利用VGGnet对印章印文分类识别的适用条件研究*
2019-09-04郝红光韩星周
张 倩 ,郝红光 ,韩星周
(1.中国人民公安大学,北京 100038;2.公安部物证鉴定中心,北京 100038)
0 引 言
印章印文的检验在文件检验工作中占较大比例,面对检验鉴定的工作量日益增长,盖印条件、样本提取质量多样化等情况,在大数据时代中,利用计算机作为辅助检验方法进行印章印文自动识别是当前学术研究的热点。卷积神经网络作为一种出色的识别工具,具备优秀的自主学习能力和适应性,使得利用卷积神经网络对印章印文自动识别成为可能。
1 卷积神经网络
卷积神经网络能够对大量图像数据集进行学习并自动提取特征进行图像分类识别。目前已在文本情感分析[1]、人脸识别[2]、图像检索[3]、字符识别[4]、笔迹识别[5]等领域中得到应用。如Ling Ding通过比对多种分类识别方法的实验结果,发现卷积神经网络对遥感影像的分类准确率最高[6]。R Almodfer等采用卷积神经网络对阿拉伯语手写单词进行识别,获得了90%以上的精确度[7]。Cui W等证明了卷积神经网络应用在离线签名笔迹检验中的可行性,分类的平均准确率达到99.77%[8]。SG Lee等探究卷积神经网络在韩文字符分类识别中的可行性,平均分类成功率高达90.12%[9]。在计算机软硬件不断发展的推动下,基于前人的开发研究,使得利用卷积神经网络作为印文的分类识别方法成为可能。
在各类卷积神经网络模型中,VGGnet以优秀的适应能力和学习能力在2014年Imagenet比赛的分类识别中获得第二名。较多的卷积神经网络模型均以VGGnet作为基础模型应用于图片检测等任务中,因此本文选取VGGnet作为实验模型进行印文的分类识别检验。该模型主要有三大部分,分别是卷积层、池化层和全连接层。在卷积层中对输入的印章印文图像进行矩阵运算,主要目的是对印章印文的特征进行逐层学习;池化层主要负责对卷积层中输出的特征值进行降维处理,在整幅图像像素中强化印文图像的特征值。全连接层主要对前面步骤中提取的特征值进行分类运算,完成分类结果的输出。
2 实验设计
2.1 实验目的
为了更好的利用卷积神经网络进行印章印文自动识别,以实验的消耗时间、损失值、识别准确率作为评价指标,探究印文分类识别的适用条件,如样本量大小、迭代次数、学习率对识别准确率的影响。
评价指标中消耗时间是指网络开始运行到最终输出准确率所需要的时间。网络模型自主学习得出的分类特征值和真实样本的特征值之间的差值即为损失值,损失值减小表示学习有效,越小的损失值表示模型正确分类能力越强、检验结果越准确。准确率作为一种十分直观的优劣指标,代表正确分类样本数与所有样本数的比值。
训练样本量越大网络学习的特征越多得到模型的识别能力越强,但制作海量的数据库消耗的工程大且耗时长,在保障较优的准确率前提下探究合适大小的样本数据库将为实际应用研究提供参考。迭代次数是指模型学习完所有样本的总次数,随着迭代次数适度的增加检测的误差会逐渐减小同时也会导致训练时长增多。学习率是指学习过程的步长,影响训练过程的快慢。学习率过小会使得模型参数值更新少、训练时间长、损失值下降缓慢,学习率过大则会导致网络只学习印文的局部特征,使得模型对测试样本的适应性较差。因此选择合适的迭代次数和学习率是保证训练的稳定性和合理高速率的关键因素之一。
2.2 实验条件与样本设计
(1)实验所用的计算机配置为Windows 10操作系统,CPU类型为第六代智能英特尔酷睿i7四核处理器、运行速度为3.4 GHz。内存最大支持容量为16 GB,独立6GB的 GTX 1060显卡。配置希捷7 200 转/分机械硬盘。
(2)选取章面内容相同的固态光敏印章、塑胶印章、铜章各一枚,其中塑胶印章和铜章分别以印泥、印油为盖印介质,均以十张A4复印纸为衬垫物,在压力适中条件下盖印完整的印文样本。
(3)使用1 200万像素的相机以10 cm物距分别单个拍照,提取印文图像作为训练和测试的印文数据集。
(4)训练、测试样本数据集分别设置如下:
①固态光敏印章盖印7 000枚印文作为训练样本、1 000枚印文作为测试样本;②塑胶章蘸取印泥、印油分别盖印3 500枚印文作为训练样本,印泥、印油印文各500枚作为测试样本;③铜章蘸取印泥、印油分别盖印3 500枚印文作为训练样本,印泥、印油印文各500枚作为测试样本。以上3组印文按照1:1:1等比设置6种不同大小的训练样本数据集依次为:21 000、18 000、15 000、12 000、9 000、6 000;测试样本数据集依次为:3 000、1 500、300、150。
(5)将待输入的印章印文样本图像像素全部统一为224×224大小,采用初始的RGB三通道作为输入源数据。计算机随机读取提供的印文样本图像,进行批量学习,为了弱化较强的特征数值对实验效果的影响,网络模型将每个样本图像像素减去所有样本的像素均值,完成样本图像数据的前处理操作。
3 实验结果与分析
3.1 样本量对印章印文分类识别的影响
设置学习率为一般推荐值0.001、迭代次数为10次,改变训练和测试样本量的大小,依次进行试验将得到的准确率、损失值、消耗时间汇总如表1所示。

表1 不同样本量的实验数据汇总
从表1可见,随着训练样本量的增加检验准确率逐渐递增、损失值下降,同时消耗时间增多;测试样本量的变化对准确率影响不明显。以15 000枚印文样本进行训练,对300枚印文进行测试得到准确率为99%,损失值为0.0144;以18 000枚印文样本训练时,测试准确率提升为100%,损失值降低至0.000 2;以21 000枚印文样本作为训练集时准确率保持为100%但消耗时间最多。考虑到制作样本的工程量和检验耗时长短,综合比较得出选取18 000枚印文作为训练样本,对300枚印文进行分类识别的效果最好。
3.2 迭代次数对印章印文分类识别的影响
基于上述实验结果,选取18 000枚印文作为训练数据集和300枚印文作为测试数据集,学习率设置为0.001。改变迭代次数,分别设置5次、10次、15次、20次共四组,试验得到的准确率、损失值、消耗时间如表2所示。

表2 不同迭代次数的实验数据汇总
从表2中得出,随着迭代次数的增多,准确率得到提升至饱和。迭代次数进一步增多准确率反而降低,迭代次数越多消耗时间越长。与迭代5次的结果相比,迭代10次的测试准确率提升为100%,损失值降低至0.000 2,迭代15次的测试准确率为100%但耗时增长。迭代次数适度的提升能优化识别的准确率和损失值,在保证一定准确率的前提下选择耗时适中的10次迭代条件最为合适。
3.3 学习率对印章印文分类识别的影响
基于上述实验结果,选取18 000枚印文样本作为训练集和300枚印文样本作为测试集,迭代次数设置为10次。依次递减改变学习率为0.1、0.01、0.001、0.000 1,实验数据汇总如表3所示。
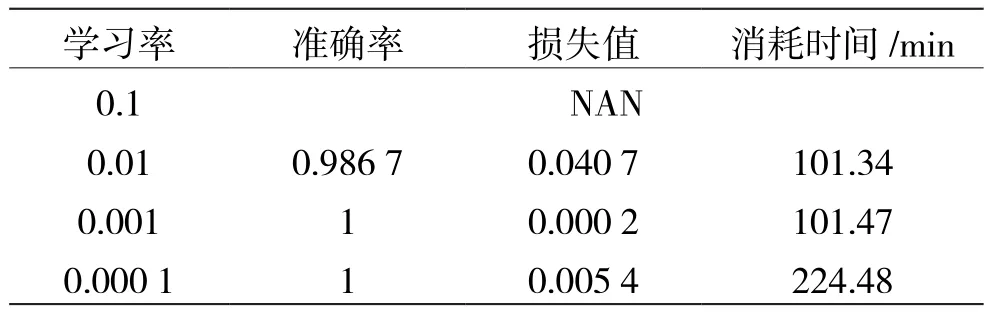
表3 不同学习率的实验数据汇总
从表3中得出,学习率降低准确率会得到提升,同时消耗时间增大。在0.1的学习率下无准确率输出,损失值的输出变为“NAN”表示学习失败;学习率降低为0.01时训练恢复正常,得到98.67%的准确率;在0.001的学习率下准确率提升到100%,损失值缩减至0.000 2,再次降低学习率的结果优化不明显且耗时增大。
网络模型通过每层的误差梯度来决定更新模型参数的大小,学习率增大使得网络参数大幅度更新而不稳定最终会导致学习失败,适当的降低学习率能缓解该问题,但同时增大了训练耗时。选取0.001的学习率能取得100%的准确率且消耗时间较为适中,为实验适用条件。
4 结 语
实验结果表明在0.001学习率、迭代10次、以18 000枚印文作为训练样本的条件下,训练得到的VGGnet模型对300枚印文进行检测,能得到100%的准确率且损失值小。证明了借助卷积神经网络VGGnet作为辅助手段对印章印文分类识别具备可行性。
