复杂背景图像的字符识别算法研究
2019-08-29张红霞白志城付秀娟刚2梅天灿2王学华
张红霞, 王 灿, 刘 鑫, 白志城, 付秀娟, 王 刚2, 梅天灿2, 王学华
(1.武汉工程大学 材料科学与工程学院,武汉 430205; 2.武汉大学 电子信息学院,武汉 430070)
0 引言
随着信息通信技术的迅猛发展, 人工智能涉及生活圈的方方面面, 其中智能化生产就是最常见的。字符刻印是产品的唯一标识, 在大规模的产品生产、存储、检测和装配线上, 产品的字符标记显得尤为重要。通过智能化的设备对现实背景下的产品进行身份识别是智能化生产的基本功能需求。这种字符识别的系统一般包括3个方面: 产品图像的获取与预处理, 字符分割和字符识别。基于字符图像的预处理过程最大程度的优化图像, 获取清晰连贯的字符边缘是字符分割与识别的首要条件, 但是在自然光下获取的图像信息存在部分不满足智能识别要求的缺陷, 如噪声污染, 局部曝光, 字符部分缺失、模糊和变形等, 如何提高这些缺陷字符的识别质量是研究人员一直关注的热点问题[1-2]。
字符识别常用模板匹配和深度学习[3-5], 对于复杂环境下的不同产品而言, 字符识别系统对算法的鲁棒性有着更高要求, 所以单一地运用某种方法不能解决整个问题[6], 字符识别系统各个环节的改进与创新都是当前人工智能的热点。本文通过伽马增强矫正字符图像的对比度, 设计了一种获取曝光区域并进行像素均衡化的局部曝光图像处理算法, 对其进行二值化、膨胀腐蚀、旋转矫正、开闭运算等预处理操作获得较为完整的字符边缘。最后由分步分割获取的字符样本图像构建训练集, 利用Keras模型提供的API接口, 构建了一个三层卷积神经网络, 通过字符识别训练实现了对局部曝光字符的可靠识别。
1 图像预处理
图像预处理能有效控制图像的噪声干扰, 矫正字符断裂, 扭曲变形, 甚至局部曝光等问题, 对于后期字符分割和识别起到了至关重要的作用。本文字符识别系统的整体结构如图1所示。

图1 产品零件表面的字符识别系统简易架构
图2为拍摄某产品零件获取的印刷字符图像, 图像中字符信息包括产品标记符, 字母, 阿拉伯数字以及一些间隔符号等, 且字符中并没有“I”, “Z”, “O” 的字母, 降低了与“1”, “2”, “0” 在字符切割和识别过程中的复杂度。由于拍摄角度和现场环境原因导致图像曝光不均匀, 存在局部曝光过度的情况, 其次背景材料为金属材料, 在空气中容易氧化锈蚀, 导致局部位置存在显著的“暗斑” 和“亮斑”, 增加了图像预处理过程中的噪声; 另外, 字符在印刷过程中由于振动或者速度原因导致部分字符断裂, 部分字符粘连等现象。为了实现这些字符信息的准确识别, 需要对图像进行合理的前处理过程。
1.1 图像伽马增强
不同光照强度下获得的图像背景灰度不一致和细节丢失问题, 采用伽马增强运算s=crγ, 取修正参数γ=0.8,c=1, 将字符图像的背景灰度级即r都增强到一定的像素值范围内即s, 既增强了图像的对比度和亮度, 也保证了后期局部曝光过程的灰度变换等操作。利用图2(a)所示的图像进行伽马增强之后得到的灰度图像如图2(b)。

图2 产品零部件印刷字符图像及灰度图
调整γ=p/10,p=1,2,…10, 随着γ的增大, 图像的背景颜色不断加深, 二值化字符图像边缘断裂情况越明显。当γ<0.6时, 字符局部曝光区域与背景像素值相近, 字符边缘不易识别; 当γ=0.8时, 如图3背景像素值集中在130~200之间, 使得像素值i∈(0,130)的点得到减弱,i∈(130,200)的点得到增强,i∈(200,255)的点保持不变. 伽马增强拉伸了图像中灰度级较低的区域, 同时压缩了灰度级较高的部分, 从而保留了字符边缘点的像素值, 确定了所有字符图像局部曝光区域的及处理。
1.2 局部曝光处理
图像的灰度直方图表明背景灰度值明显存在分布不均匀现象[7-9], 伽马增强后图像像素值大部分集中在在130~200范围内, 若像素分布相差较大直接二值化会导致噪声影响字符的边缘检测, 轮廓被噪声覆盖或者断裂。如图4(a)为阈值T=170时字符图像的二值化效果图, 可以看出背景噪声与字符区域相互作用形成字符联通或断裂, 难以进行字符的自动分割。需要对图像进行分块操作, 解决局部曝光造成的分割问题[10]。
1.2.1 图像分块操作
图2(a)可以看出单个字符所在的局部矩形方块内的像素点个数是在一定的范围内分布。过少的像素点数则表示较暗的区域, 需要保留其原像素值或者增大像素值以达到背景均衡化; 过多的像素点数则表示噪声聚集区, 需要分离背景与感兴趣的字符区域, 降低背景像素值。为了找出感兴趣区域(ROI)即局部曝光区域, 可以对整体图像(1 895×417像素)进行分块处理, 图5为分块原理图。

图5 字符图像分块原理图(单位: 像素)
从字符大小和噪声区域观察分析判断块高H在一个字符高度, 块宽W≈2H时, 能最有效保证完整的字符边缘和局部曝光操作, 对噪声的处理也比较细致。对不同块的个数进行试验发现, 取整块数目为5×10时, 相同二值化阈值下有较好的二值化效果, 增大分块数量导致基于像素点的操作时间长, 计算复杂度高而且不能保证单个字符边缘的完整性。减小分块数量不能保证局部曝光块的细致处理。
1.2.2 确定局部曝光区域
感兴趣区域即曝光区域定义为在一个块区域内, 像素值i大于整幅图二值化阈值的像素点个数Q超过该块区域面积S的50%, 则这个块为感兴趣区域(ROI)。基于全局分块化确定感兴趣区域的方法可以保证应对不同曝光图片时算法的自适应性。分块是基于像素点, 整个区域在纵向和横向的分块上会存在余留区, 在图像的噪声处理时余留区也需要同时处理。
1.2.3 对曝光和非曝光区域进行不同噪声处理
非曝光区域也定义为标准分块区。为了简便操作, 将纵向和横向余留区划分为感兴趣区域, 分两段式处理整个区域, 如公式1-1。确定曝光区域后因为背景的灰度不均匀性, 需要做出不同灰度级处理, 以每个块的像素值imin为阈值将两段式函数再次细分处理。
f1j(i)=K1×i,imin∈(0,100)∪
(100,120)∪(120,130)∪(130,140),
f2j(i)=K2×i,imin∈(0,140)∪
(140,160)∪(160,255),j=1,2,3…
(1)
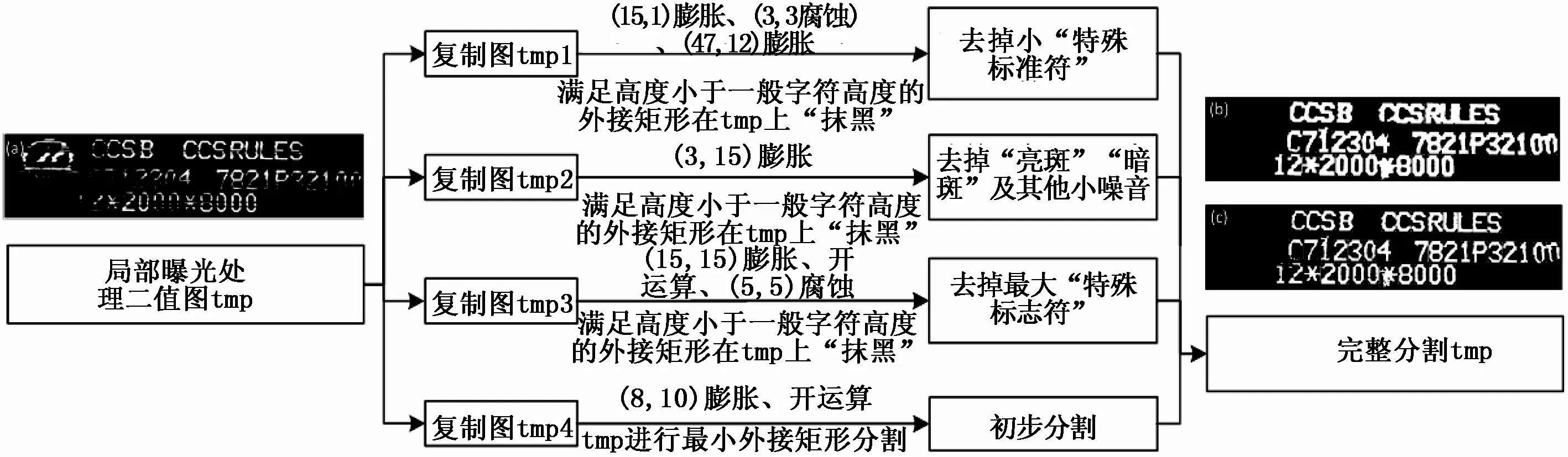
图6 字符图像分割详细流程图
f1j(i)中j=4,f2j(i)中j=3,K1与K2为矫正常数。j值越大, 则图像像素值分类越细,j值越小, 则图像像素值分类越疏。伽马增强后像素值集中分布为130~255,较低的像素值分布代表“暗区域”, 较高的像素值分布代表“亮区域”, 增加较低的像素值, 降低较高的像素值, 以T为阈值重新分布阈值, 定义c|=i/10, 统计对应c值的概率pc=nc/n(nc为c值对应的像素数,n为该块的像素总数)。通过概率分布将像素值做出如表1的矫正。
1.2.4 二值化
矫正后的像素值依次按照原像素点的位置处理原图, 得到相同阈值下二值化图如图4(b)所示。局部曝光区域噪声有了明显的减少, 且依旧保持字符的清晰边缘, 锈蚀区域导致的字符边缘串联消失, 在一定程度上解决了因局部曝光造成字符难以分割的影响。
2 字符分割
字符分割不仅要保证字符边缘的完整性且需整齐归一化, 才能保证整个流程的稳定性和广泛适用性[11-12]。图4(b)可以清晰看出部分字符边缘的缺失断裂, 以及不需要识别的产品标记符。为了稳定快速的读取字符信息, 对“特殊标志符” 和“有效的单个字符” 依次进行分割, 使得整体分割图像中不存在干扰标记, 单个字符互不关联。
2.1 去掉“特殊标志符”
除了需要识别的字符外, 字符图像还包含产品特定即特殊的标志符不在识别范围内, 为了避免不必要的分割误差和识别错误率, 将“特殊标志符” 在分割过程中直接“抹黑”。“特殊标志符”具有面积大, 宽和高的数值较大, 像素点之间存在断裂, 与字符距离较远的特点。结合OpenCV机器视觉库的封装接口利用数学形态学的膨胀、腐蚀和开闭运算, 去掉高度小于标准字符高度的一般“特殊标志符”及预处理未完全去除干净的“亮斑”、“暗斑” 和最大高度的“特殊标志符”等, 详细的字符分割流程图如图6。
2.2 单个字符的分割
初步分割之后的图像存在部分字符“粘连”, 如图6(b)所示。为了防止识别过程出现多个字符连接导致的互相干扰的情况, 以除字符“1”以外的最小字符的宽为标准宽ws, 当最小外矩形的宽w/ws取整m时分别将最小外接矩形进行等分分割, 如公式(2)和(3), 并将每个字符左右裁边2个像素值截取保留。

表1 像素值矫正中的k值
确定粘连字符的最小外接矩形的宽度w:
m=|w/ws|,m=1,2,3…
(2)
已知粘连外接矩形的点(x,y), 宽w, 和高h, 分割第i个最小矩形的参数:
(3)
由于最小外接矩形中字符“1” 的宽度最小, 其他字符的印刷宽度是一致的。以除“1” 外最小宽度的字符为标准既排除了其他字符因印刷不规范或拍摄角度导致的宽度变形, 又保证了分割过程中m取整的标准性。整体分割后的部分单个字符图像如图7(a)所示。
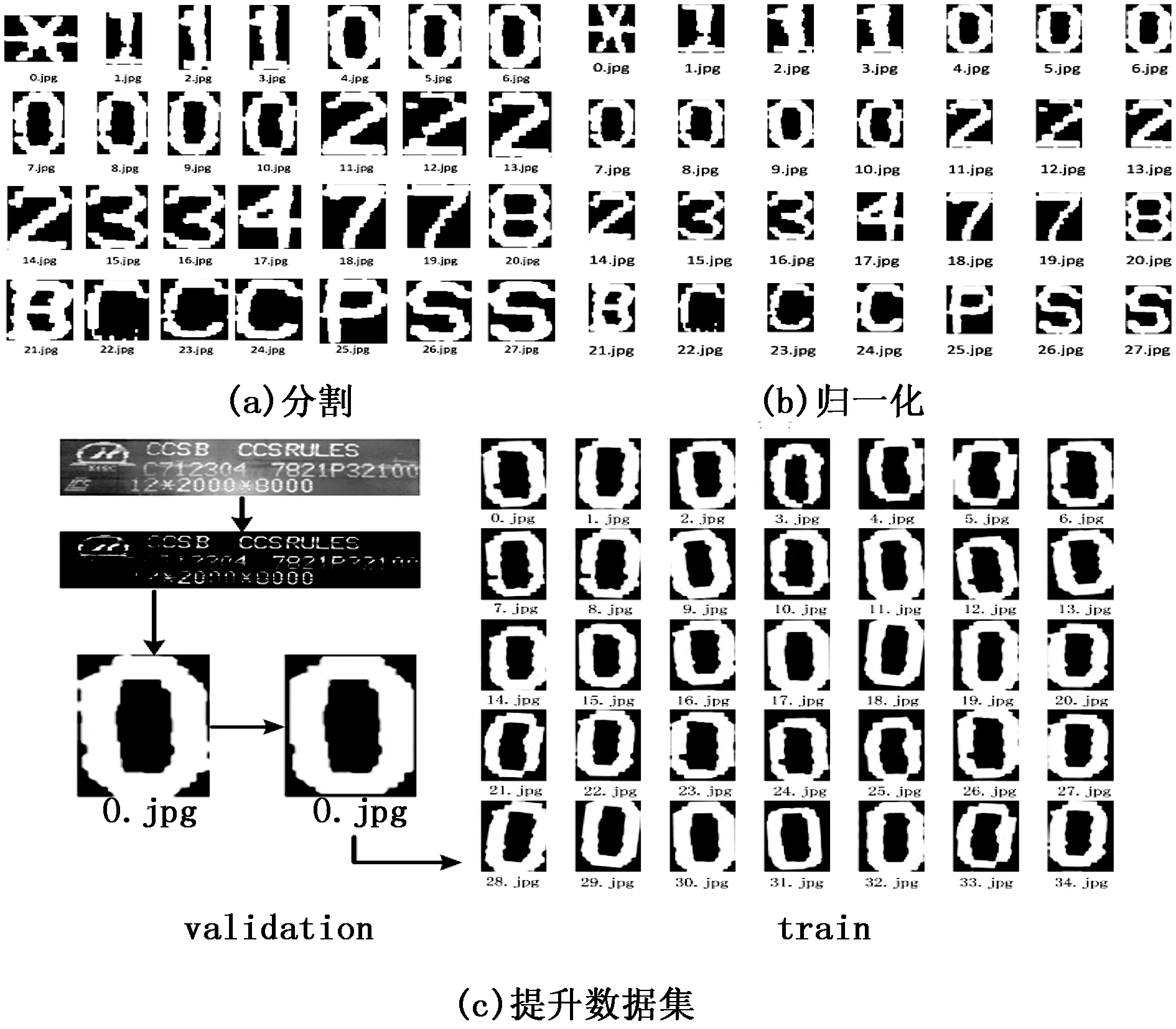
图7 字符图像分割效果(部分字符)
3 字符识别
字符识别常用模板匹配和神经网络两种算法。模板匹配算法计算量大, 匹配过程要求严格; 卷积神经网络(CNN)对高维数据处理高效, 特征分类效果好[13-15], 可用于识别各种物体。由于实验待识别的图片数量少, 分割之后待识别字符的数据集小, 实验表明CNN网络也适用于小数据集的训练, 有较高的识别率。
3.1 准备训练集、验证集与测试集
统计7张待识别图片的分割字符, 部分字符“I”, “Z”, “O” 等因字符间相似不存在印刷和识别过程, 整理把数据集分为27类, 形成每类含有7~20张不等的测试集。为了尽量利用有限的训练数据, 通过Keras提供的ImageGenerator函数对原始样本图像实现一系列旋转、移动、剪切变换、放大缩小, 水平变换等随机变换, 将数据集进行提升, 如图7(c)。训练模型中不存在两张完全相同的图片, 有利于抑制过拟合, 使得模型的泛化能力更好。提升后形成每类有110~200张不等的训练集, 将训练集和验证集的比例控制在10:1左右。
整理所有字符文件, 将图片格式保存成单通道的二值化图片, 白字黑底, 并将所有图片归一化到60×40像素值大小的格式如图7(b), 降低计算复杂度, 保证后期模型训练。
3.2 搭建与训练模型
卷积神经网络可对图像进行正确的分类, Keras模块是基于Tensorflow、Theano等后端的高层神经网络框架, 可在CPU和GPU之间无缝切换, 执行效率高。由于27类小数据集的应用, 所以模型使用简单的三层卷积网络结构, 数据模型采用Sequential模型。
Sequential模型是是单输入和单输出型简单模型, 层与层之间只有相邻关系。在本实验中搭建的3层卷积网络中加上激活函数ReLU, 最后接池化层max-pooling和2个全连接网络Dense, 以单个神经元和激活函数Softmax结束模型, 这种配置会产生多分类的结果, 为了与这种配置相适应, 使用categorical_crossentropy作为损失函数。利用.flow_from_directory函数从jpgs图片中直接产生数据和标签, 并根据这个生成器来训练网络, 网络结构如图8。

图8 Keras卷积网络结构
4 数据分析
训练集4490个字符文件, 验证集230个字符文件。模型训练反复调整参数, 定义batch_size=256, epoch=70。在CPU上训练这个模型的loss、acc、value_loss和value_acc与epoch的关系如图9所示。loss和value_loss随着epoch的增大依次减小, 不断趋近于0; acc和value_loss随着epoch的增大依次增大, 不断趋近于1。
随机连续取5次epoch的数据如表2所示, 当epoch=65时, 准确率高达96.91%, 损失值低为0.0969, 实验表明随着epoch的增大, 损失值越来越小, 准确率越来越大, 且训练集和测试集近似相等。记录得到每个epoch在CPU上耗时80~150 s。训练的模型稳定良好, 可以保证字符全部识别, 速度快且准确率高。
5 结束语
系统由VS2015开发平台采用C++编码, 在CPU主频3.2 GHz, 8 G内存的Windows 7(64位)电脑平台上开发实现并测试识别效果。结合OpenCV机器视觉库和Keras的高层神经网络API, 本文对局部曝光的工业零部件印刷字符进行取图, 曝光预处理, 单个字符的分割, 图像归一化和CNN神经网络识别处理, 从像素值的参数调整上解决了局部曝光和自然环境下背景污染问题, 并以小数据集的提升构建神经网络模型, 实现了小数据集下的96.9%的正确识别率。
