基于情感分析算法在笑声音频检测与应用的探索
2019-09-10邹宇骁

摘 要:探索笑声的情感分析算法是有意义的研究。本文介绍了笑声心理特征,笑声识别的基本原理,特征提取、计算模型和数据集情况,提出若干问题及可能的解决方案,并在此基础上探讨了研究应用和发展前景。
关键词:笑声音频检测;情感分析算法;笑情感测量计
引言:笑声情感自动识别是指:根据笑声的音频数据和其他相关信息构建计算模型,实现笑声情感自动判别的过程。笑声情感识别技术涉及多个领域,包括认知科学、心理学、生理学、声学、音频信号处理、自然语言处理和机器学习等,是一个多学科交叉的研究领域。音频信号大致可以分为三类:语音、音乐和环境声音。语音、音乐和环境声音具有显著不同的特性,因而通常分为三种不同的情形进行处理,不同音频类型需要不同的检索和语义分析技术,本文以笑声(语音)的音频特征,探索适应该特征的处理、检索和情感分析技术。
1.笑声分析
1.1笑声的心理分析
笑是人的本能反应,是情绪或者情感变化的一种重要表现形式,笑通常是一种积极快乐的情绪反映,但你遇到高兴的事情时,你会以笑来表现内心的欢快,或者以笑来表达自己快乐和满意的心情。笑通常分为两种:一种是无声的微笑,一种是有声的笑。有声笑根据情绪的高低、快乐的程度分为三种:小笑“XiXiXi(嘻嘻嘻),中笑”kekeke(呵呵呵),大笑“hahaha”(哈哈哈)。三种有声的笑反映人情感的三个维度或者开心的指数,这种情感的维度或者开心指数是可以通过笑音频分析计算出来的。
1.2笑声音频分析
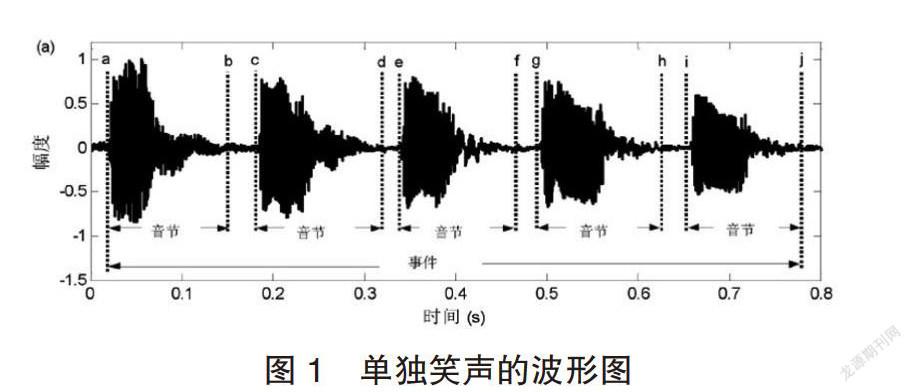
一次完整的笑声过程被称为一个“笑声事件”,构成一次完整笑声的各个相邻信号段被称为一个““音节帧袋”(bag of frames)或“音节”,这两个术语是分析笑声的特性,笑声音节跟语音音节一样,也是由浊音成分和清音成分组成的信号段。笑声事件即一次完整的笑声过程,由相邻的笑声音节构成。例如,一次完整的笑声过程通常标注为“ha haha”、“kekeke”或者“XiXiXi”。笑声事件就是指与标注“hahaha”“kekeke”或者“XiXiXi”对应的波形信号段;笑声音节则是指与某个标注“ha、ke或者xi”对应的波形信号段。单独笑声由相邻的独立笑声音节组成,一般是由一个人发出的,图1给出了一个单独笑声的波形图。
1.3笑声情感识别系统框图
图2为笑声识别系统框图。和语音识别系统一样,建立和应用这一系统可分为两个阶段:训练阶段和识别阶段。在训练阶段,系统的每个使用者说出若干笑声,系统据此建立每个使用者的模板或模型参量参考集;而在识别阶段,待识别笑者中导出的参量要与训练中的参考参量或模板加以比较,并且根据一定的相似性准则形成判断。
2.笑声情感识别
2.1特征提取
笑声情感识别常用的音频特征是以“音节帧袋”方式提取的,但是这种特征提取方法忽略了笑声的时间结构。然而,笑声随时间呈现的变化,对笑声情感识别来说可能很重要。为了验证时间信息对预测音乐表达的情感的重要性,可以将笑声变成一个特征向量时间序列。用生成式模型(向量空间模型、马尔可夫和隐马尔可夫模型)来表示该时间序列(这些模型都基于特征向量量化结果),通过使用概率乘积核,将生成式模型用于情感区分任务,这样时间信息利用后,情感预测性能得到提高。
2.2笑声情感模式的选择
笑声情感表示是情感心理学研究的一个新课题.相关研究不多,但已经有多种方案音乐情感识别和人语言情感识别的方法可供研究人员来选择。从情感识别的角度看,情感空间可以用离散类别模型或连续维度模型来表示,这样情感识别问题就分别对应到机器学习的分类问题或回归问題。
对比其他情感识别方法,笑声情感模型使用的是通用连续维度情感模型,因为通用连续维度模型将人类情感状态表示为二维或三维连续空间中的点。这种维度模型的优点在于,它可以描述和刻画情感状态的细微差别,描述笑声情感时更准确、更细致,与人的笑情感体验更一致。
被广泛采用的通用连续维度模型是环形(circomlex)模型(也称为VA模型)和PAD模型。环形情感模型认为情感状态是分布在一个包含效价度(快乐基调程度)(valence)和激活度(arouala)的二维环形空间上的点(参见图1).其中纵轴表示激活度,横轴表示效价度。
针对笑声识别以及检测问题,近些年来已有一些人员在不同的方面进行了相关研究。Gouzhen An等考虑到笑声波形结构,提出类基于音节的笑声检测方法。该实验首先以帧为单位,提取上述常用特征并使用SVM分类算法得到最初的每帧的分类结果。然后再基于韵律特征对数据进行音节划分对再对上述基线系统的分类结果进行重新打分以得到优化的结果。该方法充分考虑了笑声的结构特征,即每个笑声事件均由数个相邻的音节组成,使得笑声识别系统的性能有了明显的提升。
2.3笑声情感高斯模型
每个人笑声对情感标注经常是有所不同的,他们为概率分布,声音情感高斯(Acoustic Emotion Gaussians,AEG)模型较好的解决了这一问题,AEG模型的一个好处就是便于针对具体用户构建个性化情感识别模型,采用AEG模型来为VA笑声情感识别建模,并且提出一个基于线性回归的调整方法来对一般模型进行个性化调整。
3.基于笑声音频算法的实验设计
3.1算法选择
搜索了文献发现,目前尚无针对单个笑事件的笑声音频算法,多数笑情感算法是在连续语音中的笑声检测,或者在环境声音笑声检测,但这些算法给我们提供了有意义的参考。
本研究以单个笑事件的笑声音频“音节帧袋”的连续性情感模型和笑声情感高斯模型为特征,应用极限学习机(ELM)算法实现笑事件的笑声检测。
3.2ELM算法特点
ELM是一种新型神经网络算法,它的特点是简单易用、有效的单隐层前馈神经网络SLFNs学习算法,相比传统神经网络,需要人为设置大量的网络训练参数,并且很容易产生局部最优解的缺点。ELM的训练速度非常快,需要人工干扰较少,对于异质的数据集其泛化能力很强。对于单隐层神经网络,ELM可以随机初始化输入的权重以及偏置从而得到相应的输出权重,在算法执行过程中不需要调整网络的输入权值以及隐元的偏置,并且产生唯一的最优解,因此具有学习速度快且泛化性能好的优点。
4.应用
笑情感识别研究的最终目的创造一种人“笑情感测量计”,因为笑可以给人类带来智慧和力量,有助人的身体健康和控制情绪的作用,有一个“笑情感测量计”就像一个温度计一样时时刻刻可以客观评价人的情感维度和开心指数。开心的情绪和情绪的控制对于我们每个人的健康生活,预防和治疗疾病,幸福感;对于我们和谐家庭的夫妻关系、亲子关系;对于我们工作的人际关系等等方面都将起到意想不到的作用。特别是它可以将每时每刻,每分每秒,每日每月,每年的“笑情感”记录、分析和总结,这样大大地提高人机互动的效果。
研究工作展望:人类的笑情绪表现主要有三种:笑声表情、面部笑表情和身体笑姿态表情。身体笑姿态表情(如手势、运动姿势)变化的规律性难以获取,因而笑情感识别的研究目前主要侧重于笑声情绪和面部笑表情的识别。对笑声情绪的识别,通常被称为“笑声情感识别”;对面部表情的识别,通常被称为“人脸笑表情识别”。尽管从笑声情感获取的音频信息和面部笑表情获取的视觉信息在进行情感识别时所起的作用都很大,但这二者各有自己的优缺点,也有着某种程度的互补作用。为了在言语情感和面部表情之间取长补短,因而未来有必要将笑声情感识别技术和人脸笑表情识别技术融合在一起,以便对人类笑情感的类别进行更有效地判定。这就是所谓的“多模态笑情感识别”,即同时融合多种表情(如言语表情和面部表情)的情感识别,形成一种全方位的人笑情感测量计。
参考文献
[1]孔维民.情感心理学新论[M].长春:吉林人民出版社,2002.
[2]詹姆斯.萨利.笑得研究-笑得笑声、起源、发展和价值[M].北京:中国社会科学出版社,2011.
[3]徐利强,谢湘,黄石磊,李通.连续语音中的笑声检测研究与实现[J].声学技术,2016,35(s6):581-584
[4]孙守迁,王鑫,刘涛,等.音乐情感的语言值计算模型研究[J].北京邮电大学学报,2006,29(s2):34-41
[5]陈晓鸥,杨德顺音乐情感识别研究进展[J].复旦学报(自然科学版) 2017,56(s2):138—142
[6]邹宇骁(2001--),男,湖南郴州市人,郴州市第一中学
