面向恶意网址检测的广谱特征选择与评估
2019-09-02张慧钱丽萍汪立东袁辰张婷
张慧 钱丽萍 汪立东 袁辰 张婷

摘 要: 针对恶意网址检测系统的特征选择和降维问题,基于特征选择方法的优化结果提出多种特征子集。利用基于分类器的准确率和召回率等性能评价指标,采用随机森林、贝叶斯网络、J48、随机树机器学习方法,对信息增益、卡方校验、信息增益率、基于Relief值、基于OneR分类器、基于关联性规则、基于相关性等多种特征选择算法所确定的特征子集进行检测。结果表明,除基于相关性特征选择算法确定的特征子集外,其他方法确定的特征子集均具有良好的分类性能,其中基于关联性规则选择的特征子集的维度仅为5,但各分类器基于此特征子集的分类准确率均高达99%以上。
关键词: 网络安全; 恶意网址检测; 特征提取; 特征选择; 特征子集; 信息安全
中图分类号: TN915.08?34; TP391 文献标识码: A 文章编号: 1004?373X(2019)09?0060?05
Broad?spectrum feature selection and evaluation for malicious URLs detection
ZHANG Hui, QIAN Liping, WANG Lidong, YUAN Chen, ZHANG Ting
(College of Electrical and Information Engineering, Beijing University of Civil Engineering and Architecture, Beijing 100044, China)
Abstract: The multiple feature subsets are proposed based on the optimization results of feature selection method to solve the problems of feature selection and dimension reduction for malicious URLs detection system. The classifier?based performance evaluation indicators such as accuracy rate and recall rate, and machine learning method using random forest, Bayesian network, J48, random tree are used to detect the feature subsets determined by information gain, Chi?square verification, information gain radio, and multi?feature selection algorithms based on Relief value, OneR classifier, correction rule and correction attribute evaluation. The results show that, except the feature subset determined by the algorithm based on correction attribute evaluation, the feature subsets determined by other feature selection algorithms have high classification performance, in which the dimensionality of feature subset determined by the algorithm based on correlation rule is only 5, but the classification accuracy rate of all the classifiers based on this feature subset can reach up to 99%.
Keywords: network security; malicious URL detection; feature extraction; feature selection; feature subset; information security
0 引 言
互联网及其应用快速发展,有力地支撑了社会经济民生的运转。人们在享受互联网便利的同时,也深受网页篡改、网页后门、网页仿冒、驱动开发、网络钓鱼、点击欺诈、僵尸网络(Botnet)、分布式拒绝服务(DDoS)[1]等安全威胁,它们通过欺骗用户访问恶意网址(Uniform Resource Locators,URLs),获取用户的银行账号、密码、身份证号等敏感信息,严重危害到用户的信息财产安全。CNCERT/CC2016年度安全报告显示,360公司攔截钓鱼攻击279.5亿次,被篡改网站8.3万个。2017年上半年,国际反钓鱼工作组(APWG)报告已检测到钓鱼网站共29万余个,瑞星在全球范围内截获5 020万个恶意URLs。
为了保护用户的上网安全,Google Chrome和Windows IE等主流浏览器会采用URL黑名单机制比对用户访问网页URLs,当用户访问黑名单中的URL时会立即停止访问并向用户发出警告。然而黑名单机制只能用于检测已确认的恶意URLs,无法防范最新出现的恶意URLs。为改善此不足,本文提出基于特征提取的检测方法,通过提取网页或者URLs的词汇特征、网页信息特征、主机特征等大量信息,用于提升恶意URLs检测的准确性和时效性。然而,较高维数的特征虽然可以更有效地对问题进行准确描述,但也会不可避免地将大量冗余特征、不相关特征、噪声特征等引入特征空间。不仅降低特征提取的速度,还大大提升了计算复杂度,影响分类器运算效率和分类性能。
本文针对基于特征提取的恶意URLs检测方法面临的高维特征空间特征选择问题,在保证特征可理解性的基础上完成空间降维。首先,通过对大量恶意URLs的经验性观察,总结恶意URLs的共性特征,再结合相关文献,选择30余项相关特征构建初始特征空间。对此特征空间,选取多种特征选择算法对其进行优化,结合多种机器学习方法对筛选得到的特征子集进行检测验证,最终选取适用于多种分类器的最优特征子集结果。
1 相关工作
URLs是网民访问网站的门牌,因此也成为各种网络威胁诱骗网民的重要手段。针对恶意URLs检测方法的研究一直方兴未艾。一部分研究从URLs中的域名(DNS)检测入手,另一部分研究则利用完整URLs。文献[1]使用带语义特征的可逆哈希函数,对被查询的DNS及发起查询的IP进行快速聚类和还原,识别DNS流量中的异常,该方法可用于Botnet,DDoS攻击等异常检测的前期筛选和后期验证。文献[2]利用信号处理技术、功率谱密度(PSD)分析发现僵尸网络周期性DNS查询产生的主要频率,发现主机群的相似恶意行为模型。文献[3]通过挖掘域名里面蕴含的词根、词缀、拼音及缩写特征,实现轻量级的恶意域名检测。
URLs较DNS蕴含有更多的检测可用信息。文献[4]通过提取URLs的词汇特征和主机特征,实现钓鱼网站的分类检测。文献[5]通过提取邮件中URLs的词汇特征和基于主机的特征,基于累积分数判定URL的性质。文献[6]提出结合基于恶意URLs的词汇特征、基于主机的特征、基于域名的特征及在线社会网络特征以提高恶意行为检测效率。
面向高维特征空间,代表性、高贡献率特征子集的选择变得越来越重要。文献[7]采用Fisher分和信息增益降低特征维数。文献[8]结合遗传算法与蚁群算法提升特征选择的速度。文献[9]通过主成分分析方法以及基于关联性的特征选择算法优化评估特征并进行特征选择。
机器学习方法被大量用于恶意URLs检测,性能评估和比较是其中重要的研究内容。文献[10]通过比较发现,J48、SVM、LR三种分类方法中J48检测效果最佳,且检测准确率受phishtank恶意域名与良性域名的比例影响。文献[11]利用决策树、K?近邻、Bayesian、随机森林(RF)、支持向量机(SVM)、多层神经网络(MLP)对采用三种不同特征的恶意URLs数据集进行检测,发现对于同样的数据集,不同特征集的检测结果亦会不同。
2 方 法
2.1 特征提取
对URLs的时间特征、语法特征、结构特征、概率特征等进行概括分析,充分挖掘恶意URLs的相关特征,提高恶意URLs检测的准确率。
1) 时间特征
基于URLs被访问时间戳,统计特定时间片内的通信频度和散度。
2) 语法特征
IETF Request For Comment 1738(RFC1738)规定了URL的形式:
3) 结构特征
URL在结构上大致分为协议、域名、路径、文件名、参数五个主要部分,每个部分都具有相应的规则及习惯性用法。本文考虑多种结构特征,包括从URL总体角度选取的特征:总长度;是否以特殊字符结尾;大写字母数量;数字数量;连续数字的最大长度;连续字母的最大长度;超长字串的最大长度;重复出现的[n]元字串数量和;字符"?",“=”,“&”的数量及关系。从域名角度选取的特征:总长度;级数;最长字串长度;是否包含IP地址。从路径角度选取的特征:是否含有域名;级数;最长级路径占路径长度之比。从文件名角度选取的特征:文件名是否包含两级以上扩展名。
4) 概率特征
主要涉及各类字符的[n]?元组占比,包括:URL中数字字符占比;URL中数字与字母的转换频次;URL中元音与辅音字符比例;URL中元组在负向数据集概率和;URL中元组在正向数据集概率和;域名最长级串占域名比例;域名中不同种类的字符所占域名比例;域名中相对安全字符所占比例。
2.2 机器学习方法选取
定义特征映射函数[f:U→F={T,A,P,H}]:对每条URL记录,将其分别映射时间子向量[T={t1,t2,…,tm}]、结构子向量[A={a1,a2,…,an}]、概率子向量[P={p1,p2,…,pr}]和语法子向量[H={h1,h2,…,hq}]。采用有监督学习方法实验评估,记录标志位为[L],每条输入数据的结构为[V={F,L}={vii=0,…,m+n+r+q}]。
各类机器学习方法在网络安全事件检测中已有大量研究,主流方法包括J48决策树、RF、贝叶斯、朴素贝叶斯、支持向量机(SVM)等。J48决策树采用自上而下的递归分治策略,从根节点随特征逐个加入从而递归产生分支。RF基于多决策树实现,通过随机选取数据集和特征集构建多个决策树,以多决策树的投票结果确定分类。随机树(RT)通过随机选取[n]个特征,并计算信息增益,选择信息增益最大的节点为分裂节点,重复此过程完成树的构造和分类。Bayes网络基于概率推理,通过计算某对象的先验概率和似然计算该对象的后验概率即归属类别。
2.3 特征选择
特征选择的主要目的是从一个高维特征空间中遴选一组更小数目、更小失真的特征,以加速分类器的计算。上述时间特征、语法特征、结构特征和概率特征从多角度对URLs的特点进行了表达,这些特征既要足以显著区分恶意URLs与良性URLs,也不可避免地存在不相关或噪声特征。为此对初步遴选的上述特征进一步进行选择以实现特征空间降维。针对本文恶意URLs检测问题,特征选择操作的形式化描述如下:对于数据集[V={F,L}],其中,[F={f1,f2,…,fn}]是[n]个特征,特征选择过程就是从[F]中选择[m]个([m 特征选择算法的方法很多,理想化方法是穷举法,针对[n]个特征的[2n]种组合方式得到的特征子集进行评估,选择最优的特征组合方式。对于多维特征空间,穷举法因其巨大的时间和空间消耗基本不可行。实际应用的特征选择算法总体上可分为过滤式(Filter)、封装式(Wrapper)和嵌入式(Embedded)三大类。因本文初选的特征数量偏多,封装式和嵌入式方法计算复杂度高且依赖分类器,普适性有限,因而选择计算速度更快、更适合大规模数据处理的过滤式方法,包括信息增益(IG)、信息增益率(GR)、卡方校验(CHI)、基于OneR分类器的特征选择(OneR)、基于Relief值的特征选择(Relief)、基于相关性的特征选择(CAE)和基于关联规则的特征选择(CFS)。 3 实验与分析 3.1 数据集 分别选取PhishTank和Alexa中相关数据作为实验用正、负URLs数据集。PhishTank作为一个反钓鱼网站,自2006年建立以来每天都不断地更新大量钓鱼网站数据,本文从其获取大量恶意URLs作为恶意数据集。Alexa包含最详尽的网站排名信息,该排名是基于网站的用户链接数和页面浏览数综合得到的。一般来说,网站的浏览率越大排名越靠前,其网站内所包含的链接被访问的概率以及频次越高,链接所对应网站的安全性也就越高。因此,本文提取Alexa排名靠前的网站,爬取其页面内的URLs记录构成实验用良性URLs数据。 为保证爬取过程的快捷、高效以及数据的完整性,以python为基础,结合BeautifulSoup完成网站内记录的爬取工作,并采用正则表达式过滤,匹配得到符合条件的记录,以确保获取的记录符合URL规范而非页面内资源链接。 对于数据集规模,参照文献[4,12]的实验成果,在尽可能减少特征冲突的情况下,100 000条的数据量可以获得最好的分类结果。本文基于Alexa网站排名和网页爬取,随机选取56 500条记录构成正向URLs數据集,从PhishTank中选取2016年11月—2017年8月的50 042条记录构成负向数据集。 3.2 特征选择 本文面向恶意URLs检测初选了34项相关静态特征,将该特征集记为F1。采用IG,GR,oneR,Relief,CHI,CAE,CFS方法在F1上进行特征选择。 对上述方法的特征选择结果分析发现:IG,OneR,CHI三种方法的前22项特征高度一致,尤其是IG和CHI两种方法的评估结果只存在细微差异,本文选择此特征子集作为特征选择的结果之一,记为F2。同时以22为特征空间维度,选取GR选择的前22项构成特征子集F3,Relief选择的前22项构成特征子集F4,CAE选择的前22项构成特征子集F5。 进一步的检测实验结果发现:特征子集F2,F3,F4均产生了良好的检测结果,取其公共特征构成维度更低的特征子集F6。同时考虑到生成F2~?F5特征子集时,各算法在评估时均是基于单变量的评估准则,未考虑到多变量特征间可能存在的相互依赖关系,从而特征子集中可能包含冗余特征。为此再选取CFS评估算法,以上述特征空间为基础进行特征优化,通过结合GreedyStepwise搜索策略,CFS从大量的特征空间中选取5项特征构成特征子集F7。各特征子集包含的特征如表1所示。 3.3 机器学习 对上述各特征选择算法确定的特征子集,利用J48,RF,RT,Bayes等方法实现恶意URLs检测,结果如表2所示。表1 特征选择算法选择结果
IG F2 时间、最大子路径长度、域名分割后最长字串长度占域名比例、url中超长字串的最大长度、url长度、域名分割后最长字串长度、二元组和在恶意集、数字字母的转换频次、保留字符数、数字数量比例、url中连续字母最大长度、元辅音比、域名级数、url中数字数量、域名大小、[n]元字符串重复频次、大写字母数、域名中不同字符种类占比、路径级数、二元组和在良性集、url中连续数字最大长度、其他字符数 CHI OneR
GR F3 时间、&的数量与=的数量关系、结尾字符、域名级数、数字字母的转换频次、大写字母数、&数量、url中超长字串的最大长度、最大子路径长度、域名分割后最长字串长度、保留字符数、非不安全字符比例、文件是否包含两级以上扩展名、url中连续数字最大长度、路径级数、域名分割后最长字串长度占域名比例、url中连续字母最大长度数字数量比例、二元组和在恶意集、不安全字符数、url中数字数量、url长度 Relief F4 时间、域名分割后最长字串长度占域名比例、域名中不同字符种类占比、最大子路径长度、数字数量比例、元辅音比、url中连续字母最大长度、保留字符数、域名大小、路径级数、域名级数、url中连续数字最大长度、二元组和在良性集、&数量、域名分割后最长字串长度、二元组和在恶意集、等号数量、url中数字数量、域名中数字数量、其他字符数、&的数量与=的数量关系、结尾字符 CAE F5 域名分割后最长字串长度占域名比例、域名分割后最长字串长度、url中连续字母最大长度、保留字符数、二元组和在恶意集、元辅音比、数字数量比例、路径级数、url中数字数量、url长度、域名大小、url中超长字串的最大长度、数字字母的转换频次、等号数量、域名级数、url中连续数字最大长度、&数量、&的数量与=的数量关系、?数量是否为零、域名中数字数量、其他字符数 综合 F6 时间、保留字符数、其他字符数、url中连续数字最大长度、url中连续字母最大长度、url中数字数量、数字数量比例、二元组和在恶意集、二元组和在良性集、域名级数、域名分割后最长字串长度、域名分割后最长字串长度占域名比例、域名中不同字符种类占比、路径级数、最大子路径长度 CFS F7 时间、数字字母的转换频次、&的数量与=的数量关系、域名级数、最大子路径长度 ]
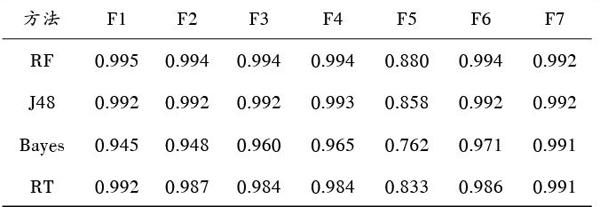
表2 基于子集F1~F7的分类结果
由表2可以发现:特征子集F1,F2,F3,F4均具有良好的检测效果,RF,J48,RT方法的准确率均达到了99%以上,Bayes方法稍逊,但达到94.5%,子集F3,F4准确率还超过96%。
表3综合上述特征子集F1~F7的分类结果,以F?measure标准为参考。可知子集F5的结果并不理想,不适用于本文问题。子集F2,F3,F4的分类性能虽均呈现轻微变化,但增减并不明显,说明特征选择的结果是有效的。针对缩减特征子集的变量数量的能力,子集F6和F7的选择结果更优。其中,子集F6包含15项特征,较子集F1的34项特征有显著减少,可有效降低学习过程中的计算复杂度并提升计算速度。对于F6,基于RF和RT的分类性能仅有0.001和0.006的微小减少,Bayes甚至有0.026的提升,说明综合各类方法的子集F6具有更好的代表性,能够有效去除学习过程中冗余、弱相关及贡献率较小的特征。
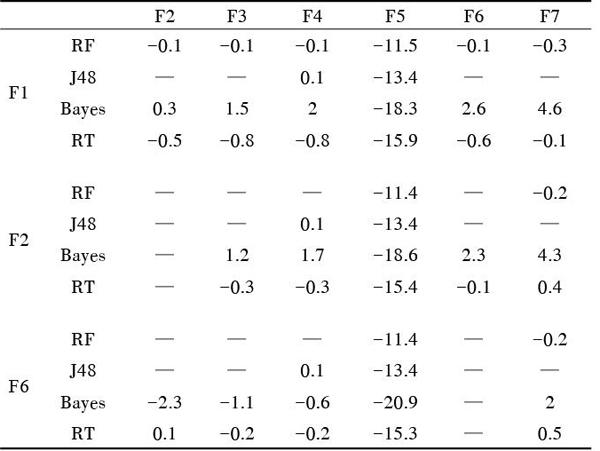
表3 各特征子集分类性能比较
对于子集F5,由于CAE的选择评估标准依赖于单个特征与类别间的相关程度,评估值高的特征对于类别区分具有良好贡献,但是这也会造成相似特征会被同时选择,维度限制下,子集中特征相关性过高,整体贡献力有限。而子集F6则综合多种特征选择方法,有效避免了这一情况的发生。同时,子集F7相比于子集F5的未考虑子集特征间的相关性及子集F6的综合提取不仅评估了单个特征的贡献能力并一同评估特征间的相关性,在降维的同时,最大限度地维持子集的整体贡献值。所以,子集F7表现出更优性能。由表3可知,相对于子集F6,F7较F1的变化更加微小。实际上,子集F7仅包含了时间、数字与字母的转换频次、&与=的数量关系、域名级数、最长子路径长度5个特征,特征空间维度大幅下降,但检测准确率均高达99%,表明该特征子集适用于多类型分类器,具有普适性,是一组优秀的广谱特征。
特征选择的目的是为了在尽可能维持特征可理解性的基础上降低特征空间维度,同时适度增加特征子集的可扩展性及普适性。这就要求所选择的特征子集适用于多种学习算法。由表4可知,子集F1~F4,F6,F7均具有良好的检测结果,各个分类器的平均准确率均超越了98%。同时,综合特征子集空间维度可以发现子集F6和F7达到更优的结果。F6子集的空间维度比F1减少了55.9%,F7子集平均准确率上升至99.15%,相对于子集F1~F5具有更优的性能。
表4 各特征子集对比结果

4 结 语
基于特征的恶意URLs的检测方法具有良好的性能,适于规模化部署,这得力于检测特征的及时有效提取。基于词汇、主机、域名等都可以提取出大量特征,它们的区分能力参差不一,有些特征在某些应用场合甚至会成为噪声数据,从而导致分类器在训练时产生过拟合现象。本文通过对IG,GR,Relief,CHI,CAE,CFS,OneR特征选择算法所遴选的结果特征在分类中的性能比较,确定了一个维度低、分类准确率高的特征子集,有效地减少了特征数量,降低了特征空间维度,既有利于降低计算复杂度,也能有效避免过拟合现象的出现。同时,该特征子集适用于J48,RF,Bayes等多种类型的分类器,具有良好的泛化能力及普适性。另外,选用的特征选择算法在对特征空间进行降维的同时维持了特征的可理解性。现有工作可以有效提高网页访问的安全性,下一步将充实初始特征空间,针对静态和动态特征探索性能更优的特征子集。
参考文献
[1] 胡蓓蓓,彭艳兵,程光.基于Counting Bloom Filter的DNS異常检测[J]. 计算机工程与应用,2014,50(15):82?86.
HU Beibei, PENG Yanbing, CHENG Guang. DNS anomaly detection based on Counting Bloom Filter [J]. Computer enginee?ring and applications, 2014, 50(15): 82?86.
[2] KWON J, LEE J, LEE H, et al. PsyBoG: a scalable botnet detection method for large?scale DNS traffic [J]. Computer networks, 2016, 97: 48?73.
[3] 张维维,龚俭,刘茜,等.基于词素特征的轻量级域名检测算法[J].软件学报,2016,27(9):2348?2364.
ZHANG Weiwei, GONG Jian, LIU Qian, et al. Lightweight domain name detection algorithm based on morpheme features [J]. Journal of software, 2016, 27(9): 2348?2364.
[4] FEROZ M N, MENGEL S. Examination of data, rule generation and detection of phishing URLs using online logistic regression [C]// 2014 IEEE International Conference on Big Data. Washington, DC: IEEE, 2014: 241?250.
[5] AZEEZ N A, OLUWATOSIN A. CyberProtector: identifying compromised URLs in electronic mails with Bayesian classification [C]// 2016 International Conference on Computational Science and Computational Intelligence. Las Vegas: IEEE, 2017: 959?965.
[6] ALGHAMDI B, WATSON J, XU Y. Toward detecting malicious links in online social networks through user behavior [C]// 2016 International Conference on Web Intelligence Workshops. Omaha: IEEE, 2016: 5?8.
[7] 武小年,彭小金,杨宇洋,等.入侵检测中基于SVM的两级特征选择方法[J].通信学报,2015,36(4):23?30.
WU Xiaonian, PENG Xiaojin, YANG Yuyang, et al. Two?level feature selection method based on SVM for intrusion detection [J]. Journal on communications, 2015, 36(4): 23?30.
[8] 张浩.网络数据特征选择的优化方法研究与仿真[J].计算机仿真,2017(2):367?370.
ZHANG Hao. Network data feature selection research and simulation optimization method [J]. Computer simulation, 2017(2): 367?370.
[9] DEMISSE G B, TADESSE T, BAYISSA Y. Data mining attribute selection approach for drought modeling: a case study for greater horn of Africa [J]. International journal of data mining & knowledge management process, 2017, 7(4): 1?16.
[10] DAEEF A Y, AHMAD R B, YACOB Y, et al. Wide scope and fast websites phishing detection using URLs lexical features [C]// 2017 International Conference on Electronic Design. Phuket: IEEE, 2017: 410?415.
[11] VANHOENSHOVEN F, N?POLES G, FALCON R, et al. Detecting malicious URLs using machine learning techniques [C]// 2016 IEEE Symposium Series on Computational Intelligence. Athens: IEEE, 2016: 1?8.
[12] AKIYAMA M, YAGI T, YADA T, et al. Analyzing the ecosystem of malicious URL redirection through longitudinal observation from honeypots [J]. Computers & security, 2017, 69: 155?173.
