利用谐波显著度和语者音色特征的混合语音中目标人基频轨迹提取
2019-09-02后方帅黎美琪刘若伦
后方帅,黎美琪,刘若伦
利用谐波显著度和语者音色特征的混合语音中目标人基频轨迹提取
后方帅1,黎美琪2,刘若伦1
(1. 山东大学,山东威海 264209;2. 中国科学院声学研究所,北京 100190)
从混合语音中提取出目标语者的基频轨迹,是语音监听、语音门禁、对话管理等应用的关键技术。为提高基频轨迹跟踪的准确率、增强抗八度误差的能力、降低系统复杂度,多基频估计以谐波乘积谱为核心,八度校正与基频分组均以元音段为基本单元,并结合了谐波显著度和语者音色特征。基于MIREX2005语音数据集的实验表明,MIREX的4种多基频估计性能指标均在75%以上,基频分组在混合语音中的判断准确率可达92%。
多基频轨迹;谐波乘积谱;语者识别
0 引言
混合语音基频随时间变化的轨迹,是语音分离、增强与识别的关键。现有的基频轨迹估计方法,主要依赖于各语音帧的静态多基频估计(Multi-Pitch Estimation, MPE),其基本思想可分为盲源分离、机器学习、谐波理论三大类。盲源分离类方法将混合信号看作是多个不同音源发出的信号,通过对音源信号特征的提取,将其分解为多个不同单源信号叠加的形式,然后分别检测单源信号的基频。最典型的就是基于计算听觉场景分析(Computational Auditory Scene Analysis, CASA)的方法[1,2]。该类方法复杂且鲁棒性不佳,对信噪比较敏感,且因连续语音存在清音及无声段,基频轨迹不完全连续,难以实现精确时序组合。机器学习类方法[3]的共性是先提取混合信号每帧的基频特征,并用于训练分类器以获取基频轨迹。该法需大量数据才能训练出比较理想的模型,而混合语音MPE的研究尚不成熟,可供使用的数据资源也不够理想,故很难习得性能良好的分类器。谐波理论类方法[4]的主要思想是:混合语音信号所包含的基频轨迹是各帧基频信息连续变化的结果。典型的算法是HSU等[5]提出的谐波叠加法。这类方法大致分为两部分,第一步计算语谱图,然后将属于某基频的若干谐波幅度相加;第二步进行基频判决确定基频轨迹。基频判决的方法多样,常用的有隐马尔科夫模型(Hidden Markov Model, HMM)、趋势估计等。这类方法理论基础完善、研究成果丰富,而且实现简单、计算量小。其中谐波乘积谱(Harmonic Product Spectrum, HPS)方法作为谐波叠加方法的改进,直观地展现了元音段基频轨迹,可以很好地体现基频帧间的连续性。不过该方法较易出现倍/半频错误,常用的基频判决方法也较为复杂且判准率不高。
基于不同的处理域,MPE方法又可分为时域、频域和时频域三大类。时域类方法的理论依据是音频波形在时域上的周期性,该周期的倒数就是基频。传统的方法主要有增强的求和自相关法[6],该方法能取得较高的准确率,但是只适用于分析低频信号;基于正弦混合模型的算法[7]在基频数不超过3的情况下能取得较高的准确率。频域类方法的理论依据是,混合语音信号可以看成基频成分及其谐波成分的组合,混合信号的频谱是多个单人语音信号频谱的线性叠加。代表性的方法有迭代谱减算法[6],该方法的准确率高,但是在确定终止准则参数时需要不断地实验。时频域类方法是在时域和频域上同时对语音信号进行信息处理,可以起到一定的互补效果,主要方法有短时傅里叶变换(Short Time Fourier Transform, STFT)、小波分析等算法。
鉴于时频域及谐波理论类方法的优越性,选取STFT下的HPS作为多基频估计的基础算法。现有的基频轨迹估计方法,主要依赖于各语音帧的单帧静态多基频估计,对帧间连贯性考虑则相对粗浅,故准确率并不高。HPS的计算过程还会在特定条件下加剧八度错误。故本文引入“元音段”重要概念,即时间和基频都连续的语音成分。这里的连续性是指在帧间隔和频率分辨率前提下的时频连续。基于元音段谐波显著度的八度校正及基于语者音色的基频分组,能够有效提高基频轨迹跟踪的准确性,且降低了判决复杂度。
元音及相关特征,如过零率、短时能量和梅尔倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)等,不仅可用于判别说话人的性别[8],还能用来区分不同语者。这类方法的关键问题是元音的端点检测,许多学者也对此进行了研究[9-10]。端点检测的一般方法都可以准确测定较纯净语音的元音起止位置,但对混合语音效果不佳。本文在混合语音多基频估计中得到的元音段信息包含了准确的元音端点检测结果,这保证了元音段音色特征在基频分组中的有效性。虽然混合语音分析的早期代表人物赵鹤鸣等[11]、王敏等[12]众多学者,多次讨论了混合语音的多基频提取及说话人识别问题,却较少有将基频估计与说话人识别联合考虑的。本文将目标人基频轨迹跟踪视为基频估计与说话人识别的联合问题,用元音段作为两者的桥梁,由多基频估计确定元音段,并以此提取音色特征,同时特征参数又用于对元音段进行分组及修正,两者融合互补。
1 算法描述
本文提出的算法框图如图1所示。预处理后的混合语音,首先通过HPS获取元音段基频,然后利用谐波能量和及谐波显著度和对元音基频进行八度校正,实现多基频初步估计。根据已有的MPE结果,再用说话人识别中常用的音色特征对元音段基频进行分组,从而准确跟踪不同人语音的基频变化轨迹,进而实现混合语音的增强与分离。
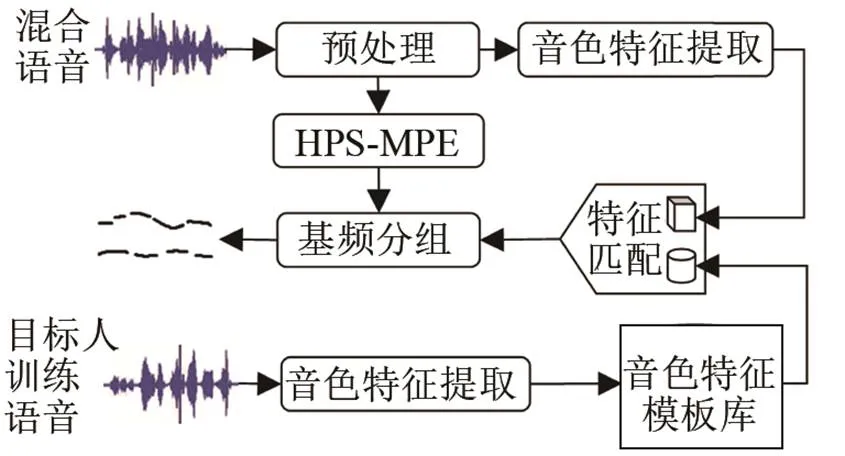
图1 针对目标人的混合语音多基频轨迹提取算法框图
1.1 预处理
预处理分时域和频域两种方式:时域预处理包括语音分段、消除趋势项及直流分量和元音端点检测;频域预处理包括最佳语谱图的确定及离散化和稳态噪声滤除。
本文在传统的基于短时平均过零率和短时平均能量的双门限语音端点检测方法[13]的基础上,根据有话段能量大,过零率小,无话段和清音段的能量小,过零率大,故元音段能零比会更大,非元音段则更小。通过引入前导无话段能零比,就可实现准确的基于短时能零比的双门限动态元音端点检测。
语音频谱的离散化包括主瓣抑制和旁瓣抑制,其示意图如图2所示。首先用旁瓣抑制,只保留大于某阈值的部分谱峰。然后用主瓣抑制,只保留各峰值频率附近一定谱宽的幅度。幅度阈值的设置需考虑语音信号的含噪声情况,一般噪声较大时取较大阈值,当语音信号比较纯净时可以取较小阈值甚至为0。谱峰宽度设为峰值幅度左右各衰减3 dB所对应的宽度。离散化的主要目的是减少语音中的噪声影响,增加基频的鲁棒性及减少计算量,使得后续HPS结果中,那些代表潜在基频的频谱峰值更加显著。图3是离散化后的语谱图。
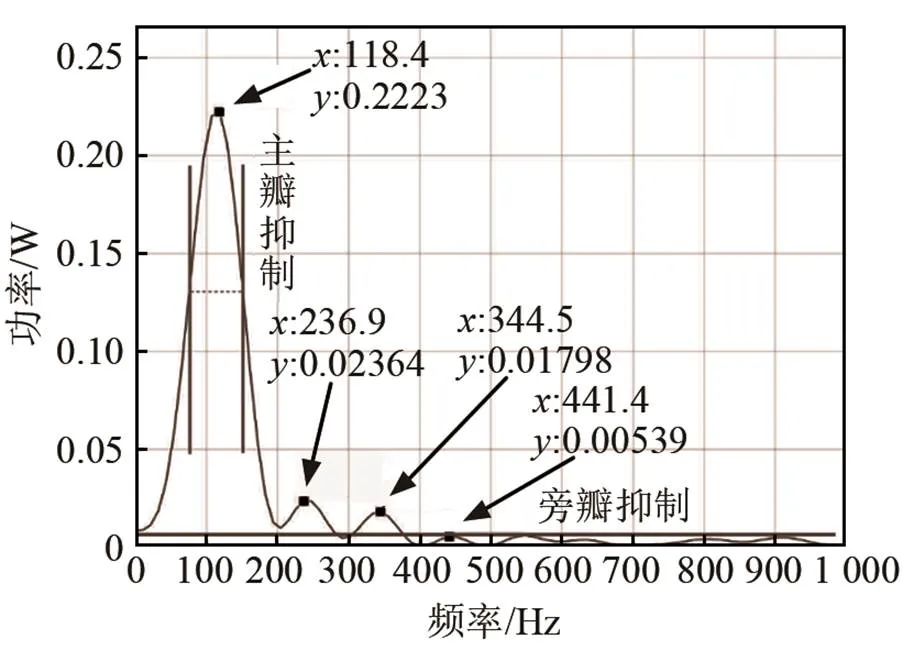
图2 语音频谱离散化示意图
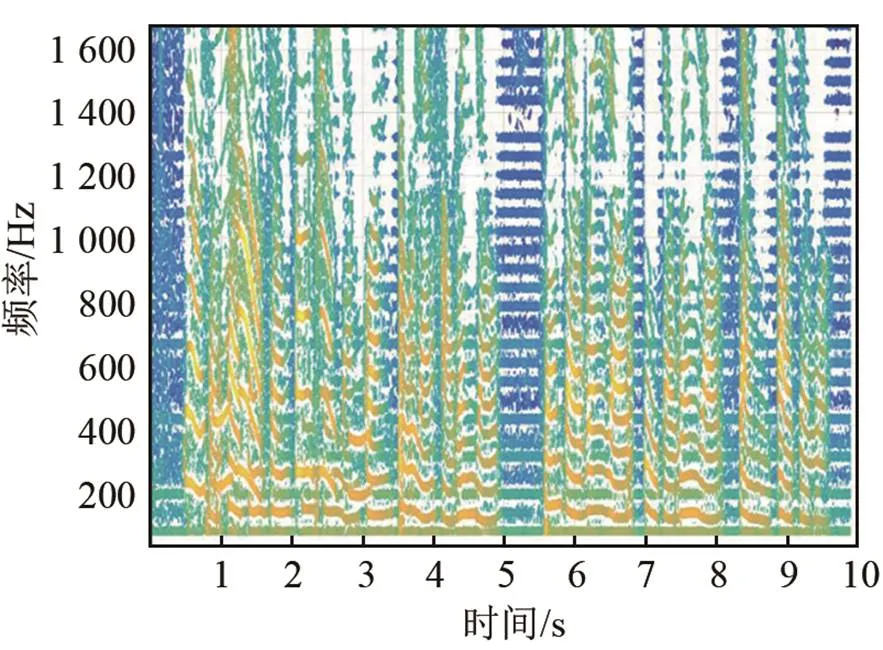
图3 离散语谱图示例
1.2 基于连续性的元音段基频提取
混合语音MPE中的基频连线的依据,一般是频率的帧间连续性,如周超等[14]利用语音基频在相邻两帧内不会超过15 Hz来区分不同基频轨迹,虽然该方法只对单个音节进行了讨论,并不适用于连续语音,但在一个元音段内还是可行的。
元音段基频轨迹提取过程包括:HPS计算、归一化、二值化及基频连线等步骤。
第1步,按式(1)定义计算HPS:

第2步,为了凸显各帧基频并减少基频野点,对每帧HPS幅度按最大值进行归一化:
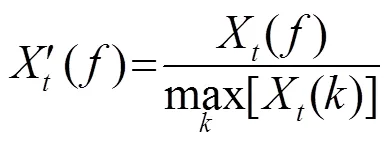
第4步,由频率的连续性以及元音段最小长度,对初始集合进行分组连线。在HPS给出的某帧基频中,频差小于较低频率的1 Bark的所有频率(Bark=26.81/(1+ (1960/))-0.53),将视为同一频率的多个估计,取其平均值作为该基频的估计结果。相邻帧基频间频差经类似处理后,即可得到元音段候选基频轨迹集合{,},和分别代表轨迹的频率和起止时刻。段长小于200 ms的结果将视为野点,直接从集合剔除。
1.3 元音段基频八度校正
MPE中出现的次频与倍频错误统称为八度错误。HPS的计算过程会在特定条件下加剧这种错误,因而需要引入八度校正对错误基频进行重置。为了在校正中避免删除真实的基频,对于两段重叠的候选元音,判定存在八度错误需同时满足以下4条:重叠长度超过长段的1/4;重叠部分两段轨迹变化趋势大体相同;重叠部分两段的基频均值符合八度关系;两段元音区分度小于八度校正阈值。本文联合谐波能量、谐波显著度这两个指标进行八度错误校正,其物理基础是短时HPS给出的候选基频轨迹间的以下几点发现:
(1) 八度错误轨迹和正确轨迹之间存在部分帧重叠,重叠部分的轨迹走向相同,但真实基频轨迹一般会较长且间断时间较短。以真实100 Hz轨迹为例,其可能存在的4种帧重叠如图4所示。

图4 100 Hz正确基频轨迹(蓝色)的4种八度错误基频轨迹(红色)
(2) 当谐波次数一定时,元音段的谐波能量将在真实基频的情况下达到最大值。段谐波能量(Segment Harmonics Energy, SHE)定义为,在元音段内,基频及其各次谐波的能量总和。式(3)给出了集合中第个基频轨迹的SHE:

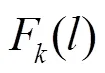
(3) 在绝大部分情况下,谐波功率在基频整数倍处的一个基频宽度内,通常存在极大值;如果在两倍基频宽度内,就可能出现多个竞争性极值;在半个基频宽度内,谐波点功率相对于邻近频率成分的优势则较低,即谐波功率极值的显著程度会明显降低[15]。

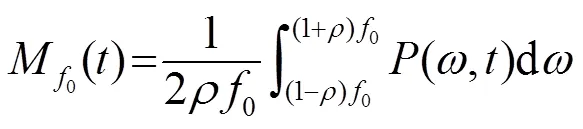

类比SHE的定义方式,通过对各次谐波窄带相对功率谱加权求和,定义第个元音段的FPS:

式中,为压缩因子[5],0<<1。引入该因子的目的是,让容易出现失真的高次谐波对基频产生更小的影响,本文选取=0.5。
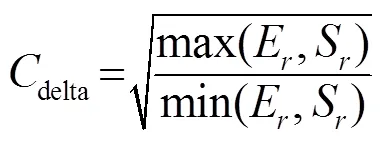
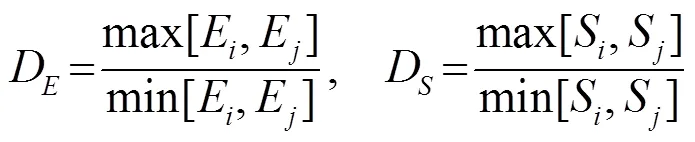
两段元音存在八度关系不等于存在八度错误,如果两段的区分度不足够大,即和相差不大,可认为存在八度错误;若很大,即和相差很大,则认为两段均应独立存在,暂不做处理。选取重置参考的时候也需类似的考量,仅当和同时大于1或同时小于1时,才按前述方法选取参考显著度,否则需选动态范围小的一对SHE或FPS设为参考显著度。
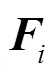

表1 八度重置方式
1.4 基于元音段平均MFCC与平均基频的基频分组
首先,按照上述方式确定目标人训练集语音元音段基频轨迹,并计算各段MFCC的均值(Averaged MFCC, AMFCC)和基频均值(Averaged Fundamental Pitch, AFP)作为音色特征,分别存入目标人AMFCC和AFP样本库。测试时,对混合语各元音段进行相同的处理,并将提取到的结果与样本库中的样本,依据相关系数进行遍历匹配。若扫描任一样本库时的最大相关系数小于0.8,则判定该元音段为非目标人语音,直接剔除。
2 实验分析
本文选取MIREX2005数据集中Amy(女)、Leon(男)、Yifen(女)3人的朗读语音为基础实验材料,将其线性叠加后制成3~12 s的混合语音片段。
2.1 基于HPS的MPE
图5为一段混合语音的MPE结果。其中图5(a)、5(b)分别为引入八度校正前后的结果,图5(c)为混合前各语音的单基频估计结果的直接叠加。从前两组结果可以看出,原始的HPS-MPE方法八度错误十分明显,这主要是由频谱的谐波结构的起伏造成的。八度校正的引入去除了近90%的倍频、半频错误,这主要源于对元音基频连续性、谐波能量、谐波显著度等参数的多方面考虑,合理地对错误基频进行了校正。
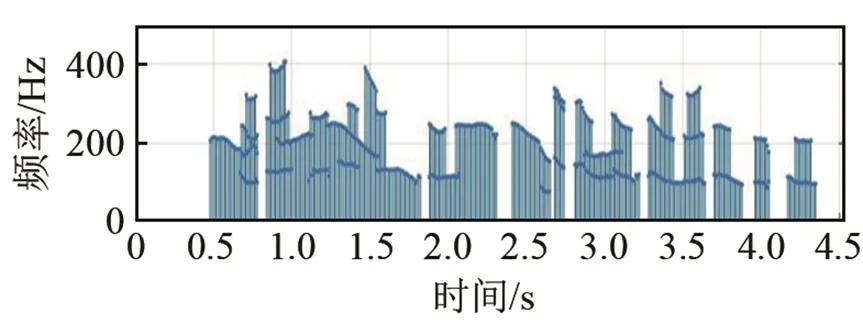
(a) 同帧同频处理+基频分组+剔除野点
(b) 剔除野点+八度纠正
(c) 混合前单基频检测结果直接叠加 图5 某段混合语音的MPE结果图 Fig.5 Multipitch estimation results of a speech mixture segment
将MIREX中四个性能指标的计数单位由帧改为元音段,就得到了本文MPE性能的评价指标。、、、R分别为查全率、查准率、精确率、精确率折中率:
(9)
式中,、、分别表示准确、虚报、漏检的元音段个数。考虑到人耳感知音高的响应时间频率分辨能力,文中对频率偏差不超过10%、元音段长度偏差不超过20%的元音段估计结果,都认为是准确的估计结果。
整体系统运行过程中要具有一定的兼容性与可扩展性,采用标准的组建和接口配置,预留端口,为以后的系统扩展升级提供一定的条件。信号源和发射应相互配合,能够进行自动切换,在任何的情况下都能够保证信号源的持续性,发射不中断,尽量避免出现系统漏洞与设备故障的存在。[3]
表2是针对Amy和Leon的混合语音,采用谐波能量、谐波显著度的查全率,以及两者联合的MPE结果的全部4种性能指标。
表2 Amy-Leon混合语音MPE实验结果(%) Table 2 Multipitch estimation results of amy-leon mixrture(%) RrRrRaRpR 谐波能量谐波显著度谐波能量+谐波显著度 72.277.686.775.084.785.7
从实验结果可以看出,联合两个指标计算得出的查全率明显高于单独使用一项指标的结果,这主要是因为重置算法中使用了谐波能量比与谐波显著度比中较大的作为参考值,当其中一个判断错误时另一个可以弥补,从而减少整体的错误概率。查全率的提高是以虚报率的增加为代价的,丢失的基频很难恢复,但虚报基频却可被剔除,所以需要稍微提高八度错误判定的门限值。漏检错误主要是因为在端点检测、消除噪声、谐波乘积谱两极化提取候选基频中,误删了部分基频,或在八度校正过程中误判两个真实的元音段存在八度错误而导致基频被重置或者去除。虚报错误主要来自噪声或者未被处理的八度错误基频,它将在下面的分组中得到解决。从整体上来看,基频估计的准确率较高,这主要是因为引入了帧间连续性,加入的八度校正模块减少了八度错误。
2.2 基频轨迹分组
本文对基于音色特征进行元音段分组算法的抗噪性、性别相关性及音色特征区分度,每组各做了100次试验,其结果如表3所示,表中没有对语音材料做特殊说明的均为纯净语音,含噪语音的信噪比为5 dB。本文中的识别率定义为:仅考虑测试语音中重叠元音段的前提下,准确判别说话人的元音段个数与全部重叠元音段个数之比。
表3 基于音色特征的语者识别结果 Table 3 Speaker recognition results based on timbre features 实验目的训练样本集测试集识别率/% 抗噪性Amy,LeonLeon99.2 Amy,LeonAmy(含噪)93.53 性别相关性Amy,Yifen(含噪)Amy95.4 Leon,Yifen(含噪)Leon98.7 AMFCC和AFP基频轨迹分组的影响Amy,LeonAMFCCAmy+Leon64.5 Amy,LeonAMFCC, AFPAmy+Leon92.0
如果单纯从基频的角度考虑,相同性别的混合语音基频通常比较接近,因而较难区分。不过本文以元音段为最小识别单位,并且结合了音色识别来辅助基频轨迹的分组,故识别率并无明显降低。实验结果表明,对于单人语音的分组,仅用一个AMFCC音色特征,即使在含噪声的情况下也可以取得95%以上的识别率,这说明AMFCC能够很好地区分不同说话人且具备一定的抗噪性。混合语音分组识别率急剧下降的主要原因是:元音段的AMFCC在元音段重叠严重时,相关匹配误差增大,通过引入AFP可以明显改善分组结果,改善效果如图6所示。
街上有提着筐子卖蒲公英的了,也有卖小根蒜的了。更有些孩子们他们按着时节去折了那刚发芽的柳条,正好可以拧成哨子,就含在嘴里满街地吹。声音有高有低,因为那哨子有粗有细。
图6(a)是仅使用AMFCC时,完全重叠的基频分组出现错误的可能性很大;图6(b)显示的是根据同一人同一时间不能对应多个基频的约束条件,同时使用AMFCC和AFP对错判元音段进行纠正的结果,这证明音色特征参数越多,对说话人的刻画越精细,识别率越高。
(a) 八度纠正前基频轨迹
(b) 八度纠正后基频轨迹 图6 AMFCC基频分组与AMFCC+AFP基频分组结果的对比图 Fig.6 Comparison of pitch trajectory grouping by AMFCC and AMFCC+AP 3 总结 本文将混合语音中目标人基频轨迹的提取分为两步:(1) 以元音段为单位,利用基于HPS及八度校正的MPE算法,减少了近90%的八度错误,与文献[14]相比,提高了近10%。目前在MIREX2005音乐主旋律提取测试集上,音乐中人声基频提取性能最好的结果在88%~90%之间,但均对数据库要求高,运行时间长;相对于大部分方法中用到的HMM等模型,本文的系统流程和算法简单,运行速度快,效率高;引入元音段代替语音帧进行MPE,更好地考虑了帧间连续性,基于元音段的八度校正有效地纠正了HPS中的八度错误,最终在更为复杂的混合语音中,基频估计准确率达84.7%。(2) 将基频分组问题转换为联合音色相关匹配的MPE,提出基于元音段音色特征的与文本无关的基频轨迹分组算法,仅使用AMFCC音色特征时,该算法在单人语音条件下的识别率接近100%,但是在混合语音情况下,识别率急剧下降,通过引入元音相关的AFP进行改进,最终识别率可达92.0%,即增加音色特征参数可以提升识别率。MPE结果与音色匹配融合互补,降低了噪声对基频估计的影响,同时提高了基频估计准确率和识别率。本文在对MPE结果的分组判决中,训练集样本库信息存在较大的冗余,模板对音色的刻画能力有待提升。 参考文献 [1] 胡琦. 基于计算听觉场景分析的单信道语音分离[D]. 北京: 北京交通大学, 2014. HU Qi. Single channel speech separation based on CASA[D]. Beijing: Beijing Jiaotong University, 2014. [2] 吴春. 基于计算听觉场景分析的双说话人混合语音分离研究[D]. 广西: 广西大学, 2014. WU Chun. Double speakers speech mixture separation based on CASA[D]. Guangxi: Guangxi University, 2014. [3] 陈麟琳. 基于机器学习的欠定语音分离方法研究[D]. 大连: 大连理工大学, 2016. CHEN Linlin. Sub-defined speech sparation based on machine learning[D]. Dalian: Dalian University of Technology, 2016. [4] HUANG Q H, WANG D M. Multi-pitch estimation for speech mixture based on multi-length windows harmonic model[C]//2011 Fourth International Joint Conference on Computational Sciences and Optimization, 2011, 345-348. [5] HSU C L, WANG D L, JANG J R, et al. A tandem algorithm for singing pitch extraction and voice separation from music accompaniment[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(5): 1482-1491. [6] 陈雪梅. 乐音信号的MPE[D]. 山东: 山东大学, 2014. CHEN Xuemei. Multipitch estimation of music signal[D]. Jinan: Shandong University, 2014. [7] DAVY M, GODSILL S, IDIER J. Bayesian analysis of western tonal music[J]. J. Acoust. Soc. Am., 2006, 119(4): 2498-2517. [8] BHARALI S S, KALITA S K. Zero crossing rate and short term energy as a cue for sex detection with reference to Assamese vowels[C]//Convergence of Technology (I2CT), 2014 International Conference, 2014. [9] KUMAR A, SHAHNAWAZUDDIN S, PRADHAN G. Exploring different acoustic modeling techniques for the detection of vowels in speech signal[C]//Communication (NCC), 2016 Twenty Second National Conference on 4-6 March 2016. [10] STANEK M. Algorithms for vowel recognition in fluent speech based on formant positions[C]//Telecommunications and Signal Processing (TSP), 2013 36th International Conference on 2-4 July 2013. [11] 赵鹤鸣, 周旭东, 金延庆, 等. 基于小波变换的重叠语音基频提取及声调识别[J]. 声学学报, 1999, 24(1): 87-93. ZHAO Heming, ZHOU Xudong, JIN Qingyan, et al. Overlapped speech fundamental frequency extraction and pitch recognition based on wavelet transform[J]. Acta Acustica, 1999, 24(1):87-93. [12] 王敏, 赵鹤鸣.基于多带解调分析和瞬时频率估计的耳语音话者识别[J]. 声学学报, 2010, 35(1): 471-476. WANG Min, ZHAO Heming. Wisper speaker recognition based on multiband demodulation analysis and instance frequency estimation[J]. Acta Acustica, 2010, 35(1): 471-476. [13] 宋知用. MATLAB在语音信号分析与合成中的应用[M]. 北京: 北京航空航天大学出版社, 2013, 78-95. SONG Zhiyong. Applications of MATLAB in speech signal analysis and synthesis[M]. Beijing: Beihang University Press, 2013, 78-95. [14] 周超, 洪弘. 汉语普通话双基频检测[J]. 声学学报, 2011, 36(2):239-243. ZHOU Chao, HONG Hong. Double fundamental pitch detection of Chinese mandarin[J]. Acta Acustica, 2011, 36(2): 239-243. [15] 宋黎明, 李明, 颜永红. 谐波显著度的基频提取方法[J]. 声学学报, 2015, 40(2): 294-299. SONG Liming, LI Ming, YAN Yonghong. Fundamental frequency extraction based on harmonic saliency[J]. Acta Acustica, 2015, 40(2): 294-299. Target pitch trajectory extraction in hybrid speech by using harmonic saliency and speaker’stimbre features KOU Fang-shuai1, LI Mei-qi2, LIU Ruo-lun1 (1. Shandong University, Weihai 264209, Shandong, China; 2. The Institute of Acoustics of the Chinese Academy of Sciences, Beijing 100190, China) Abstract: Tracking the pitch trajectory of a target speaker in hybrid speech is of great importance in speech monitoring, voice access, and dialog management. To improve the accuracy of pitch trajectory tracking and enforce the octave error suppression ability while reducing the system complexity, the harmonic product spectrum is used in the multipitch estimation. Both the octave error correction and the pitch grouping are based on the vowel segment unit and using the harmonic saliency and the speaker’s timbre features. In the evaluation over the speech data set of MIREX2005, the four performance indexes of the multipitch estimation are all higher than 75 %, and the accuracy of pitch grouping in the hybrid speech can reach 92 %. Key words: multipitch trajectory;harmonic product spectrum; speaker recognition 中图分类号:H107 文献标识码:A 文章编号:1000-3630(2019)-04-0408-06 DOI编码:10.16300/j.cnki.1000-3630.2019.04.009 收稿日期: 2018-04-11; 修回日期: 2018-05-14 基金项目: 上海市信息安全综合管理重点实验室开放基金项目(AGK201709)、山东省自然科学基金资助项目(ZR2016FM44)。 作者简介:后方帅(1992-), 男, 山东曹县人, 硕士研究生, 研究方向为音频信号模式分类。 通讯作者: 刘若伦,E-mail: ruolun.liu@sdu.edu.cn
