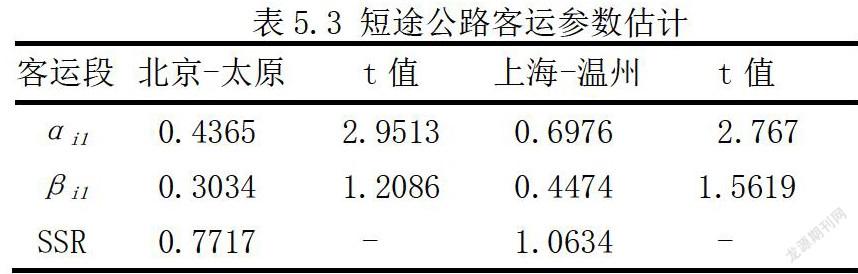
上海到温州段参数估计结果如表5.4所示,其中αi1、βi1分别为转换前后的铁路客运量同比增长率的回归系数,SSR为回归残差平方和。
铁路客运同比增长率Rit的回归系数转换前后分別为1.38、1.38和1.25、1.31,铁路客运与航空客运的发展显示出强正相关特征,阈值转换前后没有太大的变化。而上海到温州公路客运段的发展基本不受高铁开通的影响,保持强势发展势头,这一定程度上源于两地的经济交流,但主要原因是时间因素对于高铁客运形成的的竞争壁垒。综合北京到太原段的回归结果来看,虽然该段公路客运的发展在高铁出现前后呈现非线性特征,但是前后回归系数并没有明显的差别,这表明对于短途客运而言,高速公路客运对高铁客运依然保持着较强的竞争力。在短途客运方面高铁对高速客运存在挤出效应,但其作用效果已经没有那么明显。
5.2.2 中途分析
以高铁运输时间4小时到8小时为运输节点,选取北京到上海、广州到郑州的公路运输状况作为分析对象。选取数据为2001年1月至2014年12月月度数据。两个运段的高速公路客运表现如图5.5所示。
通过观察两个运段的高速公路客运表现,北京到上海的客运量远远高于其他运段的客运量,2010年之前,北京到上海的客运量保持高速增长态势;2010年之后,客运量处于稳定波动阶段,并没有太大涨幅。广州到郑州的公路客运量上涨持续到2011年,之后开始缓慢下跌。
非常明显的是,在2008年高速的增长出现了非常明显的波动,并在2008年后的2013年出现了增长率的最低谷。而铁路自2011年增长的最低谷后一直呈现出稳步增长的态势,并与于2012年后的增长率一直高于公路增长。作为中国最大的两个城市,两地之间的公路客运量不但数量远远超出其他路段,而且显现出较好的稳定性。图(b)反映出的广州到郑州段客运情况整体增长率偏低,但铁路增长在2003到2005以及2010到2014之后都超过高速的增长,高速增长持续波动,并在2010年出现了增长的最低谷。
基于阈值转化模型检验方法,首先对各运段航空客运量増长率进行非线性检验,原假设H0:α2=β2,置信度为95%,当P值小于5%时,拒绝原假设。表5.5通过F1统计检验结果,计算的背景到上海、广州到郑州的P值分别为2.33%和0.32%,均小于5%临界值,原假设拒绝,两个回归均存在阈值,为非线性回归。运用boostrap方法,将时间参数依次作为估计值带入进行OLS回归,各残差平方和排序的阈值γ4、γ5,估计值分别为130和138,分别对应日期2011年10月和2012年6月,与附录中记录各段高铁开通时间相匹配。
北京到上海、广州到郑州的参数估计结果如表5.8所示,其中αi1、βi1分别为转换前后的铁路客运量同比增长率的回归系数,SSR为回归残差平方和。
关于铁路客运同比增长率的回归系数转换前后分别为0.56、0.62和0.38、0.26,由此可以判断高速公路客运与铁路客运的相关关系与短程回归结果类似,依然保持正相关,但是具体转换前后的比较,广州到郑州的回归系数绝对值降幅为58%,北京到上海的回归系数绝对之降幅分别为34%,整体上相对于短途降幅变弱,但明显以看出广州到郑州的降幅更为剧烈。这一方面体现出中途高速公路客运与铁路客运受经济增长的共同驱动,竞争关系相于短途运输不太明显,高铁出现对于二者的竞争影响相对较小,因此转换前后回归系数估计值降幅不大,另一方面,发达城市之间的高速公路客运需求较为稳定,广州到郑州的高速公路客运受铁路运输的影响较北京到上海两个运段大,回归系数绝对值降低比较明显。
5.2.3 长途分析
长途客运的分析主要针对高铁运输时间为8小时以上的运段,由于这部分时长的客运大多昼夜间运行,与航空运输的时长差距明显,在更多方面影响旅客的出行选择。研究指标选取成都到武汉、广州到重庆两个运段。成都到武汉、广州到重庆的公路客运量具体情况如图5.6所示。
成都到武汉和成都到南京公路客运发展情况基本相似,2007年之前基本保持持续发展,在2007年中旬小幅下挫之后,2008年迅速恢复增长势头,并持续到2011年。在2011年之后增速变缓,成都到南京的公路客运量略高于成都到武汉的客运量,两段公路客运维持小幅上涨至2014年末,但其发展势头己远不如前。广州到重慶的公路客运量远远超过另外两个运段的客运量,这可能与两个城市的经济总量和地理位置相关。综合来看,从2001年到2014年,除偶尔小幅波动外,基本保持强劲的增长态势,似乎并未受到其他因素的影响而有所迟滞。
成都到武汉路段客运量同比增长率如图5.7(a)所示。2002年,公路段段客运量增长率短暂下跌为负,之后在2003年迅速反弹,并保持平均30%以上的增长速度直到2006年末,增长速度平稳。2007年迅速下跌至负20%水平,但在2008年重新恢复增长,最高达到50%以上。2010年-2014年,公路段客运量同比增长率逐渐下跌,但基本维持正增长。成都到武汉距离1146.2公里,公路段客运耗时约12.45小时,离铁开通后运行时间9.4小时,两者相差3.05小时。成都到武汉地形复杂,虽然直线距离不长,但是高速运行路线比较曲折,速度较慢,耗费时间较长,导致高速发展受阻,高铁继续平稳发展。
广州到重庆公路段客运量同比增长率如上图(b)所示,2002年增长速度短时期内为负的25%,之后迅速反弹,2003年达到峰值50%。2004年之后基本保持平稳发展,2007年增长率下跌至零,但2008年恢复增长,并保持10%增长水平至2014年。整体发展平稳,无明显下跌。广州到重庆距离13.4公里,公路客运耗时15小时,高铁开通后运行时间11小时,两者相差4小时。重庆作为贯通东西部地区重要枢纽,自身经济实力较强,与广州的客流量均高于平均水平,广州到重庆的公路客运持续保持高速发展。
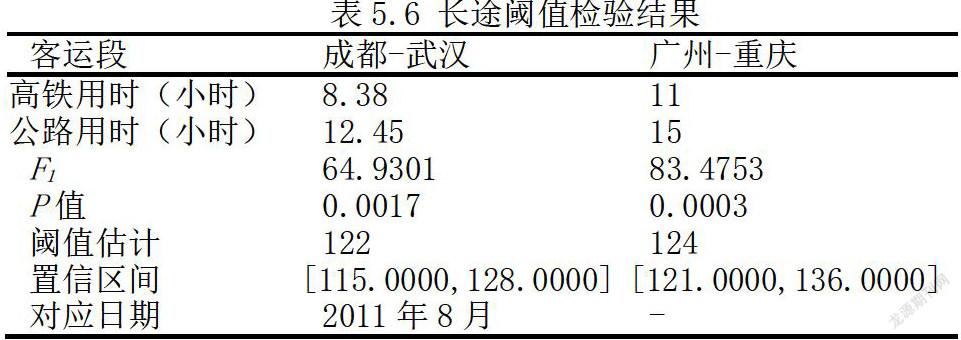
表5.7为各运段通过统计量F1检验结果,计算得到成都到武汉、广州到重庆的P值分别为1.7%、1.34%,均小于5%临界值,原假设被拒绝,两个回归均存在阔值,为非线性回归,估计值分别为122、124,分别对应日期2011年8月,基本与附录中记录各段高铁开通时间相吻合。
成都到武汉、广州到重庆的参数估计结果如表5.8所示,其中αi1、βi1分别为转换前后的铁路客运量同比增长率的回归系数,SSR为回归残差平方和。
关于铁路客运同比增长率Rit的阈值系数转换前后分別为0.93、2.57和0.37、0.37,同样降幅较大,阈值转换前后,公路客运同比增长率与铁路运输同比增长率之间的回归系数绝对值变小,凸显了随着高铁的出现,高铁规模和高铁密度的提高,较快的运行速度已经对该高速公路客运产生了较强的替代作用。值得注意的是,长途公路客运同比增长率与铁路运输同比增长率之间存在明显的正相关关系。
基于以上模型求解可以得出,高铁对于高速公路客运的压力可以起到一定额缓解作用。这种缓解效果主要体现在中长途的出行中,而对于短途出行,由于价格、灵活性等因素的影响,这种缓解作用并不是十分明显。但是由于在同一经济体下,受益于经济增长的推动,促进了客流量的迅猛増长,无论是铁路客运还是高速公路客运都有着较好的发展时机。旅客出行会根据自身需求综合这两种甚至更多种交通方式[3]。
5.3 模型二建立
在目前大力发展高速铁路建设的潮流下,通过问题一模型的建立与求解,基本发现了高速铁路与高速公路在客流运输上的竞争关系,为了进一步探索不同旅客出行方式选择的更深层关系,结合旅客出行选择理论,即旅客出行的利益最大化——经济型K、安全性Q、舒适性C、方便性TC、快捷性T、准时性,得出不停运输方式在客流竞争时的竞争因子的计算[4]:
其中U1表示不同运输方式之间的竞争因子,θi为不同影响因素的权重大小。因此通过量化不同的影响因素因子,可以得出不同运输方式之间的竞争因子的大小。
利用logit预测模型对于不同出行方式的客流量进行分担预测。结社每种运输方式的选择由k种不同因素X影响,由假设二可知各因素为相互独立的,则对于N个旅客进行建模可得旅客选择出行方式的似然函数为:
其中 为函数的系数,在求估计值时对式3.23求对数,舍去函数的常数项,化简得:
根据加法原则的效用函数模型进行计算,可得用函数影响因子值如下表所示:
普铁和公路运输的效用函数影响因素的相关属性标准统计如表5.9所示:
将相关数据代入系数计算公式(19)得到六大影响因素的系数值如表5.10所示:
为了说明问题的准确性,我们选取西北地区较为不发达的城市宝鸡、二线城市兰州、以及新一线城市西安进行分析。利用层次分析方法对西安宝鸡-宝兰客运各段进行分析,确定出行个体在选择出行方式的主要影响因素,得出主要的影响为出行方便性、经济型、快速性和安全性,其重要程度分别为0.344、0.195、0.226、0.235,证明权重分析结果正确。
2017年的7月9日宝兰客运专线开通,增加了两地之间的第三种运输方式,分担了两地之间的大量旅客运输,此外还有一部分的客运量被私家车占有。,目前该区间的客流量及市场竞争现状如表5.11所示:
通过对两地之间四种不同的交通运输方式进行分析,可以得出,在两地之间最快的出行方式为宝兰高速铁路,运费最省的出行方式为陇海线出行。
客运以及高铁专线情况如下图所示:
宝兰客运专线起始于陕西省宝鸡市,途径甘肃省天水市、定西市终于甘肃省兰州市,沿途设有南岔站、天水南站、秦安站、通渭站、定西北站、榆中站、兰州西站。宝兰客运专线开行以后,由于兰州地区和天水地区的高速铁路尚未组网,日均开行列车对数较少,开行的列车对数为44对,其中包含通过列车。列车在兰州西站的发车时间范围为:最早一趟车为早上6:45分,最晚一趟车为晚上19:45,开行列车有八辆编组和16辆编组两种类型,其中八辆编组的列车定员为586人,16辆编组的列车定员为1172人,一等座票价为99元、二等座票价为83元。
对其运输通道的客流预测采用重力预测模型:
其中α、β、θ为模型中用到的参数。
5.4 模型二求解
根據路段运营的实际情况,运用最大似然分析方法,对重力模型中的参数计算如表5.13所示:
将上表数据使用F检验和t检验得到相关参数为:
将搜集到的西安-宝鸡-兰州的经济指标带入到式(18)算得客流量为:
为了更加准确的预测,对旅客采用了行为调查和意向调查两种方法(调查问卷见附录2),调查结果的统计数据如下表5.16和5.17所示:
参与调查的旅客中,旅客在选择出行方式时,对不同的影响因素重视程度不同,本次调查过程中对五个方面的指标对旅客进行了问询,五个指标分别为安全性、快速性、舒适性、方便性及出行票价。
(1)对统计结果进行分析计算,得到旅客心中对高速铁路出行的安全性满意度为1,对高速公路出行的安全性满意度为0.65。
(2)经济型方面,由于高速铁路与高速公路出行方式的费用价格相差并不是很大,所以旅客出行时对高速铁路的经济型满意度为1,对高速公路出行的经济型满意度为0.95。
(3)快速性方面,选择宝兰高铁出行时出行时间为lh20min,高速公路出行时间为4h。旅客对高速铁路的方便性的满意度为1,对高速公路出行的方便性的满意度为0.34。
(4)在旅客出行的舒适性和方便性方面,对兰州天水区间的情况运用计算发的方法统计情况具体如表5.18所示。
(5)稳定性方面,是指旅客出行的稳定性,高速铁路的市场分担率里面有一部分客流出行选择高速铁路稳定不变。
综上,得出对影响旅客选择出行方式的不同影响因素满意度和权重值如表5.18所示:
采用上文的高速铁路和高速公路各自的效用函数,计算相应的效用值,其计算过程如下所示:
高铁效用值:
V1=1×1×(0.92×0.13+1×0.63+0.85×0.14+0.95×0.1) ×1×1=0.9638
高速效用值:
V1=0.65×1×(0.64×0.13+0.5×0.53+0.75×0.19+0.7×0.15) ×1×1=0.1939
由此,解得客流量最终分流结果为:
5.5 模型三建立
基于模型二中各站客流量的预测结果,依据各站铁路分布图建立模型,旨在解决基于旅客全出行过程构建的网络,求解网络范围内所有 OD对的路径及网络中客流在网络中的分布情况。引入混合遗传算法,建立模型约束——流量守恒约束(流量守恒约束是指网络中每个节点流入客流量等于流出的客流量。流量守恒能够避免发生丢流、添流和串流的现象)和能力约束[5]。为使整个铁路网输送所有车流所消耗的广义费用最小,并尽可能使各线路利用率达到平均,建立铁路网车流径路优化模型三如下所示:
其中式(19)、(20)本别表示目标函数:车流在路网上的广义费用最小以及能力利用率最大的路段最小化,式(23)、(24)、(25)分别表示约束条件:车流的不可分割性、路段能力的限制以及车站能力的限制。
用混合遗传算法求解铁路网车流分配问题时,需根据解的性质设计合适的编码方式——直观的表现问题的解以及尽量满足模型中的约束。基于上述分析,采用0-1整数编码如下图所示:
染色体长度为所有车流所对应的可行径路数的数量之和;若第i支车流的可选径路数为li,则该车流所占的码位长度为li;在第i支车流径路集代表的基因片段中,若数字为1,则表示车流i选择该基因位点所代表的径路;鉴于约束条件(25),每支车流的径路集所代表的基因片段中,有且仅有一个基因位点取值为1。染色体由各支车流对应的径路集顺序排列,即表示一种可能的铁路网车流分配方案。
5.6 模型三求解
应用混合遗传算法求解步骤及方法如下:
步骤1:设定各参数,种群大小popsize,交叉概率调整参数分别为pc1、pc2,变异概率调整参数分别为pm1、pm2,最大迭代次数Maxgen,初始温度ts,温度衰减参数α;
步骤2:按照前文染色体编码方式生成初始种群pop,当前代数n←l;
步骤3:计算当前种群中各染色体适应度,选择最优个体直接进入下一代,剩余个体进行轮盘赌随机选择;
步骤4:根据下式计算得到的交叉概率,对种群进行一致性交叉操作;
步骤5:根据下式计算得到的变异概率,对种群进行变异操作;
步骤6:在子代种群随机选择一个染色体生成其邻域解,按式(13)对两者进行选择,更新当前迭代次数n←n+1;
步骤7:算法终止判定,若n≤Maxgen,转步骤3循环计算,否则输出当前种群中最优染色体,并解码为最优车流分配方案。
对于西安-宝鸡-兰州各段铁路分布情况简化后的路网结构如图5.22所示,图中有20个节点车站、29个路段。令所有车站的改编能力均为b=2000,各路段的权重(里程、走行时间、费用综合值)、能力参数值以及各支车流OD流量均采用文獻[6]中所用数据。
设置混合遗传算法参数如下:种群大小popsize=50,交叉概率调整参数分别为pc1=0.9、pc2=0.6,变异概率调整参数分别为pm1=0.1、pm2=0.01,最大迭代次数Maxgen=500,初始温度ts=999,温度衰减参数α=0.87[7]。通过仿真计算出的最优染色体编码为:
popbest=[10|10|010|0100|0010|001|001|010000|100|00010|010|100|01|01000|10|100|001]由此解码出的径路选择方案如表5.21所示。
在此分配方案中,整个铁路网系统中车流的广义消耗为17784670,能力最高路段5→6利用率为92.3%。根据以上结果,得出西安、宝鸡、兰州线路最优线路配置结果为:
六、模型的评价与推广
6.1 模型评价
对于高铁开通对高速公路通行压力是否有所减缓,本文通过使用阈值回归模型对高铁对高速的影响程度进行了分析,并通过短中长三种路程的长度分别进行了相应的影响分析,得到:短程影响不是很明显,中途有相应的影响,长途有明显的影响。
根据问题一的分析结果,结合实际情况,可以看出阈值回归模型有着较好的评价效果,直观的展示出了现实中高铁开通对高速公路的影响,并能将影响因素分而治之,最终得到相应的评价结果,并能将各种因素的评价结果进行相应的结合分析得到最终的影响评价;另外阈值回归模型的建模结合了阈值限制与回归分析,在数据规律的基础上附加了现实约束阈值,使得得到的评价结果即具有数据的发展规律性又含有现实性的真实约束,使得此模型更具有实际的应用意义以及更强的说服力。
对发展不同城市進行高铁最佳数量的配置,本文采用了混合遗传优化算法对配置数目进行优化,并结合logit预测模型对数据进行预测,最后通过高铁路网模型建设得到最优道路数对应的客运量分担率,验证的最优道路数的可行性。
问题二的logit预测模型对未来人口出行数据进行了预测,为后续的优化模型做了数据支撑,使得优化结果具有前瞻性;混合遗传优化算法将遗传算法的全局搜索能力与模拟退火算法的局部搜索能力相结合,在保证结果的正确性的前提下又提升了计算过程的效率,使得数据规模影响的误差降到了最低,并得到了相应的优化解;在得到最佳高铁配置数目之后,本文使用路网模型建设模拟了城市对应高铁道路的分担率的变化,进一步的验证了优化结果的可行性和正确性。
综上,两个问题的模型考虑周全,在数据准备上具备完整性和正确性,在模型建立上具有科学性和可行性,在验证上具有实际性和准确性,得到的相应结论具有细致性和支撑性以及正确性。
6.2 模型推广
阈值回归模型,在问题一中分析出了高铁开通对高速公路的车辆通行压力是否具有影响,以及影响因素的各种分类展示。则相应的公司或政府可使用此模型得到对公司业绩影响因素的评测以及各因素对业绩影响的大小,在得到相应的影响因素的信息后,可对公司的相应政策的进行合理的调整,以在工作减压的同时保证利润的最大化。
混合遗传优化算法,在问题二中结合数据的支撑模拟得到了各城市的高铁配置最佳数目,并通过高铁路网验证了各道路客运量分担率,得到了结果的可行性和最优性。
使用此模型,对于高铁建设的意义重大,由于此模型考虑到了高铁建设的成本、减压作用、人们出行偏好等各种影响因素,在各种因素的结合之下得到相应的最优建设道路数目,减少了资金的消耗量,降低了公路的通行压力,避免了道路的闲置可能性,并得到了利润的最大化。故此模型十分适用于公司或政府对于工程量的规划,值得采用。
参考文献
[1]刘汉中.阈值自回归模型参数估计的小样本性质研究[J].数量经济技术经济研究,2009(10):112-124.
[2]梁钟方.高速铁路对民航客运的影响分析[D].山东大学,2016.
[3]李晓伟,王炜.高铁竞争下高速公路客运选择行为与发展策略[J].铁道科学与工程学报,2018,15(03):574-580.
[4]李强.高速铁路开行对区域高速公路旅客运输的影响研究[D].兰州交通大学,2018.
[5]王文宪,陈钉均,陈皓.混合遗传算法在铁路网车流分配中的应用[J].计算机仿真,2015,32(04):129-132+153.
[6]乔国会.铁路网车流优化分配模型研究与综合算例分析[D].北京交通大学,2008.
[7]邢文训,谢金星.现代优化计算方法[M].北京:清华大学出版社,2005.
