基于协同过滤算法实现高校个性化就业推荐系统研究
2019-09-10刘艳
摘 要:高校畢业生就业形势严峻、竞争异常激烈。“就业难”源于毕业生对于企业需求认识不足和对自我的认知不足,所以很多时候只能找一个专业不对口又不感兴趣的工作,而企业又出现的“招人难”的现象,又造成了毕业生和企业双方的损耗。协同过滤算法的个性化就业推荐系统,能够通过挖掘学生的兴趣爱好、职业导向等多重信息,从而生成学生就业兴趣模型,同时结合以往毕业生就业数据,为毕业生提供适合自身的就业推荐导向。本文重点介绍了基于协同过滤算法的就业推荐概念及基于协同过滤算法实现高校个性化就业推荐系统是如何开发设计的。
关键词:协同过滤算法;高校毕业生;个性化就业推荐系统
中图分类号:TP391.3 文献标识码:A 文章编号:2096-4706(2019)15-0010-03
Research on Personalized Employment Recommendation System in
Colleges Based on Collaborative Filtering Algorithms
LIU Yan
(Software College of Hunan Vocational College of Science and Technology, Changsha 410118,China)
Abstract:The employment situation of college graduates is severe and the competition is fierce. “difficult employment” is due to the lack of awareness of the needs of enterprises and self-awareness of graduates,so many times they can only find a job that is not suitable for your major and not interesting ,and the phenomenon of “difficult recruitment” appears in enterprises,which results in the loss of both graduates and enterprises. Through the personalized employment recommendation system based on collaborative filtering algorithm,the model of students’interest in employment can be generated by mining multiple information such as students’interests,career orientation and so on. At the same time,combined with previous graduate employment data,it can provide graduates with suitable employment recommendation guidance. This paper focuses on the concept of employment recommendation based on collaborative filtering algorithm and how to develop and design the personalized employment recommendation system based on collaborative filtering algorithm.
Keywords:collaborative filtering algorithm;college graduates;personalized employment recommendation system
0 引 言
据统计,2018年全国普通高校毕业生人数将近820万人,高校毕业生数量从2001年的114万增长到2018年的820万,主要缘于教育改革实行过后,高校的大规模扩招。毕业生人数的不断增加使得大学生的就业压力年年增大,很多高校毕业生找不到工作,时时刻刻喊着“就业难”,同时企业却出现了招不到可用人才的境遇。“就业难”一方面是因为人才质量培养质量的下降和就业人数的不断增加,另一方面则因为毕业生对于企业需求认识不足和对自我的认知不足。很多毕业生都存在着“高不成低不就”的现象,这使得就业难上加难。同时,高校为了增加学生就业率,也积极为毕业生们开展就业指导、免费为毕业生们提供双选会招聘会等。但是在这个过程中,由于师资力量和专业水平等多方面的原因,高校的就业指导工作仍旧无法实现一对一的个性化推荐,所以毕业生们无法找到自己满意的工作,而企业又找不到想要的人才。
互联网的飞速发展和各种信息的爆炸式增长,使得人们越来越难以获得有针对性的信息,在此基础上个性化推荐系统应运而生。个性化推荐系统能快速帮助用户在广袤的信息海洋中寻找到有效信息,满足用户的个性化需求。这种个性化推荐系统无疑为高校毕业生的个性化就业推荐提供了有效的方法。每年的招聘信息数据和毕业生就业数据为高校毕业生的个性化就业推荐提供了大量信息支持。个性化就业推荐系统能够通过挖掘学生的兴趣爱好、职业导向等多重信息,从而生成学生就业兴趣模型,同时结合以往毕业生的就业数据,为应届毕业生提供适合自身的就业推荐导向。
1 协同过滤推荐算法概述
个性化推荐系统中最核心的内容是推荐算法模块,常用的推荐算法有协同过滤算法、基于内容的推荐算法、基于网络结构的推荐算法和混合推荐算法等,其中最为行之有效的就是协同过滤推荐算法。
协同过滤推荐(Collaborative Filtering Recommendation,简称CFR)的概念是在1992年第一次提出来的,首次应用于Tapestry系统。该方法主要是通过寻找相似度用户为目标,根据用户的喜好程度进行预测,协同过滤推荐在个性化、自动化以及持久性等方面与之前方法相比都有了明显提高。其计算原理为:利用用户历史数据判断用户的相似性,通过计算出来的相似性找到与用户最相似的用户集合,为用户推荐喜欢的产品[1]。
1.1 传统的基于协同过滤算法的个性化就业推荐模型
采用协同过滤算法进行个性化就业推荐,首先要建立毕业生就业模型,为了提高计算效率,缩小相似度的计算空间是重点,本文采用K-means聚类对毕业生的就业选择评分进行分类,然后在各个分类中寻找评分相似的毕业生。
首先对数据模型进行描述,构造xy阶矩阵,x代表毕业生数,y代表不同类型的企业数,R表示每个毕业生对不同类型企业的喜好评分合集,即R=(rij)xy,rij表示毕业生对不同类型企业的评分值,可以设定5级评分制(0级到4级),0表示不喜欢该企业,4表示非常喜欢该企业。
其次对学生的评分进行聚类,通过计算毕业生就业选择评分,找出分数相似的毕业生,在集合中选择相似度最高的多个企业推荐给毕业生作为就业选择。
1.2 改进的基于协同过滤算法的个性化就业推荐模型
高校毕业生的就业是一个双向选择问题,传统的基于协同过滤算法的个性化就业推荐模型虽然可以帮助毕业生更精准的选择适合自己的就业企业,但是却忽略了企业的择人要求,因为本文提出改进的基于协同过滤算法的个性化就业推荐模型,个性化就业推荐模型不仅要考虑到毕业生的就业兴趣和选择,同时还要考虑企业的招聘需求和择人标准。结合主客观两个方面来判断毕业生的相似度,避免不相关的毕业生选择对相似毕业生选择的产生干扰,提高毕业生就业推荐系统的双层次进准度。
2 基于协同过滤算法实现高校个性化就业推荐系统研究
2.1 推荐原理简述
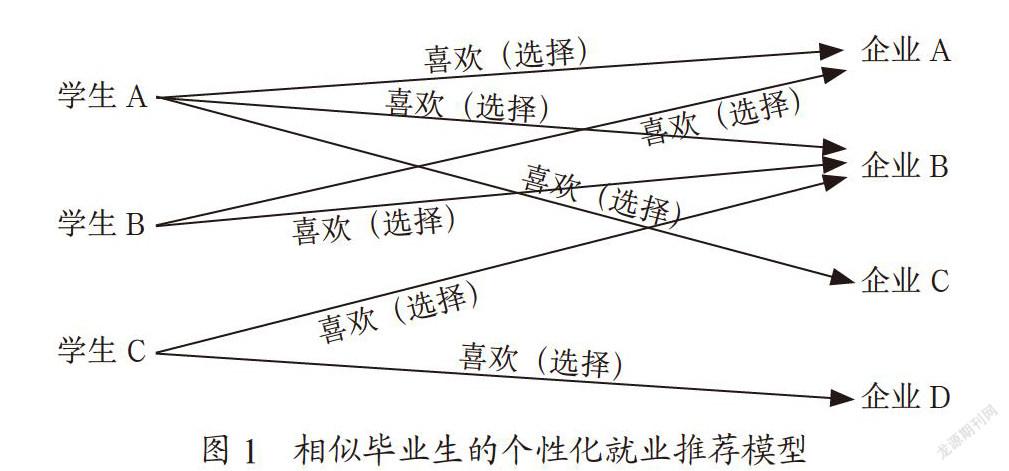
实现高校毕业生个性化就业推荐的过程,其实就是要通过毕业生的个人兴趣爱好、所学专业等因素找到和企业的具体需求相似度高的企业。所以基于高校本身往届毕业生的数据,采用相似性传递原理,首先找到与应届毕业生最为相似的往届毕业生,然后把他们做一对一或一对多的对应,形成对应集,把往届毕业生选择的企业推荐给应届毕业生,这样建立起应届毕业生和企业之间的相似关系。例如,毕业生A和毕业生B相似,那么毕业生B喜欢的单位毕业生A很有可能会喜欢,毕业生B选择的企业选择毕业生A的机会也会更大,如图1所示,相似毕业生的个性化就业推荐模型。
2.2 基于协同过滤算法的高校个性化就业推荐系统用户模型塑造
基于协同过滤算法的高校个性化就业推荐系统面向的对象是高校毕业生,而推荐系统的使用者主要是高校或者企业人事或招聘网站。在系统的应用目标方面,高校主要是为了根据毕业生的特点为其推荐合适的岗位,增加就业率。企业人事或招聘网站主要是为了通过对往届毕业生的招聘经验,找到最合适其工作岗位的应届毕业生。因而系统的第一步就是要塑造毕业生用户模型,也就是要对毕业生的就业特征进行提取。
2.2.1 毕业生信息提取
首先是毕业生基本信息的提取,基本信息主要包括毕业生的性别、身高、体重等,这些信息的获取可以从学生的毕业档案中提取,收集毕业生基本信息是很重要的,因为很多岗位对员工的自然情况是有一定要求的。
其次是影响毕业生就业选择的其他因素,包括个人层面、家庭层面、学校层面和社会影响层面。个人层面,包括学生的专业、学历、兴趣爱好、生源地等;家庭层面包括父母的社会地位、经济状况等因素;学校层面包括学校所以地、学校整理影响力、科研水平和课程体系等;社会影响层面包括社会法规、就业政策、落户政策,人才市场需求等因素。
2.2.2 毕业生就业特征权重值
权重值在算法中起到重要作用,因为能够在毕业生就业中起到作用的因素的重要性,并不是相同的,而是要有所侧重的。可以从多个角度进行分析与设计,从企业人事或招聘网站角度来说,他们往往侧重于学生的某几项技能,因此这某几项技能的权重值要相应地有所增大,進而实现企业用人的精准化[2]。从学生角度来说,学生在学习和成长过程中兴趣爱好与就业取向是会发生变化的,从就业取向方面来说,新变化的往往才是学生目前真正想从事的工作,所以相对陈旧的就业意图,重要性权重值设计时要高很多,才能真正体现学生的就业想法[3]。
2.3 基于协同过滤算法的高校个性化就业推荐系统用户模型的实现
根据毕业生信息的提取、就业特征权重值的推算办法和K-means聚类法,构建基于毕业生特征的协同过滤推荐算法,用X={X1,X2,…,Xn}代表往届毕业生和应届毕业生的就业特征向量,Y={Y1,Y2,…,Yn}代表往届毕业生和应届毕业生的就业兴趣评分向量。然后对所有往届毕业生的就业特征向量进行聚类分析,直到最后聚类中心不变动。随后输入每位应届毕业生的就业特征向量和就业兴趣向量,找出计算得出的最小值对应的聚类中心,那么应届毕业生就属于这一类。这样根据设定的推荐企业或推荐岗位把最相似的往届毕业生的工作单位推荐给应届毕业生,实现基于协同过滤算法的高校个性化就业推荐。
3 结 论
对基于协同过滤算法的高校个性化就业推荐系统的研究,可以解决高校毕业生盲目就业,招聘企业盲目招聘等问题,它可以根据毕业生的兴趣爱好、专业方向等实现毕业生的精准就业,也可以为招聘企业精准招聘提供有力的依据。然而,一个系统的实现涉及到多领域多方面的知识点,一个算法的实现和优化也需要结合多领域多方面的知识点进行研究和探讨。在基于协同过滤算法的高校个性化就业推荐系统的实现过程中,还需要不断的深入研究,以提升该模型的精准度和实用性[4]。同时,一个系统经过设计与实现并不足以完全具备准确性,还要经过后期的测试和不断地应用,在应用中不断改进和提升。
参考文献:
[1] 揭正梅.基于协同过滤的高校个性化就业推荐系统研究 [D].昆明:昆明理工大学,2015.
[2] 隋占丽,李文,李影,等.面向大学生就业的协同过滤推荐算法与推荐系统研究 [J].山东农业工程学院学报,2017,34(4):3-4.
[3] 曹红姣.基于情境感知的大学生就业推荐系统的设计与实现 [D].武汉:华中师范大学,2014.
[4] 郭韦昱.基于用户行为分析的个性化推荐系统设计与实现 [D].南京:南京大学,2012.
作者简介:刘艳(1982-),女,汉族,湖南长沙人,讲师,硕士,研究方向:移动应用、大数据。
