基于主题模型的文化资源密集区感知研究
2019-09-10郜童童刘文泽孟斌黄松陈思宇
郜童童 刘文泽 孟斌 黄松 陈思宇



[摘要]随着国家树立文化自信、强调文化传承、弘扬文化精髓等战略的提出,要求调动一切力量发展和继承文化传统,文化资源密集区文化遗产丰富,作为文化传承保护的重要载体愈发被学者和社会各界人士关注。在总结梳理现阶段文化遗产保护传承利用相关研究的基础上,探索将微博数据、大数据分析方法与文化资源保护利用相结合,利用爬虫工具获取门头沟地区2017年一年内带有位置信息的9万余条微博数据,运用机器学习框架Scikit-Learn,通过朴素贝叶斯对相关数据进行学习训练,将与文化感知相关的微博文本选取出来,进一步用LDA模型将文化资源保护利用的相关微博分为5个主题,并利用GIS技术,将主题分析结果进行空间分析,根据每个主题的空间分布特征与主题关键词特征相结合,归纳为古刹祈福、徒步观景、古村度假、自驾休闲、民俗感悟五大主题,发现5个主题的分布空间特征较为明显,文化资源密集区的空间结构对归属主题的内涵有很好的解释和支撑作用。
[关键词]文化感知;文化资源密集区;LDA模型;微博数据;网格分析
[中图分类号]G 122[文献标志码]A[文章编号]1005-0310(2019)02-0045-11
Abstract: As the country establishes cultural self-confidence, emphasizes cultural heritages, and promotes the essence of culture, it is demanded to mobilize all forces to develop and inherit cultural traditions. As an important carrier of cultural heritage and protection, cultural heritage in the areas with intensive cultural resources has been paid more and more attention by scholars and people from all walks of life. Based on the summary of the research on the inheritance and utilization of cultural heritage protection at this stage, this paper explores the combination of microblog data, big data analysis methods and cultural heritage protection. By using the reptile tool to obtain more than 90,000 pieces of Weibo data with location information in the Mentougou area in 2017, and by using the machine learning framework Scikit-Learn, the learning and training related data through Naive Bayes will be related to cultural heritage perception. The microblog text is selected, and the related microblogs of cultural heritage sites are further divided into five themes by LDA model, and the GIS technology is used to spatially analyze the topic analysis results. According to the spatial distribution characteristics of each topic and with the combination of the topic key word characteristics, the conclusion is summarized as the five themes of ancient temple blessing, walking observation, ancient village vacation, self-driving leisure, and folklore perception. It finds that the distribution characteristics of the five themes are more obvious, and the spatial structure of the cultural resource-intensive areas has a good explanation for the connotation of the subject and supporting effect.
Keywords: Cultural perception; Cultural resource-intensive areas; LDA Model; Microblog data; Grid analysis
0引言
文化遺产具有悠久的历史,反映着人类社会发展的进程,体现着传统优秀文化的精神内涵,具有极高的艺术价值和文化价值。习近平总书记在党的十九大报告中指出要“坚定文化自信,推动社会主义文化繁荣昌盛”[1],而注重文化遗产地保护、深入挖掘其内涵价值,可以推动文化自信、文化发展、文化繁荣,总书记在十九大报告中还提到要“加强文物保护利用和文化遗产保护传承”[1],就需要我们从多方面、多角度探索文化遗产保护传承的方法。而文化遗产地是文化遗产的空间载体,研究文化遗产地是对文化遗产保护传承的一个重要方面,可以从地理空间视角探索文化遗产保护传承。
现今我国学者对于文化遗产地的研究方法和角度多样,很多学者致力于相关定性研究,这类研究多提出一种思路,对较为宏观尺度的文化遗产资源进行分析,提出适用的旅游开发建议,如贵州、江苏、陕西等[2-4]。也有学者对于文化遗产地的非物质文化资源旅游开发研究较多,重视文化遗产地非物质文化遗产更加细分的研究,如传统手工制作技艺[5]、民俗体育[6]、传统曲艺[7]等,注重对非物质文化的分析,针对不同类型的非物质文化遗产提出了建议,如文化遗产传播可以利用直播平台[8]、建设非遗博物馆等[6]。总的来说,相关定性研究角度多样,但是缺乏有效的数据做支撑,对时间、空间的变化并没有追踪调查,很难与时俱进地了解文化遗产地相应的变化。我国学者对于文化遗产地的定量研究也颇多,大多与旅游结合集中在更小的尺度空间,如很多学者深入对文化遗产地游客感知、居民感知两个视角的分析。在游客感知方面的研究有安徽黟县宏村[9]、杭州西湖[10]、河南嵩山少林寺[11]等,提出如突出开发旅游体验项目、加强智慧旅游公共设施投入等建议。在居民感知方面研究有安徽西递村[12]、广西桂林龙脊平安寨[13]、四川九寨沟[14]等,提出如应让居民更多地参与旅游开发、构建合理的利益分配机制等建议。相关的定量研究虽然有一定的问卷调查量,但其样本数量不具规模,质量有待深入评价。同时调查问卷形式也具有人力物力成本大、周期性长等缺点,过于注重旅游开发视角,对文化价值研究不足,这就可能导致实践操作层面可行性不强等问题。
除了定性研究和定量研究,还有一些学者开展了大数据对文化遗产地的研究,多以某一文化遗产地为例,通过一些数据平台收集、筛选大量数据,从某种角度对数据进行分析,但缺乏对旅游地的空间分布规律研究,将文本数据与地理空间技术应用的结合较弱,缺乏文化遗产地空间解读。很多学者以某些角度为基础收集微博数据进行分析,如旅游形象感知[15]、游客流分析[16]、文化遗产认知[17]、营销现状[18]等,通过大数据分析得出结论或建议,如有学者认为文化遗产地交通拥堵缺乏管理,应当加强巡视管理等。虽然学者们用大数据对文化遗产地进行分析有所成果,但是过于聚焦于旅游,对文化遗产价值、文化遗产的空间分布规律、空间应用技术研究不足。但值得一提的是,也有学者通过大数据对文化遗产价值或文化遗产空间分布规律进行深入探讨。如周佳颖等人通过筛选大量的微博數据,探测现今民众对中国传统节日的情感认知以及认知区域特征[19]。孟斌等人通过对北京三山五园的研究,梳理GIS云技术发布数字化历史地图及建立应用系统的程序,阐述数字化技术方法对于首都北京城市空间形态的研究意义[20]。
本文基于主题模型的微博用户数据,通过数据分析、实证研究对文化遗产价值和资源、空间位置信息、空间分布规律进行深入研究,从地理空间视角探索文化遗产保护以及文化遗产丰富区域的可持续发展。本文选取的门头沟地区严格意义上不属于文化遗产地,但是其本身的文化资源丰富程度不容忽视,文化资源密集,历史底蕴丰厚,对于文化资源密集区感知研究与对文化遗产地研究有着很好的支撑作用,从而探索文化遗产保护研究。运用大数据方法对文化资源密集区感知研究就是为了更全面地对门头沟地区的文化资源进行分析,微博文本数据真实性较强、数量规模大、针对性强,通过微博数据进行文化资源密集区感知研究,有助于促进这些区域的文化遗产保护和区域的可持续发展,为未来的文化资源丰富地区提供一种保护思路。
1数据及研究方法
1.1研究区域与数据源
1.1.1研究区域概况
门头沟区隶属北京市,位于北京城区正西偏南,是个有着深厚历史底蕴的文化资源密集区。拥有北京城母亲河之称的永定河自由徜徉其中,早在1万年前的新石器早期,北京历史上著名的东胡林人就在此繁衍生息。门头沟地区历史文化资源十分丰富,拥有潭柘寺、戒台寺、爨底下村古建筑群和灵岳寺等全国重点文物保护单位,北京市级文物保护单位9个,琉璃渠村、爨底下村、灵水村等3个村入选由建设部和国家文物局共同组织评选的“中国历史文化名村”,在已经公布的四批中国传统村落名单中,北京共有21个村入选,其中门头沟区就有12个。在北京市十三五规划纲要中,明确提出要“挖掘区域文化遗产整体价值,制定实施北部长城文化带、东部运河文化带、西部西山文化带保护利用规划”[21],西山永定河文化带成为推动北京文化中心建设的重要抓手之一。随着西山永定河文化带地位的确立,门头沟区在文化带中的历史文化价值逐渐被人们关注。
1.1.2数据源与数据获取
数据的获取上,本文利用新浪微博官方API和网页爬虫工具,获取门头沟地区的2017年微博用户数据。根据新浪微博官方发布的2018年第一季度财报显示,截至2018年3月,微博月活跃用户数已增至4.11亿,日活跃用户则增至1.84亿,其中活跃用户中来自移动端的比例达到了93%。面对如此巨大的体量和海量数据,在数据源选取上有针对性地设置选取规则,例如只对定位为门头沟辖区内的微博进行抓取,字符长度在4个字符以上,抓取的属性包含微博ID、文本、时间、经纬度等信息,最终获取近10万条微博信息作为数据源。
微博数据等大数据具有价值密度低的特点,因此数据的预处理是后续分析的基础,针对此次获取的微博数据的处理包括自定义词典的建立和停用词的剔除两部分。由于中文文档中没有明确的分隔符,不能直接引用西方文本以空格为词语的自然分隔符方式,所以需要利用中文分词处理技术将汉字序列切分成单独的具有明确语义的词项。本文在多次试验的基础上,建立了一套关于门头沟区文化资源密集区的自定义词典,包括地点的名词、行为和情绪的表达,如爨底下、定都阁、石佛岭、点赞、美照、夜跑等,利用基于语义的分词算法,得到了较好的分词结果。为了提高数据采集精度,需要对数据进行停用词的剔除,包括微博表述中经常用到的@、#、//、表情等特殊符号,中文语境下使用普遍但却无实际意义的词语,诸如语气助词、介词、连词、副词等加入停用词库进行降噪处理,并且将广告、打榜、抽奖等无关微博进行剔除。
1.2研究方法
1.2.1基于语义的微博分类与提取
基于语义的微博分类提取,利用Python机器学习框架Scikit-Learn制作分类模型,对微博文本进行分类与提取。Scikit-Learn是一款简单有效的数据挖掘和数据分析工具,集成了成熟的机器学习的算法,可以广泛用于解决监督和非监督分类问题[22-23],其中特征选取采用IF-IDF方法计算,在常用的7种统计学分类方法中,朴素贝叶斯(Naive Bayes)处理微博数据优势较为明显,特别是对于二类分类的学习训练时间短,精确率、正确率、召回率明显高于其他分类方法[24]。本文在原始数据中随机抽取1万条微博,采用监督分类的方式对文本进行识别,并且利用标签分类赋值,与文化资源密集区相关的微博赋值为1,否则赋值为0,利用朴素贝叶斯算法进行机器学习文本分类,在源数据中计算机识别分类,为主题模型的构建提供了数据基础。
1.2.2LDA主题模型分析
LDA主题模型是David M.Blei等[25]人基于浅语义分析和概率浅语义分析提出的一种对文本数据的主题信息进行建模的主题概率模型[26]。LDA可以用来识别大规模文档集或语料库中潜藏的主题信息,并且有极强的解释性,可以有效地解决短文本数据稀疏性的问题[27],主题提取效果显著,可较好地反映文本体现的热点话题。LDA模型也是一个三层贝叶斯概率模型,包含词-主题-文档3层结构,通过运用概率方法对模型进行推导,来寻找文本集的语义结构,挖掘文本的主题[28]。这种非监督学习的主题构建算法,无需对训练集进行人为标注,只需在文档集以及语料库中指定主题的数量k、迭代次数和狄利克雷参数即可[29],极大地节省了人力成本和时间成本。目前LDA模型作为最基础、最著名的主题构建方式,广泛地应用于主题挖掘和舆情分析,有学者将其与情感分析相结合,展开旅游地[30]或传统节日的感知研究,也有学者尝试作为微博信息推荐依据[31]、科学文献分析[32]的方法。本文基于 Python3.5 中 Gensim 库的LDA 模型构建算法,对经过语义提取出的关于文化资源密集区相关微博的文本内容进行主题分析,通过LDA 模型中的词袋(Bag of Words)计算出不同主题的概率,以及主题下对应的词语分布概率,最终获得微博用戶对文化资源密集区感知的主题聚类结果。
2结果及分析
2.1分类结果分析
自定义词典的确定。在试验前期阶段,作者发现默认的分词计算效果欠佳,无法有效地将门头沟地区文化内涵较为丰富的地点进行分词识别,例如文本为“爨底下”“定都峰”,会被计算机语句分为“爨/底下”“定都/峰”两个词。分词是文本分析的基础步骤,不正确的分词直接影响数据的分析,因此建立门头沟地区文化遗产相关的自定义词典十分必要。通过文献查询和对文本多次、反复的试验,将文化资源密集区名单加入词典当中,以及通过多次的人工矫正,对不正确的分词加以调整,最终得到较好的分词结果。
分类测试识别文化资源密集区相关的微博,在Excel中调用look up工具在源数据中随机抽取2万条微博进行人工标注,标注规则为文本明确提及文化资源密集区,或没有出现明确地点但是通过文本内容可以判断发布者来自文化资源地的可以标注为1,否则将判别为与文化资源或遗产无关微博并标注为0。为了将主观因素降到最低,采用阅卷形式,同一份数据最多3个人进行标注,如果两人标注内容相左,则交由第三人进行判别。最终在数据中获得训练样本近1万条,包括正向即1和负向即0的人工识别标签各近5千条。将训练样本进行机器学习,利用朴素贝叶斯方法对源数据进行文本分类,最终提取出文化资源密集区相关微博2万3千条左右。在自检结果中,混淆矩阵显示人工标注和计算机识别均为正向的文本1 018条,同为负向的文本1 148条,经计算自检率达到87.6%,综合判定分类结果准确率为86.5%,机器学习分类结果比较理想(见表1)。
2.2主题分析结果及分析
2.2.1主题数量的确定
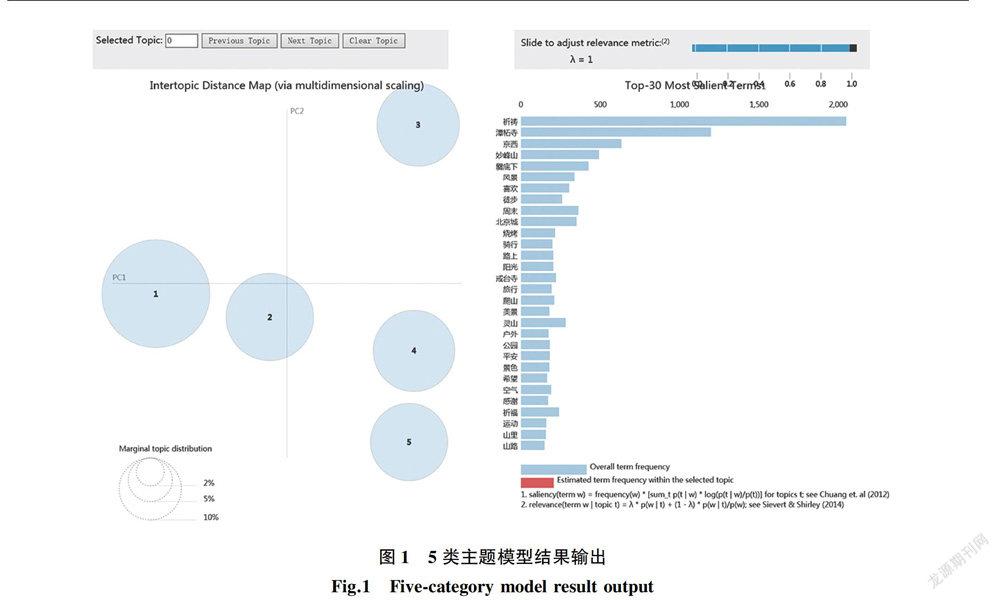
为了更精确地选择微博主题的数量,以期获得比较准确、全面的结果,第一次试验,尝试将主题个数设定为4,输出25个关键词,通过对结果图的查验以及关键词的辨别,发现当主题个数为4时,2类主题与4类主题高度重合,从关键词来看,两个主题都反映户外风景观光,分类差异特征不明显,结果不佳。而后,分别将主题个数依次上调,得到不同数量主题的结果展示图以及输出的关键词,通过统计图中每个主题的分布比较,以及关键词的对比核查,发现随着主题个数的增多,地点类关键词如“潭柘寺”“爨底下”“妙峰山”“京西”等词基本都占有较高的贡献值,但是超过5个主题后,随着主题数量越多,各个主题分布的位置都有不同程度的交叉重叠现象,有的甚至出现3个主题甚至4个主题分布位置叠盖在一起,加之对关键词的校验发现各主题间关键词糅杂,模糊了各个主题的特点,不能很好地提取出每个主题的特征,会为解读带来较大困难,效果不理想。通过多次的实验探索,最终确定当主题个数为5个时,各主题在结果图中的分布较为分散,关键词也能较为清楚地反映每个主题的特征,决定将其作为本文的实验结果,进行下一步分析解读的基础(见图1、表2)。
2.2.2主题关键词及其解读
和前三个主题不同,主题4中的关键词是一个动词“喜欢”(见图5),其表达的是情绪的好坏,对于用户的关注点无法判断,只能侧面表现用户的心情,所以进一步综合其他关键词对其主题进行分析。由图5可知,该主题中公园旅行的贡献率最高,这部分用户更加关注的地点是有休闲游憩功能的公园,主要的景点有定都阁、莲石湖、神泉峡等,这些景点区域都位于门头沟区东部,属于近郊地区。关键词“开车”也能很好地证明这些区域距离城区较近,非常适合短途自驾游、组团游等旅游模式。配合“好吃”“美食”“活动”等关键词可知该主题在游玩之余有了餐饮的涉及,野餐露营或者品尝特色美食等概率较高。
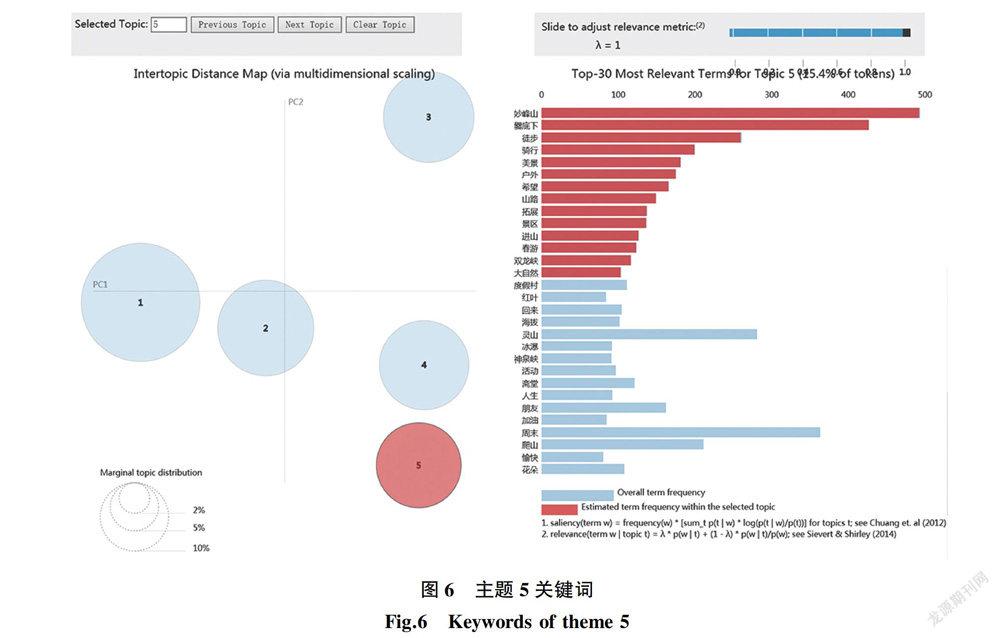
主题5可以看到两个地点性关键词“妙峰山”和“爨底下”的贡献率都十分高(见图6),这两个地点看似关联度不高,但是用户将两个地点的话题放在一起比例较高,可以从两地的文化背景着手分析,妙峰山是门头沟区乃至京西民俗文化的发祥地,有着悠久的民俗传统和广泛的传播,而爨底下村,作为首批录入国家级文化遗产地的古村落,其独特的古建筑和古民居风貌引人入胜,居民的建筑形式、生产习俗、聚落形态等作为民俗文化的重要组成部分,展现了爨底下村悠久而深沉的民间文化。因此不难理解妙峰山与爨底下村在历史底蕴和民俗魅力上的共同点,通过户外徒步、骑行、拓展等形式,身体力行,融入其中,表达了对民俗文化的积极性与关注度。
2.2.3主题的空间分布
将主题模型输出结果导入ARCGIS10.6,利用渔网工具建立格网,对其进行格网分析,计算每个格网中每个主题数量所占的比率,比率较高的格网就是相关主题空间分布的热点地区。本研究选取占比为50%以上作为标准,获取每个主题代表性的地区相对分布的空间特征。如图7所示,主题1主要分布于门头沟区中北部和东南部地区,集中分布于雁翅镇和潭柘寺镇。
主题2零散分布在各个村镇,主要集中于门头沟区西部的清水镇。主题3分布东西部地区差异较为明显,集中分布在中西部的村镇。主题4分布于门头沟西部和北部地区,清水镇、斋堂镇和雁翅镇分布数量较多。主题5分布较为广泛,在清水镇、斋堂镇、雁翅镇、妙峰山镇和潭柘寺镇较为集中。各个主题在门头沟区各个地区均有分布,但差异性较为明显。
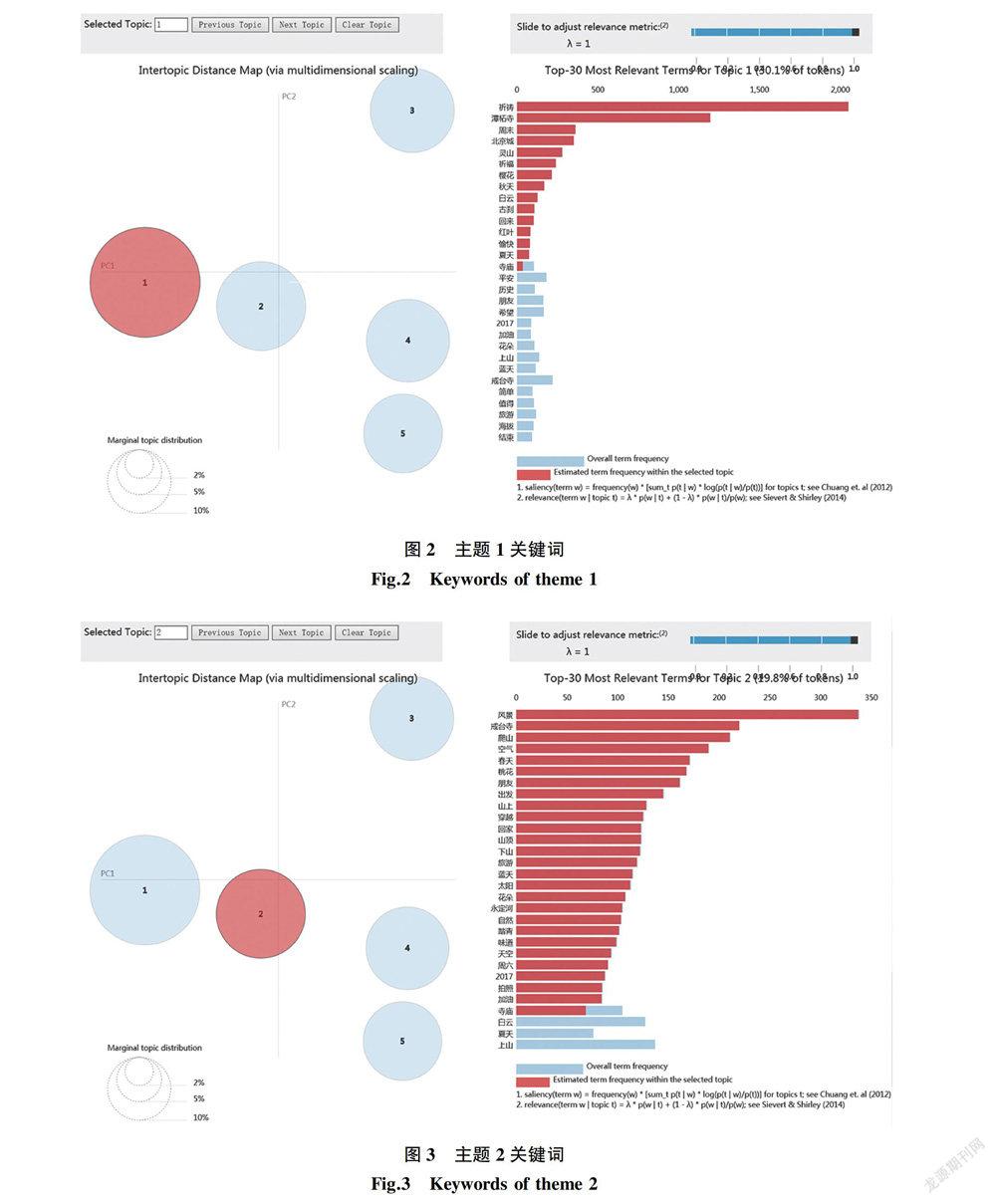
主题1位置分布有明显沿道路分布的特征,东南部该主题体现较为明显的网格大致与潭王路道路线路分布趋势相同,潭王路是通往天门山景区以及潭柘寺景区的主干路,可以理解为用户习惯于在祈福来往的路上进行相关微博内容的发送。潭王路北部区域为妙峰灵溪景区,妙峰山建有娘娘庙等庙宇,三处庙宇群分别为灵感宫、回香阁、玉皇顶,山上建有释、道、儒、俗等不同信仰的殿宇14座,以创建于明末的“娘娘庙”著名,可以看出妙峰山也是用户选择祈福的文化遗产地区之一。北部热点区域大部分沿道路分布,较为明显的分布在大镇路、庄大路、高芹路,这3条路都距离得胜寺较近,且周边并无其他景区或遗产地,可以认为是前往得胜寺祈福的用户在祈福路上或归途进行的相关内容分享,故而本文将主题1归纳为古刹祈福主题。如图8所示。
主题2主要集中清水镇,清水镇南部的热点地区为百花山国家级自然保护区,其风景资源包括主峰景区、草甸景区、望海楼景区、百草畔景区四大景区。保护区中18处独特景观、35个景点,有丰富的生态价值、观光价值和科考价值,是注重体验自然遗产风光用户的选择地之一。清水镇北部的观景主题体现也十分明显,主要分布于灵山自然风景区、龙门涧风景区和黄草梁景区,3个景区位置紧密,形成了强大的风景观光吸引力,致使用户无法忽视其自然景观价值,成为观景热点区域。另外两个热点网格分别置于109国道和高沿路,109国道是通往门头沟区西部的主干道,其交通地位显著,高沿路的热点体现,很可能是其服务于靠北地区用户前往清水镇进行观光游览的道路,两条道路都是通往清水镇观景游览比较重要的交通线路,故而将主题2归纳为徒步观景。如图9所示。
主题3中清水镇的热点村落在黄安村,位于清水镇西南通往百花山的方向,相传宋代已成村,村中不仅有众多的古民居,还有昌宛专署旧址、石刻和过街楼等,其中昌宛黄安专署旧址为门头沟区级文保单位,加之百花山国家级保护区的带动,黄安村成为该主题的热点地区。其他热点地区分散位于109国道、斋柏路、军红路周边,沿线村落众多,如灵水村、爨底下村、张家村等,村落大都历史悠远、特色鲜明、古迹较为丰富。沿途还有一些度假村、避暑山庄、客栈等设施,为游客提供中长期村庄生活体验,村落具有一定的旅游开发基础,民俗、饮食等基础设施完善,村内物质文化遗存较为丰富,再之周边自然景观丰富,为家人周末度假创造了良好的条件,
让自己在游玩的同时不至于过于疲惫,更好地促进家庭之间的感情,所以可以将主题3归纳为古村度假。如图10所示。
主题4的热点从空间分布上来看,多位于主干道附近如109国道,109国道定位区域方便到达,分布于门头沟中西部地区,良好的交通条件弥补了距离城区较远的缺点。
同时从热点分布来看,部分热点积聚于斋堂镇,斋堂镇在门头沟区基础设施相对完善、旅游知名度较高,大量游人开车来此游玩。通过上文对主题4的关键词分析解读,提取到了具有多元性的休閑娱乐,其关键词也体现了短途旅游的特点,同时根据其热点的空间分布点位于主要交通干道和斋堂镇,其较高的交通通达性的作用明显,可以将主题4归纳为自驾休闲。如图11所示。
主题5热点地区为斋堂镇灵水村,被国家文物局列为第二批公布的“中国历史文化名村”,该村自古有崇尚文化的遗风,明初就建有社学,尊师重教,读书上进蔚然成风,出过22名举人、2名进士和10余名全国最高学府国子监的监生,得名“灵水举人村”。此地打卡的用户无疑可以很好地感受灵水村传承悠久的“尚学”民风传统,体会浓厚特色的教育文化。另外打卡热点地区为妙峰山,是以宗教民俗为主的文化圣地,每年均举办妙峰山娘娘庙会,以香客祭祀妙峰山“天仙圣母碧霞元君”为中心活动,集民间花会、戏曲曲艺表演、观赏自然风光和集市活动为一体,很好地展现妙峰山地区的民俗特色和民间信仰文化。还有部分打卡热点地区为采摘园、观光园等农业特色项目体验区,展现农家民俗,例如京西山水种植社、紫云樱桃采摘园、京西东山贡梨园等民俗特色体验区,对民俗、农乐等进行感知,综合关键词中的妙峰山、爨底下,展现的是丰富的民俗文化内涵,故而主题5为民俗感悟。如图12所示。
3结论与讨论
3.1结论
本文以微博数据为依托,尝试将其与文化遗产地的感知研究相结合,利用朴素贝叶斯文本分类方法,在提取门头沟区文化遗产地相关微博的基础上,运用LDA模型进行主题模型构建,并且将各个
模型的结果回归地图,研究不同主题的分布特征,
得到以下结论:
1) 门头沟地区与文化遗产相关微博分为五大主题。经过LDA模型构建,将文化资源密集区的微博内容体现的话题分为古刹祈福主题、徒步观景主题、古村度假主题、自驾休闲主题和民俗感悟主题,每个主题下面的贡献值较高的关键词,可以较好地反映该主题的特征。
2) 每个主题空间分布差异较为明显。古刹祈福主题主要集中分布于雁翅镇和潭柘寺镇。徒步观景主题分布相对较为分散,主要集中于清水镇。古村度假主题分布东西部地区差异较为明显,集中分布在中西部的村镇。自驾休闲主题多分布于主干道和交通设施便利的地区,交通依赖程度较高。民俗感悟主题分布较为广泛,在多个村镇均有较好的体现。
3) 热点位置对多个主题有较好的呼应。利用GIS渔网分析工具,将每个文化资源密集区主题相对数量的微博位置清晰展现,多个主题的热点位置均能较好地体现出主题的空间特征,文化资源密集区的空间结构对文化遗产感知具有重要的影响。
3.2讨论
由于微博文本具有内容短小、噪音大的特点,此方面的大数据处理方法还在研究阶段,未形成权威的解决方案,本文虽然利用机器学习对微博文本是否和文化遗产感知有关进行了研究,但对如何提升分类精度有待进一步加强。另外,LDA模型中主题的个数确定依然是经验值,需要多次反复试验,根据经验选取,主观因素较大。同时,微博内容位置与实际位置存在脱离现象,或是存在打卡地点偏离等问题,也导致部分讨论的文化遗产感知的结果回归到图上后空间特征并不明显,在下一步的研究中,要加强对微博数据本身特点的进一步分析,在技术上寻求更好的解决方案,为文化遗产保护传承利用的相关研究提供更加有效的技术支持,促进文化
资源密集区更好的保护与传承。
[参考文献]
[1]习近平.决胜全面建成小康社会夺取新时代中国特色社会主义伟大胜利——在中国共产党第十九次全国代表大会上的报告[EB/OL].(2017-10-27)[2019-03-01].http://www.xinhuanet.com/2017-10/27/c_1121867529.htm.
[2]罗绍明.贵州文化遗产资源保护与旅游发展[J].中国发展,2018,18(4):33-37.
[3]黄年红,尹燕,卢勇,等.江苏文化遗产旅游开发研究[J].农村经济与科技,2013,24(12):86-89+59.
[4]杜忠潮.陕西关中地区帝陵遗产资源保护与旅游开发研究[J].咸阳师范学院学报,2011,26(6):54-62.
[5]张妍,张婕.基于天津非物质文化遗产活态传承下的传统手工艺生产性保护研究[J].包装工程,2019,40(4):192-196.
[6]陈永辉,白晋湘.非物质文化遗产保护视角下我国少数民族民俗体育文化资源开发[J].武汉体育学院学报,2009,43(3):75-80.
[7]李广宏,梁敏华.桂林戏曲非物质文化遗产旅游数字化开发研究[J].河北旅游职业学院学报,2018,23(4):28-32.
[8]薛璐瑶,张璐,唐嘉闻.非物质文化遗产的新媒体传播研究——以内蒙古呼和浩特市 “和林格尔剪纸”为例[J].新媒体研究,2019,5(1):42-44+55.
[9]卢松,吴霞.古村落旅游地写生游客满意度评价——以黟县宏村为例[J].地理研究,2017,36(8):1570-1582.
[10]张嫄媛,单文君.基于游客感知的杭州西湖景区智慧旅游公共服务体系优化研究[J].时代经贸,2018(6):56-58.
[11]张琪.嵩山少林寺游客旅游动机研究[J].河南工程学院学报(社会科学版),2015,30(2):22-27.
[12]卢松,张捷,苏勤.旅游地居民对旅游影响感知与态度的历时性分析——以世界文化遗产西递景区为例[J].地理研究,2009,28(2):536-548.
[13]唐晓云,闵庆文,吴忠军.社区型农业文化遗产旅游地居民感知及其影响——以广西桂林龙脊平安寨为例[J].资源科学,2010,32(6):1035-1041.
[14]卢松,张捷,李东和,等.旅游地居民对旅游影响感知和态度的比较——以西递景区与九寨沟景区为例[J].地理学报,2008(6):646-656.
[15]楊敏,李馨怡.基于微博数据分析的西安旅游形象感知研究[J].曲阜师范大学学报(自然科学版),2017,43(1):81-88.
[16]陈晓艳,张子昂,胡小海,等.微博签到大数据中旅游景区客流波动特征分析——以南京市钟山风景名胜区为例[J].经济地理,2018,38(9):206-214.
[17]杨微石,郭旦怀,逯燕玲,等.基于大数据的文化遗产认知分析方法——以北京旧城中轴线为例[J].地理科学进展,2017,36(9):1111-1118.
[18]塔娜,张海.微博旅游营销现状研究——以宏村为例[J].度假旅游,2018(11):204-206.
[19]周佳颖,王俊蓉,张景秋.微博用户的中国传统节日感知及区域差异研究[J].地球信息科学学报,2019,21(1):77-85.
[20]朱海勇,孟斌,张景秋.数字化技术和三山五园文化遗产保护与利用[J].北京联合大学学报,2016,30(1):21-25.
[21]北京市人民政府办公厅. 北京市国民经济和社会发展第十三个五年规划纲要[EB/OL].(2016-03-28)[2019-03-09].http://www.beijing.gov.cn/gongkai/guihua/2841/6590/6600/1700260/1532420/index.html.
[22]SWAMI A, JAIN R. Scikit-learn: machine learning in python[J]. Journal of Machine Learning Research, 2012, 12(10):2825-2830.
[23]杨忆,李建国,葛方振.基于Scikit-Learn的垃圾短信过滤方法实证研究[J].淮北师范大学学报(自然科学版),2016,37(4):39-41.
[24]史琬莹.朴素贝叶斯方法在文本分类中的运用[J].电子技术与软件工程,2018(11):192.
[25]BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J].Journal of Machine Learning Research, 2003(3):993-1022.
[26]邓丹君,姚莉.基于微博标签和LDA的微博主题提取算法[J].计算机与数字工程,2017,45(5):954-957.
[27]宋蕾,张培晶.基于LDA主题建模的微博舆情分析系统研究[J].网络安全技术与应用,2014(4):5-6.
[28]张晨逸,孙建伶,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
[29]谢永俊,彭霞,黃舟,等.基于微博数据的北京市热点区域意象感知[J].地理科学进展,2017,36(9):1099-1110.
[30]张学民,赵明宇.基于LDA和情感分析的西塘古镇旅游形象研究[J/OL].河北工业大学学报(社会科学版):1-9[2019-03-07].https://doi.org/10.14081/j.cnki.cn13-1396/g4.000113.
[31]崔金栋,杜文强,关杨.基于大数据与LDA融合的微博信息推荐方法研究[J].情报科学,2018,36(9):27-31+76.
[32]周娜,李秀霞,高丹.基于LDA主题模型的“作者—内容—方法”多重共现分析——以图书情报学为例[J/OL].情报理论与实践: 1-9[2019-03-07]. http://kns.cnki.net/kcms/detail/11.1762.g3.20190131.1556.004.html.
(责任编辑李亚青)
