基于依存搭配抽取技术的平面媒体语言监测研究
2019-08-22邵艳秋申资卓刘世军
邵艳秋,申资卓,刘世军
(北京语言大学 信息科学学院,北京 100083)
0 引言
搭配通常是指由两个或两个以上的词语所组成的一种语言表示,这种表示往往是语言某种习惯方式的表达。搭配对于提高机器翻译、信息检索、自动问答等应用研究以及句法、语义分析等基础研究都具有重要的支持作用,同时对于语言学以及对外汉语教学等的研究也具有重要意义。
早期搭配研究主要是依靠人工判断,主观性很强,时间消耗大,比如《英文搭配词典》就是由一名日本学者通过穷举的方法花费20年时间完成[1]。随着计算机技术的发展,搭配研究也开始向自动化发展,主要表现在搭配抽取技术方面。国外较早开展搭配自动抽取研究的是Choueka、Klein和Neuwtiz[2],他们将共现次数达到一定阈值的相邻词串抽取出来作为搭配,但这种方法会漏掉很多彼此不相邻的搭配,比如make-decision;Church和Hanks[3]改进自动抽取技术,提出了用表示词对联系紧密程度的互信息作为评价搭配的指标,取得了一定进展,但该方法也有一定局限性,一些经常共现的彼此依赖的词语会被抽取出来,比如“医生、护士”;Lin[4]基于浅层句法分析抽取搭配;Yang[5]融合频率、似然比、点互信息、方差等多种统计指标,利用决策树方法获取搭配。
国内的搭配研究近些年也有显著发展。孙茂松[6]等在借鉴国外研究成果的基础上,提出了包括强度、离散度以及尖峰三项统计指标,开启了基于统计的大规模语料搭配自动抽取的先河;王萌、俞士汶[7]等抽取量名搭配并对其进行定量分析;曲维光[8]等提出了一种基于框架的词语搭配抽取方法;车万翔[9]等在1.8 GB的大规模语料库中统计词对个数、距离及方差,并应用t检验的改进方法得到了词对之间的“搭配强度系数”值,以此来衡量它们之间这种搭配关系;徐润华[10]探讨了两种基于句法分析结果比对的词语搭配自动获取方法,并建设了大规模词语搭配知识库。黄德根[11]等提出了基于词向量技术的搭配抽取方法,并通过对比实验表明基于词向量的方法优于传统的多策略融合的方法。目前来看,搭配的自动抽取技术正在逐渐与语言学知识融合,从初期纯粹利用统计量抽取搭配发展到如今,搭配的自动抽取已经融入了词性、句法等特征。
语言监测研究方面,目前国内的主要工作集中于对历时语料库的计量分析,通过统计指标考察语言的历时变化,饶高琪等[12]利用了互信息、联合熵、变异系数等9种统计方法,从1946年-2015年的报刊语料中抽取稳态词进行语言监测研究。一些国外学者,近来也采用词向量技术、可视化技术、主题模型来研究历时的语言数据,Arendt[13]等提出了在大规模历时社会媒体语料上动态训练词向量并可视化的方法。Hida[14]等人则利用结合动态信息与静态信息的主题模型对文本历时数据建模。
本文通过对语料进行句法依存分析,提出了一种基于句法依存分析的搭配自动抽取方法,并将此技术应用于近70年《人民日报》语料库的搭配抽取,通过抽取出来的搭配对语言的发展变化、社会生活的变迁进行分析研究。
1 基于依存关系的搭配再定义
Firth提出搭配是指一个词语的语义由与它经常一起出现的另一词语决定[15],主要用于词汇层面。孙茂松引用了Benson的观点,认为“重复出现决定了搭配应有一定的流通度,而非偶然的个例”,搭配是约束组合而不是自由组合,即搭配不可预期性[6]。该观点认为“warmest greetings”是搭配,因为这种说法是习惯使然,没有规律可循。林杏光等在编写搭配词典时提出了一种“少而精”的原则,认为“好词典”“坏词典”这种非常常见的搭配不宜录入搭配词典,而“百科词典”“英汉词典”则可以[1]。申修瑛在《现代汉语词语搭配研究》中指出,搭配是介于自由组合与惯用语之间的词语组合方式[16]。
可见,人们往往将搭配的定义与自由组合和约束组合(或惯用语)做比较。在总结上述观点的基础上,本文对自由组合进行限定,即认为像“好词典、好学生”这类扩展性很强的组合为自由组合,而认为“受到批评、受到谴责”这类能扩展但扩展性很有限的组合为非自由组合。其次,本文对“共现”进行了界定,认为在一句话中彼此有依存关系的两个词语即为共现,例如,“我们邀请他参加学校举行的运动会”这句话中的“参加”和“运动会”是有依存关系的,句法上存在动宾关系,尽管二者距离比较远,我们仍将其视为共现,在一个完整的句子内,不论词语之间的间隔有多远,两个词语只要是有依存关系,即认为是共现。而“参加”和“学校”虽然距离很近,但二者之间没有依存关系,则不视为共现。
综上,本文定义的搭配为:具有一定共现频率的非自由组合。该定义中“共现”的含义即为词语对在句中存在依存关系;“一定频率”则通过阈值进行控制,只有超过一定阈值才视为是稳定的搭配;而“非自由组合”则是上文提到的以一种相对特异的方式相互约束的组合。
2 基于依存分析的搭配自动抽取
2.1 依存句法分析
以往的搭配抽取通常是将“共现”定义为在一定范围内的共同出现。比如用开窗口的方法抽取搭配就是以一个词为核心词,窗口大小设为n(n一般不大于5),那么该词前后各n个词语与其共现,在此基础上统计共现频率。窗口的设定太大就会增加计算量,并且会有大量彼此没有句法或语义联系的词对被抽取出来,窗口如果设定太小就会漏掉很多间隔比较远而联系紧密的搭配。因此,这种开窗口的方法虽然对于某些搭配的抽取会有很好的表现,但同时也常常会抽取出彼此没有语法、语义关系而只是经常在一定距离范围内共同出现的非搭配关系的词对,而且也会遗漏一些相隔距离远而又存在内在联系的搭配。本文将搭配定义在具有依存关系基础之上的一定频率的非自由组合的“共现”。
本文基于依存句法分析进行搭配抽取。依存分析是以句子为单位进行分析,将具有句法依存关系的两个词语用依存弧相连接并标出相应的依存句法关系。相比于开窗口的方法,将共现定义为彼此有依存关系的词对更加准确,一方面过滤掉了没有关系的词对,另一方面在一个句子范围内,不受距离限制。
图1是句子“我们邀请他参加学校举行的运动会”经过依存句法分析的结果,有依存弧相连接的两个词语在句子中具有句法依存关系,弧的方向为核心词指向依存词,弧上的标签为词对的句法依存关系,如“HED”表示句法上的核心关系,“SBV”表示主谓关系,“DBL”表示兼语关系,“VOB”表示句法上的动宾关系,“WP”表示标点符号,“RAD”表示右附加关系,“ATT”表示定中关系。本文采用哈工大社会计算与信息检索研究中心的LTP平台提供的句法分析开源工具进行依存句法分析。
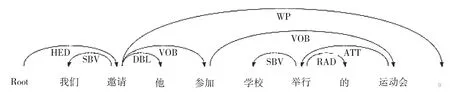
Fig.1 An example of the tree representation result of dependency parsing图1 依存句法分析结果树状图表示示例
2.2 基于依存分析的搭配自动抽取算法
基于依存句法的搭配抽取算法,主要通过对大规模语料进行依存句法分析,获得具有句法关系的词对,进而计算词对之间的互信息来表征词对之间的共现性。这里互信息衡量了两个词语之间的相关性,互信息越大,两个词语就越相关。算法的详细步骤如下:
Step 1:语料预处理,包括对语料进行分句、分词、词性标注等。
Step 2:句法依存分析。将经过预处理的语料作为输入进行句法依存分析(本文采用的句法分析工具是哈工大语言云平台上的依存句法分析器)。
Step 3:抽取句法依存弧。依据句法依存分析的结果生成句法三元组集合。句法三元组是由父节点词语、子节点词语和依存成分三个部分组成,表示为(w1,w2,Rela_Syn),其中,w1为核心父节点,w2为依存子节点,Syn为词语w1与w2间的依存句法关系,遍历文件,输出所有的句法三元组。
Step 4:频次统计。以(w1,w2,Rela_Syn)为对象统计存在某句法关系Rela_Syn的词语对的频次Freq-Syn。然后,将统计得到的Freq-Syn加入句法三元组,从而构造出带有频次信息的句法四元组集合(w1,w2,Rela-Syn,Freq-Syn)
Step5:计算互信息。构造带有加权互信息的句法五元组集合。互信息计算公式如式(1)所示:
(1)
WSyn=Freq-Syn/Sum-Syn
(2)
其中WSyn为句法权重,Freq-Syn为步骤4中统计得出的词语对的频次,Sum-Syn为语料库中抽取出的句法三元组的总数。经过计算后,将加权互信息MI加入句法四元组,从而得到句法五元组(w1,w2,Rela_Syn,Freq-Syn,MI)。
Step 6:设定阈值抽取搭配。通过抽样观察,本文将Freq-Syn的阈值设定为10,MI的阈值设定为0.000 1,然后抽取出Freq>=10且MI>=0.000 1的搭配。
根据上述算法,以句子“我们邀请他参加学校举行的运动会”为例,经step2进行句法依存分析后,结果如表1所示。表中每个词语单独占据一行,各列从左至右分别表示词语在句中的位置用序号、词语、词性、该词语的依存节点即父节点序号、该词语的句法成分。例如,词语“我们”的词性为代词r,父节点为2号节点“邀请”,担当动词“邀请”的主语(SBV)成分。全句核心节点的父节点位置标为0,如节点“邀请”是全句的核心词,其父节点位置标为0。而经step3处理之后,会得到诸多带有句法信息的三元组表示,如(参加,运动会,VOB),表示依存弧的方向由“参加”指向“运动会”,并且“运动会”是“参加”的“直接宾语”,二者之间的关系是动宾关系(VOB)。

表1 句法依存分析结果二维表表示示例
2.3 实验结果与评价
为了评测2.2中提出的算法的有效性,本文构建了VOB句法关系候选搭配集S,即将句法关系为VOB的五元组抽取出来组成S,然后再设定阈值进行搭配抽取实验。
经实验,从候选搭配集S中,共抽取出句法搭配对268 102个。表2是按互信息倒排后排名前10的句法搭配对。从表2可以看出,抽取出来的“解决 问题”“加大 力度”“开展 活动”等都是合理的搭配,但是,由于句法分析只有11个不同的句法标签,粗粒度分类会对搭配抽取产生相对多的干扰因素,致使搭配抽取的准确率降低。所以,在上表中“认为 是”“说 是”这一类的组合也被分为了VOB。另外,本文对自动抽取的结果进行了评测,采用基于词典的评测方法,即从自动抽取的搭配中,选出出现次数较多且收录在张寿康《现代汉语实词搭配词典》中的5个动词,分别计算准确率和召回率。以动词“受到”为例,其搭配的准确率为27.2%,召回率为66.7%。

表2 排名前10的句法搭配对

表3 未在词典中出现的“受到”的搭配词语集合
由于考虑到词典收录搭配的局限性,即从大规模语料中抽取出的搭配虽然未被词典收录,但仍然是常用的搭配,本文又进一步对抽取结果进行了人工评测(即不参照词典,只要评测人认为该词对是搭配就视为正确搭配),仍以“受到”一词为例,其搭配准确率为74.7%。表3中列出了动词“受到”未在搭配词典中出现的搭配,但经过人工判断确定其属于搭配,共123个。
3 基于搭配的平面媒体语言监测
3.1 基于词语的平面媒体语言监测
目前,语言监测的相关任务主要是基于独立词语进行研究的,为了发现基于词语的语言监测与基于搭配的语言监测的异同,本文利用近70年的《人民日报》语料,以1977年为界,分别对1977年以后和1977年以前的两个时期的语料进行词频统计,并对两个时期的词频统计文件进行了对比。表4和表5是这两个时期各自独有的词语按照词频倒排后的前20个词语。
表4中的出现年份表示该词语第一次出现的年份,从表中的词语可以大致看出1977年以来社会发生的变化,比如“乡镇企业”“高新技术”“第三产业”等。

表4 1977年以后出现的词语

表5 1977年以后消失的词语
表5中的“最后出现的年份”表示该词最后出现的年份。从表中的词语可以看出消失的词语大部分是人名和地名等专有名词,从这一方面可以反映出专有名词的生命周期较短,比较容易消失。另一方面,1977年以前的语言风格与现在相比还是有一定差异的,首先表现在用词方面,“米”作为长度单位取代了“公尺”;其次,音译词的翻译风格比较随意,比如“托辣斯”,“塞拉勒窝”。
3.2 基于搭配的平面媒体语言监测
本文从搭配角度出发进行语言监测研究,以1977年为界,根据2.2提出的算法分别抽取出该界限之前和之后两个时间段内的部分句法搭配,对两个时段的搭配进行比对,生成“1977年以后产生的搭配”和“1977年以后消失的搭配”两个集合。表6和表7分别列出了这两个集合按词频倒排后的前20个搭配。
从表6和表7中可以看出1977年以后社会发生的一些大的变化,如发展经济、香港回归、加入世贸、建设精神文明等。而1977年之前的一些搭配如“学习老三篇”“革命造反派”“斗私批修”等在报纸媒体上已经随着社会的发展逐步消失了。

表6 1977年以后出现的搭配

表7 1977年以后消失的搭配
3.3 基于搭配变化的平面媒体语言监测
本文同时对两个时代共有的词语做了分析,通过抽取这些词语在不同时代的搭配,观察搭配在不同时代的变化。
实验步骤如下:
Step 1:语料:抽取出来两个时代的搭配集合,1977年之前的搭配集合设为A,1977年之后的搭配集合设为B。
Step 2:分别以A,B中所有的词为key,以该词在1977年之前和之后的所有搭配词语的集合为value-A和value-B,建立字典Dic-A,Dic-B。
Step 3:设B中独有的词语计数器:count=0。
Step 4:遍历Dic-A中所有key,如果这个key也在Dic-B中,则取出这个key分别在Dic-A和Dic-B中的值:value-A和value-B。遍历value-B中每个词,如果不在value-A中则count++。
Step 5:如果B中独有的词语占B总数的比重超过了50%,就将该词输出作为候选。
在候选结果中,本文选出了几个代表性的词语作为示例,如表8所示。表8的搭配在1977年前后发生的变化反映了这两个时代社会发生的变化,比如:从“绝对平均主义”的搭配发展到“打破、反对、克服平均主义”的搭配,表现了社会分配方式的改变;“缴纳、征收农业税”的搭配变化为“减免农业税”;“交纳公粮”的搭配,变化为“缴纳所得税、保证金、保险费”,这表现了税收方面政策的调整;“下海捕鱼”的搭配变化为“下海经商”则体现出了市场经济的出现等等。

表8 搭配词语发生改变
为了更细致地反映词语搭配随时间的历时变化情况,本文进一步基于1956-2015年的《人民日报》语料,以五年为一个时期,进行基于搭配变化的语言历时监测,从而通过常用词语的搭配变化更加具体地展现各个时期国家政策、社会生活的变迁。在实验结果中,本文选取了VOB句法关系的一些常用动宾搭配进行展示,如表9-12:

表9 2001-2015各时期搭配表

表10 1986-2000各时期搭配表

表11 1971-1985各时期搭配表

表12 1956-1970各时期搭配表
从表9-12中各时期共有词语的搭配变化中,可以充分展示出各时期社会的特点,以“建设”一词为例,从“建设发电站、钢铁厂”可以反映出新中国成立以后,国家大力发展重工业。从“建设核电站、高速公路”可以反映出改革开放初期,对基础设施建设的重视,从“建设生态省、执政党”可以反映出整个社会对环境、政治的关注,从“建设共同体、丝绸之路”可以反映出中国在世界影响力的提升。
这些实验结果表明,与基于单独的词语监测方法相比,搭配的语境更丰富,表达的意思更加准确,更容易让人理解事件本身,从而反映语言的变化和国家政策、社会生活的变迁。
4 结论
本文在依存分析的基础上给出了搭配的定义,基于自动依存分析的结果,计算句法加权互信息,抽取出了具有依存句法关系的搭配对。通过对近70年的《人民日报》平面媒体语料进行统计,将语料以1977年为界分为前后两部分,在这两部分语料的基础上进行基于依存句法分析的搭配抽取,再对抽取出来的这两个时间段的搭配进行比较。通过比较可以发现一批新产生的搭配,一批消失的搭配,以及一批搭配词语发生改变的搭配。相比于单独的词语监测,基于搭配变化的视角进行的监测研究,能够更加全面地理解语言的变化以及社会的变迁。
