高中人工智能课程项目案例资源设计与开发
2019-08-30张学军董晓辉
张学军 董晓辉

[摘 要] 随着新版《普通高中信息技术课程标准(2017年版)》的发布,案例教学资源尤其是具有情境性、复杂性、综合性、实践性等特点的项目案例教学资源的建设成了一项亟须解决的任务。面对目前项目案例资源严重不足的现状,文章在相关研究基础上,基于大数据时代背景下人工智能应用的视角,提出了基于大数据的人工智能应用开发框架,阐述了该开发框架所包含的网络爬虫应用开发和基于大数据的人工智能应用开发流程的设计。基于该开发框架并结合新版《普通高中信息技术课程标准(2017年版)》中的“人工智能初步”模块要求,构建了高中信息技术课程的人工智能应用设计框架。基于该设计框架,使用Python语言开发了有声小说、教育故事文本分析、人脸检测与人脸识别三个人工智能应用项目案例。这些项目案例融合了大数据、人工智能应用的典型特征,具有较好的迁移性,不但可以在高中信息技术课程中的“人工智能初步”模块以及其他模块中使用,其设计框架也为基于学科核心素养的高中信息技术课程教学的落地提供了一种解决思路。
[关键词] 大数据; 人工智能; 高中人工智能课程; 项目案例资源; 设计与开发
[中图分类号] G434 [文献标志码] A
[作者简介] 张学军(1968—),男,甘肃会宁人。教授,博士,主要从事数字化教育资源设计与开发、人工智能教育研究。E-mail: xjzhang99@163.com。
一、问题的提出
根据美国市场调查公司IDC的预测,人类产生的数据量正在呈指数级增长,这个速度在2020年之前会一直保持下去。预计到2020年,全球将总共拥有35ZB(1ZB数据相当于全世界海滩上的沙子数量的总和)的数据量。一方面,数据量的爆炸式增长、社会的日益数字化,促使人类社会进入大数据时代[1];另一方面,大数据、云计算等技术推动人工智能进入快速发展期,以大数据为原材料、人工智能为引擎的科技时代的来临不可阻挡。在教育领域,基于大数据的人工智能应用将使教育更加接近教育的本质:系统地帮助学习者提升认知能力并服务于学习者的个性化需求[2]。2017 年,国务院出台的《新一代人工智能发展规划》明确提出,在中小学阶段设置人工智能相关课程,逐步推广编程教育[3]。新版《普通高中信息技术课程标准(2017年版)》,将“人工智能初步”模块列为选择性必修课[4]。由于人工智能课程难度较大,不宜采用传统的“讲授”式教学,更適合应用情境化、基于问题、基于案例的教学模式[5]。从现有的理论研究来看,有较好价值的中学人工智能教育案例研究的成果很有限[6-8];从目前的实际应用情况来看,类似《人工智能基础(高中版)》[9]这样的配套了实验平台(提供案例)的教材还不多,提供的案例资源也很有限。项目案例资源作为一种特殊的教学资源,以贴近实际的项目为载体,具有情境性、复杂性、综合性、实践性等特点,能够更好地帮助学生理解并运用知识来解决实际问题。因此,本文所在研究团队开发了几个典型的可用于高中人工智能教育应用的项目案例资源,为高中人工智能教育如何落地提供依据,同时,也为高中一线信息技术教师如何上好人工智能课提供可借鉴的思路。因为开发的项目案例资源既涉及人工智能教育应用,同时,又关联大数据如何获取。所以,该项目案例资源不但可用于高中“人工智能初步”模块的教学,而且高中信息技术课程其他模块也能参考使用。
二、大数据背景下人工智能课程的技术基础
高中信息技术课程的人工智能应用项目案例涉及数据获取(网络爬虫)和人工智能领域的语音合成、文本分析、人脸检测与人脸识别等多种技术。
(一)网络爬虫
网络爬虫是一种自动下载网络资源的程序[10] ,网络爬虫按照实现的技术和结构可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫等类型[11]。笔者所在研究团队开发的3个项目案例中的网络爬虫属于聚焦网络爬虫。聚焦网络爬虫也叫主题网络爬虫,顾名思义,聚焦网络爬虫是按照预先定义好的主题有选择地进行网页爬取的一种爬虫。聚焦网络爬虫在开发时要关注以下几点:第一,根据主题确定要爬取的网站数据;第二,分析整个网站的数据结构(确定网站的URL格式,确定网页的数据格式、编码格式以及对外请求方式);第三,编写代码时,首先要通过请求网络获取服务器响应后的数据,其次要分析数据结构,通过解析的方式过滤出有用的数据,最后把过滤的数据进行保存(本地保存或数据库保存)。本文在3个项目案例中使用Python语言,利用网络爬虫技术根据主题需要爬取了1057720部小说(文本)、2060篇教育故事(文本)和30680张人物图片。
(二)语音合成
语音合成是文本转换为语音的技术[12]。基于深度神经网络(DNN)的语音合成一般要经过如下步骤:文本→文本分析→特征提取→DNN处理→参数生成→波形生成→语音[13-14]。使用应用程序编程接口(API)是快速获得语音合成等相关应用结果数据的好方法。很多知名的大公司都开放了API,如国外的Google、Amazon和国内的百度、腾讯、阿里巴巴、科大讯飞等公司都开放了大量人工智能API,其中百度开放的人工智能API涉及百度语音(语音识别、语音合成)等11个大类和许多子类。本文在项目案例1“有声小说”中,使用Python语言,通过调用百度语音API中的语音合成API,将1057720部小说(文本)转换成了相应的语音文件(mp3格式)。
(三)文本分析
文本分析也称为文本挖掘,是从文本数据中获得高质量的信息和见解所遵循的方法和过程[15]。文本分析一般由获取文本信息(原始文本)、分词(将原始的文本分割成一个个独立的词)、文本清洗(去除无用的标签、特殊符号、停用词)、标准化(词干提取、词形还原)、特征提取(词频率与逆文档率、词嵌入、文本转换为稀疏矩阵)、建模(相似度算法、分类算法)等环节组成。本文在项目案例2“教育故事文本分析”中,使用Python语言,通过调用百度人工智能自然语言处理API中的情感倾向分析API,实现了2060篇教育故事文章的情感倾向分析。项目案例2中2060篇教育故事文章的文档主题分析,则是使用Python语言,通过调用机器学习scikit-learn库中隐含Dirichlet 分布(LatentDirichletAllocation,LDA)模块实现的。
(四)人脸检测与人脸识别
人脸检测,简单来说就是从图片找到人脸的位置。一般来说,人脸检测应该可以正确检测出图片中存在的所有人脸,不能有遗漏,也不能有错检[16]。由于人臉识别一般包含人脸检测环节,所以本文主要介绍人脸识别。人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术[17]。本文在项目案例3“人脸检测与人脸识别”中,使用Python语言,通过调用百度人工智能人脸识别API中的人脸检测API和人脸对比API,实现了所选静态图片的人脸检测和人脸识别,对于动态环境(摄像头刷脸)下的人脸检测和人脸识别,则是使用Python语言,通过调用人脸识别库face_recognition和计算机视觉库python-opencv联合实现的。
三、基于大数据的人工智能应用开发框架设计
大数据背景下的人工智能应用开发不能只考虑人工智能应用因素,需要融合互联网大数据、人工智能应用两大因素,形成“互联网大数据+人工智能应用”的开发思路。
(一)基于大数据的人工智能应用开发框架设计
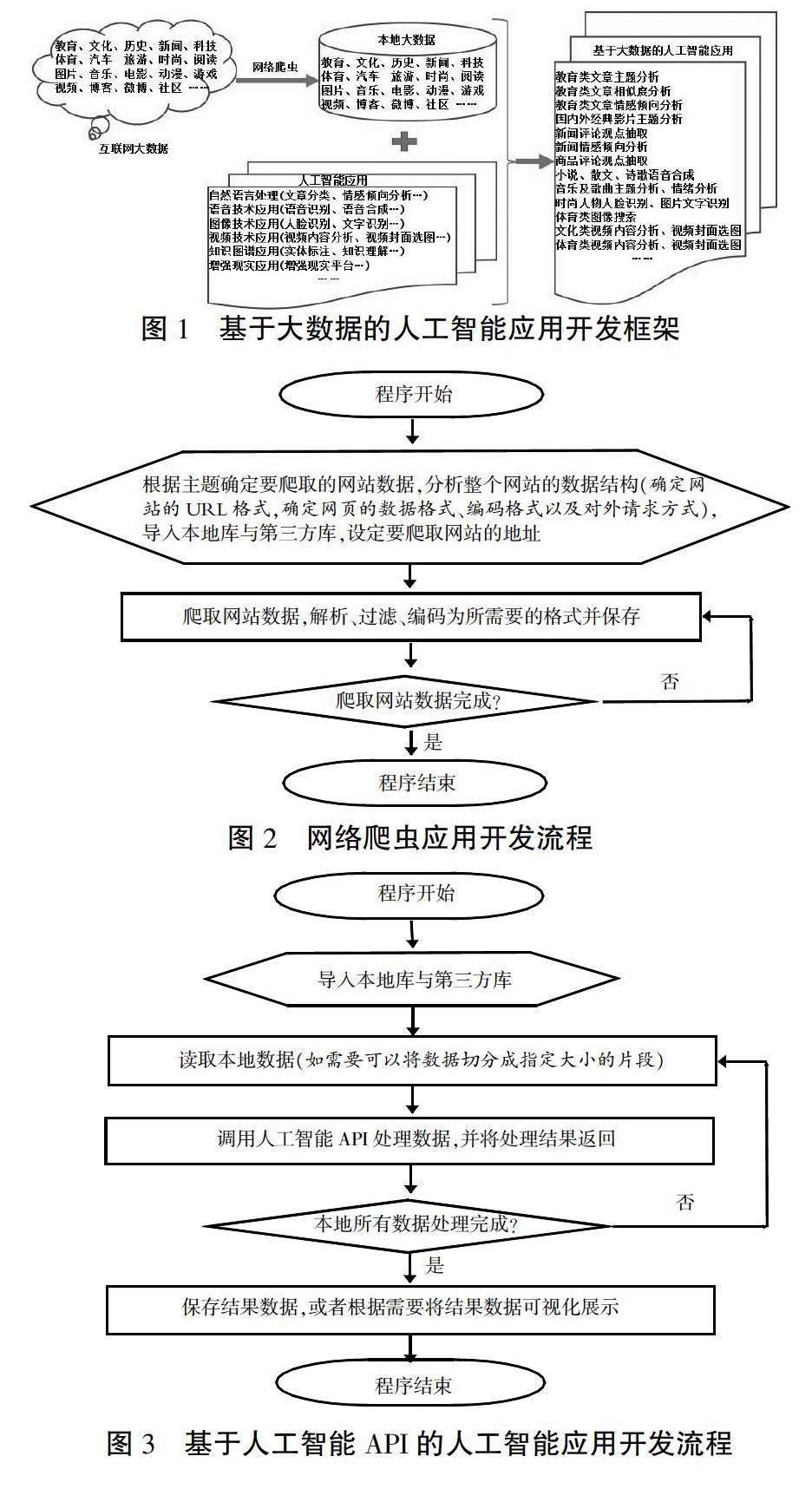
基于大数据的人工智能应用开发涉及四个关键词:大数据、人工智能应用、网络爬虫、大数据与人工智能应用的结合。对于大数据,主要考虑大数据从哪里来以及如何存储,本文认为目前大数据的主要来源就是互联网,互联网上有各种各样的大数据,这些大数据来自于教育、文化、历史等各个领域,互联网大数据一般不能直接使用,要通过网络爬虫下载到本地,选用适合的存储方式存储成为可直接使用的大数据。本文认为,人工智能应用主要涉及自然语言处理、语音技术应用、图像技术应用等应用领域;只有将本地大数据与人工智能应用相结合,才能满足包含教育类文章主题分析等各种具体应用项目的要求。基于大数据的人工智能应用开发框架如图1所示。
互联网是孕育各类大数据的非常重要的来源。互联网上的大数据浩如烟海,如教育、文化、历史、新闻、科技、体育、汽车、旅游、时尚、阅读、图片、音乐、电影、动漫、游戏、视频、博客、微博、社区等各类大数据,应有尽有。开发时,首先要根据主题需要选择其中的某类主题,然后通过百度等搜索引擎查找、分析互联网上与所选主题尽可能吻合的网站作为大数据的来源;然后利用网络爬虫技术编写爬虫程序,将所选网站上相应主题的大数据下载到本地电脑形成本地大数据;接下来根据开发需要选择人工智能应用中的某类应用(目前能实现的人工智能应用涉及自然语言处理、语音技术应用、图像技术应用、视频技术应用、知识图谱应用、增强现实应用等多种类型,开发者可根据开发需要选择其中具体的某类应用来进行);最后针对下载到本地的某个主题的大数据(如教育类文章),利用人工智能应用中的某类具体应用(如文章分类),开发相应的基于大数据的某个具体的人工智能应用(如教育类文章主题分析)。
(二)网络爬虫应用开发流程设计
网络爬虫应用程序是实现从互联网大数据到本地大数据转移的主要技术手段,网络爬虫应用开发流程如图2所示。以Python语言为例,首先根据主题确定要爬取的网站数据,分析整个网站的数据结构(确定网站的URL格式,确定网页的数据格式、编码格式以及对外请求方式),导入Python中os、time、re、json等本地库以及requests、bs4、lxml、pandas等第三方库,设定要爬取网站的地址;然后运用requests中get等方法爬取网站数据,利用解析、过滤方法(如lxml中xpath)解析、过滤网站数据,编码为所需要的格式(如utf-8),并通过数据保存方法(如pandas中to_csv)保存到本地文件(当然也可以根据需要采用其他方法保存到本地数据库)。
(三)基于人工智能API的人工智能应用开发流程设计
基于人工智能API的人工智能应用程序是实现基于大数据的人工智能应用的常用技术手段和核心环节。本文的人工智能应用程序所需的大数据,指的是将所需要的互联网大数据经过网络爬虫应用程序爬取下来保存到本地的大数据。基于人工智能API的人工智能应用开发流程如图3所示。
以使用Python语言开发语音合成为例,首先导入Python中os、re等本地库以及人工智能语音处理第三方库(如百度语音处理aip);然后读取爬取好的本好大数据[如本文中的1057720部小说,根据需要将每部小说切分成长度为1024字节的一系列片段(百度人工智能语音aip每次处理的文本长度要求不超过1024字节)];调用人工智能API(如百度语音处理aip库中AipSpeech模块的语音合成方法systhesis)将相应文本数据转换为音频数据;最后将音频数据保存为mp3文件(本文在程序中还调用了ffmpeg软件,将初步生成的一个个片段mp3文件拼接成了一个完整的mp3文件)。
四、高中信息技术课程人工智能应用设计框架
高中信息技术课程人工智能应用设计框架的构建有三个依据:(1)普通高中信息技术课程标准(2017版)中“人工智能初步”模块的要求;(2)华东师范大学出版社和商务印书馆联合出版的教材《人工智能基础(高中版)》内容要求;(3)基于大数据的人工智能应用开发框架。人工智能应用设计框架如图4所示。
《普通高中信息技术课程标准(2017年版)》中“人工智能初步”模块内容要求明确指出,通过剖析具体案例,了解人工智能的核心算法,熟悉智能技术应用的基本过程和实现原理;知道特定领域(如机器学习)人工智能应用系统的开发工具和开发平台,通过具体案例了解这些工具的特点、应用模式及局限性;利用开源人工智能应用框架,搭建简单的人工智能应用模块,并能根据实际需要配置适当的环境、参数及自然交互方式等[4]。这些内容要求在图4中的“基于大数据的人工智能应用开发框架”中通过技术环境层、大数据接口层、人工智能API层和人工智能应用层等由低层到高层的四层结构整体体现出来。人工智能应用层包含语音识别/合成、图像识别、自然语言处理等各种人工智能应用案例,人工智能API层包括百度人工智能API等开发工具和开发平台,技术环境层包括tensorflow等开源人工智能应用框架。
华东师范大学出版社和商务印书馆联合出版的教材《人工智能基础(高中版)》依据《普通高中信息技术课程标准(2017年版)》中“人工智能初步”模块内容要求编写,该教材设计思路提炼为“耳聪目明,心灵手巧”[18],这八个字的设计思路体现在该教材的内容结构[共九章,按先后顺序为(1)人工智能:新时代的开启心灵(开篇);(2)牛刀小试:察异辨花(目明);(3)别具慧眼:识图认物(目明);(4)耳听八方:析音赏乐(耳聪);(5)冰雪聪明:看懂视频(目明) ;(6)无师自通:分门别类(目明);(7)识文断字:理解文本(心灵);(8)神来之笔:创作图画(手巧);(9)运筹帷幄:围棋高手(心灵)]中。
在分析上述高中信息技术课程人工智能应用设计框架构建的前两个依据的基础上,本研究基于大数据的人工智能应用开发框架,设计了高中信息技术课程人工智能应用设计框架中虚线框内的应用开发框架,该框架在本质上与图1的框架是一致的,只不过为了便于解释将它分为四层(技术环境层、大数据接口层、人工智能API层和人工智能应用层)。人工智能应用层包含语音识别/合成对应教材设计思路中的“耳聪”,图像识别对应教材设计思路中的“目明”,自然語言处理对应教材设计思路中的“心灵”;人工智能应用层的实现需要调用下层的人工智能API层(如百度人工智能API接口等)来实现具体的语音识别/合成、图像识别、自然语言处理等应用,因为现在的人工智能应用讲求“无数据,不智能”,因此,人工智能API层需要调用下层的大数据接口层(如网络爬虫等)来实现将互联网上的大数据下载到本地,网络爬虫的实现依据图2中的网络爬虫应用开发流程;大数据接口层最终依赖最低层技术环境层(如python、tensorflow等)的支持。高中信息技术课程人工智能应用设计框架图中虚线框内的应用开发框架的技术实现依据图2的网络爬虫应用开发流程和图3的基于人工智能API的人工智能应用开发流程来实施。
五、高中信息技术课程人工智能应用项目案例资源开发
本文开发的3个高中信息技术课程人工智能应用项目案例(项目案例之一:“有声小说”,涉及语音合成,对应教材设计思路中的“耳聪”;项目案例之二:“教育故事文本分析”,涉及自然语言处理,对应教材设计思路中的“心灵”;项目案例之三:“人脸检测与人脸识别”,涉及图像识别,对应教材设计思路中的“目明”),均属于基于大数据的人工智能应用,选用的程序开发语言是Python。之所以选择Python作为高中人工智能应用开发语言,理由有以下几个方面:第一,Python是最接近自然语言的计算机程序语言之一,也是当前业界人工智能应用开发的首选语言之一;第二,Python入门门槛低,开发者学习后可以快速上手,将精力集中于开发项目中的主要业务逻辑本身而不是侧重于Python语法;第三,Python除了本身自带的大量核心库以外,还可以广泛使用大量的第三方库,从而快速实现网络爬虫、Web应用、数据分析、人工智能等各种应用开发;第四,目前新课改在审的高中信息技术教材中大都使用了Python语言,Python语言很有可能成为高中信息技术教材甚至相应科目高考的首选语言。实践过程中,每个项目案例资源开发时所采用的应用程序由网络爬虫、人工智能应用两大部分组成。其中网络爬虫实现互联网大数据向本地大数据的转移,人工智能应用实现语音合成、文本情感分析、文档主题分析、人脸检测与识别等应用。程序开发环境:(1)操作系统 win7/win10;(2)Python语言版本3.6;(3)Python集成开发环境PyCharm 2018.2。
(一)项目案例之一:有声小说
该项目案例旨在体现人工智能课程三大应用(自然语言、语音、图像/视频)之一的语音技术应用,让学生在复杂的项目情境中深刻体会人工智能课程中语音识别/合成技术的原理和算法,实现高中人工智能课程教材中的“耳聪”(能听会说)目标,以及高中信息技术新课标的计算思维学科核心素养。该项目代码包含学习Python编程所需的绝大部分语法,同时,又涉及网络小说大数据爬取和人工智能中语音合成算法的应用。通过该项目的算法讲解、代码训练,既能培养学生的文本大数据与人工智能语音技术应用能力,又能有效培养学生的计算思维。
1. 案例介绍
“有声小说”项目实现爬取网络小说大数据(文本)并转换为语音(mp3文件)。在网络爬虫应用开发中,从起点中文网(https://www.qidian.com,2018-12-15)选择免费的小说,利用Python编写的网络爬虫程序(novelDownAll.py,程序代码近50行) 共爬取了1057720部小说;在人工智能应用开发中,使用Python编写的语音合成程序(SpeechSynthesisAll.py,程序代码120多行) 将爬取的小说转换为语音(mp3文件)。
2. 程序实现
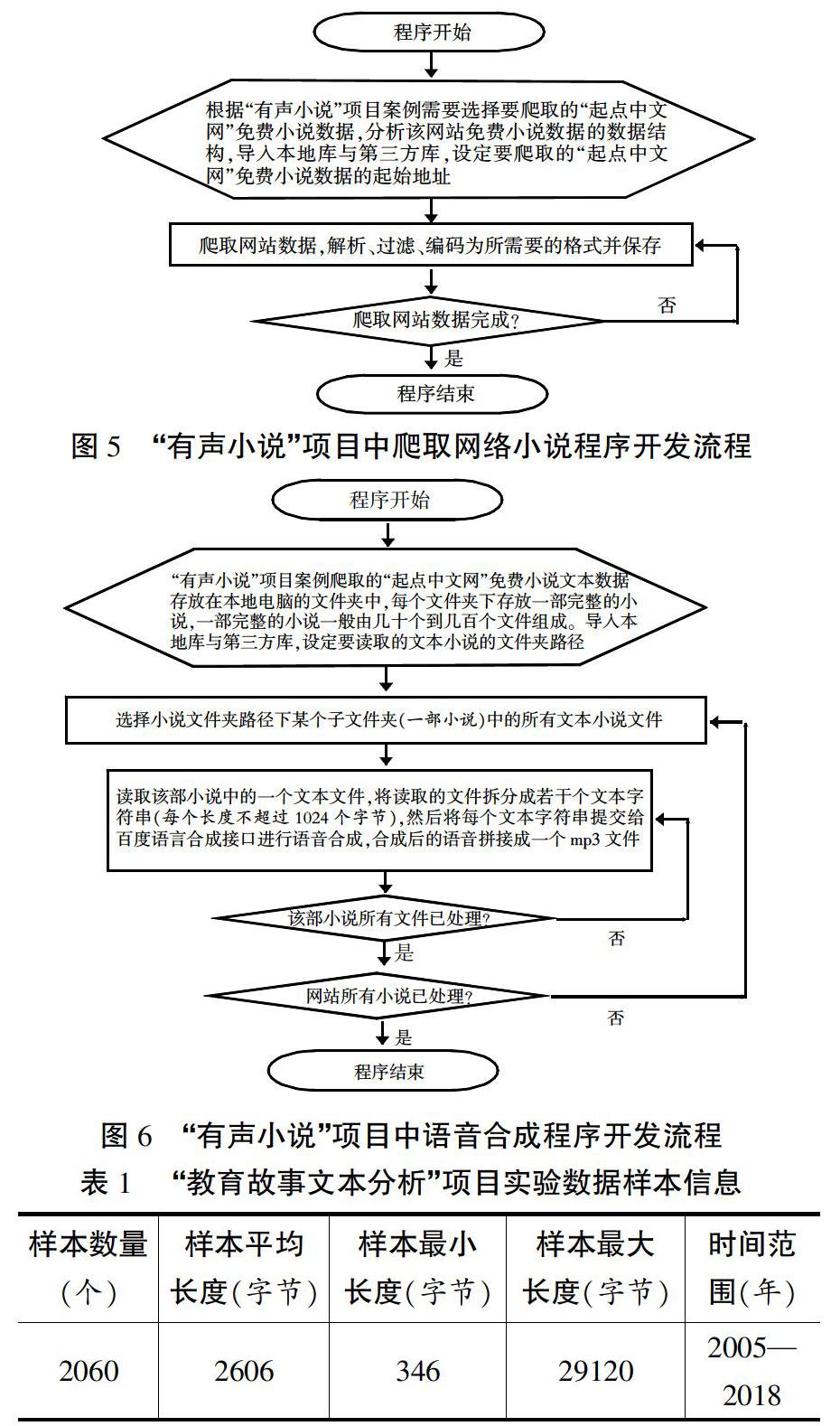
“有声小说”是一个非常典型的基于大数据的人工智能应用项目,由通过网络爬虫爬取网络小说程序和通过百度语音合成接口生成mp3小说程序两部分组成,其程序开发流程如图5、图6所示。由于本文篇幅所限,未能提供程序源码,有需要者可通过E-mail与作者联系。
(二)项目案例之二:教育故事文本分析
该项目案例旨在体现人工智能课程三大应用(自然语言、语音、图像/视频)之一的自然语言处理应用,让学生在复杂的项目情境中深刻体会人工智能课程中自然语言处理(含文本情感分析)的原理和算法,实现高中人工智能课程教材中的“心灵”(能思考会分析)目标以及高中信息技术新课标的计算思维学科核心素养。该项目代码也包含了学习Python编程所需的绝大部分语法,同时,又涉及教育故事文本大数据爬取和人工智能中文本分析算法的应用。通过该项目的算法讲解、代码训练,既能培养学生的文本大数据与人工智能自然语言处理应用能力,又能有效培养学生的计算思维。
1. 案例介绍
“教育故事文本分析”项目爬取了教育故事类文章并对这些文章进行了情感分析与主题分析。在网络爬虫应用开发中,从7C教育资源网(http://www.7cxk.net/,原名为中小学教育资源站,2018-12-20)中选择了教育故事栏目,使用Python编写的网络爬虫程序共爬取了2060篇文章;在人工智能应用开发中,使用Python编写的程序实现了2054篇(剔除了6篇,由于某些限制无法用人工智能API分析)文章的情感分析和2060篇文章的主题分析。
2. 情感分析过程及结果
本文之所以选择7C教育资源网作为“教育故事文本分析”项目的数据来源,是由于该网站资源较为丰富,其中包括从小学到高中各学科的各类资源,其中既有学生资源,也有教师资源。“教育故事”(http://www.7cxk.net/teacher/guanli/gushi/)是7C教育资源网中属于教师资源的一个栏目,积累了学科教师和教育名家撰写的大量生动活泼、积极向上、教育价值和意义突出的教育故事类文章。“教育故事文本分析”项目从上述网站中爬取的实验样本数据见表1。
表1中样本长度在346字節至29120字节之间,样本长度分布如图7所示。
文本情感分析,简单来说就是分析文本以理解作者表达观点中所透露出来的情感、感觉或情绪。情感分析也称为意见分析/挖掘,是指使用如自然语言处理NLP、字典资源、语言学和机器学习等技术来进行主观意见相关的信息提取(这些主观意见包括情绪、态度、心情、情态等),并尝试用这些来计算文本文档所表示的极性(指文本是否表示积极、消极或中性的情绪,更高级的分析包括寻找更复杂的情绪如悲伤、快乐、愤怒和讽刺等)的过程[15]。“教育故事文本分析”项目情感分析结果如图8(a)、(b)所示。
本文的情感分析调用了百度人工智能文本分析API的aip库中的AipNlp模块,调用的方法是sentimentClassify,使用该方法会返回极性 (Sentment:0表示积极,1表示中性,2表示消极)、积极情感概率(positive_prob)、消极情感概率(negative_prob)、置信度(confidence)等信息。由于连续频繁调用百度人工智能文本分析API服务会被拒绝,所以2054个文本(1个文本代表1篇文章,2060个文本按顺序从1~2060编号,剔除了6个由于某些限制无法用人工智能API分析的文章,其编号依次为367、1121、1137、1303、1439、2055)被分成两个图[图8(a)、(b)]来显示。由于百度人工智能文本分析API每次能处理的文本长度不超过1024个字节,因此,将每个文本切分成了一系列片段,每个片段为1024个字节,所以图中纵坐标的单位是(片)段数(1024字节/段)。图8(a)、(b)中的积极、中性、消极均表示置信度在95%及以上的文本数据,积极_参考、中性_参考、消极_参考均表示置信度在95%以下的文本数据,积极_总表示积极与积极_参考数量之和,消极_总表示消极与消极_参考数量之和,中性_总表示中性与中性_参考数量之和。
从图8(a)、(b)中可以看出,2054篇教育故事类文章中情感极性属于积极的最多,属于消极的次之,属于中性的最少,详细占比如图9所示。
从图9可以看出,积极情感(置信度高)占22.73 %,积极情感占 48.80 %,积极情感合计占71.53%;消极情感(置信度高)占3.71 %,消极情感占 22.66 %,消极情感合计占26.37%;中性情感(置信度高)占0.04 %,中性情感占 2.21 %,中性情感合计占2.25%。从情感分析结果来看,积极情感占70%以上。该结果在一定程度上说明,7C教育资源网中的教育故事类文章表达的情感积极向上,由于该分析结果是对2054篇文章的整体分析,近似于全样本 (全样本为2060篇文章),因此,该分析结果有较好的参考价值。
3. 主题分析过程及结果
人工智能文本分析中的主题分析,就是采用聚类分析方法,从而确定文本的核心主题。典型的聚类分析方法有k-means聚类、近邻传播聚类、层次聚类等,本文的主题分析采用了LDA(Latent Dirichlet Allocation)。LDA是一种文档主题生成模型,包含词、主题和文档三层结构,核心观点是文章的每个词都通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到[19]。本文的主题分析以上文介绍的2060篇文章作为数据分析来源,主题分析调用了机器学习scikit-learn库中LDA模块LatentDirichletAllocation,调用的方法是fit。主题分析的文档先要经过分词、文本清洗、标准化、分词文本转换为稀疏矩阵等一系列步骤,然后使用fit方法生成相应的文档主题模型。
设置自定义主题个数为5,每个主题的关键词个数为8,则随机两次运行主题分析程序生成的文档主题及关键词,见表2、表3。
主题数与主题对应关键词数不同,则结果不同。从表2、表3可以看出,即使每次运行时设置的主题数与主题对应关键词数都相同,运行的结果也有差异,使用者可多次运行程序后选择自己认为比较满意的结果即可。
实际上,还可以使用pyLDAvis等Python第三方库,将结果用图来可视化展示。设置自定义主题个数为5,则使用pyLDAvis将结果可视化后如图10所示。
图10展示的是选择主题1后的界面图,图中展示主题1所占的百分比为41.5%。主题1中包括前30个关键词及所占比例(每个主题均包含30个关键词),图10右上部分滑动滑块,可以从0~1调整参数λ的值,λ不同,前30个关键词的顺序和名称会不同。经反复设置不同的主题运行程序后发现,本案例中主题分为3类是一个比较合理的选择,因为此时3类主题合计占比为99.6%,其他主题合计占比为0.4%(在一定程序上可以忽略),同时,各主题所占的比例以及主题与主题之间没有交叉且距离相对适中。3类主题关键词及占比见表4。
(三)项目案例之三:人脸检测与人脸识别
该项目案例旨在体现人工智能课程三大应用(自然语言、语音、图像/视频)之一的图像/视频技术应用,让学生在复杂的项目情境中深刻体会人工智能课程中图像检测与识别的原理和算法,实现高中人工智能课程教材中的“目明”(能看会分析)目标以及高中信息技术新课标的计算思维学科核心素养。该项目代码同样包含了学习Python编程所需的绝大部分语法,同时,又涉及图像大数据爬取和人工智能中图像检测与识别算法的应用。通过该项目的算法讲解、代码训练,既能培养学生的图像大数据与人工智能图像/视频技术应用能力,又能有效培养学生的计算思维。
1. 案例介绍
“人脸检测与人脸识别”项目爬取了网络中的海量人物图片并对选择的部分图片实现了人脸检测及人脸识别。在网络爬虫应用开发中,从新浪网导航“图片”中“时尚”栏目下设的“美容”子栏目(http://slide.fashion.sina.com.cn/b/,2018-12-27)选择图片,使用Python编写的网络爬虫程序(程序代码近50行) 共爬取了30680张人物图片;在人工智能应用开发中,使用Python编写的人脸检测和识别程序(程序代码近170行) ,实现了基于静态图片或动态摄像的人脸检测和识别程序。
2. 人脸检测与人脸识别分析过程及结果
本文中对于静态图片的人脸检测,是通过调用百度人工智能人脸检测与识别aip库中的AipFace模块实现的,调用的方法是detect;对于静态图片的人脸识别,是通过调用百度人工智能人脸检测与识别aip库中的AipFace模块实现的,调用的方法是match;对于动态环境(摄像头刷脸)下的人脸检测和人脸识别,则是通过调用Python第三方库中的人脸识别库face_recognition和计算机视觉库python-opencv联合实现的。
静态图片的人脸检测的效果如图11(a)、(b)所示[图片来自公开的人脸数据集LFW(http://vis-www.cs.umass.edu/lfw/)]。为了避免侵权,本文未使用从新浪网中爬取的图片。
从图11(a)、图11(b)的对比可以看出,图11(b)中被识别的人脸被方形框所标记。应当注意的是,百度人工智能API提供的人脸检测功能对图片中的人脸数目有限制,本文测试结果为检测的人脸数不超过10个。
对于静态图片的人脸识别,假设提供比对的静态图片如图12(a)、(b)所示[图片来自公开的人脸数据集LFW(http://vis-www.cs.umass.edu/lfw/)],则程序运行后显示结果为:照片相似度为91.84%,是同一个人。一般来说,如果照片相似度在80%以上,则被识别为同一个人。
对于动态环境(摄像头刷脸)下的人脸检测和人脸识别,程序运行后显示结果如图13所示。
如图13所示,在动态环境(摄像头刷脸)下,人脸不但被检测到(方形框标记人脸),而且也被识别出来(方形框左下方显示出了被识别者的姓名信息)。
六、结 束 语
新版《普通高中信息技术课程标准(2017年版)》发布以来,笔者一直在思考一个问题:如何让基于学科核心素养的信息技术课程教学真正落地?本文认为,对绝大多数一线教师来说,具有挑战性的是缺乏适合教学应用的、优秀的项目案例教学资源。因为就目前的实际情况来说,优秀的项目案例教学资源太少了。巧妇难为无米之炊,新的信息技术课程倡导基于情境的案例式教学、项目式教学,这些教学方式比以往的教学方式更注重案例资源尤其是项目案例资源的积累和运用。如果能结合大数据背景,开发基于大数据的人工智能应用项目案例,不失为目前高中信息技术课程教学资源建设的一种新思路。通过开发这样的项目案例资源,既解决了优秀的项目案例资源缺乏的问题,又解决了高中信息技术课程中最具挑战性的人工智能课程教学难的问题,从而使基于学科核心素养的信息技术课程教学初步落地,也让大数据、人工智能这些概念不仅仅停留在理论宣传上,更渗透到一线教师日常教学的实践中。由于基于大数据的人工智能应用比较复杂、形式多样,也许本文的研究仅仅只是一个开始。
[参考文献]
[1] 陶皖.云计算与大数据[M].西安:西安电子科技大学出版社,2017:9-11.
[2] 何克抗. 21世纪以来的新兴信息技术对教育深化改革的重大影响[J].电化教育研究,2019(2):5-12.
[3] 国务院.新一代人工智能发展规划[EB/OL].[2019-01-22].http://www.gov.cn/zhengce/content/2017-07/20/content_ 5211996.htm.
[4] 中华人民共和国教育部.普通高中信息技术课程标准(2017年版)[M].北京:人民教育出版社,2018:9-10.
[5] 馬超,张义兵,赵庆国.高中《人工智能初步》教学的三种常用模式[J].现代教育技术,2008(8):51-53.
[6] 李鸣华.案例教学法在高中人工智能课程中的运用研究[J].中国电化教育,2008(2):99-102.
[7] 吴晓如.人工智能教育应用的发展趋势与实践案例[J].现代教育技术,2018(2):5-11.
[8] 赵飞龙,钟锟,刘敏.人工智能科普教育探究——以初中“语音合成”课为例[J].现代教育技术,2018(5):5-11.
[9] 汤晓鸥,陈玉琨.人工智能基础(高中版)[M].上海:华东师范大学出版社,商务印书馆,2018:1-169.
[10] 周德懋,李舟军.高性能网络爬虫研究综述[J].计算机科学,2009(8):26-29,53.
[11] 韋玮.精通Python网络爬虫:核心技术、框架与项目实战[M].北京:机械工业出版社,2017:6-8.
[12] 杨顺安.面向声学语音学的普通话语音合成技术[M].北京:社会科学文献出版社,1994:5-6.
[13] 张斌,全昌勤,任福继.语音合成方法和发展综述[J].小型微型计算机系统,2016(1):186-192.
[14] 于延锁,朱风云,李先刚,等.面向大语料库的语音合成方法研究[J].北京大学学报(自然科学版),2014(5):791-796.
[15] 迪潘简·撒卡尔.Python文本分析[M].闫龙川,高德荃,李君婷,译.北京:机械工业出版社,2018:35-36.
[16] 何之源. 21个项目玩转深度学习:基于Tensorflow的实践详解[M].北京:电子工业出版社,2018:112-113.
[17] 秦鸿,李泰峰,郭亨艺,等.人脸识别技术在图书馆的应用研究[J].大学图书馆学报,2018(6):49-54.
[18] 专知. 第一本人工智能中学教材来了!《人工智能基础(高中版)》编著历程 [EB/OL].[2019-01-27]. https://cloud.tencent.com/developer/article/1143504.
[19] 百度百科.LDA [EB/OL].[2019-01-27].https://baike.baidu.com/item/LDA/13489644?fr=aladdin.
[Abstract] With the release of the new version of Information Technology Curriculum Standards for Senior High Schools (2017 edition), the construction of case teaching resources, especially project case teaching resources with scenarios, complexity, comprehensiveness and practicality, has become an urgent task to be solved. Faced with the serious shortage of project case resources at present, based on relevant researches and from the perspective of AI application in the era of big data, this paper puts forward the framework of AI application development based on big data, and expounds its application development of web crawler and the design of AI application development based on big data. Based on the development framework and the requirements of the "Preliminary Artificial Intelligence" module in the new version of Information Technology Curriculum Standards for Senior High Schools (2017 edition), this paper constructs the design framework of AI application for high school information technology curriculum. Based on this design framework, three AI application cases of audio fiction, text analysis of educational stories, face detection and face recognition are developed by using Python language. Those project cases integrate the typical characteristics of big data and AI application, and have good mobility. Not only can they be used in the "preliminary AI" module and other modules of high school information technology curriculum, but also their design framework provides a solution to the implementation of high school information technology curriculum teaching based on subject core literacy.
[Keywords] Big Data; Artificial Intelligence; Artificial Intelligence Course in Senior High School; Project Case Resources; Design and Development
