YOLO9000模型的车辆多目标视频检测系统研究
2019-08-29
(西安工程大学 电子信息学院,西安 710048)
0 引言
针对现如今高交通流的信息发展时代下,道路交通拥堵问题及车辆信息识别的需求,智能交通系统[1]成为解决此类问题的有效手段。在此背景下,我们必须对车辆的微观信息进行有效采集。车辆检测是智能交通系统数据前端采集的一个重要环节[2],同时作为目标检测技术的一个具体应用方向,基于机器学习的车辆检测更是近年研究热点。而深度学习[3]作为机器学习中重要的一部分,在未来车路协同环境和微观交通对象信息提取的工程应用中,在进一步提高检测率、鲁棒性的车辆多目标实时检测系统中提供了良好的技术基础。
文献[4]中,Szegedy等人采用深度学习的方法在VOC 2007数据集测试结果中使mAP达到了30%;R-CNN[5]则将传统机器学习和深度学习结合起来,有效的将mAP提升至48%;不久Uijlings等人通过修改网络模型的结构将mAP提高到66%。随后通过进一步优化目标检测网络模型结构,出现了SPP-Net[6]、Fast R-CNN[7]、Faster R-CNN[8]、YOLO[9]等,mAP变化如表1所示。YOLO与传统依赖先验知识的特征提取算法不同,它是采用深度卷积神经网络的全新实时目标检测方法,对几何变换、形变和光照具有一定程度的不变性,进一步的将mAP提升到了78.6%,改善了车辆外观多变带来的影响,使检测系统具有更高的灵活性和泛化能力。
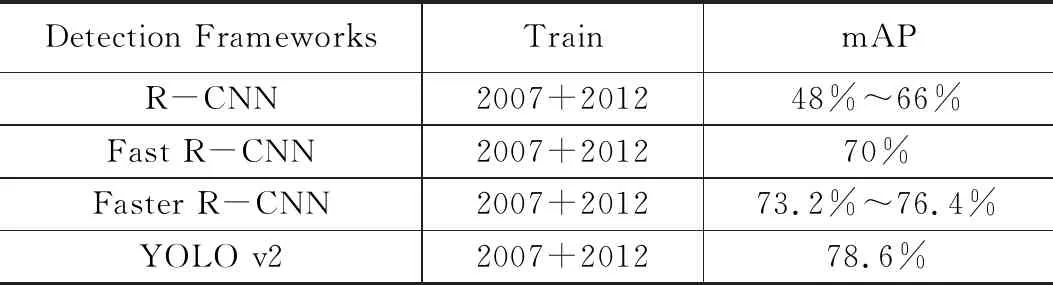
表1 mAP变化
本文针对车辆多目标检测系统中,车辆外形、车体结构以及道路场景复杂等变化导致的检测率低的问题[10],利用Darknet深度学习框架的YOLO9000算法,对本文构建的多目标车辆VOC数据集进行特征训练学习,进一步对网络模型进行改进和参数的调整,最终得到本文改进的车辆多目标实时检测模型。
1 YOLO9000算法
YOLO9000是采用YOLO v2 + join training算法,在ImageNet上进行预训练后,采用我们的数据集开始训练模型。将数据随机旋转或调整色度和亮度等进行数据增强,对训练目标进行卷积池化的特征提取,进而得到我们的车辆检测模型并进行视频检测分析。训练流程如图1所示。
1.1 基于YOLO 9000模型的的目标检测算法
YOLO9000是一个实时物体检测系统,可以检测9418个对象类别[11]。YOLO9000的设计理念遵循端到端训练和实时检测:它把一整张图片一次性应用到一个神经网络中去,网络会把图片分成s×s个不同的单元格,对每个单元格进行训练学习,若车辆的中心点落在某个单元格内,则相应的单元格负责检测该车;我们设置阈值为0.25,在输出的特征图上,对每个单元格进行直接位置预测,输出置信度评分超过阈值的检测结果。通过WordTree产生所需要的B个bounding boxes的位置,每一个bounding box获得5个坐标预测值:分别为(tx,ty)、(tw,th)和一个置信度评分,目标回归如图2所示。
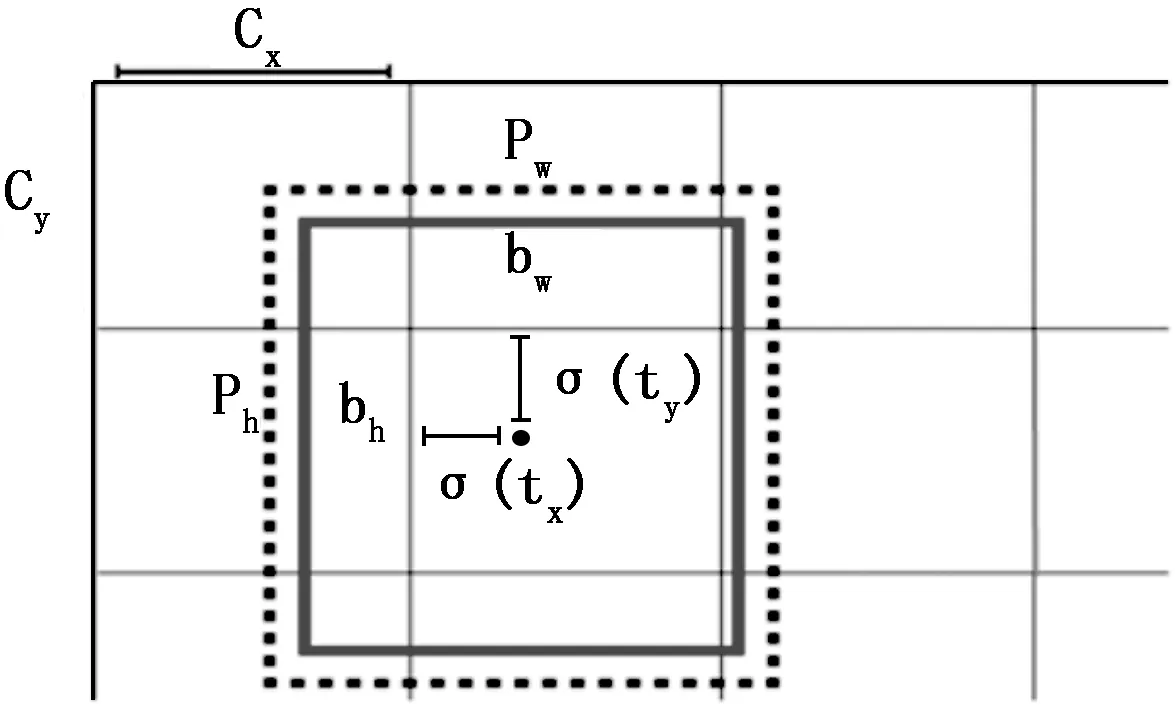
图2 回归目标
(tx,ty)是每个bounding boxes的中心距离其所在单元格边框的偏移坐标位置,(tw,th)是bounding boxes的真实宽高相对于整幅图像的比例,单元格距离图像左上角的边距为(cx,cy),单元格对应bounding boxes维度的长和宽分别为(pw,ph)。则bounding boxes的真实位置预测如式(1)所示:
bx=σ(tx)+cx
by=σ(ty)+cy
bw=pwetw
bh=pheth
(1)
置信度评分是通过出现的bounding box与对应待检测车辆目标的概率以及bounding box和车辆目标真实位置的IOU积的关系对该bounding box位置预测的精度进行表示,其具体计算如式(2)所示。
(2)
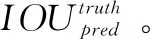
除此之外,YOLO9000算法中每个单元格还将产生有且仅有一组包含C个条件概率Pr(Classi|Object)的概率集,此概率集将用于目标最佳位置的确定。
1.2 YOLO9000多目标检测模型改进
YOLO9000使用WordTree整合数据集之后,在数据集(分类-检测数据)上利用层次分类的方法训练模型,使该系统可以识别超过9000种物品[11],本文是用于车辆多目标的检测系统设计,因此只有一类目标——车,去掉了层次训练方式。YOLO9000模型与VGG模型类似,使用3×3的滤波器在每次池化之后将通道数加倍,并采用batch normalization 来稳定训练,加速收敛,正则化模型。YOLO9000的模型结构简化到了24层,第23层是17×17,和之前YOLO v2的13×13类似,只是把输出预测网格变成了17×17,网络结构如图3所示。
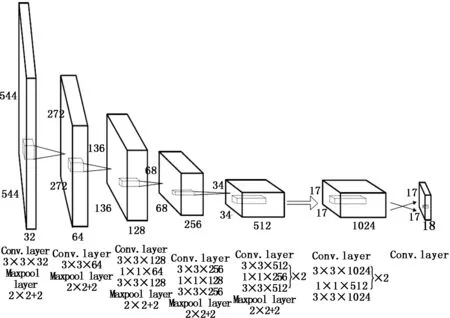
图3 YOLO9000模型框架
在深度卷积神经网络中,route层起连接作用,可以进行层的合并为网络带来更细粒度特征[12];reorg层可以将这些特征与下一层的特征尺寸相匹配,即match特征图尺寸。因此,本文在YOLO9000网络结构的15层后添加一个route层,16层后添加一个reorg层和一个route层,本文命名为YOLO9000_md(YOLO9000_multi-target detection)网络模型。
2 实验结果及分析
2.1 实验准备
车辆检测系统硬件配置为:西安工程大学深度学习工作站的服务器容天SCW4750,采用一个CPU Intel i7-5930,4个NVIDIA GeForce TitanX 12G,8个8G内存。YOLO9000算法的程序设计语言为C++语言,操作系统为Ubuntu16.04,深度神经网络参数配置平台为Darknet框架,整个开发环境为Ubuntu16.04+Opencv 3.1.0+CUDA 8.0+CUDNN5.0,配合应用基于深度卷积神经网络的GPU加速库CUDNN,对数据进行快速训练及实时性验证。
基于CNN[13]的车辆检测方法需要从大量样本中学习车辆特征,若样本集不具有代表性,很难选择出好的特征。为保证数据的多样性,本文分时段对同一目标路段(西安市碑林区金花南路19号西安工程大学立交桥)进行图像采集。同时,根据光照和车流密度的不同,文章采集了早上6:00-7:00的自由流(车辆数<300辆/小时)、9:00-11:00的同步流(300≤车辆数≤900辆/小时)、7:30-8:30的阻塞流(900<车辆数<1300辆/小时)等[14]车流密度条件下的三组数据组合成一个混合样本(由训练集和验证集组成),获取样本如图4所示(部分)。将训练样本按80%和20%的比例随机分开,用于模型的训练和模型性能的验证(见2.2.1节)。

图4 混合数据样本
2.2 实验结果分析
2.2.1 训练结果验证分析
本文使用在ImageNet上预训练得到的网络模型对YOLO9000和YOLO9000_md模型进行参数调整,将我们制作的车辆VOC数据集导入模型,在GPU加速情况下训练1小时后,获取了迭代20000次之后的检测模型。我们将初始学习率设为0.001和0.0001,在迭代2000次、6000次和15000次时以之前的0.1倍来改变学习率,保存迭代10000次和20000次的不同权重模型,将训练结果进行实验对比分析。
1)Loss曲线分析:
图5为YOLO9000模型和YOLO9000_md模型训练时的Loss曲线图。子图(a)是YOLO 9000模型以0.0001的初始学习率在迭代1000次时的Loss曲线图,其训练开始由于学习率过小发散比较严重,在迭代接近400次逐渐趋于收敛;子图(b)是将学习率调整为0.001后的Loss曲线图,对比图(a)明显训练开始抖动降低,并且在迭代200次时就迅速收敛,但是两条曲线开始摆动都处于发散状态,且Loss最大值都达到了2000多;子图(c)是YOLO9000_md模型以0.001的初始学习率训练时的Loss值,训练时一直处于收敛状态比较平稳,Loss值一直在300以内,并且在迭代400次后逐渐无限趋于0。虽然图(b)YOLO9000在收敛速度上具有优势,但在检测实验过程汇总中发现,前期收敛速度的微小差别对后期检测效果影响较小。因此做了进一步的验证。
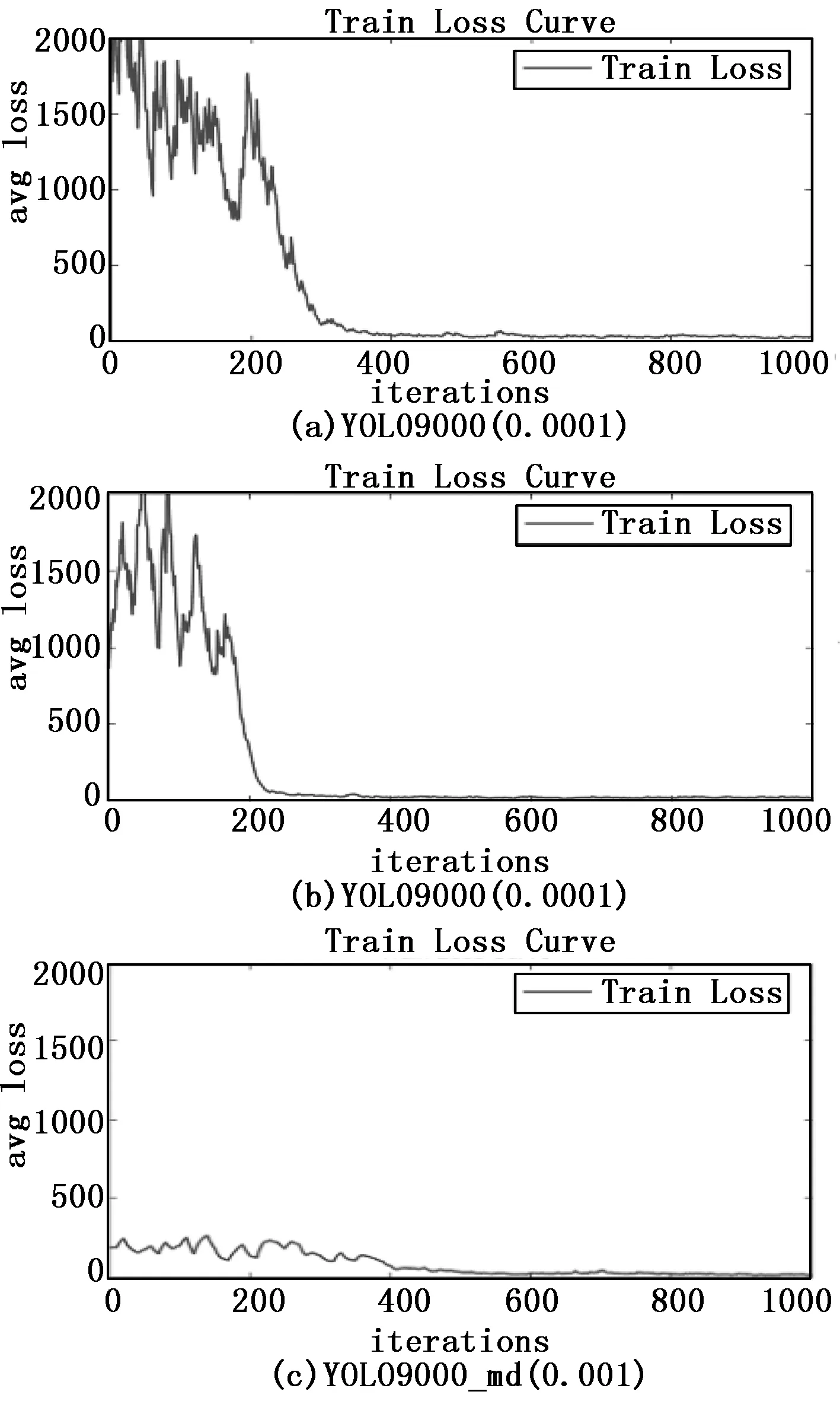
图5 Loss 曲线图
2)准确性分析:
我们进一步对验证集进行测试的结果如表1所示。其中,Total表示实际有多少个目标包围框,即待检测实际目标个数;Correct表示正确的识别出了多少个包围框,就是我们在检测一张图片时,网络模型会检测出很多目标包围框,每个目标包围框都有其置信概率,概率大于阈值的包围框与实际的目标包围框计算IOU,找出IOU最大的包围框,如果这个最大值大于预设的IOU的阈值,那么Correct就加一;Proposal表示所有检测出来的包围框中,大于阈值的包围框的数量;Precision表示精确度如式(3)所示;Recall表示召回率,是检测出车辆的个数与验证集中所有车辆个数的比值,如式(4)所示:
(3)
(4)
由表2可知:在验证364个目标时,以0.0001的初始学习率得到的YOLO9000模型可准确检测出314个车辆目标,其Precision只有76.77%,Recall值是86.26%;以0.001的初始学习率得到的模型其Precision值提升到了89.03%,同时Recall提高到了95.88%;改进模型YOLO 9000_md以0.001的初始学习率训练后得到的验证结果显示,其Precision和Recall值同时提升了0.2%以上,达到了很好的折中效果。
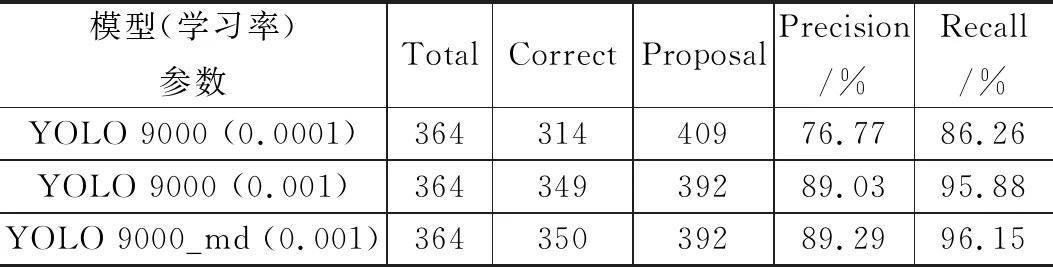
表2 测试结果
3)检测结果分析:
为进一步验证模型在实际交通视频视频检测中,训练的不同权重模型对检测结果的影响。本文将YOLO9000模型以0.001的初始学习率在经过半个小时的训练后得到了迭代10000次的权重模型,一小时后得到迭代20000次的权重模型,将不同的权重模型进行车辆多目标的检测,对检测结果进行了直观的对比,如图6所示。

图6 YOLO9000模型
对比图6实验结果,YOLO9000迭代20000次检测效果优于10000次结果。子图(a)的第一张右后方、第二张中间下方对比子图(b)存在明显的漏检情况;第一张右下方将背景误检为了车辆目标,第三张中右后方将地面杂物也误检为了车辆;这是由于预测框与检测出的标记框即IOU数值存在较大差异。分析可知,迭代次数在同等条件下较多的迭代次数,将获得更好的检测效果,但对于资源的耗费将更多。
2.2.2 视频下的多目标实时检测结果分析
因YOLO方法受训练样本影响较大,需要样本多样性且具有代表性,在应用本文采集的组合不同车流密度得到的样本训练模型之后,为验证其在交通视频下检测结果都具有准确性,本文根据之前实验结果(详见2.2.1),以0.001的初始学习率用YOLO9000和改进YOLO9000_md模型将采集到的视频图像进行实时检测如图7所示,最后得出其测试结果的混淆矩阵。混淆矩阵主要用于比较分类结果和实际检测结果,可以把分类结果的比例显示在一个混淆矩阵里面,进而分析图像检测分类的准确程度。结果如图8、图9所示。

图7 视频检测结果
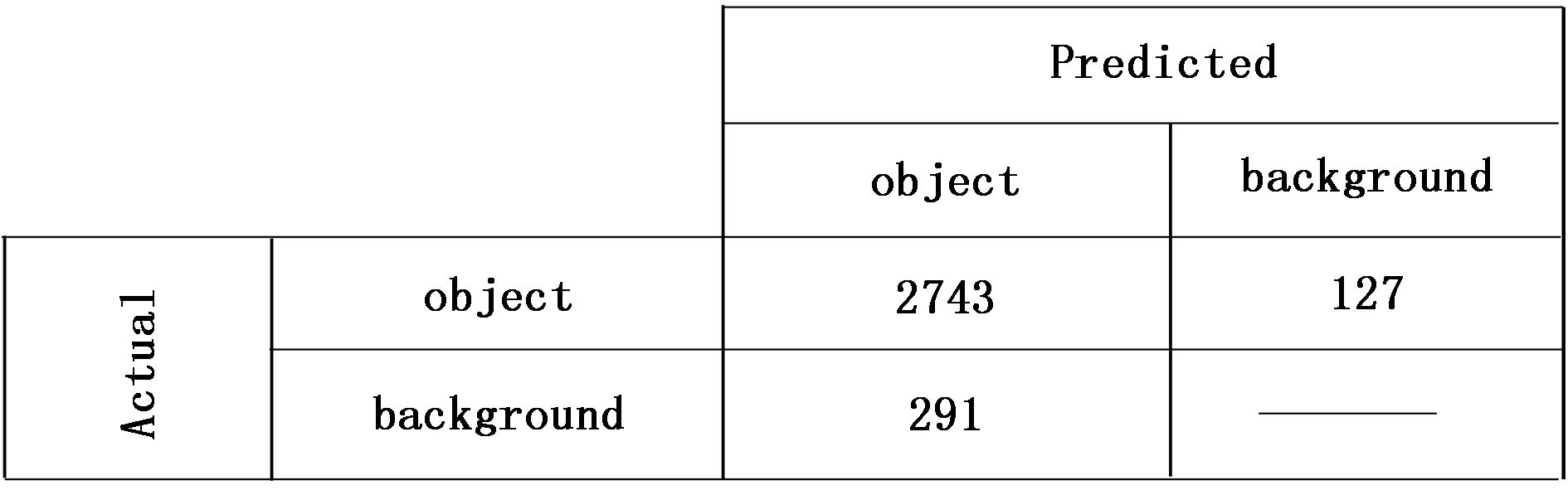
图9 YOLO9000_md模型
在交通视频的检测中,可以很好地检测出视频中的车辆,如图8所示。我们一共提取到了673张图像,一共包括2880个待检测目标,由图9可知,YOLO9000模型将背景检测为车辆的有142个,也就是误检;而将车辆目标没有检测出来303辆,也就是漏检;最终正确检测出车辆目标2738个。相比图8,图9改进YOLO9000_md模型正确检测出目标2743个,比YOLO9000模型的正确检测出的目标多了5个,同时对做到了很好的处理误检和漏检情况做了很好处理,情况也有所减少。因此,针对视频下的多车辆目标实时检测,本文训练获得的YOLO9000-md模型具有更好的检测效果。
3 总结
本文针对城市多车道中多目标视频检测问题,利用深度学习的Darknet框架下的YOLO9000目标检测算法,通过对YOLO9000模型参数的分析,根据车辆目标特征及其运动特征,进行不同网络结构的训练和对比,提出了一种能够获得较准确检测结果的YOLO9000-md网络模型,该模型将目标检测问题转换为目标的二分类问题,通过大量的试验,获得了以组合不同车流密度的车辆作为训练集,基于YOLO9000-md网络结构模型选取2000次迭代的视频下多车辆目标检测方法。文章最后,对所建立模型进行了实测实验,通过实验结果的多种分析发现:本文改进的YOLO9000-md模型的实验结果正确率可以达到96.15%,相比于传统的机器学习,无论在准确率或者运行效率上都得到了大大的提高;对比经典的YOLO9000模型可以看出,YOLO9000-md模型在获得较好Precision值的条件下损失的Recall值明显较小;同时最终检测结果更好,普适于视频下的多目标检测,虽正确检测结果相差不远,但效果良好。
