一种增量挖掘优化流程模型方法
2019-09-10薛洋婷王丽丽
薛洋婷 王丽丽




摘 要:增量挖掘是在已有挖掘结果的基础上,仅挖掘增量数据库,更新已有的挖掘结果.传统过程挖掘算法大多是批量式挖掘,模型精确度随着日志不断新增逐渐降低,获得精确度高的模型需要从头开始重新挖掘.因此,本文提出了一种增量挖掘优化流程模型方法.首先,根据频数高的事件日志的行为轮廓,构建初始模型,频数较低的日志,创建依赖关系树;其次,通过部分新增日志来不断更新依赖关系树,进而优化模型;最后,通过具体的实例分析验证了该方法有效.
关键词:petri网;行为轮廓;过程挖掘;增量挖掘
中图分类号:TP391.9 文献标识码:A 文章编号:1673-260X(2019)10-0057-04
随着信息技术的快速发展,业务流程管理发挥着越来越重要的作用.业务流程模型是业务流程管理的关键,挖掘出当前业务流程模型至关重要.随着事件日志不断更新,传统挖掘算法着重于从头开始重新挖掘,这使得成本增加且效率低.因此,本文提出了增量挖掘优化流程模型,在已挖掘出流程模型的基础上,挖掘增量日志信息来更新模型.
目前,增量挖掘在数据挖掘中应用比较广泛.增量式的数据挖掘主要是指仅挖掘增量数据库,更新已有的挖掘结果,得到最新的规则.文献[1]一种灵活的声明性框架,用于对流数据的物化视图(即连续查询的结果)进行增量维护.拟议框架的主要组成部分是View Delta函数(ViewDF),它声明性地指定了在新批数据到达时如何更新物化视图.文献[2]提出了一种新的流量数据增量半监督学习框架.每层模型都包含生成网络,判别结构和桥.生成网络使用基于自动编码器的动态特征学习来学习流数据的生成特征.文献[3]提出了一种从增量数据库中挖掘高效用模式的有效算法,其中一个数据库扫描基于列表的数据结构而没有候选生成.该算法优于先前的一阶段构造方法和候选生成.文献[4]提出了IncGM+,一种用于在单个大型演化图上进行连续频繁子图挖掘的快速增量方法.将“边缘”的概念适应于图形上下文,IncGM+维护边缘子图并利用它们来修剪搜索空间.文献[5]提出了一种称为IMU2P-Miner的增量算法,用于从单变量不确定数据中进行增量最大频繁模式挖掘.文献[6]提出了一种新的增量关系关联规则挖掘(IRARM)方法,旨在逐步调整数据集中标识的有趣关系关联规则.文献[7]提出了一种通过处理子图来检测社区的增量方法.首先进行综合分析,并提出四种增量元素.然后建议不同更新策略.文献[8]专注于增量更新,以选择具有多个对象变体的新特征子集.首先,以递增方式更新依赖性函数以评估候选特征的质量.然后,当在决策系统中添加或删除多个对象时,会开发两个增量特征选择算法.文献[9]提出了增量挖掘首先提取部分模型,然后在最后将它们集成到完整的模型中,新增日志能够更新、扩展和改进部分流程模型.而本文则是先挖掘出初始模型,再对部分进行改进,从而优化模型.
本文的其他部分内容安排如下:第1节给出一个动机例子,第2节介绍基本概念,第3节介绍了一种增量挖掘优化模型分析方法,第4节通过实例分析来验证算法的可行性.最后,总结全文并展望未来的工作.
1 动机例子
现如今,网上购物已成为人们生活必需,本文只考虑买家中心其网上购物大致步骤:A,…,R分别表示登录,选择商品,加入购物车,购买商品,选择支付方式,银行卡支付,支付宝支付,支付成功,确认收货地址,修改收货地址,訂单生成,取消订单,交易关闭,确认收货,评价订单,仅退货,再收货,退货退款.表1记录买家系统的事件日志序列及其实例数,根据表1的发生频数高的事件日志信息构建了图1所示的初始模型M.该模型符合购物的一般流程,但通过分析发现,日志有的活动并未出现在流程模型M中.仅通过部分日志挖掘出的模型,精确度随着日志更新而降低.因此,本文是针对不断新增的日志进行研究,利用日志活动之间的直接依赖关系创建依赖关系树,通过更新依赖关系树进而优化已得到的模型.
2 基本概念
定义1[10] (流程Petri网)一个流程模型Petri网PM=(P,T,F,C,s,e)是一个六元组,满足以下条件:
其中,k为给定日志中的不同轨迹数,n为日志轨迹中所含的数目,x表示日志轨迹重放时就绪变迁的平均数目,m表示模型中可见任务的数.
3 一种增量挖掘优化模型分析方法
本节主要介绍增量挖掘更新流程模型,它是启发式挖掘的扩展.首先,给出启发式挖掘相关定义;然后,给出增量挖掘优化模型算法,它是利用现有挖掘方法挖掘出初始模型,频数低的日志建立依赖关系树,本文的依赖关系树出自文献[9],它是AVL树,它包含了候选关系,支持度和置信度值.通过重放适合度低的高频数新增日志以及低频数的新增日志来更新依赖关系树,新增或删除树的结点,得到最终的依赖关系树,确定依赖关系是否添加到模型,起到优化模型的作用.
3.1 相关启发式挖掘知识
3.2 增量挖掘优化模型算法
输入:初始日志L,新增日志InL,阈值σ
输出:更新后的流程模型
步骤1.预处理事件日志,按事件日志发生频数从大到小排列;
步骤2.根据频数高的日志的行为轮廓,建立初始模型M;
步骤3.频数低的日志组成日志L”;
步骤4.活动e1,e2,e3…∈L”,根据L”创建活动之间的依赖关系rel(e1,e2),rel(e1,e3),…,得到相应活动下存在的依赖关系,如rel(e1,e2),rel(e1,e3)是活动e1下的依赖关系,对应生成结点e2,e3;
步骤5.根据定义5,依次计算rel(e1,e2)支持度和置信度,同一活动的不同依赖关系之间添加有向弧,如第4步中活动e1下有两个结点e2,e3,在e2和e3结点间添加有向弧;
步驟6.根据步骤4和5,创建不同活动下的依赖关系树,如果活动e暂时没有依赖关系,即没有产生结点,也在依赖关系树中保留该活动;
步骤7.每条新增日志,计算频数高的日志与模型M的适合度aLP,低于给定值的日志InL和频数低的新增日志,组成日志InL”;
步骤8.计算日志InL”中活动对的支持度和置信度;
步骤9.如果rel(e1,e2)置信度大于依赖关系树中对应活动对的置信度,更新e1活动下的依赖关系树中rel(e1,e2)的置信度,如若小于,则删除依赖关系树中该结点;
步骤10.依赖关系rel(e1,e2)在新增日志未再出现,继续保留依赖关系树中相应的结点;
步骤11.如果InL”出现新的活动对,在依赖关系树添加结点,重复步骤8,9,10,直到得到最新的依赖关系树;
步骤12.更新的依赖关系树中的结点置信度在不断增加越来越接近1,则认为这一依赖关系存在,在流程模型中找到相应活动,增加库所和变迁,使得在模型中也存在这关系;
步骤13.更新后的流程模型.
4 实例分析
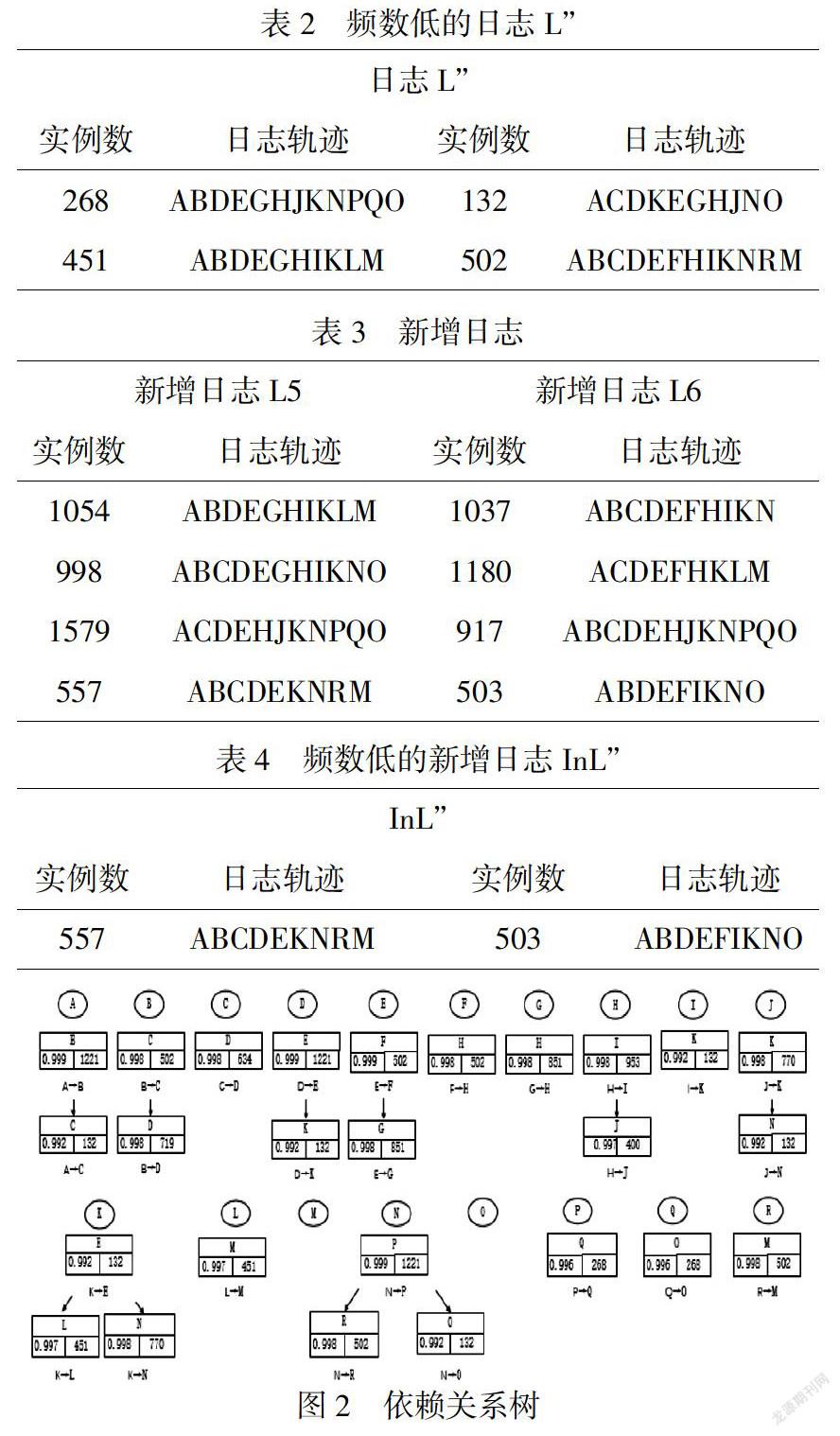
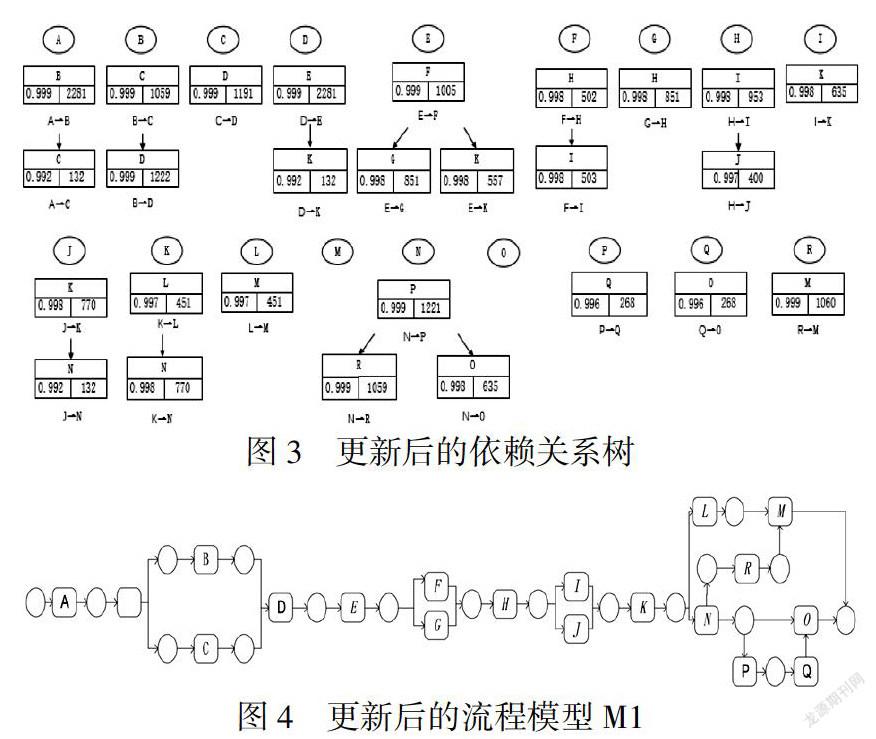
本节以上述提出的买家系统购物(动机例子)来验证提出算法的可行性.频数低的日志如表2所示,根据算法建立依赖关系树如图2,发现新的关系rel(K,E),rel(R,M),rel(N,R),rel(D,K)和rel(J,N)未在流程模型中出现,因此,通过新增日志更新依赖关系树判断是否更新模型,新增日志如表3所示,计算每个新增日志,得到适合度大于给定值0.95,即InL”只包含了频数低的日志,如表4所示,用来更新的依赖关系树,得到新的依赖关系树,如图3所示,图2的活动关系对在新增日志未出现则保留这些依赖关系,也不更新流程模型,A,B,C,D,G,H,I,J,L,M,N,O,P,Q,R这些活动没有增加或删除新的关系,它们的支持度和置信度在增加或保持不变,因此,不更新流程模型.E,F这两个活动出现新的关系rel(E,K),rel(F,I),活动K有删除rel(K,E)=0.615小于0.992.
流程模型发生变化是活动未在流程模型中出现且随着新增日志的增加其置信度在增加,则考虑在流程模型中添加该活动,如活动R可以在模型中添加,其置信度在增加从0.998到0.999;或者是有的活动删除或新增关系结点也会引起流程模型的改变,如rel(K,E)就不在模型中更新;再者有依赖关系没有在模型中出现,并且在新增日志中也为再出现这一关系,保留此关系并不更新流程模型,如rel(D,K),rel(J,N).因此,得到新的流程模型如图4.经过行为适当性计算aB(M)=0.419,aB(M1)=0.451,aB(M1)>aB(M),说明优化后模型的行为适当性得到了提高.
5 结束语
本文提出了一种增量挖掘优化流程模型方法,首先,通过频数高的日志建立初始模型,由于不是全部日志,因此需要对初步建立的模型进行优化分析.本文通过扩展的启发式挖掘,重新构造了使用的数据结构,以支持模型的增量更新,通过依赖关系树的更新来优化流程模型,最后,通过一个实例说明业务流程优化方法的可行性.未来需要对复杂模型进行优化,且文章仅考虑了控制流方面对于数据流,资源等方面没有考虑,将是下一步工作重点.
参考文献:
〔1〕Yuke Yang, Lukasz Golab , M. Tamer Ozsu. ViewDF: Declarative incremental view maintenance for streaming data[J]. Information Systems,2017,(71):55-67.
〔2〕Yanchao Li, Yongli Wang, Qi Liu,etal.Incremental semi-supervised learning on streaming data[J]. Pattern Recognition,2019,(88):383-396.
〔3〕Unil Yun a , Heungmo Ryang a , Gangin Lee a , Hamido Fujita An efficient algorithm for mining high utility patterns from incremental databases with one database scan[J]. Knowledge-Based Systems,2017:124:188–206.
〔4〕Ehab Abdelhamid, Mustafa Canim,etal. Incremental Frequent Subgraph Mining on Large EvolvingGraphs[C].IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, 2017:2710-2723.
〔5〕Hanieh Fasihy , MohammadHosseinNadimi Shahraki Incremental mining maximal frequent patterns from univariate uncertain data[J] Knowledge-Based Systems,2018,152: 40–50.
〔6〕Diana-Lucia Miholcaa, Gabriela Czibulaa, A new incremental relational association rules mining approach[J]. ScienceDirect nce,2018,126:126–135.
〔7〕Zhongying Zhao, Chao Li,etal. An incremental method to detect communities in dynamic evolving social networks[J]. Knowledge-Based Systems,2019,163:404–415.
〔8〕Wenhao Shu, Wenbin Qian b, Yonghong Xie Incremental approaches for feature selection from dynamic data with the variation of multiple objects[J]. Knowledge-Based Systems ,2019,163:320–331.
〔9〕Kalsing A C,Thom L H,Iochpe C, et al. AN INCREMENTAL PROCESS MINING ALGORITHM[C]. international conference on enterprise information systems, 2010: 263-268.
〔10〕Smirnov S, Weidlich M, Mendling J. Business Process Model Abstraction based on Behaviroural Profiles[C]. In 8th International Conference, San Francisco, December 7-10, 2010. Heidelberg: Springer Berlin Heidelberg, 2010, 6470:1-16.
〔11〕Weidlich M,Polyvyanyy A,Desai N,et al.Process compliance measurement based on behavioural profiles[C]. Advanced Information Systems Engineering.Berlin Heidelberg:Springer,2010:499-514.
〔12〕Van der Aalst W, Weijters T, Maruster L.Workflow mining: Discovering process models from event logs[J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(9):1128-1142.
〔13〕Li S , Li T , Liu D . Incremental updating approximations in dominance-based rough sets approach under the variation of the attribute set[J]. Knowledge-Based Systems, 2013, 40:17-26.
〔14〕Li Y , Liu X Q , Hou J J . Maintaining Dynamic Information Systems Using Incremental Dominance-Based Rough Set Approach[J]. Applied Mechanics and Materials, 2014, 631-632:53-56.
〔15〕Shu W, Qian W. An incremental approach to attribute reduction from dynamic incomplete decision systems in rough set theory[J]. Data & Knowledge Engineering, 2015, 100:116-132.
〔16〕Jing Y , Li T , Luo C , et al. An incremental approach for attribute reduction based on knowledge granularity[J]. Knowledge-Based Systems, 2016, 104:24-38.
