面向App用户评论的软件特征挖掘研究
2019-08-22吕宏玉杨建林南京大学信息管理学院北京林业大学经济管理学院
吕宏玉,樊 坤,杨建林(.南京大学信息管理学院;2.北京林业大学经济管理学院)
1 引言
随着移动智能终端的广泛普及和互联网技术的快速推进,应用商店和App都得到了蓬勃发展,用户对于App的需求被激发。[1]应用商店作为中间平台,允许开发者发布以及允许用户搜索、购买、下载、评论App,[2]评价形式为评分星级、评论标题和评论文本构成的单条评论。其中评论文本里的评价对象,即用户的关注点称为软件特征,[3]一般为描述软件功能或性能的词或短语。[4]以软件特征为中心的文字评价往往包含与需求相关的信息,如错误异常反馈[5]、用户体验总结[2]、功能优化建议[6]、新功能提议[7]等内容,这些反映用户对App改进和演化期望的内容被称为特征请求。[8]因此,获取特征请求将有助于开发者初步确定软件质量[9]和修改软件下一版本的需求。[10]
但是,开发者从用户评论中获取特征请求具有一定难度。一方面,应用商店内评论数据量大,[5,11]评论文本具有非结构化的特点;[12]另一方面,评论具有较大的自由性,评分星级与评论文本具有不对称性,[13]即高评分星级对应的评论文本表达负面情感倾向,或低评分星级对应的评论文本表达正面情感倾向;此外,评论文本质量不一致,部分评论文本只是简单地整体评价而非针对特定质量。[14-15]因此,挖掘用户在整篇评论中所表达的情感态度不具有太多的实际意义,获取用户反馈的有效途径是挖掘出软件特征再进一步分析用户对具体特征的情感态度。[16]
目前,学术界在评论文本的特征挖掘领域主要从特征频繁项、特征-意见共现关系、模型训练和显隐式特征匹配四个方面展开。[17]现有研究的评论对象主要是实体商品,对App评论文本提取特征的相关研究较少。文涛等使用规则模板提取App软件特征和情感词汇,考虑范围限于显性特征。[2]Guzman等利用搭配发现算法挖掘用户评论中细粒度的软件特征,并使用主题建模技术将软件特征分组成更有意义的高级特征。[4]彭珍连提出一种基于特征模型和协同过滤的特征获取方法,该方法可探索出历史软件特征之间的关系,可补充App的缺失特征以及预测待开发App的缺失特征。Johann等应用词类和句子模式同时从产品页面和用户评论提取软件特征,并对2个来源的提取结果进行匹配。[18]冉猛提取用户评论中的特征词、副词和情感词,并逐级量化计算用户对App的情感倾向程度。[19]
为获取软件特征,本文提出新的挖掘方法。具体而言,先利用句式匹配和情感倾向相结合的识别方法确定包含特征请求的评论,在该范围内使用基于关联规则的算法提取软件特征。与现有研究相比,本文的不同之处是在提取软件特征之前,从App用户评论全集中识别出包含特征请求的评论,确定出有效的挖掘范围。该方法将帮助App开发者从评论中获取用户对App的反馈信息。
2 研究思路和设计
本文的研究思路是将软件特征挖掘分为4个步骤进行(见下图)。① 评论数据收集:利用爬虫程序从网站上收集Apple App Store中的App用户评论。② 评论数据处理:对收集的用户评论数据进行去噪处理,重新整理成结构化的文本语料,并进行分词和词性标注。③ 特征请求评论识别:应用句式匹配和情感倾向相结合的方法,从评论全集中识别出评论文本里包含特征请求的评论。④ 软件特征提取:在特征请求评论范围内基于关联规则的算法提取App软件特征。
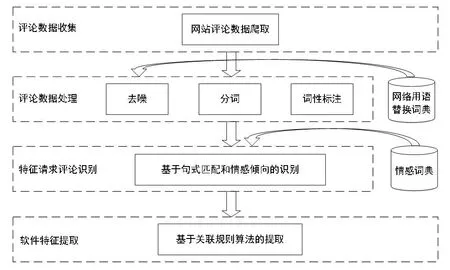
图 软件特征挖掘流程
3 数据收集与数据处理
3.1 数据收集
本文的数据对象是Apple App Store内用户对App发表的评论,数据收集地址为德普优化网。本文选取的App来自社交、工具、音乐、摄影和游戏5个类别,在每个类别中选择最热门的2个App,共计10个。以2018年2月20日为时间起点,利用Python爬虫程序按照逆向时间顺序爬取评论,数量共计11,437条,将该原始评论集合命名为R0。单条评论收集5项内容:评论时间、用户名、评分星级、评论标题和评论文本。
3.2 数据预处理
评论集合R0包含部分噪音数据,因此先进行数据预处理工作,包括3种常规去噪处理和2种针对App特殊评论的处理。整个过程通过Python程序实现。
(1)非中文评论处理。本文提出的软件特征挖掘方法面向中文用户评论,但评论集合R0中含有其他语言评论。如以下2条对“QQ”的用户评论文本。
①“Le logiciel n佴cessaire伽 la communication de la Chine.”
②“Ireallyreallyreallycan’tstand thespeed ofuploadingpictures.”
本文先去除评论集合R0评论文本中的标点符号,判别评论文本的语言,过滤非中文评论。对于中文评论中的单个英文词汇,因为多数属于专有名词,本文保留并做大写转小写的处理。如以下是1条“QQ”的评论原文及其处理后的结果。
评论原文:“iPhoneX都出来这么久了,QQ还不打算适配吗?”
处理结果:“iphonex都出来这么久了,qq还不打算适配吗?”
(2)无关内容评论处理。评论集合R0中存在部分与App无关的评论:一种是表达简单情感态度而缺少评价对象的评论,评论文本字数一般较少;另一种是垃圾评论制造者为吸引浏览者的注意力编写的字数过多评论。[20]如以下2条关于“QQ”的用户评论文本。
①“还行。”
②“你不能不知道的某宝某猫购物内幕,省钱党首席攻略!惊天地泣鬼神,就在这里发生,花生日记通过整合成千上万家的电商商家,向用户每天呈现多达几万的品类丰富、实惠、高折扣的商品。适合所有网购用户,当前绝佳的省钱利器。安卓用户在应用宝或应用商店里搜索花生日记,苹果用户在app store搜索花生日记,下载后注册账号输入邀请码完成,注册邀请码qcty3r或hewpiho。完成注册后把注册手机号后五位发我,领取2元微信红包或花生日记99元代理资格。”
本文将评论文本长度作为过滤器,过滤评论集合R0中评论文本字数小于4或大于300的评论。
(3)高字重复率评论处理。字重复率是中文评论中重复的字出现的比率,采用如下公式[20]表示。

评论集合R0中包含评论文本字重复率较高的评论。如以下2条对“QQ”的用户评论文本。
①“可以可以可以可以可以可以。”
②“啊啊啊啊啊好的好的好的好的好的。”
上述2条评论文本的字重复率分别为0.833和0.8,表达含义不明确。因此,本文过滤评论集合R0中字重复率大于0.6的评论。
(4)文本错位评论处理。经观察分析发现,与其他种类商品评论相比,App用户评论中存在文本错位的特殊情况:部分评论的评论标题中含有异常反馈、使用体验、功能需求、优化建议等有用信息,而评论文本的内容是“为什么”“如题”“见标题”等文字。如以下2条对“QQ”的用户评论。
① 评论标题:“要是能增大聊天表情收藏数量就好了”。评论文本:“如题”。
② 评论标题:“我都是很多年的老用户了,QQ宠物下线也不正式通知”。review:“为什么?”
因此,本文在评论数据预处理阶段,根据评论文本中的“为什么”“如题”“见标题”等文字识别出问题评论,将其评论标题内容与评论文本内容做置换处理。
(5)网络用语评论处理。App用户评论的特殊性还表现在评论文本中的网络用语较多,如以下2条对“QQ”的用户评论文本。
①“qq的离线传输功能有毒吧,一个txt文档整整用了一个小时,我还能说什么?”
②“为qq的视频美颜疯狂打call,素颜也可以和别人视频啦”。
上述2条评论包含网络用语“有毒”和“打call”,分词工具和词性标注工具都无法识别。因此,本文利用搜索引擎收集近一年的网络用语,收录词条共计107个,结合App用户评论的词汇使用统计结果构建全新的网络用语替换词典,利用该词典对评论集合R0中的网络用语进行识别并将之替换为书面语。如,网络词汇“渣”“炒鸡”“腻害”“为毛”“醉了”,用书面词汇分别替换为“差劲”“超级”“厉害”“为什么”“无语”。
预处理后每个App得到有效评论1,000条,共计10,000条,将该有效评论集合命名为R1。
3.3 分词与词性标注
本文采用Python中文分词组件“jieba”对评论集合R1的评论文本进行分词和词性标注,处理所得评论集合R2用于进一步数据分析。
4 软件特征挖掘范围确定
评论集合R2同时包含特征请求评论和非特征请求评论。用户在特征请求评论中表达对具体特征的情感态度,其中必定包含软件特征;非特征请求评论多为用户对App做出的整体评价,评论中包含的软件特征较少。本文对评论集合R2进行人工标注,判断单条评论属于特征请求评论或非特征请求评论,进一步标注非特征请求评论中是否包含软件特征,统计结果见表1。
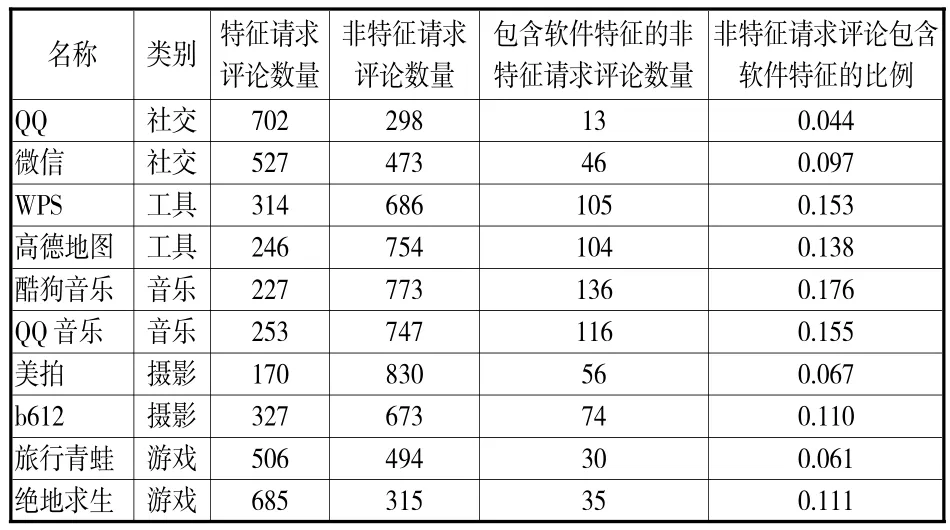
表1 评论集合R2人工标注结果
由表1可知,非特征请求评论包含软件特征的平均比例仅为0.111。为保证挖掘效率,本文忽略非特征请求评论中的软件特征,将软件特征的挖掘范围确定为特征请求评论,提出基于句式匹配和情感倾向的特征请求评论识别方法。
4.1 基于句式匹配的特征请求评论识别
通过对特征请求评论的观察,发现由于App的特殊商品属性,其评论文本通常包含固定句式,而非特征请求评论文本中不含该类固定句式。因此,可以通过检测评论文本中是否包含固定句式来判断评论类别。本文共总结出否定、疑问、抱怨、惋惜、建议和期望6种固定句式。在判断评论是否符合某一固定句式时,检测评论文本中是否包含关键词,以及关键词一定距离内是否有评价对象,即名词或动词词性的软件特征,并且关键词与特征词的位置固定。因此,固定句式由关键词、特征词词性和特征词相对位置构成。对于部分语气明显的关键词,不需要检测评论文本中的特征词词性及其相对位置,关键词出现在评论文本中即可判断该评论是特征请求评论。
(1)否定句式。用户在使用App过程中若发现当前版本功能未涵盖的领域,在撰写评论文本时就会以否定句的形式指出App尚未满足自身需求的功能特征。经总结得到14个否定句式。表2是用户对“QQ”的否定句式评论。

表2 否定句式评论样例
上述2条评论的评论文本对“QQ”的账号管理和版本更新做了评价,属于特征请求评论。它们符合固定句式“不允许+v/n”和“v/n+没有了”,其中“不允许”和“没有了”为否定关键词,“v/n”为特征词词性,特征词相对位置分别在关键词后和关键词前。
(2)疑问句式。当App出现异常导致某些功能无法正常使用,或App存在不合理的设计、限制和使用条款等问题时,用户将通过应用商店向开发者反映问题,在撰写评论文本时会以疑问句的形式表达。经总结得到17个疑问句式。表3是用户对“QQ”的疑问句式评论。

表3 疑问句式评论样例
(3)抱怨句式。当App出现的错误严重影响使用或已存在问题长时间未得到解决时,会引起用户的不满情绪,用户对App进行评价时发泄不满情绪,用含有抱怨语气的句式表达App的缺陷。经总结得到25个抱怨句式。表4是用户对“QQ”的抱怨句式评论。

表4 抱怨句式评论样例
(4)惋惜句式。App的某些属性或功能低于用户期望且开发者对此进行优化调整的可能性较小时,用户会在撰写评论文本时以惋惜语气的句式表达。经总结得到10个惋惜句式。表5是用户对“QQ”的惋惜句式评论。

表5 惋惜句式评论样例
(5)建议句式。部分用户对App整体较为满意并希望持续使用,他们会在应用商店平台向开发者提出优化建议,因此在撰写评论文本时会以建议语气的句式表达。经总结得到15个建议句式。表6是用户对“QQ”的建议句式评论。

表6 建议句式评论样例
(6)期望句式。部分用户根据自身使用体验希望开发者对现有版本功能进一步优化时,会用期望的句式撰写评论文本。经总结得到8个期望句式。表7是用户对“QQ”的期望句式评论。

表7 期望句式评论样例
最终总结所得固定句式共计87个,每个类型选择3个固定句式展示(见表8)。
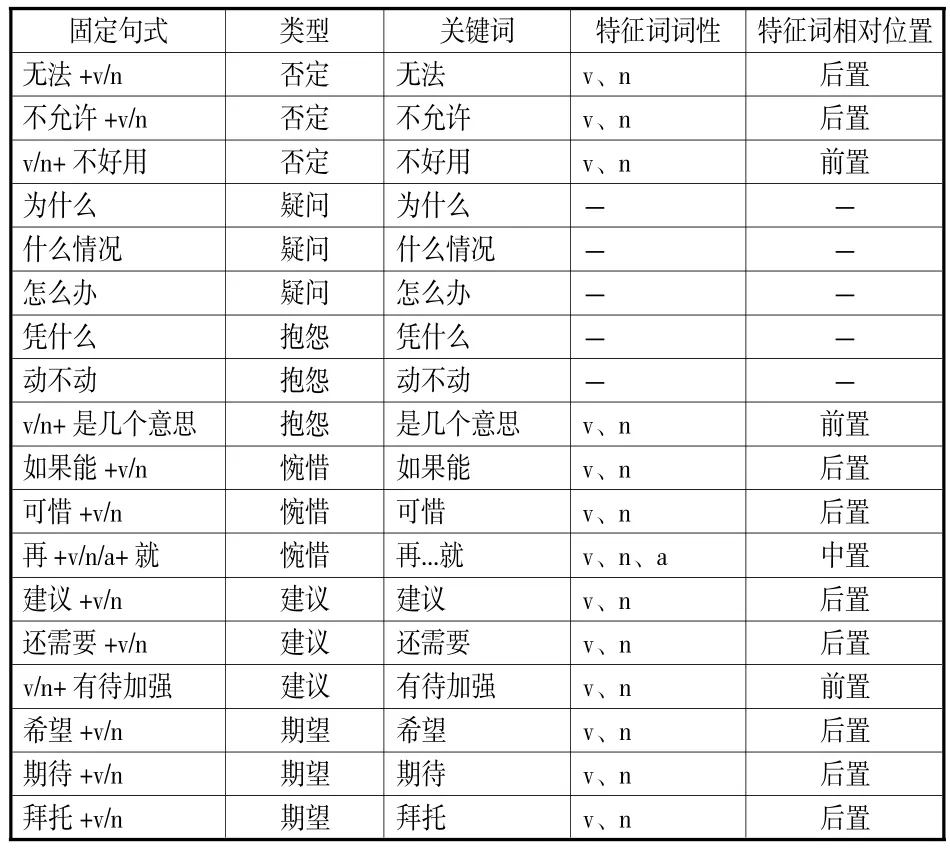
表8 固定句式样例
4.2 基于情感倾向的特征请求评论识别
对App用户评论进行分析,可以发现当评论文本的情感倾向为负向时,评论内容更有可能包含使用体验、功能需求、错误反馈和优化建议等信息,即可以从中提取出软件特征。而情感倾向为正向时,评论文本多为用户对App整体的情感态度,缺少评价对象。本文尝试对评论文本进行情感挖掘,根据情感倾向判断评论是否为特征请求评论,将负向情感倾向的评论筛选出来作为非特征请求评论。实现方法为情感词典分析法,情感词典采用大连理工大学情感词汇本体库。
4.3 基于句式匹配和情感倾向的特征请求评论识别
首先,对评论集合R2进行句式匹配,筛选出符合固定句式的评论;其次,对剩余不含固定句式的评论进行情感分析,筛选出情感倾向为负向的评论;最后,将两种方法识别得到的评论进行合并,得到特征请求评论集合R3。上述方法就是基于句式匹配和情感倾向的特征请求评论识别方法,实现工具为Python程序。
4.4 识别效果评价
通过基于句式匹配和情感倾向的识别方法得到的特征请求评论集合为R3,即软件特征挖掘范围。为验证该识别方法的效果,将评论集合R2的人工标注结果作为识别结果的评判标准。评价指标选择准确率和召回率,计算公式[20]如下。
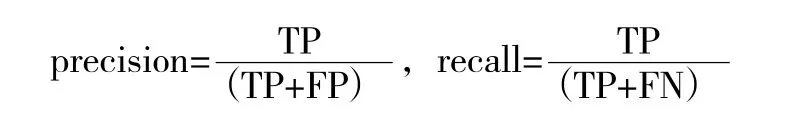
在分类过程中,准确率和召回率值越大代表分类效果越好。为了综合比较分类性能,引用准确率与召回率的调和平均值F_score,计算公式[20]如下。

以人工标注结果为参考,利用准确率、召回率和F_score3个指标衡量,基于句式匹配和情感倾向的特征请求评论识别方法对10个App的用户评论识别效果见表9。
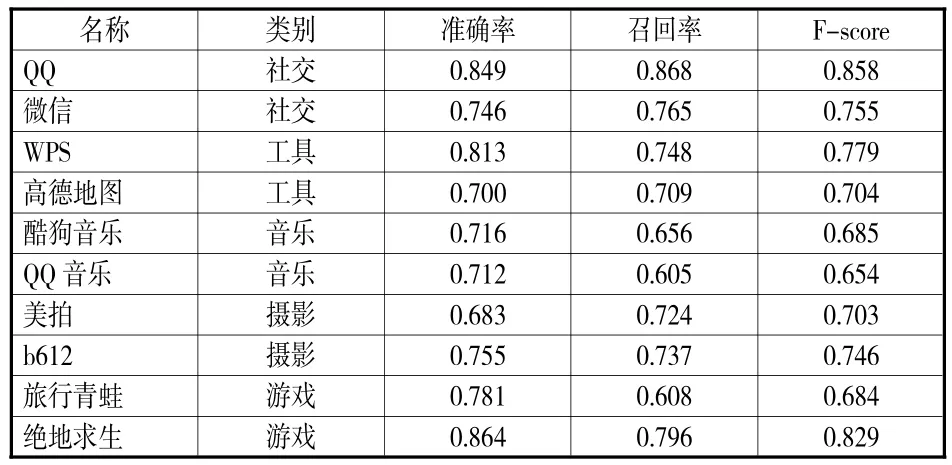
表9 特征请求评论识别效果
基于句式匹配和情感倾向的特征请求评论识别方法的3个衡量指标值全部在0.7左右,均值分别是0.747、0.712、0.728,说明比较稳定。
5 软件特征提取
在特征请求范围提取软件特征阶段,本文通过基于关联规则算法的Python程序实现,由以下5个步骤组成。
(1)创建关联规则事务文件。这一步骤采用特征请求评论集合R3的评论文本创建关联规则事务文件。以评论文本为事务单位,提取评论中的全部名词、名词短语、动词和动名词短语作为项,以文本文件格式存储。
(2)确定候选软件特征集合。利用关联规则Aprioir算法从事务文件中找出满足最小支持度为1%[21]的频繁项作为候选软件特征集合I0,不考虑3项以上的频繁项。[22]
(3)候选软件特征集合剪枝。根据中文评论的临近规则,[21]对候选软件特征集合I0进行剪枝,得到候选软件特征集合I1。
(4)独立支持度修正。根据中文评论中的独立支持度定义,[21]确定最小独立支持度为3,过滤候选软件特征集合I1中独立支持度小于3的项,得到候选软件特征集合I2。
(5)过滤非软件特征词。将App软件用户评论中的高频非软件特征词从候选软件特征集合I2中过滤掉,形成最终的软件特征集合I。非软件特征词包括2种类型:① App软件、开发商的名称及其简称,如“酷狗音乐”“酷狗”“百度网盘”“百度”。② 表达用户情感倾向、与App功能属性不相关的动词,如“喜欢”“希望”“感觉”“建议”。
6 结果与分析
6.1 提取结果
通过上述方法在软件特征挖掘范围即特征请求评论集合R3内提取软件特征,选取每个App软件特征集合I中频率排在前10位的元素,结果见表10。

表10 App软件特征
观察表10可以发现,提取出的软件特征与多种类型的特征请求相关。以“QQ”为例,第一个软件特征“闪退”,其所在的评论文本反映了用户对系统稳定运行的特征请求,内容类型属于错误异常反馈;最后一个软件特征“适配iphonex”,其所在的评论文本表达的是用户对兼容最新手机型号的特征请求,内容类型属于新功能请求。其余8个特征所在的评论文本都与用户对改进现有功能的特征请求相关,内容类型属于功能优化建议,如特征“消息”的一个所在评论文本“好友发来的消息总是延迟通知,这个缺陷难道很难修复吗?”由此可见,挖掘所得软件特征来自错误异常反馈、新功能请求和功能优化建议等不同类型的特征请求评论文本。因此,进一步挖掘用户对具体特征的情感态度来获取特征请求是开发者获取用户反馈的一种有效途径。
6.2 结果评价
以人工标注结果为参考,利用准确率、召回率和F_score3个指标衡量,10个App的软件特征获取结果见表11。
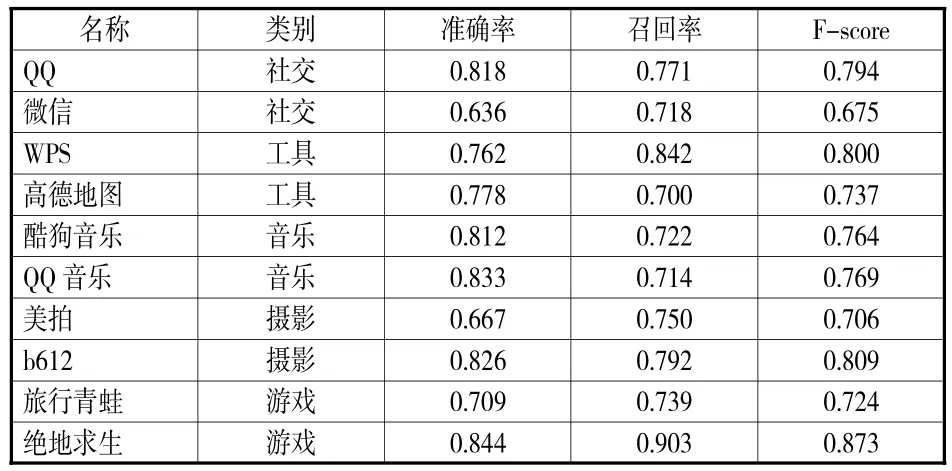
表11 App软件特征挖掘结果
观察表11可得,各App的准确率、召回率和F-score较为稳定。为进一步验证方法的有效性,本文设置对照实验,将未经范围识别的评论集合R2作为实验数据,用同样的提取方法进行实验,并记录2次实验结果的平均值以及同类研究的结果(见表12)。
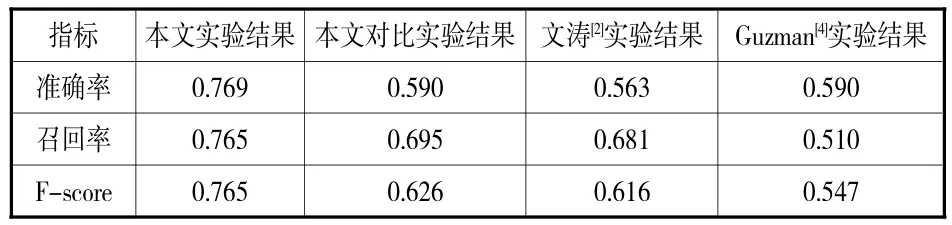
表12 App软件特征挖掘结果
由表中数据可得,本文实验结果的3个指标均优于对照实验结果,表明在软件特征提取前进行挖掘范围识别是十分必要的。本文实验较同类研究在准确率、召回率和F-score均有改善,验证了软件特征提取方法的有效性。
7 结语
面对数量激增的App用户评论,开发者如何高效地从中获取软件特征以协助App的改进和演化,已经成为一个亟待解决的问题。本文提出基于挖掘范围识别和关联规则算法的App用户评论软件特征获取方法:收集大量评论数据并进行预处理,利用基于句式匹配和情感倾向的识别方法确定包含特征请求的评论范围,并通过关联规则算法提取出软件特征。结果表明了该方法的有效性。
但是,本文存在一定局限性。首先,在挖掘范围内基于关联规则算法提取软件特征时选取满足最小支持度的频繁项加入到候选项中,没有对非频繁特征项进行处理。今后研究可将非特征频繁项加入到软件特征集合中,以补充关联规则算法提取的结果,从而最大限度地提高软件特征挖掘的准确性和全面性。其次,本文只选取了应用商店内5个类别的App用户评论,后续研究应涉及更多类别的App或者其他类型的软件产品,以增加研究资料的推论价值。
