基于深度学习的点胶缺陷检测
2019-08-23查广丰胡泓
文/查广丰 胡泓
在工业生产中,以往的人工检测由于其费时费力而不再受到关注,在对产品进行缺陷检测时,更多的是采用机器视觉的方法,从而达到提高生产效率和降低成本的目的,进而使得产品更加具有竞争力。目前,在机器视觉方面有两类算法,分别为数字图像处理算法和基于卷积神经网络的深度学习算法。
目前有许多学者在点胶缺陷检测领域提出了基于数字图像处理的方法,如庄付等人[1]利用传统图像处理技术对太阳电池串滴胶质量进行检测,主要通过图像处理等操作得到胶层的面积、质心以及自定义的复杂度公式进行对胶层的质量判定,虽然可作为一种太阳电池串滴胶的质量评价标准,但是整个过程较为繁琐,需要特定制定各种标准,算法泛化性不足。陶思理等人[2]研究出了一套用于检测干电池封胶质量的视觉检测系统,该系统能够对干电池封胶过程中的多种缺陷进行识别,但该系统的图像处理效率低,图像传输效率还需要改进。
现如今,随着计算机性能的不断提升,机器学习在缺陷检测这一领域由浅层次结构模型慢慢过渡到深层次结构模型,例如支持向 量 机[3](Support Vector Machines,SVM)、Boosting[4]、最大熵方法[5](如 Logistic Regression,LR等)这一系列的浅层次结构模型在处理图像、视频、语音、自然语言等高维数据方面表现较差,特征提取难以满足要求,而深度学习技术弥补了这一缺陷,在提取物体深层次的结构特征方面更具有优势。在工业缺陷检测这一领域中,深度学习有着至关重要的作用。李致金等人[6]提出一种基于主成分分析法的深度学习模型,构建印刷标签检测系统,从中进行信息提取和学习处理。毛欣翔等人[7]构建了基于YOLOv3模型的连铸板坯表面缺陷检测平台。姚明海等人[8]运用深度学习模型对磁片表面缺陷进行检测,并达到了良好的效果。
本文的研究对象是胶条。胶条的缺陷主要分为以下几种:多胶、少胶、断胶、扭曲以及含有气泡。胶条的主要缺陷如图1所示。
1 深度学习模型选择
一般在利用深度学习算法进行缺陷检测时,首先要确定的是网络模型。因为胶条种类分为6类,类别数量不是很多,故我们初步选择Alex、Mobile以及Lenet-5三种比较简单的网络模型。在实验中,我们采集的缺陷图片数量为:正常1300张、胶条扭曲355张、胶条断胶413张、胶条多胶492张、胶条少胶624张、胶条含有气泡506张,总计3690张图片。在此基础上,我们分别利用三种模型对其进行训练,最终得到的模型检测效果以及单张图片检测时间如表1所示。
从表1中可以发现,Lenet-5模型的准确率相对最高,同时其单张图片的检测时间也是最少,所以本文最终选择Lenet-5模型。
2 经典Lenet-5模型结构
Lenet-5模型是Yann LeCun[9]提出的一种经典的卷积神经网络,最先用于手写数字识别,对于图像特征提取非常有成效。该模型网络结构图如图2所示,在不包括输入层的情况下,整个模型总共为7层,其中包括卷积层、池化层以及全连接层三种类型。
2.1 卷积层
卷积网络运算之所以能够改进传统的机器学习系统,是因为其含有以下三个特点:稀疏交互、参数共享以及等变表示。首先,第一个特征是稀疏交互,主要通过将卷积核的大小改变为远小于输入大小来实现,从而减少模型训练的计算负荷并降低模型的存储要求;其次,第二个特征是参数共享,其特征在于在模型的同一个层中使用相同的参数,这对模型的存储也提供了巨大的便利;最后,第三个特点是等变表示,主要是指输出随着输入的变化而变化,它的变化方式是一致的,利用此性质可以方便的处理图形或者时间序列。卷积层得到的特征图为每个卷积核通过“滑动窗口”的方式提取出输入数据不相同位置的特征[10]。该特征图是由输入图像与卷积核卷积运算之后加上一个偏置,然后通过激活函数得到的。卷积公式为:
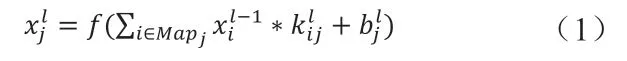
式中,l代表的是目前的卷积层数,k为卷积核,b表示加在每一个卷积核上的偏置,*代表卷积运算,Mapj表示第j个特征图,f代表激活函数。
以图2中的C3层为例,它的上层为S2。S2层中共含有6个特征图,尺寸为14×14。C3层的卷积核的尺寸大小为5×5,卷积步长为1,且不进行全0填充操作,所以C3层得到的特征图尺寸大小为(14-5+1)/1=10,即10×10,特征图的个数,即卷积核的个数为16。卷积的过程示意图如图3所示,图中l-1层的特征图尺寸为6×6×1,经过与l层的卷积核卷积运算之后得到了4×4×6的特征图,即每一个卷积核都会与特征图进行卷积运算,从而得到新的特征图,而卷积核的个数也就等于得到的特征图的个数。C3层包含的参数个数为卷积核参数和偏置项之和,则每个特征图的参数为5×5+1=26个,故训练时总共的训练参数为26×16=2416个,连接数为10×10×16×(25+1)=41600个。

表1:各模型的精度以及单张图片测试时间
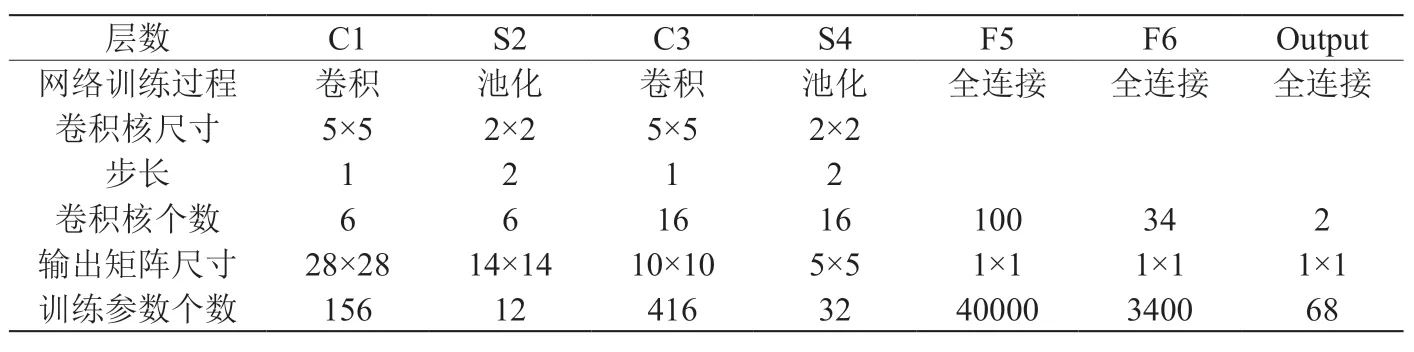
表2:经典Lenet-5模型连接参数
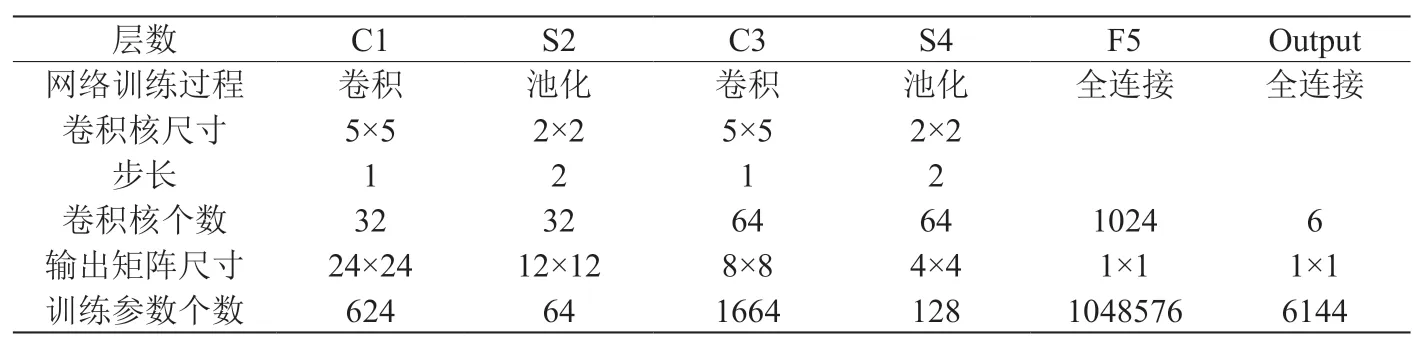
表3:改进Lenet-5模型连接参数
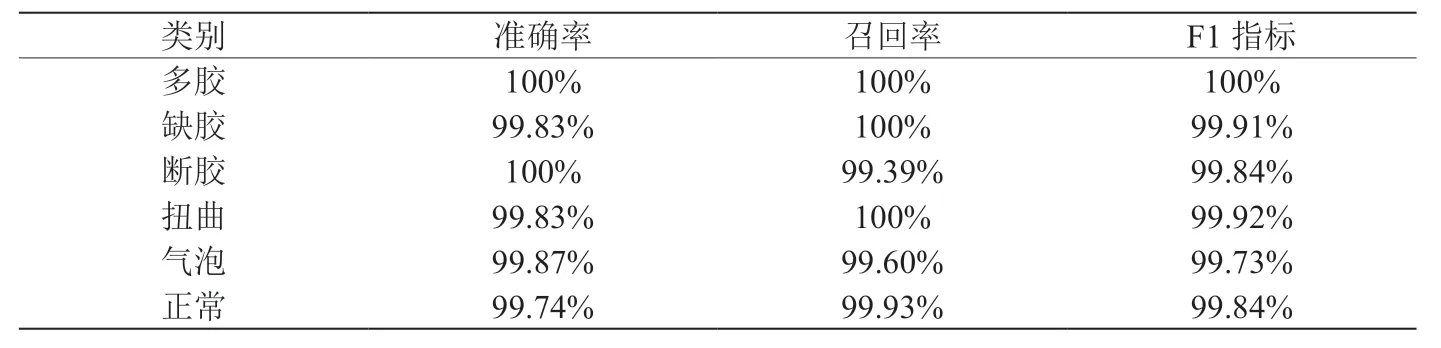
表4:改进Lenet-5模型性能表
2.2 池化层
池化层主要是将某一区域的最大值或者平均值来代替这一区域范围在神经网络上的输出,有效地缩小矩阵的尺寸,从而减少最后全连接层中的参数。最常用的两种池化方法是最大值池化(max-pooling)和平均值池化(meanpooling),具体公式为:
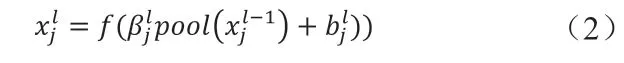
式中,pool(.)代表的是池化函数,最大值池化则取一定范围下的像素最大值作为输出结果,平均值池化则说明将某范围下的像素平均值作为输出结果,每个特征图包括参数β和b[11]。
以池化层S4为例,其中包括16个特征图,特征图中的每一个节点都是以C3层中2×2的局部领域作为输入的,步长为2,由此可得到输出层的尺寸为输入出层的四分之一,即5×5。池化过程示意图如图4所示,图中l-1层的特征图尺寸为4×4,在经过池化之后,得到的是2×2的特征图。一般来说,池化层内的参数都是人为设定的,所以不需要进行训练。
3 改进训练方法
从数据上可以看到,经典Lenet-5模型的准确率也只有75%,并不能满足我们的需求,所以我们需要对训练方法进行改进。本文打算从两个方面对训练方案进行改进,一是通过数据增强得到更多的训练数据,二是对经典的Lenet-5网络结构进行改进。
3.1 数据增强
由于实际含有的图片比较少,而在对模型进行训练时,神经网络的参数数量又非常巨大,要想使得这些参数正常工作则需要大量的数据进行训练,一种方法是获得新的数据,但由于成本较高,故不推荐,第二种方法是对数据进行增强,即利用已有的数据进行例如翻转、平移或旋转等操作,增加样本数量,提高算法的精度。本文中采用亮度和对比度变换两种操作。

图1:点胶缺陷样品图
在实际生产中,由于现场环境的多变、机器的抖动和光源的变换都会引起图像上亮度和对比度的变化。对图片进行适当的亮度和对比度变换,能够有效的增强算法的鲁棒性。图5展示了进行亮度变换的效果图。
3.2 改进Lenet-5模型
由于采集到的数据图片尺寸为800×600,每张图片包含的信息量太大,并且某些缺陷特征并不是很明显,显然经典Lenet-5网络模型会因为网络的学习能力不足而产生过拟合,因此不能够很好的对图片进行而分类。故本文对网络结构进行了改进,首先将输入层的大小由32×32改为28×28,再将图2中的F5和F6两个全连接层合并为一层,同时加上dropout层,最后通过softmax激活函数输出,具体的结构参数变化见表2和表3。
从表中可知,模型由之前的7层变为6层,减少了网络的臃肿度,同时在F5全连接层中加入了dropout,
dropout是Hinton[12]在2012年提出的,是对具有深度结构的人工神经网络进行优化的方法,在学习过程中通过将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性,从而实现神经网络的正则化,降低其结构风险。图6展示了神经网络在使用dropout前后的对比图。
4 点胶缺陷识别实验分析
4.1 实验平台及方法
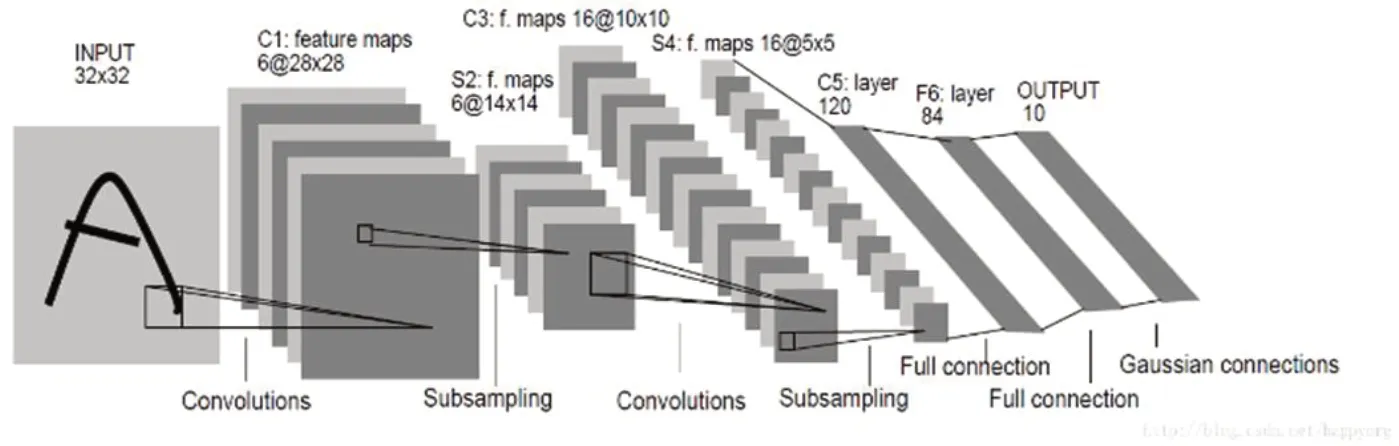
图2:经典Lenet-5模型结构
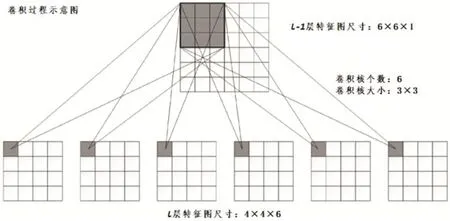
图3:卷积过程示意图
本文实验设备为个人笔记本电脑,操作系统是Windows 64位,CPU为Inter(R) Core(TM) i5-3230M (频率2.60GHz),计算机内存为4G。在运用深度学习时的框架为Tensorflow,训练时使用生成截断正态分布的方法初始化参数,将AdamOptimizer作为优化器的优化算法,softmax交叉熵函数作为损失函数,网络的超参数如下:批次处理大小(mini_batch)为128,最大迭代次数(max_step)为17500,学习率(learning_rate)为0.001,学习率每100轮更新一次,在加入的dropout层中设置的参数为0.5。在经过数据增强后,各类缺陷图片的数量分别为:正常3900张、胶条扭曲1065张、胶条断胶1239张、胶条多胶1476张、胶条少胶1872张、胶条含有气泡1518张,总计11070张图片。
4.2 实验结果
图7为经典的Lenet-5网络模型下的训练集损失和测试集损失变化曲线,由于训练的时候观察到测试集损失一直处于离散状态,故只训练到6000轮。图8为改进的Lenet-5网络模型下的训练集损失和测试集损失变化曲线。从图中可以明显的看出,经典的Lenet-5网络模型的训练集损失趋于稳定,但其测试集损失却一直在变化,且距离训练集还有一定的距离,产生了明显的过拟合现象。改进的Lenet-5网络模型在加入dropout层以及数据增强后减少了模型过拟合程度。
由于模型的准确率受到多方面的因素影响,故本文在保持F1指标最佳的情况下对超参数进行了调试,最终得到的算法性能表如表4所示。
从表中我们可以看出,相比于改进之前的方案,检测的准确率得到了大幅提升。重要的是,每一类缺陷的检测准确率都很高,达到了实际生产中的精度需求。
5 结语
本文首先通过比较Alex、Mobile以及Lenet-5三种模型在点胶图片分类中的表现,最终选择了Lenet-5网络模型,然后运用数据增强技术以及对经典的Lenet-5网络模型结构进行修改得到改进的训练方法。实验表明,经典的Lenet-5模型对于点胶图片存在过拟合现象,训练精度不是很高,改进的Lenet-5模型由于加入了dropout层以及在拥有大量数据图片下的基础上减少了过拟合现象,且在各类缺陷图片的检测精度上也存在一定的优势,达到了工业检测中对点胶缺陷检测精度的要求。
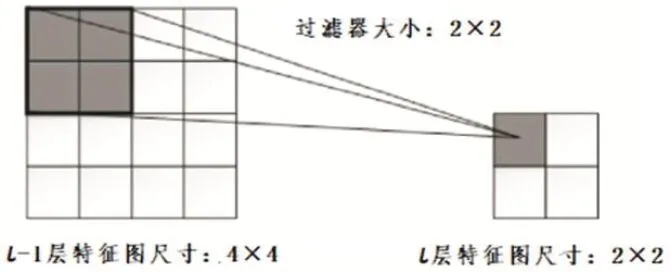
图4:池化过程示意图

图5:亮度变化对比
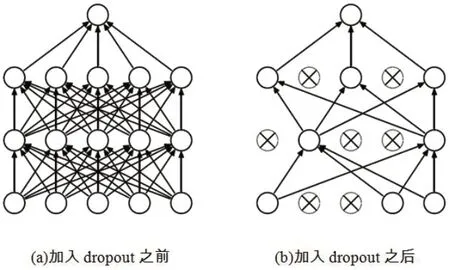
图6:dropout原理图

图7:经典Lenet-5模型交叉熵损失
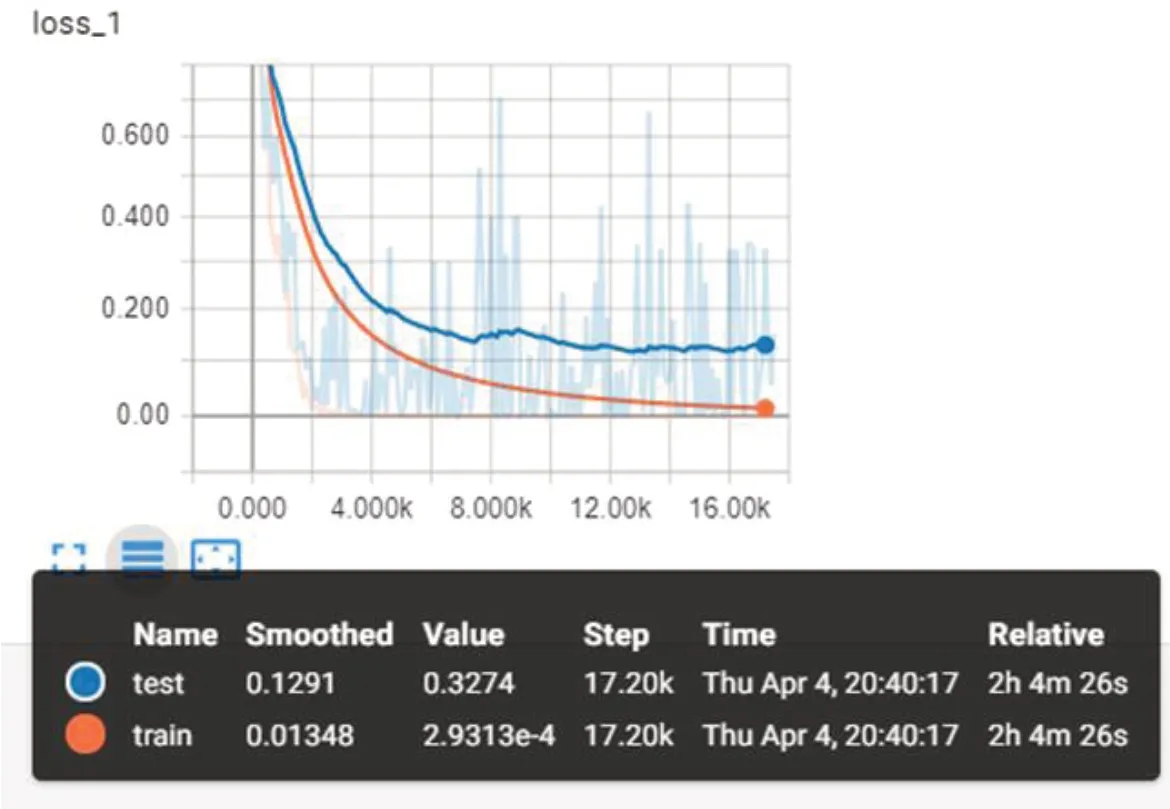
图8:改进Lenet-5模型交叉熵损失
