面向不平衡数据的分类算法①
2019-08-22蒋宗礼史倩月
蒋宗礼, 史倩月
(北京工业大学 信息学部,北京 100124)
不平衡数据指在数据集中一类或多类的样本数量远远超过其他类的样本数量,疾病诊断[1]、情感识别[2]、故障诊断[3]等常见数据都是不平衡数据.通常,令多数类样本为负类,少数类样本为正类. 传统分类算法使用不平衡数据时的分类结果往往偏向多数类样本,性能较差,提高不平衡数据的分类精度成为当前的研究热点.
针对上述问题,Chawla等人[4]提出SMOTE (Synthetic Minority Oversampling Technique),该算法在少数类样本与其邻近点间通过乘以0到1的随机数线性插入样本. Han H等人[5]提出Borderline-SMOTE方法,将样本数据点分为安全点、边界点和噪音点,在分类边界通过SMOTE方法生成数据. Barua等人[6]提出MWMOTE,根据少数类样本距离和密度因素赋予对应信息权重,使用聚类方法生成簇并用SMOTE合成少数类样本.以上方法多数在边界生成数据,容易造成模糊边界的问题,并且多以欧几里得距离计算样本的分布,难以接近真实的数据分布,可能会产生噪声而误分.
变分自编码器(Variational Auto Encoder,VAE)[7]是由Kingma DP和Welling M在2014年提出的生成模型,是深度学习方法中的一种无监督模型. 作为热门的生成模型之一,已有许多学者对其进行研究,文献[8]提出基于变分自编码器进行异常检测,文献[9]使用变分自编码器提取语言特征,文献[10]提出了一种基于变分贝叶斯自编码器的局部放电数据匹配方法.
现有的过采样预处理方法主要通过计算欧几里得距离、密度等影响因素来学习数据间的分布. 然而,随着互联网的发展,数据以大容量、高维度、不平衡的趋势递增,只根据简单的衡量因素生成的样本无法全面代表大量的高维样本数据. VAE已广泛应用于计算机视觉、图像处理、自然语言处理等领域. 但其发展时间较短,还需突破更多的领域,本文对其做了探索,结合过采样来解决不平衡数据引起分类误差问题.
不平衡数据分类问题广泛影响着现实生活. 例如,医疗诊断领域的基因表达样本,其特征展现出高纬度的特点,决定疾病的特征占其中的极少数,同时,疾病的样本数量远远小于其他的样本数量,呈现出高度的高维不平衡性使数据分类时忽略极少数的癌变基因.在银行信用卡欺诈检测中,欺诈交易占数据的极少数使分类容易误分欺诈交易数据,而对欺诈数据的误分类造成的代价往往更严重. 网络入侵、情感分类、语音识别等领域都存在明显的数据不平衡特性. 为验证本文提出模型可以有效改善原始不平衡数据对分类产生的偏斜影响,使用UCI数据库四个常用的数据集进行实验,结果证明使用变分自编码器数据预处理相比其它过采样算法提高了算法的F_measure和G_mean,具有重要的现实意义.
1 相关工作
1.1 不平衡数据处理常用方法
不平衡数据训练时多数类样本信息占主导地位,导致分类结果偏向多数类样本,主要有数据层面和算法层面的解决办法[11].
数据层面通过重新分布数据以减小不平衡度,包括欠采样,过采样和混合采样. 欠采样即去除多数类样本,如随机欠采样、Tomek Links,欠采样方法虽然可以使数据达到平衡状态,但是在减少样本的同时也减少了对分类有重要影响的样本信息,会影响分类结果.过采样即增加少数类样本,如随机过采样、SMOTE、Borderline-SMOTE,但其容易导致分类过拟合,且存在模糊边界等问题. 混合采样结合欠采样和过采样方法,如SMOTE+Tomek Link算法[12],该算法首先使用SMOTE生成数据,然后利用Tomek Link方法清理噪声数据.
算法层面典型的解决方法有代价敏感算法[13]和集成学习方法[14]. 代价敏感方法对不同的类赋予不同的错分代价以降低少数类样本的错分率,集成学习方法集合多个弱分类器并赋予不同的权重来提高分类性能.算法层面的解决方法主要针对某一类数据集改进,难以扩展.
1.2 自动编码器
自动编码器(Auto-Encoder)由Rumelhart在1986年提出,其网络结构如图1所示. 其中,输入层到隐藏层的映射表示为编码器,隐藏层映射到输出层构成解码器.

图1 自动编码器网络结构图

编码过程:
解码过程:

其中,w,w′为权重矩阵,b,b′为偏置项. s(x)为激活函数,通常取线性函数或者Sigmoid函数.

自动编码器首先对输入向量x编码得到编码结果z,然后对z解码得到重构向量x′. 其学习过程是无监督的,目标是使输出数据尽可能重现输入数据,即最小化重构误差.
自动编码器是一种数据压缩算法,编码阶段将高维数据映射成低维数据,实现数据的特征提取,解码阶段则与编码阶段相反,从而实现对输入数据的复现[15].
2 改进的不平衡数据分类模型
深度学习通过对输入数据进行多层特征变换可学习到更复杂的数据特征,变分自编码器由神经网络学习训练样本的分布,可以生成与训练样本近似的数据,本文结合变分自编码器解决传统过采样技术的过拟合问题.
2.1 变分自编码器
变分自编码器基于变分下界和贝叶斯理论,目标是最大化边缘似然函数的变分下界,其模型图如图2所示.
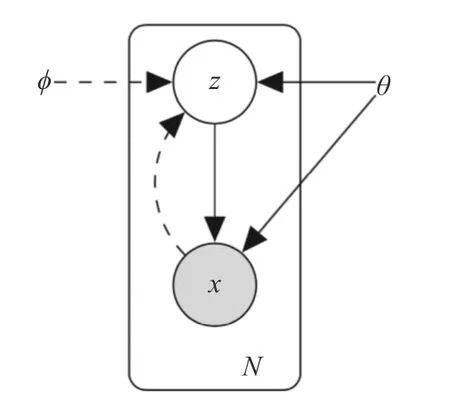
图2 变分自编码器的图模型
其中,z为隐变量,x是希望生成的目标数据. 虚线表示后验分布pθ(x|z)的近似分布qφ(z|x),实线表示生成模型pθ(x|z)pθ(z),φ,θ是在训练过程中共同学习的网络层参数[16].
变分自编码器目标函数的推导过程如下:
假设X={x(1),···,x(N)}是独立同分布的数据集,x(i)由条件分布pθ(x|z)生成,z服从先验分布pθ(z),数据集x的对数似然函数可写为式(4)
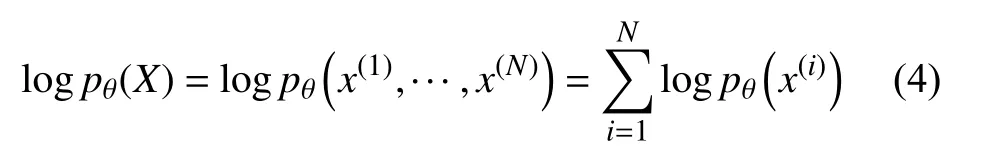
x(i)的边缘似然函数为

为求解对数似然函数,引入后验概率pθ(z|x)和pθ(z|x)的近似后验概率qφ(z|x). 使用KL散度(Kullback-Leibler Divergence,KLD)衡量与的距离:

代入贝叶斯公式,并进一步化简,式(6)可得出如下公式:


由于KL散度非负,存在不等式(9):
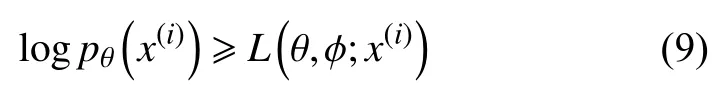
由此得到目标函数的变分下界:
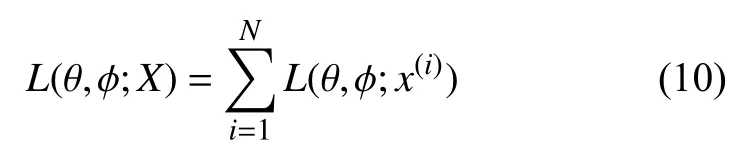
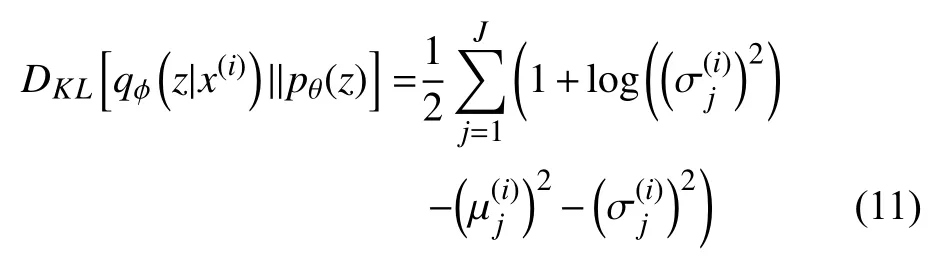
其中,j为σ(i)的第j个元素,µ(i),σ(i)由编码器计算得出.

式(12)从N(µ,σ2)采样z后计算logpθ(x(i)|z(i))的平均值,该过程不可微. 变分自编码器通过参数重构化解决式(12)无法梯度下降求解的问题,参数重构引入了噪声随机变量ε∼N(0,1),令z=µ(i)+σ(i)⊗ε(i),将采样步骤与模型参数分离.
转换后的目标函数L(θ,φ;x(i))如式(13)所示:
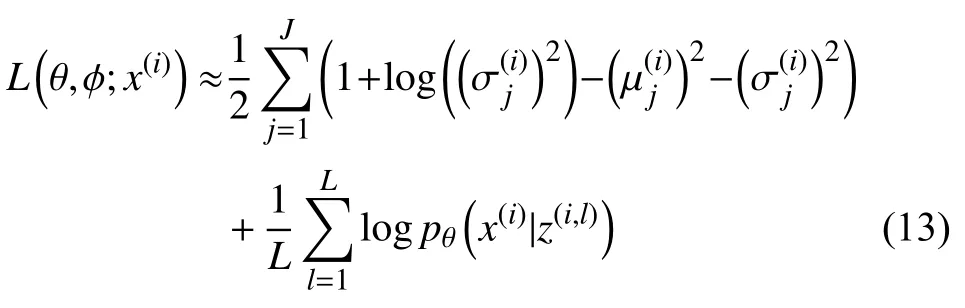
2.2 融合变分自编码器的不平衡数据处理
利用过采样和变分自编码器的优点,本文提出融合变分自编码器的过采样预处理技术,首先使用变分自编码器学习少数类样本的分布特征,然后利用自编码器的生成器生成相似数据以降低原始数据的不平衡度,最后将平衡后的数据作为输入数据训练逻辑回归分类器. 整体分为以下3个阶段:
第一阶段:变分自编码器学习少数类样本分布特征.
变分自编码器的结构与自编码器相似,编码器Q将输入数据经过多层非线性特征转换映射为高斯分布,解码器P将由高斯分布采样的隐变量重构为输入数据.
变分自编码器的结构图如图3所示.

图3 变分自编码器结构图
本文令编码器Q和解码器P为含有一个隐藏层的神经网络.
其编码器和解码器的模型如图4所示.

图4 变分自编码器的编码器和解码器模型图
编码器:

解码器:

其中,W1,W2,W3,W4,W5为变分自编码器的连接权值矩阵,h1,h2,h3,h4,h5为自编码器的偏置向量.
对构建的变分自编码器,采用随机梯度下降算法最小化重构误差进而不断调整自编码器网络的参数W,b,第l层的Wl,bl更新公式如下:
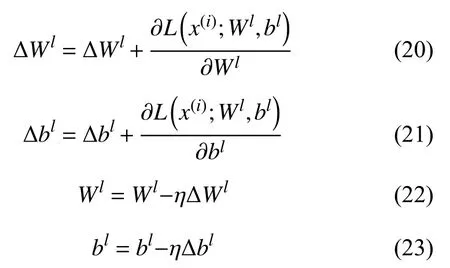
第二阶段:采样隐变量并输入到生成器中生成指定数量的样本.
由于变分自编码器假设先验分布为高斯分布并进行了参数重构化,因此只需要从标准正态分布中采样隐变量,将其输入到第一阶段训练的生成器中就可以生成相似样本. 生成样本的数量对分类结果有至关重要的作用,目前还没有统一的方法决定样本采样量,本文通过观察不平衡率与分类结果折线图找到最优采样量.
第三阶段:将生成数据与原始数据结合作为输入数据训练逻辑回归分类器.
整体模型结构如图5所示.
融合变分自编码器的不平衡数据处理训练算法如下:

算法1. 融合变分自编码器的不平衡数据分类算法1) 将样本数据集分为训练集和测试集.Xminµ,σ 2) 训练集的少数类样本作为输入数据输入到变分自编码器中,根据公式(15)(16)计算.N(0,1)εz=µ+σ·ε 3) 从采样,根据公式计算隐变量z.4) 隐变量z输入到解码层,根据公式(19)计算输出y.L(W,b;X)5) 根据公式(13)计算损失函数,根据公式(20)-公式(23)更新参数. 若算法不收敛,重复步骤2)-步骤5); 若收敛,停止训练.6) 通过变分自编码器的生成器生成N个数据.7) 生成样本数据和原训练集数据结合,输入到逻辑回归分类器中训练.8) 测试集作为输入数据,输入到训练好的分类器中计算评估分数.
3 实验分析
3.1 数据集描述
本次实验所用数据集为UCI 4个常用的数据集[17,18],具体描述如表1所示.
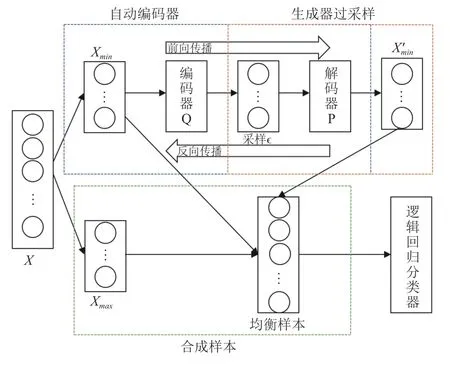
图5 不平衡数据分类结构图
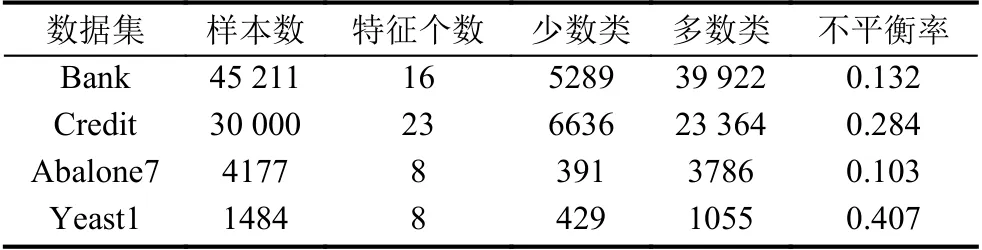
表1 数据集信息
其中,bank指UCI Bank Marketing银行营销数据集,该数据集通过客户信息以及对客户的电话联系判断客户是否将认购定期存款. credit指UIC default of credit card clients数据集,该数据集目的是预测用户是否会违约拖欠付款. Abalone7是UCI abalone数据集,该数据集通过物理量法预测鲍的年龄,本文令年龄7岁为正类,其它年龄为负类. yeast1是UCI Yeast数据集,其目标是预测蛋白质的细胞定位点,本文令类AUC为正类,其它类为负类.
3.2 评价指标
传统方法使用准确率(正确分类样本个数/总样本个数)评估分类结果,该评估指标可以准确评价平衡数据集的分类,但是衡量不平衡数据集时忽略了少数类样本的分类精度[19]. 例如,样本数据集中少数类样本占比为10%,多数类样本占比为90%,若把所有样本分类为多数类样本,准确率为90%,但是少数类样本分类精度为0.
根据混淆矩阵(如表2所示),有以下评价指标:
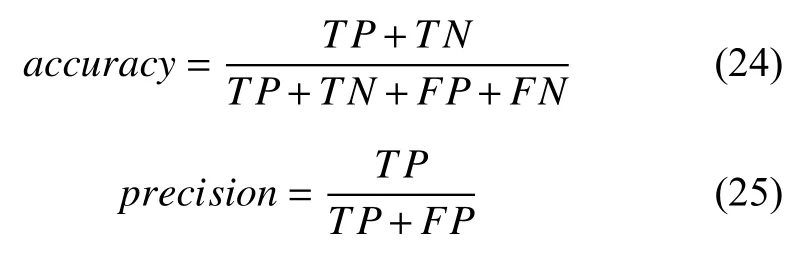

查准率(precision)表示被正确分类的正类样本占所有预测为正类样本的数据比例. 查全率(recall)表示被正确分类的正类样本占所有正类样本的比例.F_Measure综合考虑了precision和recall,是两个衡量指标的调和平均,可以评价分类器的整体性能,当两者都较大时,F_Measure才会较大. G_mean是少数类样本分类精度和多数类样本分类精度的几何平均值,可评价分类器对于每一类的分类性能. F_Measure和G_mean更适合评价不平衡数据的分类性能,本文选择F_Measure,G_mean和准确率accuracy作为评价指标.

表2 混淆矩阵
3.3 数据采样量对分类的影响
为验证VAE数据预处理解决不平衡数据问题的有效性,实验对比了不进行数据预处理以及使用SMOTE、Borderline-SMOTE、ADASYN过采样方法后的分类性能. 实验均采用十次五折交叉验证的平均值作为实验结果.
不平衡率对分类器的性能起至关重要的作用,图6展示了不断增加少数类样本后不平衡率对应的F_Measure值,图7展示了不断增加少数类样本后不平衡率对应的G_mean值.
通过图6和图7看出,不同数据集对应的最优采样率不同. 经过对比发现Bank采样后不平衡率到达0.4最优,Credit采样后不平衡率到达0.65最优,Abalone7采样后不平衡率到达0.6最优,Yeast1采样后不平衡率到达1.1最优. 虽然Bank数据集和Abalone数据集使用VAE预处理的G_mean值略低于其它预处理方法的G_mean值,但是经过VAE预处理的F_Measure值几乎都高于其他预处理方法的F_Measure值,可以看出VAE预处理具有更好的分类性能.

图6 4个数据集采样后不平衡率对应的F_Measure值
3.4 实验结果
表3分别列出了4个数据集使用不同预处理方法在最优采样率下的F_measure,G_mean和准确率.LR表示直接对不平衡数据使用逻辑回归分类器分类.
由表3可知,数据集使用变分自编码器数据预处理对比其它预处理方法有明显提高. Bank数据集使用VAE预处理对比直接进行分类提高了25.6%,对比使用SMOTE方法提高了0.16%,对比使用Borderline-SMOTE提高了2.30%,对比使用ADASYN提高了0.00%.credit数据集使用VAE预处理对比直接进行分类提高了49.1%,对比使用SMOTE方法提高了2.57%,对比使用Borderline-SMOTE提高了3.18%,对比使用ADASYN提高了3.39%. Abalone7数据集使用VAE预处理对比直接进行分类提高了387倍,对比使用SMOTE方法提高了4.30%,对比使用Borderline-SMOTE提高了4.86%,对比使用ADASYN提高了3.19%. Yeast1数据集使用VAE预处理对比直接进行分类提高了76.9%,对比使用SMOTE方法提高了2.07%,对比使用Borderline-SMOTE提高了3.14%,对比使用ADASYN提高了2.25%. 对于4个数据集F_Measure平均值,变分自编码器使用VAE预处理对比不进行数据预处理提高80.3%,对比SMOTE方法提高2.12%,对比Borderline-SMOTE方法提高3.31%,对比ADASYN方法提高2.12%.
数据集使用变分自编码器数据预处理整体提高了G_mean值. 对于Bank数据集和Abalone7数据集,本文方法略低于其它数据预处理方法,但是在Credit数据集上实验,本文方法对比不进行预处理提高了38.1%,对比SMOTE方法提高了2.03%,对比Borderline-SMOTE提高了1.71%,对比ADASYN方法提高了2.5%.在Yeast1数据集上实验,本文方法对比不进行数据预处理提高了51.7%,对比SMOTE方法提高了1.13%,对比Borderline-SMOTE提高了3.03%,对比ADASYN方法提高了2.30%. 对于4个数据集F_Measure平均值,变分自编码器使用VAE预处理对比不进行数据预处理提高了86.9%,对比SMOTE方法提高了0.41%,对比Borderline-SMOTE方法提高了0.97%,对比ADASYN方法提高了0.41%.
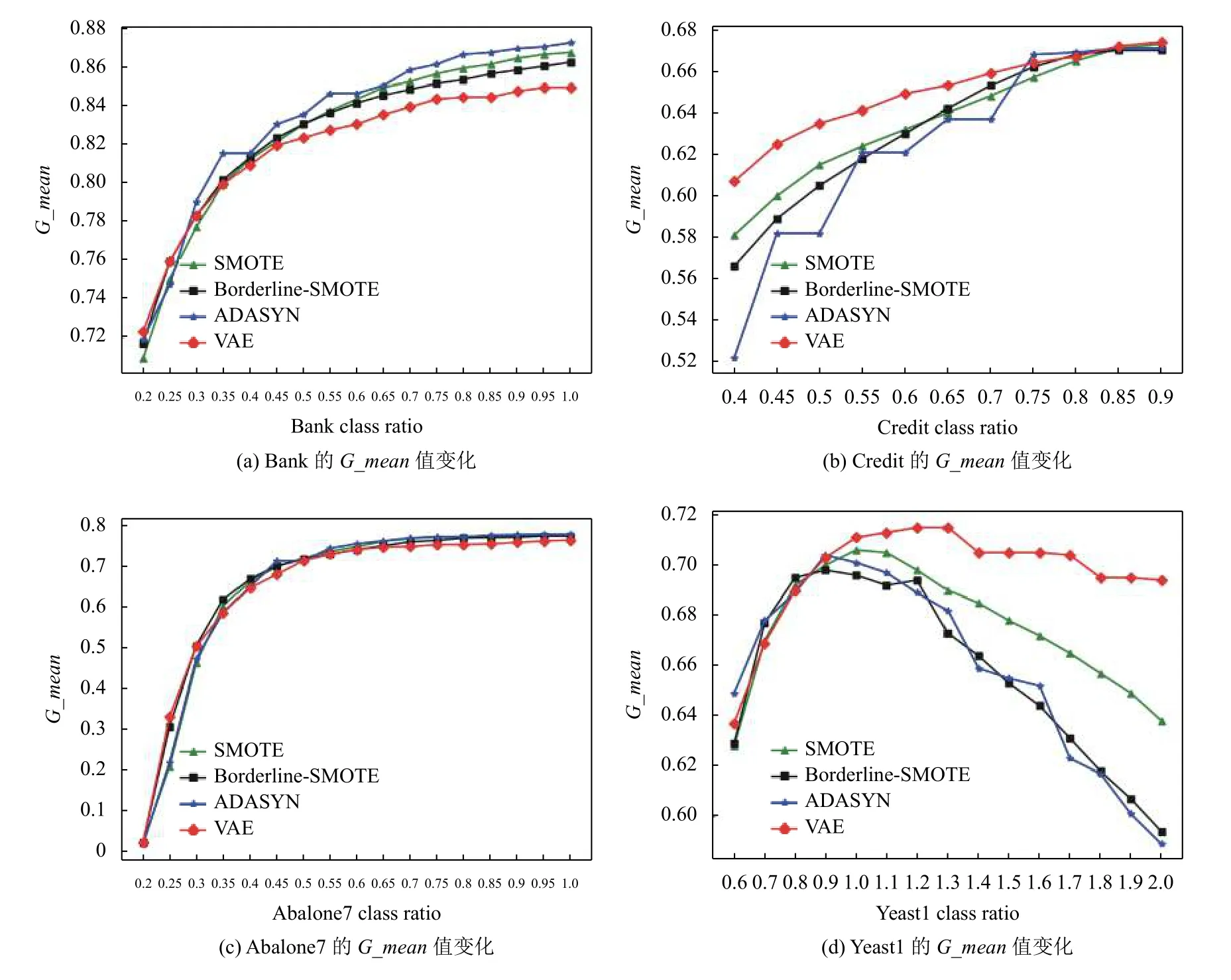
图7 4个数据集采样后不平衡率对应的G_mean值

表3 数据集使用不同方法的F_Measure,G_mean,accuracy
数据集使用变分自编码器数据预处理对比其它预处理方法整体上提高了分类准确率. Bank数据集使用VAE预处理对比直接进行分类降低了0.55%,对比使用SMOTE方法提高了0.33%,对比使用Borderline-SMOTE提高了1.12%,对比使用ADASYN提高了0.22%. Credit数据集使用VAE预处理对比使用SMOTE方法降低了1.11%,对比使用Borderline-SMOTE降低了0.62%,对比使用ADASYN降低了0.37%. Abalone7数据集使用VAE预处理对比使用SMOTE方法提高了1.13倍,对比使用Borderline-SMOTE提高了1.15倍,对比使用ADASYN提高了17.9%. Yeast1数据集使用VAE预处理对比使用SMOTE方法提高了4.63%,对比使用Borderline-SMOTE提高了9.04%,对比使用ADASYN提高了8.40%. 对于4个数据的accuracy平均值,变分自编码器预处理对比SMOTE方法提高11.3%,对比Borderline-SMOTE方法提高18.2%,对比ADASYN方法提高2.42%.
3.5 实验结果分析
由表3可以看出,直接使用逻辑回归分类器对不平衡数据分类的F_Measure和G_mean值很低,分析其原因,是由于逻辑回归算法平等的看待每一类样本,而少数类样本提供给分类器的有效信息极少,分类器将大部分样本预测为多数类样本以保证较高的准确率,导致少数类样本的准确率严重降低. 为解决此问题,本文在样本输入到分类器之前进行过采样处理均衡正负类样本提高少数类样本精度.
相较于SMOTE、Borderline-SMOTE、ADASYN算法,本文提出的算法其准确率、F_Measure和G_mean更高. 可见,相比仅通过欧几里得距离及其改进算法衡量数据间的分布情况,本文通过含有多个神经元的隐含层线性学习并使用激活函数非线性变换,学习样本的不同特征分布,以此学习到的分布更接近真实数据分布. 另外,借助变分自编码器的思想,使采样的数据通过解码器生成的少数类样本更符合原始数据的特征.
变分自编码器充分考虑了少数类样本不同层次的特征,可以生成更广泛的少数类样本,从而有效提高了分类器的泛化能力. 因此,本文提出方法训练的分类器预测测试样本时,准确率、F_Measure和G_mean都较高.
综上所述,使用变分自编码器均衡不平衡数据集改善了原始数据集中多数类样本占主导作用使少数类样本准确率降低的问题,其生成的样本增加了分类时少数类样本的有效信息并提高了少数类样本的分类识别率,具有更高的分类精确度.同时,变分自编码器通过神经网络多次非线性特征转换学习到的数据分布特征更接近真实数据,改善了传统过采样技术产生无效的“人造样本”影响少数类样本分布导致模糊正负类边界的问题. 融入变分自编码器的过采样技术在提高少数类样本精确度的同时兼顾了多数类样本准确率.
4 结论
本文结合变分自编码器和过采样技术解决数据不平衡导致传统分类器分类性能较差的问题,该方法通过变分自编码器学习少数类样本的分布,使用其生成器生成相似的数据以均衡数据集. 实验结果表明变分自编码器生成的样本更接近真实数据,融合变分自编码器的数据预处理技术保证了较高准确率的同时提高了少数类样本的精确度,改善了不平衡数据的分类偏斜问题和传统过采样的过拟合问题.
