一种粒子群和改进自适应差分进化混合算法及在生产调度中的应用
2019-08-29
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
0 引言
随着社会的发展,流水车间调度问题正在引起广泛的关注。流水车间调度问题是指在一定的时间内,对可用共享资源的分配和生成任务进行合理科学的安排,从而可以在较短时间内获取较优的调度方案。求解流水车间调度问题的方法有很多,如人工智能算法、精确求解方法。其中人工智能算法更适合求解车间调度问题,尤其是差分进化算法和粒子群算法。差分进化算法是可以利用种群个体之间的差异从而逐步进化的一种搜索算法[1]。该算法是R. Storn和K. Price为了求解Chebyshev多项式而提出的[2-3],而粒子群算法是J. Kennedy和R. C. Eberhart提出的一种进化算法[4],通过追随当前搜索到的最优值来寻找全局最优,并显示出实际问题的优越性。
本文首先介绍了基于自适应变异算子的差分进化算法,并且分析了此算法的缺点,提出一种粒子群算法和改进的自适应差分进化混合算法PSO_FMDE;最后通过实验分析了该算法的优异性能。接着描述了流水车间调度问题的模型,并且通过实验分析了PSO_FMDE算法求解流水车间调度问题的突出表现。
1 粒子群和改进自适应差分进化混合算法
1.1 粒子群和改进自适应差分进化混合算法
粒子群算法的基本思想是首先初始化种群,计算种群中个体的适应值,然后根据适应值去更新粒子的速度和位置,当前个体通过与种群中最好个体比较跟踪[5-6],从而产生新个体。
对于差分进化算法,首先会通过随机初始化策略把初始种群进行初始化操作,然后随机选取两个不同的个体与互不相同的第三个个体通过线性组合的方式产生一个变异后的新个体,再对新个体通过特定的交叉函数得到交叉后的个体,最后将新个体与当前最优个体比较,从而选出下一代的最优个体。因为标准的差分进化算法变异因子是恒定的,所以在种群初期个体较多进化相对较慢,种群后期个体较少进化相对较快。所以颜学峰等人提出了一种具有自适应变异算子的差分进化算法MDE[7],根据算法搜索进度自适应的变异算子如下:
(1)
其中:F0为变异算子;Gm为最大进化代数;G为当前进化代数。
该算法在种群进化初期具有较大的变异因子值F=2F0,因此初期个体变化较快,个体多样;随着算法的进展变异率逐渐降低,到了算法的后期变异率已经接近于F0,从而避免了最优解的破坏,保留了良好的信息,提高了搜索到全局最优解的概率。该算法和大多数算法一样,虽然具有了种群初期进化较快,种群后期进化较慢的特性[8-9],但是没有考虑到当代个体的适应值是否向着最优个体的适应值逼近,即个体适应值是否朝着最优解的方向发展。假设当代个体经过变异、交叉后, 其适应值并未向着最优个体的适应值逼近,偏离了正确的迭代方向,此时恰巧变异算子却变小了,导致整个子代个体近乎速度放缓,不易快速收敛到全局最优值[10-11]。因此本文提出了一种新的自适应差分进化算子FMDE,其中变异算子F的定义为:
(2)
式中,fi(pre)代表上一代个体的函数值,f(min)代表当代的目标函数最优值,fi(suf)代表当代个体的函数值。如果当代个体适应值与当代最优值的差的绝对值比上一代个体适应值与最优值的差的绝对值要小,说明当代的此个体偏离了最优值的进化方向,这时采用适当增加变异算子F,稍微加快进化速度,但又考虑到变异算子的取值范围,所以采取添加一个单调递减的指数函数的策略[12]。
粒子群算法在优化求解过程中早起具有较快的收敛速度,在后期容易陷入局部最优,难以获得全局最优解。种群差分进化算法会从当前最优个体和经过变异、交叉后产生的新个体中选择一个较优个体作为当前最优个体。只有当适应值优于父代个体使才选为子代,否则父代直接进入下一代,该机制增加了算法的收敛速度。但该算法有陷入局部最优解的缺点,并且粒子群算法和该算法有一定的相似度,因此本文考虑将两种算法结合,首先让两种算法分别迭代,接着为了避免混合算法的迭代后期出现停滞现象,引入一种随机跳出机制,通过一个随机函数使出现停滞现象的个体变成一个新个体,这样就跳出了局部最优,实现如下:
(3)
其中:M表示可以允许停滞的最大迭代次数,(Xmin,Xmax)是可以允许的搜索范围。
因此,本文提出的混合算法PSO_FMDE实现步骤如下:
算法 PSO_FMDE算法
输入:基本的输入参数,包括R1、R2、c1、c2、vmax、itermax、F0、Gm、G等
输出:最优个体最优值
1)对两个种群POPPSO和POPFMDE进行随机初始化,而且位于不同区域。
2)开始迭代,根据公式(1)~(3)对POPPSO种群中所有个体进行位置和速度更新;
3)利用改进的自适应差分进化算法FMDE对种群中所有个体执行变异、交叉、选择操作。
4)分别选择当前迭代中,POPPSO种群以及POPFMDE种群中的最佳个体。
5)选择两个种群中较优的个体,并判断个体是否出现停滞现象,陷入局部最优,如果陷入局部最优,则执行步骤6),否则执行步骤7);
6)根据公式(6)更新个体位置,然后重复计算每个种群中个体适应值,选择较优的个体;
7)判断当前是否达到最大迭代次数或者全局最优位置满足最小界限,如果满足退出条件,输出最终结果并退出,否则返回步骤2);
步骤5中判断当前的结果陷入局部最优,出现停滞现象的方法如下:
(4)
1.2 函数优化测试
为了测试和解释PSO_FMDE算法在求解全局最优问题的性能和优越性,将该算法分别与MDE、FMDE进行了对比,然后对以下的数学优化问题进行寻优[13]。
-5.12≤xi≤5.12,i=1,2,…,10
(5)
优化问题的目标函数在10维可行域内有210-1个局部最优解,差分进化算法可以求解这一问题。为了保证实验的有效性,3种算法的参数尽可能一致,其中种群大小为Np=100,最大进化代数是800。交叉参数CR=0.1,加速常数C1=0.1,C2=0.2惯性权重参数w=0.9,允许的最大停滞次数numpause=10等。
为了研究变异因子对算法的性能影响,变异因子F分别取值0.1,0.5,0.7,1.5,2。图1、图2、图3分别展示了MDE、FMDE、PSO_FMDE三种算法在不同的变异率情况下,最优值与迭代次数的关系。图x轴代表迭代的次数,y轴代表最优值。
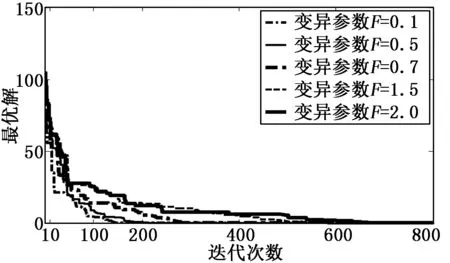
图2 FMDE算法变异参数实验
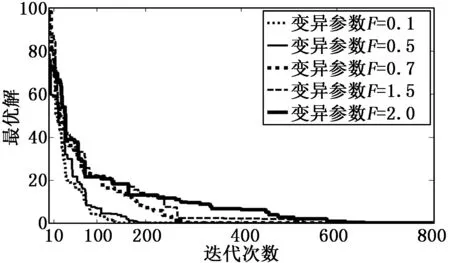
图3 PSO_FMDE算法变异参数实验
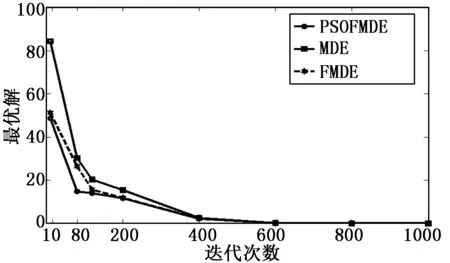
图4 3种算法的性能比较
从三幅图可以看出随着变异参数的增加,会需要更多的迭代次数才能达到最终的全局最优解(即进化结束),比如F=0.1时只需要100次迭代就能进化完成,F=0.7时需要大约250次能完成进化,但是F=2时会需要将近450次才能完成进化,性能逐渐减小。同时也能看出,在固定的迭代次数时,变异率越小,最优解的值就更靠近全局最优解。
图4展示了不同算法在相同变异因子下的性能,此时itermax=1000,F=1.5,通过结果可以看出,在迭代初期(前200次迭代), PSO_FMDE算法能够更快地靠近全局最优解0,其次是FMDE算法。当迭代次数固定时,PSO_FMDE算法到MDE算法靠近全局最优解地速度依次降低,也就是说从PSO_FMDE算法到MDE算法的性能逐渐下降,表明PSO_FMDE算法使群体的平均适应度和最优适应度和其他算法相比都有适当的提高。
2 PSO_FMDE算法求解流水车间调度问题
2.1 流水车间调度问题模型
问题描述:如果要在m台机器上利用n个工件进行流水加工,每个工件需要经过m道工序,每个工件在每台机器上只加工一次,每台机器在某一时刻只能加工一个工件,而且各个工件在机器上所需要的加工时间和准备时间已知,且各个工序都有相应的约束条件,以使工件完工时间最小。
令cik代表工件i在设备k上的完成时间。tik代表工件i在设备k上的加工时间,且cik>0,i,j=1,2,…,n,k=1,2,…,m。该流水车间调度问题的目标函数为:
(6)
约束条件为:
1)设备h先于设备k加工工件i:cik-tik≥cih;
2)工件i先于工件j在设备k上加工:cjk-tjk≥cjh。
2.2 PSO_FMDE求解流水车间调度问题的步骤
差分进化算法求解流水车间调度问题和遗传算法求解车间调度问题类似[14-15],主要分为以下几个步骤:
1)设置差分进化算法的参数,包括最大迭代次数、变异因子等。
2)根据流水车间调度问题,随机初始化两个种群。
3)根据交叉变异或者速度位置更新得到临时种群,对临时种群进行评价。
4)选择较优个体,并判断是否陷入局部最优,如果是则求解公式(3)。
5)并判断满足终止迭代条件。如果满足,根据最优个体得到流水车间调度问题的最佳调度方案;否则进行进化操作,转步骤3)。
2.3 仿真实验
采用标准TA类[16]车间调度问题进行实验测试,设置粒子群算法和改进自适应差分进化的混合算法的种群规模是40,最大进化次数是800。数据集分别选择20工件5机器、50工件5机器以及100工件5机器,在上述3个数据集上进行流水车间调度问题的实验。实验采用Pascal语言编程实现流水车间调度优化算法。
3种算法MDE、FMDE、PSO_FMDE分别对3种不同规模的数据最进行makespan目标最小化,比较几种算法的性能。在测试实验过程中,为了实验结果科学及更具说服力,3种算法分别运行10次,然后分析10次结果的最优值(makespan)和平均值,几种不同规模数据的优化结果如表1所示。
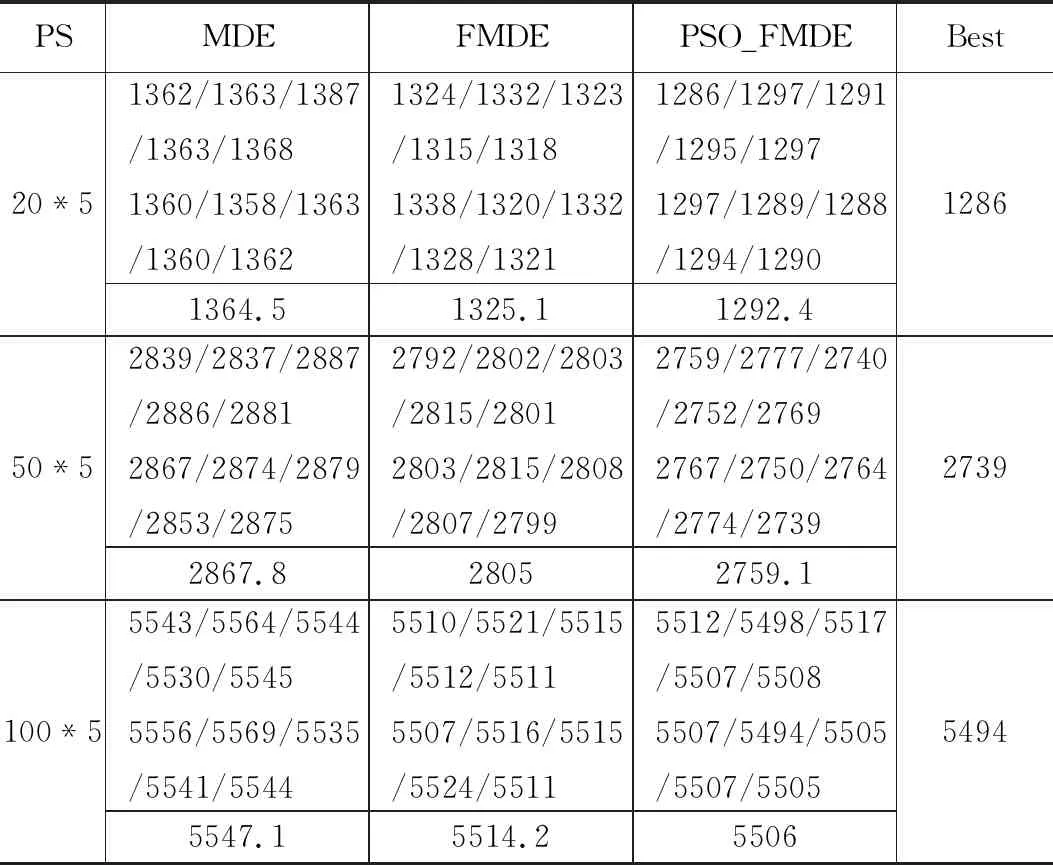
表1 不同规模的不同算法的最优值
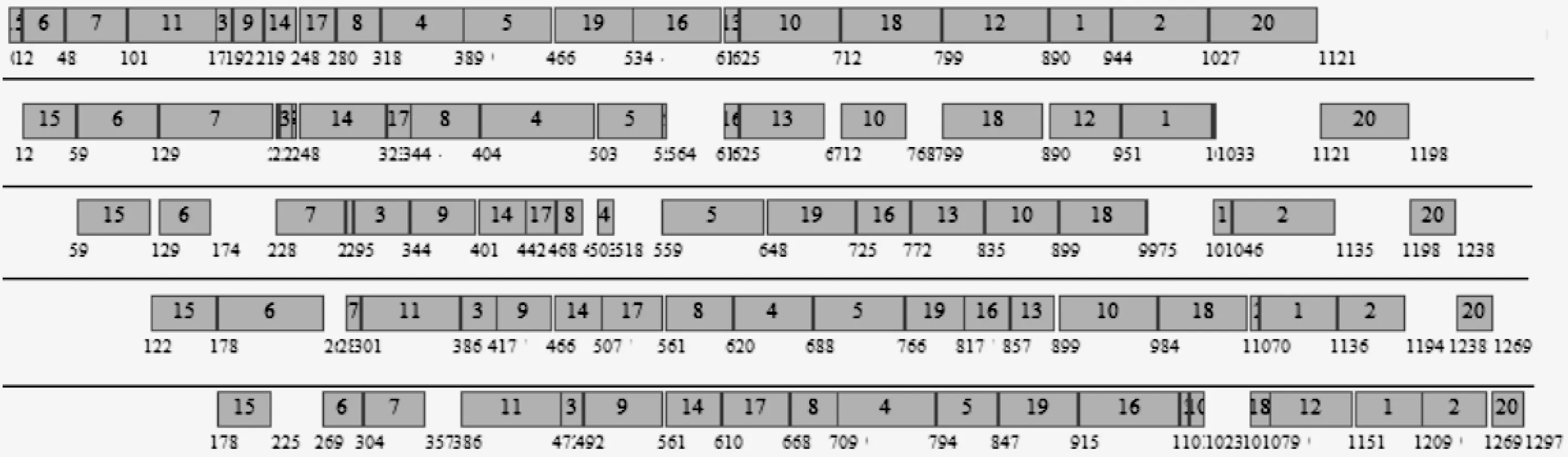
图5 20*5 PSO_FMDE算法的最优调度方案
对于同一个数据规模单从最优值来看,PSO_FMDE算法比其他算法的最优值更理想。为了进一步分析算法性能,将算法平均值(Avg)的差作为评价指标。在3种不同规模的数据集(20*5、50*5、100*5)下,PSO_FMDE算法的平均值与FMDE、MDE算法的平均值差值分别是72.1、108.7、121.1。从差值可以看出,在相同机器数量时,随着工件数的增加PSO_FMDE算法较其他算法的优化强度也随之增加,说明PSO_FMDE算法随着数据规模越大就会越有效。因此,PSO_FMDE算法有着较好的有效性以及稳定性。
图5给出了使用PSO_FMDE算法对规模为20*5的调度集进行优化时得到的第一次计算结果的甘特图。
3 结语
考虑到粒子群算法和改进的自适应差分进化算法的异同,将两种算法进行结合,提出了基于粒子群和改进的自适应差分进化的混合算法。因为进化过程中可能会出现局部最优的问题,因此本文采用随机个体替换停滞个体的方法,以便快速跳出局部最优解区域。通过多种算法的性能对比,较单一算法相比,该有更优更靠近最优解的优势,具有一定的实用价值。为了用PSO_FMDE算法求解流水车间调度问题,将最小化最大完成时间作为调度方案的最优评价指标,因为该算法加快了全局搜索速度和跳出局部最优解的进度,所以具有一定的实践意义。
