K-means聚类算法性能分析与优化研究
2019-08-27杨柳
杨 柳
(西安电子工程研究所 西安 710100)
0 引言
随着信息技术的高速发展,数据对社会生产与生活中诸多领域的影响越来越突出,大量的数据应用于军事及民用领域中,数据与生产生活的关系愈发紧密。如何从海量数据中提炼出有用的信息使其更好地服务生活,成为当前面临的难题。因此,数据挖掘技术在各行各业得到迅速地发展。数据挖掘技术是指从大量、无规则、有噪声数据中挖掘出有价值的信息。聚类算法是数据挖掘的重要组成部分,是将数据以无监督方法,根据数据的特征划分成多个簇,数据聚类分析是对数据进一步处理的基础。常见的聚类的方法包括层次方法、划分方法、网格方法、密度方法、模型方法[1]。
K-means聚类算法属于划分方法,是一种经典的聚类算法,具有简洁易懂、快速有效等优势,近年来受到广泛关注。本文介绍了K-means算法的原理和实现过程,分析了K-means聚类算法的性能以及不同因子对K-means聚类算法的影响机理,为无监督聚类过程的设计与应用提供了理论指导。
1 数据聚类问题概述
聚类是指将数据集分成若干个不同的簇,同一簇内的数据相似度尽可能大,不同簇的相似度尽可能小。假设数据集A,A={a1,a2…aN},其中N代表数据集中数据对象个数。聚类是把A中N个数据对象划分成k个簇{C1,C2…Ci…Ck},Ci表示第i个簇。聚类后的结果集表示为X[2]:
(1)
聚类问题的基本流程是,首先提取对象特征,判断特征之间的相似程度。然后选取合适的聚类算法进行聚类,最后进行结果验证。聚类分析是在无先验知识的前提下进行聚类,在没有训练集条件下以数据之间的相似度差异将数据划分成若干簇。数据差异性一般取决于数据之间的某种距离,依据数据的性质可以采用不同的距离,常用的欧式距离表示如下:
d(ai,aj)=
(2)
其中d(ai,aj)表示数据ai和aj之间的欧式距离,p表示数据ai的维度。
准则函数通常用来评价聚类质量,恰当的准则函数能够有效促使相似度大的数据分配到同一个簇中,相似度低的数据分配到不同的簇。聚类算法中常见的准则函数包括误差平方和准则、加权平均平方距离和及类间距离和准则等,其中误差平方和准则Jc表示为:
(3)
式中nj是类Cj中对象的个数,mj类Cj的平均值,定义为
(4)
Jc可以用来描述N个数据对象需要划分成k个类时,所产生的总的误差平方和。Jc越大说明总的误差平方和越大,表示聚类效果不好,所以应让其值尽可能小。当各类样本比较密集且样本数目悬殊不大时使用误差平方和准则较合适。
2 K-means聚类算法
基于划分方法的聚类算法是将数据点的中心作为簇的质心,根据数据之间的相似性度为标准,使同一个簇内数据尽可能相似。划分方法首先任意分配初始聚类,然后不断地迭代改变每一次聚类分结果,但是要求每一迭代的聚类效果要优于上一次。划分方法运行速度快,原理简单,容易实现。K-means聚类算法是基于划分方法的一种典型代表[2-4]。
K-means是一种动态迭代聚类算法,其中K表示类别(簇个数),Means表示均值。K-Means利用数据点均值进行聚类。K-means算法开始执行之前需要给定参数K,确定数据集中簇的个数。然后确定K个类的质心,一般随机选取K个数据作为簇的初始质心。接着执行数据聚类进程,计算剩余数据点到初始簇质点的相似程度,该相似程度可以使用距离或其他数据属性特征,根据相似程度分配数据点到距离最近的簇中,接着重新计算当前簇中的所有数据点的均值,并依此均值作为簇的新质心,重复计算每个数据点到当前簇质心的距离,直到聚类中元素不再改变或是准则函数收敛到某一个值,算法结束迭代。
3 K-means算法的具体流程
1)在所有数据样本中随机选取K个数据对象作为初始聚类中心,c1,c2…ck;
2)遍历所有数据,计算每个数据点相对各个聚类中心的欧氏距离d(ai,cj)(1≤i≤N,1≤j≤K);
3)根据距离d(ai,cj),将每个数据划分到距离最近的中心点所属类中;
4)计算每个簇的平均值,并作为新的中心点,参考公式(4);
5)重复步骤2)~ 4),直至准则函数收敛,或执行了足够多的迭代。
4 聚类初始质心对聚类的影响
在K-means算法中,动态迭代依赖于随机选取的K个初始聚类质心,算法每一次聚类结果都不相同。当K个质心分布在数据点集的各个簇中时,聚类效果良好。当某个簇中包含两个聚类质心,且簇间离较远时,就会导致簇的分裂以及另外两个簇的错误合并,聚类效果较差。
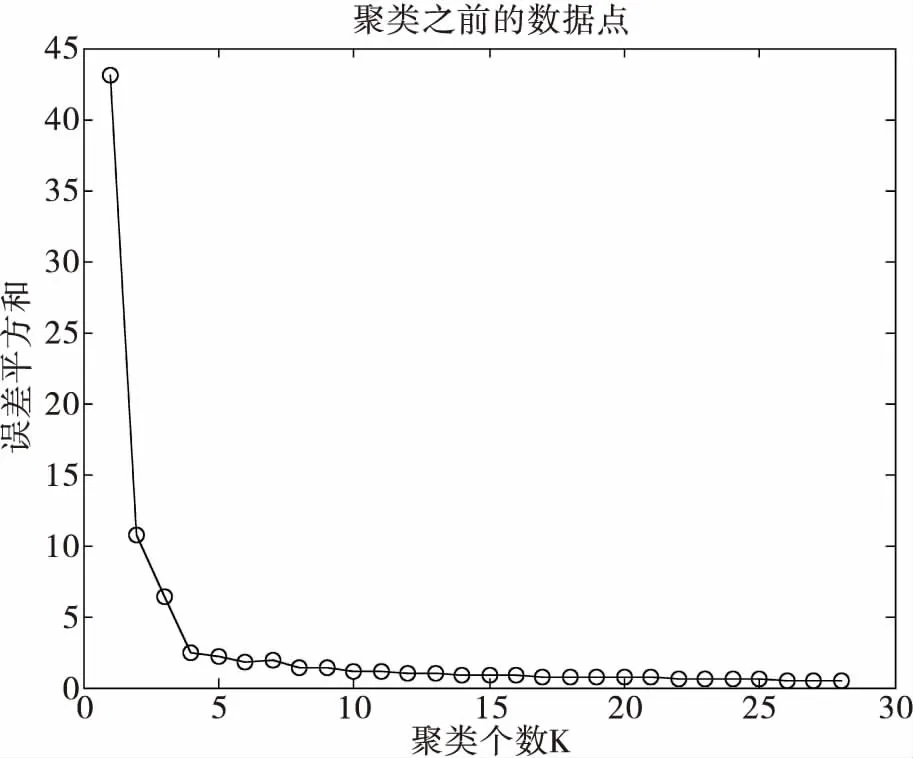
针对K-means聚类算法中随机选取初始质心的导致聚类质量不稳定的问题, K-means++算法对初始聚类中心进行了修正。K-means++算法与K-means算法都采用动态迭代的思想,主要改进是如何初始选取K个初始聚类质心。K-means++算法选取初始聚类中心时,假设当前已选取了n个初始聚类中心(0 K-means聚类算法的选择初始质心的流程如下: 1)从数据点集中选取一个数据点作为初始聚类中心; 2)计算每个数据与当前已有聚类中心之间的最短距离D(i); 3)选择新的聚类中心,D(i)较大者成为聚类中心的概率越大; 4)重复2)和3),直到选择出K个聚类中心。 其中,步骤3)的具体实施方法是: ①累加每个数据点与距离最近的聚类中心点距离,累加和表示为sum(D(i)); ②在0到sum(D(i))之间取一个随机值R,然后循环计算R=R-D(i)(i=i+1),直到R≤0。此时的数据集A中的第i个数据点即为下一个聚类中心。 为了说明初始聚类质心对聚类结果的影响,本文随机产生了一组数据点集,分别采用K-means算法和K-means++算法进行聚类。以数据点之间的欧式距离为标准,采用误差平方和为准则函数。数据点集个数N=800,聚类个数K=6。 图1 K-means算法聚类结果-随机初始质心(a) 图2 K-means算法聚类结果-随机初始质心(b) 图1和图2给出了采用随机初始质心时聚类结果,其中(a)和(b)代表不同的随机值。对比图1和图2可以明显地看出,当给定不同的初始聚类质心时,得到的聚类结果也不尽相同,且聚类效果并不理想,尤其是图1的聚类结果。 图3给出了K-means++算法聚类结果,对比原始数据点的分布可以看出,K-means++算法聚类结果更为合理。 图3 K-means++算法聚类结果 K-means聚类算法要求算法开始之前必须确定聚类个数 K值,该设置会对聚类结果产生一定的影响,同时也限制了其无监督聚类算法的应用。 一般化的聚类方法归纳为: 3)计算不同K值下的准则函数输出; 4)搜寻准则函数的最大(最小值)对应的K值及聚类结果,或者寻找准则函数输出转折点对应的K值及聚类结果。 图4 K-means++算法聚类结果-K=4 有效性值根据实际应用的不同可以采用不同的有效性值,常见的有效性函数可参考[6]。为了说明K值对聚类结果的影响,本文随机产生了一组数据点集,采用K-means++算法进行聚类。以数据点之间的欧式距离为标准,采用误差平方和为准则函数。数据点集个数N=800。 图5 误差平方和随K值变化 从图5给出的误差平方和随K值变化的趋势可以看出,随着聚类个数的不断增加,整个聚类结果的误差平方和不断的减小。此时误差平方和并不能完全反应聚类的效果。同时,大范围的搜索也会导致资源的浪费,一种可行的方法是观察误差平方和的变化趋势,当误差平方和逐渐收敛时即可停止搜索过程。图5中,当K≥4时,误差平方和逐渐收敛,故K=4是一个相对合理的聚类个数,对应的聚类结果如图4所示,与原始数据集分布可以看出,聚类结果基本有效的反映了原始数据集的分布特征。 本文首先回顾了聚类问题的相关理论基础,然后针对基于划分的聚类思想展开了讨论,重点介绍了K-means和K-means++两种聚类算法方法,并且讨论了影响聚类性能的两个重要问题,聚类初始质心和聚类个数对聚类性能的影响,通过仿真研究验证了本文的观点,下一步工作将深入开展无监督聚类算法在实际应用中的优化问题,包括算法收敛速度、相似度量函数选择等。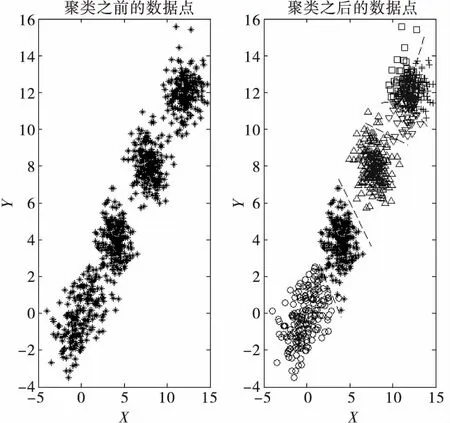
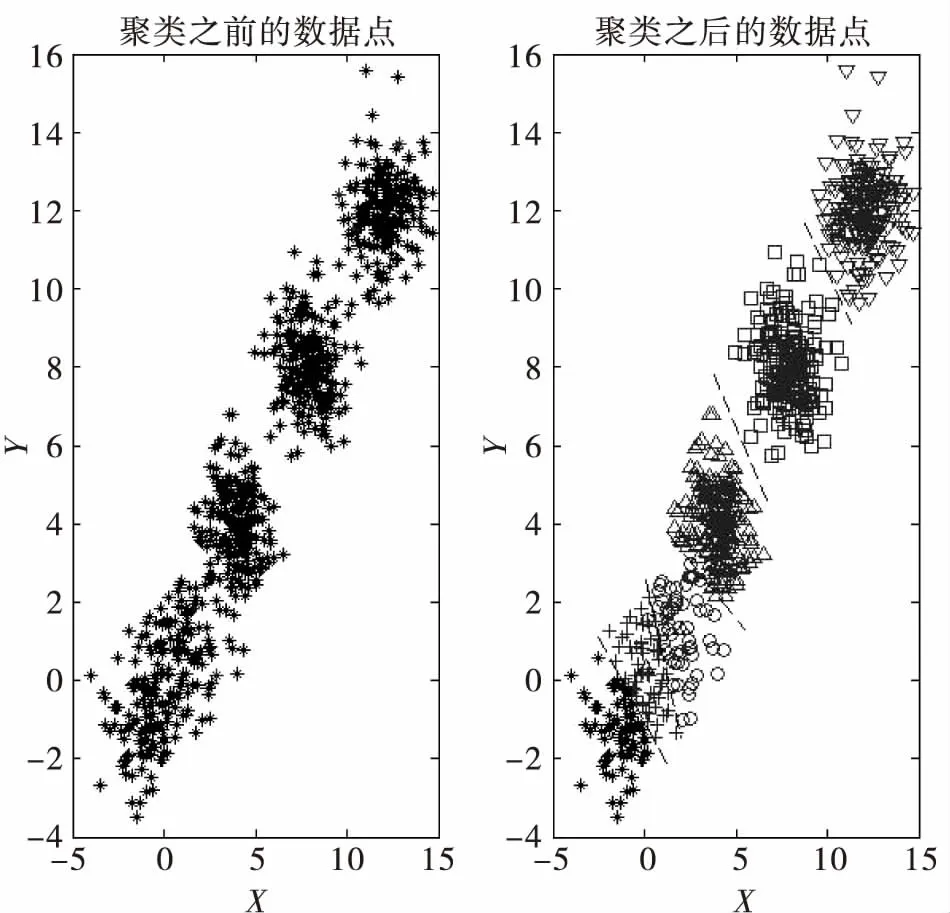

5 聚类个数对聚类性能的影响
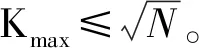

6 结束语
