一种基于稀疏分段的协同过滤推荐算法
2019-09-02贺怀清计瑜惠康华刘浩翰
贺怀清 计瑜 惠康华 刘浩翰
摘 要: 针对数据强稀疏性严重制约协同过滤算法推荐准确性的问题,提出基于稀疏分段的改进方法。首先利用基于迭代预测的支持向量回归在解决小样本高维数据中的优势,对稀疏的[U?I]矩阵中相对弱稀疏的密集数据部分预测缺失评分,然后使用基于项目的插补协同过滤方法预测剩余数据的缺失评分。在多个公开数据集中的实验表明,该方法适用于强稀疏数据集的推荐,与基于项目协同过滤比较可取得较好的预测结果。
关键词: 稀疏分段; 支持向量回归; 基于项目的推荐; 协同过滤; 数据稀疏性; 小样本
中图分类号: TN911.1?34 文献标识码: A 文章编号: 1004?373X(2019)09?0090?05
A collaborative filtering recommendation method based on sparseness segmentation
HE Huaiqing, JI Yu, HUI Kanghua, LIU Haohan
(College of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China)
Abstract: Since the strong sparsity of data seriously affects the recommendation accuracy of collaborative filtering algorithm, an improved method based on sparseness segmentation is put forward. The support vector regression based on iterative prediction is used to estimate the missing scores for the relatively?weak sparse density data of sparse [U?I] matrix, which has the advantage in predicting the high?dimensional small?sample data. The item?based imputative collaborative filtering method is employed to predict the missing scores of residue data. The experimental results of several public datasets show that the method is suitable for the recommendation of strong?sparse dataset, and can obtain better prediction results than the item?based collaborative filtering method.
Keywords: sparseness segmentation; support vector regression; item?based recommendation; collaborative filtering; data sparsity; small sample
0 引 言
协同过滤[1](Collaborative Filtering,CF)是应用最为广泛的推荐算法,其主要思想是同样兴趣的用户拥有相同偏好的概率更高,据此建立[U?I]矩阵预测用户对未接触过物品的兴趣度,为其推荐依兴趣度排序的物品列表。以往研究表明,预测误差的微小改进也会显著提高推荐的准确率[2]。而数据的强稀疏性是导致算法预测误差过大的重要因素[3],因此许多研究者都在致力于解决这个问题,目前典型的方法有以下幾种:
1) 文献[4]提出快速插补CF算法。该算法将数据集分割为子集来预测稀疏性大于95%数据的[U?I]矩阵缺失评分,但不同子集之间的预测结果不参与其他部分的计算。
2) 文献[5]提出自适应填补方法。该算法将基于模型和记忆协同过滤结合来预测缺失评分,需根据参数判断自适应使用基于项目的协同过滤(Item?Based Collaborative Filtering,IBCF)还是基于用户的预测。
3) 采用支持向量机(Support Vector Machine,SVM)预测数据,即将有评分数据的二维[用户,电影]数据看作一个有评分标签[user+movie]元素的特征向量[6]。算法利用了SVM对高维数据分类准确性的优点[7],但SVM时间复杂度随数据的增加呈指数增长。
4) 文献[8]提出结合全局和局部的稀疏线性方法。它提取不同行为特征的用户子集对同一项目进行不同的相似度预测,最终取相似度均值。但在全局整合需要自适应权重才能达到更好的效果。
结合上述对数据细化的方式来解决数据稀疏性问题的优点,并针对不同方法存在的局限性,将支持向量回归(Support Vector Regression,SVR)计算精确、IBCF方法速度快和扩展性好的优点结合起来,提出基于稀疏分段的协同过滤方法,以解决数据强稀疏性导致预测准确率偏低的问题。
1 算法描述
检测推荐算法的数据集有MovieLens,ML?latest,EachMovie,Jester,Lastfm[9?10]等,通过分析和以往研究[4?5]发现它们由相对密集部分和稀疏部分组成。本文用[U?I]矩阵缺失值占整个矩阵的比例表示稀疏程度:
文献[4?5]中数据稀疏性强的Movielens在本文中稀疏度为94%。结合上述方法优缺点分析,提出稀疏分段的协同过滤来解决数据稀疏性问题。首先根据数据特点对数据进行强稀疏和弱稀疏的分割,对弱稀疏部分经过填充后输入迭代预测的支持向量回归模型,得到更多的可信评分数据;在下一步使用基于项目的插補协同过滤方法预测剩余缺失值。这样既可以利用支持向量回归在小样本数据上预测精确的优势,又在某种程度上解决数据大量缺失带来的稀疏性问题。
1.1 稀疏分段算法步骤
数据集[U?I]矩阵有[M]个用户,[N]个项目,[u]代表任意用户,[i]代表任意项目。本文基于稀疏分段的协同过滤算法的步骤如下:
1.2 弱稀疏数据的预测
弱稀疏数据的预测步骤如下:
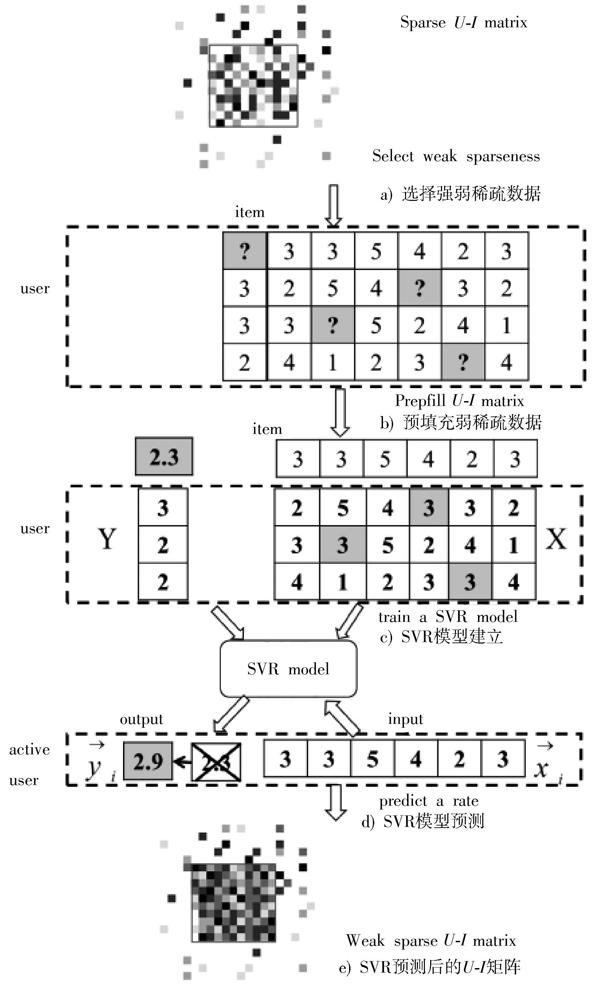
Step1:现实数据集稀疏度往往高于90%,精确的算法也不能在统计意义上有可信的结果。为了突出迭代预测的SVR在高维数据小样本上表现优异的优势,需为数据集选择弱稀疏部分,根据实验需选择缺失评分比例约为60%部分,使训练样本可信度更高,过程如图1a)所示。数据中存在评分多的用户和流行物品,计算用户评分项目数量和项目被评次数,筛选大于一定次数(根据不同数据集实验经验,这个次数表现约为用户总数[110]和项目总数[110])的用户和项目作为样本,降低该数据缺失评分比例。
Step2:对弱稀疏数据部分进行预填充处理,使数据更符合迭代支持向量回归的特性,过程如图1b)所示。对于用户[u],评分项目集合为[Ru],对其未评分项目[i],[Ru,i=0],若在计算中直接将0代入样本,而0在协同过滤中表示用户非常不喜欢[11],若将此先验条件代入计算,则不利于打分习惯的预测。本文中,第一步预测之前需将所有[Ru,i=0]的部分暂改为当前被评分项目的均值参与运算。
Step3:确定特征向量和分类标签。从弱稀疏矩阵第一个项目计算,直到最后一个项目。对项目[i],任一用户[u]的特征向量是当前用户对其他项目的评分构成的特征向量,用[xu=Ru,1,Ru,2,…,Ru,N]来表示,且评分标签[yu]是用户对当前项目的评分[Ru,i]。
Step4:为项目[i]建立SVR模型。在弱稀疏矩阵中用SVR算法模型[12]预测缺失值。若给定训练数据集[T=x1,y1, x2,y2, …,xi,yi,…,xl,yl],[l]为训练样本个数,本文[1≤i≤l],[xi]为特征向量,[yi]为评分标签。需求解的支持向量回归模型函数[12]为:
将Step3弱稀疏矩阵中除当前用户[u]外所有用户的特征向量和标签代入式(2)得到项目[i]的SVR模型,如图1c)建立模型过程中用高斯核函数将向量映射到高维非线性空间。
图1 基于稀疏分段方法的预测过程
Step5:求弱稀疏部分项目[i]的评分预测,过程如图1d)所示。对项目[i]的所有用户评分中,[Ru,i=0]的用户的特征向量为当前用户除当前项目评分外的所有评分,代入模型得到用户[u]的评分标签[yi],计算结果存入[U?I]矩阵。
通过不断迭代Step4,Step5过程,高维非线性曲面空间会不断拟合为符合不同用户的打分习惯的特征空间曲面,由特征空间曲面模型得到的预测评分也更精确。第一步预测结束时,被挑选的数据集弱稀疏部分的缺失评分数据被全部预测完成,效果如图1e)所示。
1.3 强稀疏数据的预测
本文使用IBCF方法预测[U?I]矩阵中剩余缺失值,以往研究也表明在数据稀疏性低于90%的情况下协同过滤算法表现更好[3?4]。
Step1:通过新[U?I]评分数据得到[N×N]的项目间相似度矩阵。在IBCF方法中寻找当前用户打分过的项目集合并计算集合和项目列表之间的相似度,得到[N×N]的相似度矩阵,表示不同项目间的相似程度,取值范围为[-1,1]。选择[k]个最相似项目[{i1,i2,…,ik}]作为[k]近邻[13]。项目[i,j]间相似度[sim(i,j)]通常使用余弦相似度计算,公式[13]为:
式中:[Ru, N]为用户[u]对所有项目的评分;[simi,N]为项目[i]与任意项目的相似度。由项目的相似度和用户打分过的项目评分求内积并归一化得到预测值。使用[k]个最相似项目代替全部[N]个项目来防止最受欢迎项目总纳入计算结果,本文将此方式叫作K?IBCF。
1.4 稀疏分段算法的时间和空间复杂度分析
[D]为数据稀疏度,K?IBCF的时间复杂度为[ONNMD],空间复杂度为[ON2]。本文第一部分未知评分数为[S],[D]为SVR预测后数据稀疏度,时间复杂度为[OS2+NNMD],空间复杂度为[OS+N2]。稀疏分段方法因SVR使用更多时间和空间资源降低预测误差。
2 实验数据与评估
2.1 数据集
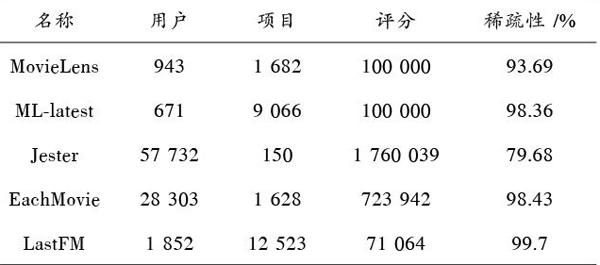
本文选择如下数据集评价实验结果,MovieLens和ML?latest以及EachMovie是电影数据,评分为1~5的离散值。Jester是笑话数据,评分为-10~10的实数,归一化至0~5范围。LastFM是音乐数据,在本文实验过程中把用户听歌次数转为0~5的量化值来预测。对于EachMovie,0值表示不喜欢和未评分,本文去掉未评分信息的不可用数据。
2.2 评估方法
本文使用五折交叉验证来评估提出算法的表现。通过计算预测误差来衡量不同算法的表现,具体需要计算MAE值:
2.3 实验结果和实验分析
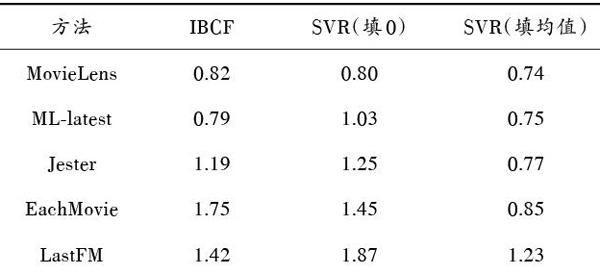
不同数据集弱稀疏数据部分在IBCF和基于稀疏分段的MAE值比较见表1。填均值比填0对SVR的预测影响更大,因0值在迭代的SVR中代表强烈的不喜欢,而在插补的IBCF中使用余弦公式,0不起作用。可验证迭代预测的SVR在弱稀疏数据部分的预测优势,使数据集合理扩充为非强稀疏的数据集,让IBCF算法在下一步预测中更好地应用。
表1 弱稀疏数据上SVR模型优势
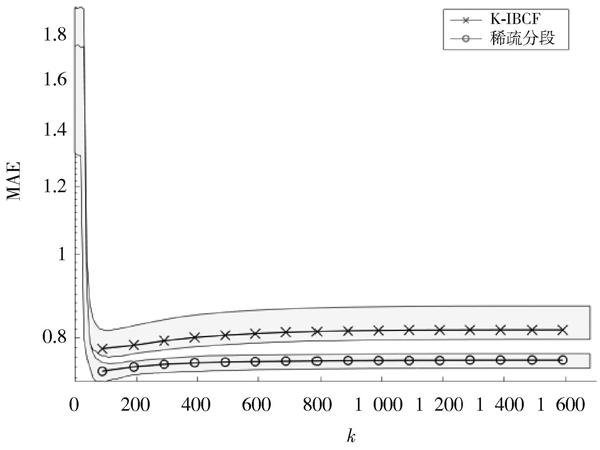
圖2 MovieLens使用[K]?IBCF和稀疏分段方法的MAE值
本文使用五折交叉验证,因此区域部分表示5次不同实验结果的MAE值的范围。区域中的曲线代表MAE平均值。由图2可得,当[k]接近120时MAE值更小,且在不同的[k]近邻下稀疏分段方法都稍好于K?IBCF方法。[k]值逐渐增大,预测误差先减少后呈现增大趋势,因为选取近邻越多越准确,但近邻超出一定程度,必然使得大众普遍喜欢的物品被多次纳入计算,从而误差会出现上升趋势。
本文根据不同数据集的项目数量对近邻[k]进行相应更改,更好地体现算法在[k]值变化时产生的MAE值变动。基于稀疏分段的方法和K?IBCF算法的MAE值对比如表2所示。本文算法在稀疏性非常高时表现更好,通过迭代预测SVR的方式,合理扩展可信数据,避免在数据稀疏性为90%以上导致不同算法都很难支撑统计意义的缺点[14]。当数据稀疏性不是很高时,如表3 Jester特性,缺失评分远低于90%,传统算法依然在预测此类数据集的缺失值方面表现突出。
表2 不同数据集的MAE值
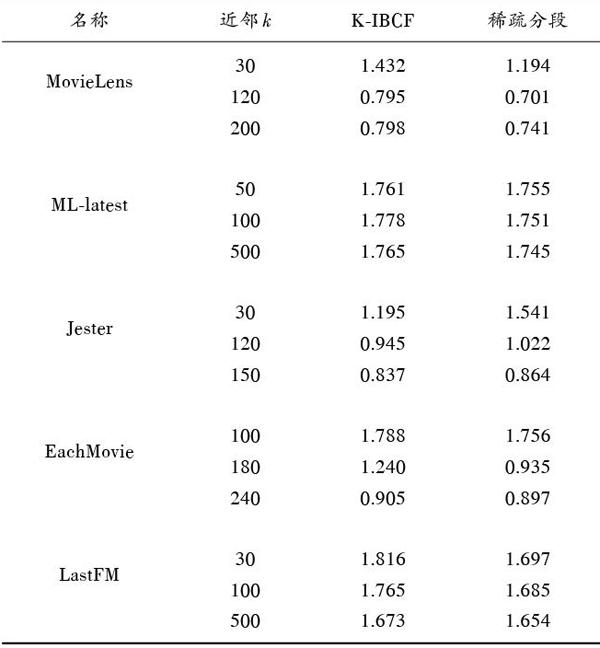
表3 数据集属性
由实验可得,稀疏分段方法在第一步选取的数据集适用于SVR模型,使得SVR在弱稀疏数据集的应用中得到了可信度高的评分。且整个方法没有使用单一相似度的协同过滤,避免将所有用户的打分行为特征都视为同一模型,多次迭代的SVR模型潜在地将用户行为模式、项目特征与评分的匹配模式呈现多元化。稀疏分段方法在发挥SVR和IBCF两个算法优点的同时,还能规避两个算法的缺点,既能提高预测准确性,又能避免全局使用SVR模型过高的时间复杂度。
3 结 语
本文通过将数据稀疏性分为弱稀疏部分和强稀疏部分,从而将预测评分的步骤对应地分为两步,结合SVR模型准确预测的特点对弱稀疏部分预测,利用IBCF算法可扩展性和时间开销小的特点对强稀疏部分进行预测。实验结果证明,本文算法的适用场景为评分信息分布明显不均且有大量缺失的情况,尤其在数据稀疏性大于90%的情况下可以丰富稀疏矩阵的信息。
本文提出的方法在减小数据集预测误差的同时,还存在稍高于传统协同过滤方法时间开销的问题。下一步工作中考虑将每个数据集的预测从评分频率高的数据开始预测起,直到[U?I]矩阵的全局都被逐渐预测结束,或者最大化地利用属性信息,把它们当作新的特征向量来预测评分。
参考文献
[1] EKSTRAND M D, RIEDL J T, KONSTAN J A. Collaborative filtering recommender systems [J]. Foundations and trends in human?computer interaction, 2011, 4(2): 81?173.
[2] KOREN Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas: ACM, 2008: 426?434.
[3] KOREN Y, BELL R. Advances in collaborative filtering [M]// Anon. Recommender systems handbook. US: Springer, 2015: 77?118.
[4] SU X, KHOSHGOFTAAR T M, GREINER R. A mixture imputation?boosted collaborative filter [C]// Proceedings of the 21st International Florida Artificial Intelligence Research Society Conference. Florida: ACM, 2008: 312?317.
[5] REN Y, LI G, ZHANG J, et al. The efficient imputation method for neighborhood?based collaborative filtering [C]// Proceedings of the 21st ACM international conference on Information and knowledge management. [S.l.]: ACM, 2012: 684?693.
[6] SHI Y, LARSON M, HANJALIC A. Collaborative filtering beyond the user?item matrix: a survey of the state of the art and future challenges [J]. ACM computing surveys, 2014, 47(1): 3.
[7] 丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J]. 电子科技大学学报,2011,40(1):2?10.
DING Shifei, QI Bingjuan, TAN Hongyan. An overview on theory and algorithm of support vector machines [J]. Journal of University of Electronic Science and Technology of China, 2011, 40(1): 2?10.
[8] CHRISTAKOPOULOU E, KARYPIS G. Local item?item models for top?n recommendation [C]// Proceedings of the 10th ACM Conference on Recommender Systems. [S.l.]: ACM, 2016: 67?74.
[9] MovieLens. GroupLens datasheet [EB/OL]. [2015?12?15]. https:// grouplens.org/datasets/movielens/.
[10] EachMovie. EachMovie collaborative filtering data set [EB/OL]. [1997?02?16]. http://www.cs.cmu.edu/~lebanon/IR?lab/data.html.
[11] LI Z, PENG J Y, GENG G H, et al. Video recommendation based on multi?modal information and multiple kernel [J]. Multimedia tools and applications, 2015, 74(13): 4599?4616.
[12] CHANG C C, LIN C J. LIBSVM: a library for support vector machines [J]. ACM transactions on intelligent systems and technology, 2011, 2(3): 112?115.
[13] WU X, CHENG B, CHEN J. Collaborative filtering service recommendation based on a novel similarity computation method [J]. IEEE transactions on services computing, 2017, 10(3): 352?365.
[14] HU Y, SHI W, LI H, et al. Mitigating data sparsity using similarity reinforcement?enhanced collaborative filtering [J]. ACM transactions on Internet technology, 2017, 17(3): 1?20.
