基于改进PSO-SVM算法的帕金森疾病诊断研究*
2019-09-03丁卫平余利国
张 琼 丁卫平 景 炜 余利国
(南通大学计算机科学与技术学院 南通 226019)
1 引言
据国家卫生局不完全统计,帕金森疾病已成为继肿瘤、心脑血管疾病之后影响中老年人健康的第三大高危疾病,且患病人数比例正逐年增加。帕金森疾病[1]是由于中脑黑质多巴胺神经元的死亡,纹状体DA含量显著性减少以及黑质残存神经元胞质内出现嗜酸性包涵体导致的一种神经性系统疾病。目前,根据中国帕金森疾病的诊断标准[2],这类疾病的诊断方法主要包括以下几类:传统方法是医生直接通过判断病人临床表现出的静止性震颤[3]、运动迟缓、肌强直[4]和姿势步态障碍[5]等特征来得出诊断结果。但由于轻症患者初期临床表现不明显,医生仅通过行为特性不能够作出准确的判断,容易导致漏诊、误诊的发生。为了提高诊断的精准度,现阶段医院采用影像技术[6]来作为医生诊断的辅助手段。影像诊断技术主要通过脑血流、神经递质、转运体、黑质回声改变的影像来辨别病人是否患病。虽然影像技术提高了帕金森疾病的诊断精准度,但是却带来了高昂的医疗成本。随着机器学习[7]的发展,研究者们针对以上传统诊断方法出现的问题,提出了一种将计算机技术与医疗数据相结合的分析方法,来提高帕金森疾病的诊断正确率以及降低医疗成本。如雷少正等[8]针对医生诊断效率不高的问题,提出了基于主成分分析的帕金森量表优化算法来诊断帕金森病。该算法采用主成分分析方法减少大量交叉重复的量表,再通过支持向量机来进行分类,以此提高医生的诊断效率。但是此方法只对医生初次诊断帕金森病有帮助,如果想更详细地确定症状的轻重,则需要采用传统的量表方法。如李勇明等[9]提出了基于语音样本重复剪辑和随机森林的帕金森病诊断算法研究。该算法对剪辑优化后的样本采用随机森林算法对帕金森数据样本进行分类诊断,达到了较好的分类准确度,但该方法语音特征较多,效率低下。如王金甲等[10]提出的一种基于深度卷积神经网络的帕金森步态识别方法,通过捕捉行动人的步态信息,经过深度卷积神经网络,来匹配帕金森患者信息,但由于人的形体姿势多样,存在较大的噪声干扰。
针对上述问题,本文则提出一种基于改进的PSO-SVM算法,将该算法应用在帕金森疾病中,并与 GA-SVM[11]算法和 PSO-SVM[12]算法在帕金森数据上的结果进行对比,证明IMPSO-SVM算法能对帕金森疾病进行快速有效地判断,提高了医生对帕金森疾病的诊断准确性,降低误判的发生。
2 PSO-SVM算法介绍
粒子群优化的支持向量机算法是通过粒子群优化算法[13]对支持向量机[14]参数进行优化并寻得最优组合的过程。该算法描述如下:对于给定的N个种群,在M维度的探索空间里,其中第i(i∈N)i个种群中粒子的坐标为 Xi=(xi1,xi2,…,xim),移动的速度为 Vi=(vi1,vi2,…,vim),个体的极值为 Pi=(pi1,pi2,…,pim),全局的极值为 Pg=(pg1,pg2,…,pgm),则粒子的速度计算公式如下:
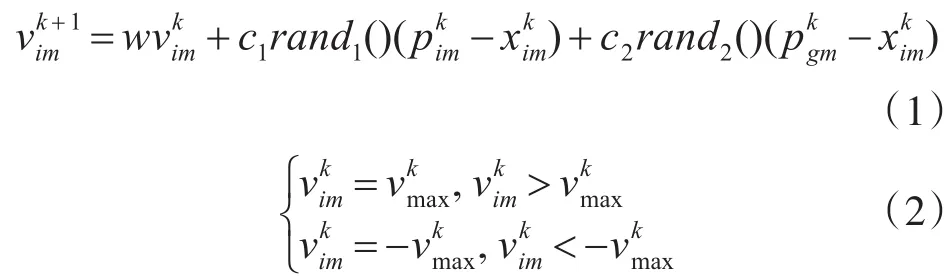
其中,w为惯性权重,在传统的粒子群优化算法中是固定不变的,k为当前迭代次数,c1和c2是学习因子,pgm代表整个种群中全局最优位置,pim代表着当前粒子的最佳位置,在两个不同的 pgm之间,局部粒子的最佳位置会随着全局最优位置来进行改变。类似的,在当前不同的位置 pim之间,全局位置的粒子也随着当前种群的最佳位置改变而改变。当前粒子的位置被调整通过下面的公式:

将优化后寻得的局部最优解和全局最优解作为支持向量机的核函数,惩罚系数,代入到支持向量机的目标函数中:

3 改进的PSO-SVM对帕金森疾病诊断研究
3.1 改进PSO-SVM算法(IMPSO-SVM)
针对上述粒子群优化的支持向量机算法中式(1)的惯性权重w和学习因子c1和c2都是人凭借主观经验来设定的,而根据不同的数据集,数据之间的多样性,不可能每次的参数都是最优的,并且不当的参数容易导致粒子群优化算法对支持向量机优化过程中粒子过早成熟陷入局部最优解的问题。因此本文提出的改进算法是通过改变粒子的惯性权重和学习因子来提高算法的性能。
本文的主要改进思想是对不同性能的粒子分配不同的惯性权重,对性能较好的粒子采用较大的惯性权值,让其主要负责更优区域的探索,不断更新 pg,来探索全局中最优的解;而对性能较差的粒子则采用较小的惯性权值,让其迅速收敛致局部最优解附近。该改进算法的具体做法是:将粒子按其个体最优位置从最优到劣进行排序,其中排在第i位粒子的惯性权重及相应学习因子的表达式如下:

其中,wmax和wmin分别为预定义的最大与最小惯性权重,m为种群规模,学习因子c1i和c2i根据惯性权重wi动态的调整。该方法可以在每一步进化中都较好地平衡全局与局部探索能力。通过把优化后的局部最优位置和全局最优位置来作为最优的惩罚系数C和核函数γ,并通过适应度来评价粒子的性能,适应度越高代表粒子探索能力越强。适应度函数如下所示:

其中accurary是支持向量机的预测模型精度,是通过对训练数据,训练标签进行建模,其中交互验证模式的系数为3,惩罚系数为,核函数为。
因此改进后的粒子群速度计算公式如下所示:

其中 wi和 c1i,c2i分别如式(5)和式(6)表示。
3.2 IMPSO-SVM对帕金森疾病诊断步骤
随机将帕金森数据的三分之二分为训练数据集Train,三分之一的分为测试数据集Test。
输出:预测的精确度,算法的执行时间。
Step1:根据min-max标准化对Train和Test数据进行归一化处理,并标记为训练集和测试集;
Step2:初始化粒子群算法的位置和速度;
Step3:根据式(7)计算粒子群算法的适应度函数值;
Step4:通过式(5)和式(6)来对每个帕金森粒子的惯性权重和学习因子进行改进;
Step5:当获得满足的优化条件或达到最大迭代次数时,终止该过程,得出惩罚系数C和核函数γ的最优解,执行Step7,否则执行Step6;
Step6:更新当前粒子的速度和位置,跳转到Step3,重新计算适应度值;
Step8:将Step1中的训练数据集D1和支持向量机最优参数组合,构建支持向量机模型;
Step9:通过支持向量机模型预测测试数据集D2的预测精度;
下面是该算法的详细流程图:
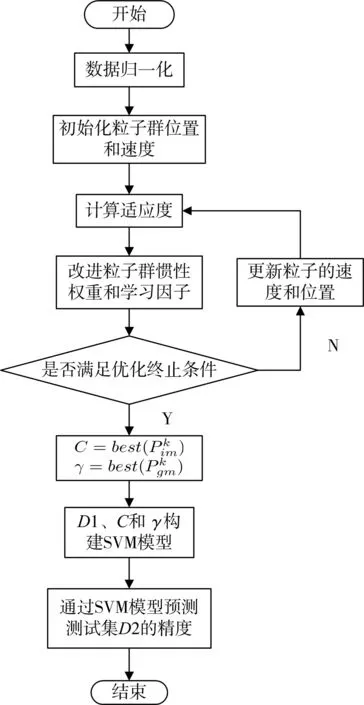
图1 IMPSO-SVM算法流程图
4 IMPSO-SVM在帕金森数据的实验结果与分析
4.1 帕金森数据介绍
本文所使用的数据是由 Little[15~16]等提供的一组帕金森疾病语音数据集,是通过观察帕金森患者的语音临床表现特征提取而来。该数据获取了31个人的195份语音样本并从中提取23个语音特征,其中23人为帕金森患者,8人为健康患者。如表1详细地描述了帕金森数据的数据属性。
4.2 实验对比与分析
为了证明IMPSO-SVM算法能更好地识别帕金森病的效果,本文引入了两种经典机器学习算法作为对照实验:一种是采用原始的粒子群优化的支持向量机(PSO-SVM),另一种是采用遗传算法优化的支持向量机(GA-SVM)。将这三种算法分别的运用在帕金森数据上,实验结果如图2所示。

表1 提取的主要语音特征及描述

图2 三种算法对帕金森数据的平均适应度图
适应度的大小决定了群体内基因型机体存活并将其基因传递至下一代的相对能力。适应度越大,存活和生殖机会也就越高,越不容易过早的成熟。由图2可知,改进算法的平均适应度值整体优于另外两种对比算法的平均适应度值,表明改进算法在帕金森数据中,粒子繁殖能力更强,越不容易成熟收敛。

图3 三种算法对帕金森数据的最佳适应度图
最佳适应度值表示在粒子群优化过程中,得出的最佳粒子的适应度值。最佳适应度值越高代表对支持向量机参数优化的效果越好,越有利于支持向量机对帕金森数据做出准确的预测。如图3所示,IMPSO-SVM算法在一开始时就表现出很强的探索能力,经过数次进化后,明显地高于另外两组算法,表明该改进算法对帕金森数据的预测值更加准确。通过表2,可以看出三种算法在帕金森数据上的性能优劣。

表2 三种算法对帕金森数据集的实验结果对比
通过不同的试验方法在对帕金森数据的应用中可以看出,在预测精确度上,IMPSO-SVM相比PSO-SVM高出13.51%,比GA-SVM高出10.81%;在执行效率上,IMPSO-SVM相比PSO-SVM节省了1.67s,比GA-SVM节省了1.81s。出现这种实验结果的原因是由于对性能较好的粒子分配较大的惯性权重,有利于探索出全局最优解,避免了过早成熟,提高了支持向量机的准确度;对性能较差的粒子分配较小的惯性权重,使其快速收敛到局部最优解,节省了优化时间,提高了算法的执行效率。
5 结语
帕金森疾病在中老年人群中的比例正逐年增加,对患者及家庭造成了严重的影响。如何做到早发现早治疗,对患者的康复起到关键性的的作用。而本文则针对目前医生对帕金森疾病诊断出现的误诊、漏诊等问题,提出了一种基于改进的PSO-SVM算法对帕金森疾病诊断,用以提高对帕金森疾病的准确识别精度。该算法对不同性能的粒子动态分配惯性权重和学习因子,来提高支持向量机模型的学习能力和泛化能力。并通过实验表明,IMPSO-SVM算法在对帕金森疾病诊断方面,与另外两组算法相比,无论在预测精度,还是在执行效率上都有了很大提高,证明IMPSO-SVM算法可作为辅助医生诊断帕金森疾病的有效方法。由于帕金森临床数据表现多样,而本文只是针对帕金森语音临床数据进行的分析,为进一步提高帕金森诊断精确,下一步将针对帕金森综合临床数据来进行诊断研究。
