基于HMM的混响环境下语音识别研究
2019-08-22杜珍珍彭春堂
叶 硕,杜珍珍,彭春堂,贺 娟
(武汉邮电科学研究院,湖北 武汉 430000)
0 引 言
语音识别是当今的热门研究之一,自动语音识别(automatic speech recognition,ASR)技术是实现人机交互的关键[1]。在人机交互过程中,非特定人的语音识别具有广阔的应用前景。隐马尔可夫模型(hidden Markov model,HMM)是语音识别技术中的重要模型之一,根据不同需要对建模对象进行变化,可实现不同作用,比如说话人识别[2]、连续语音识别[3]、情绪识别等[4]。
语音识别环境多变,当人处于狭小环境或声源距离声音采集器较远时,由墙壁、物体反射的延迟且衰减后的声音信号与源信号叠加在一起引起混响。这种与原始信号叠加形成的干扰,会导致卷积失真,大大降低了语音的清晰可懂度。
在去混响领域,学者们做过许多研究,如文献[5]对混响声场进行了细致的分类,文献[6]分析了不同手段去混响的效果。文中基于HMM,提出一种使用卷积同态滤波器去混响的方法。在预处理阶段对混响语音进行降噪,提高语音在混响环境下的识别精度,并借助MATLAB完成仿真。
1 语音去混响方法研究
完整的识别过程如图1所示,可以分为语音采集、特征学习、识别匹配三个阶段。其中In1为训练模型所用的语音信号,In2为待识别语音信号,Out为输出识别语音。用于提取特征的语音,通常采集于无干扰的实验室环境,而待识别的语音,通常来自于存在干扰的环境。
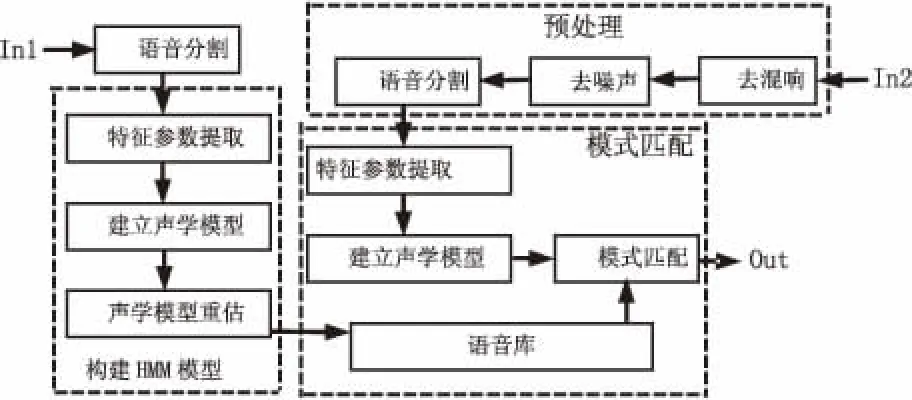
图1 基于HMM的语音识别系统框图
在某些场合,适度的混响会在听觉上使人感到舒适,但在信号处理领域,混响不但会导致语音信号幅值变化、相位延时、共振峰偏移以及产生其他谱峰,其拖尾的混响声部分还会掩盖后面语音的弱能量音部分。在进行语音识别时,混响使得测试集参数和训练集参数发生匹配失真,识别系统性能发生急剧下降[5]。
混响环境下,接收到的信号可用如下数学模型表示[6]:
其中,s(n)为有用信号;ak为反射系数;nk为反射波时延。x(n)又可表示为有用信号s(n)与混响环境下的冲激响应h(n)的卷积形式:
x(n)=s(n)*h(n)
为解决混响问题,现行方法大致有三种:基于复倒谱滤波(complex cepstrum filtering,CF)、基于复倒谱均值减(complex cepstrum mean subtract,CMS)以及基于波束形成(beam forming,BF)。文中采用复倒谱滤波的方法,该方法本质上属于同态滤波,能将非线性结合的信号变换为加性结合的信号,从而可以使用线性滤波的手段去除混响[7]。卷积同态系统由三个子系统级联而成:特征子系统、线性系统、特征子系统的逆系统。
特征子系统实现原理如图2所示,其作用是将信号的时域卷积形式变换为时域的线性运算。输入信号x(n),经Z变换后变为两信号频域的相乘,取对数进而得到频域线性运算,再进行逆Z变换,得到原始信号的时域线性形式,即复倒谱:

图2 特征子系统实现

2 HMM的语音识别算法
2.1 HMM的建立
孤立词或短词汇的语音识别算法一般分为两类:动态时间规整(dynamic time warping,DTW)和HMM。
DTW算法基于动态规划(DP)的思想,利用语音中逻辑的先后不可改变这一特性,能克服因发音习惯的不同而导致的语音信号与模板不匹配问题。但该算法只能识别特定说话人的特定文本,具有局限性,因此文中使用HMM来进行语音识别。
HMM是一种用参数表示的、基于语音信号的时间序列结构建立的、用于描述其随机过程统计特性的概率模型,在处理离散时间序列的观察数据中应用广泛[8-9],能实现非特定说话人的语音识别。一般分为连续HMM(CHMM)、半连续HMM(SCHMM)以及离散HMM(DHMM)[10],该模型表明,当前状态只与前一时刻所处的状态有关。
对比DTW,HMM的特点是:状态隐含、观察可测。将语音部分分割成极小的时间片段,那么该片段的特性近似稳定,总过程可视为从某一相对稳定特性到另一相对稳定特性的转移。
构建语音信号的HMM,将它的语音分成上下两层,下层是不可测的、有限状态数的、马尔可夫链模拟的语音信号统计特性变化的隐含随机过程;上层引入概率统计模型,是与马尔可夫链的每一个状态相关联的观测序列的随机过程[11]。
语音信号是一种非平稳信号,一段完整的语音信号可以分为静音、语音、停顿、语音、静音五个部分[12]。其中语音部分,又可将每一个音节分成构筑其发音的最小单位—音素。多状态的HMM构成一个音素,多个音素的HMM串接构成一个字,将多个字的HMM串接起来,便可得到词汇的马尔可夫链。图3所示便是一个音素与观测序列的关系,其中O1,O2,…,OT为观测得到的序列,若干个序列组成状态集S1,S2,…,而这个状态集便对应了语音的一个音素。

图3 HMM与语音参数关系
连续语音识别就是马尔可夫链和静音组合起来的HMM,用概率密度函数计算语音特征参数对HMM模型的输出概率,通过搜索最佳状态序列,以最大后验概率为准则找到识别结果[13]。
2.2 HMM的训练
一个HMM可由式λ=(π,A,B)描述,其中π为初始状态概率,A为状态转移概率矩阵,B为观测概率矩阵。π和A决定状态序列,B决定观测序列。作为参数重估问题,HMM需要解决三个问题[11,13-14]:
(1)输出概率计算问题。
该问题是语音信号的建模问题。已知观测序列O={O1,O2,…,OT}和隐马尔可夫模型λ=(π,A,B),将所求观察序列在HMM下出现的条件概率分成两部分,分别利用前向算法、后向算法将求得的条件概率进行乘积,进而得到整个观察序列的输出概率,以达到降低计算复杂度的目的。
定义HMM的前向概率为αt(i)=P{O1,O2,…,OT;qt=i|λ},表示在给定HMM参数λ的前提下,观测序列为{O1,O2,…,OT}在t时刻处于隐藏状态i的概率。前向概率αt(i)的递推公式如下:
初始化:α1(i)=πibi(O1),i∈[1,N]。

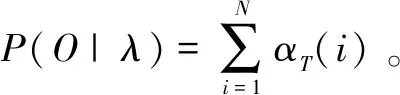
与前向概率相对应,定义后向概率为βt(i)=P{Ot+1,Ot+2,…,OT;qt=i|λ},表示在给定HMM参数λ的前提下,观测序列{Ot+1,Ot+2,…,OT}在t时刻处于隐藏状态i的概率。
后向概率βt(i)的递推公式如下:
初始化:βT(i)=1,i∈[1,N]。


经过分析,可得输出概率计算公式为:
反复迭代直到HMM参数不再发生明显变化为止。
(2)状态序列解码问题。
该问题是寻找最优匹配问题。Viterbi算法是一种广泛用于通信领域的动态规划算法,即用动态规划求概率最大路径,它克服了全概率公式无法找到最优状态转移路径的问题。给定观察序列和HMM,通过Viterbi识别算法确定一个最优的状态转移序列,并得到该路径所对应的输出概率。
初始化:δ1(i)=πibi(O1),ψ1(i)=0,i∈[1,N]。
迭代计算:

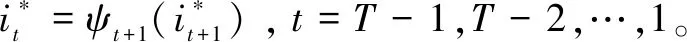
其中δt(i)为t时刻第i状态的累计输出概率,ψt(j)为t时刻第i状态的前续状态信号,为最优状态序列中t时刻所处的状态,为最终的输出概率。实际使用中,通常用对数形式的Viterbi算法,这样将避免进行大量的乘法计算,减少了计算量,同时还可以保证较高的动态范围,避免由于过多的连乘而导致溢出问题。在识别阶段,如果HMM模型为整词模型,就没有必要保存前续节点矩阵和状态转移路径,可以进一步减少计算量。
(3)模型参数的估计问题。
该问题是模型的修正问题,使HMM能够做到非特定人的语音识别。Baum-Welch算法是极大似然(ML)准则的一个应用,利用该算法对初始化的HMM参数进行训练重估,即多个不同人对同一条命令重复多次录入,分别计算各自的特征参数序列,得到重估模型参数,使P(O|λ)概率最大。

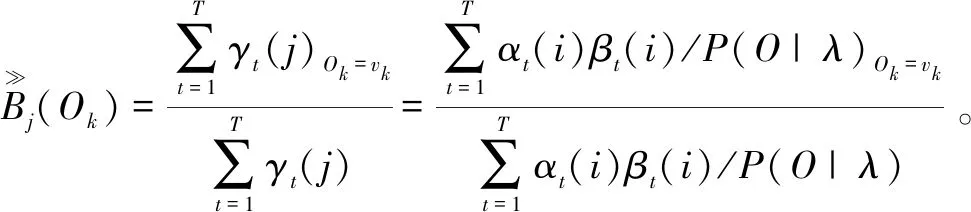
由于该系统采用从左至右、无跳转、单向结构的HMM模型,初始概率恒等于π1=1、πi=0,i∈[2,N],因此不需进行重估。
3 实验测试
文中的数据库为自建库,采用普通麦克风录制。测试中发现,当使用16 kHz及以上时,语谱图在4 000 Hz以上的频段依然存在大量数据,而人类发声系统一般发出的语音处于300 Hz~3 400 Hz之间。分析原因,是由语音信号采样率引起的,因此文中使用8 kHz的采样率。说话语音为普通话。
自建库包括两部分,一部分为训练语音:20个说话人录制10条时长为2 s的正常语音;另一部分为测试语音:30个说话人录制10条长为2~4 s的正常语音,再在狭小回廊环境录制10条长为2~4 s的语音作为混响语音。训练语音与测试语音文本相同。
实验开始对语音信号进行降噪处理,滤除高频噪声,然后进行端点检测等处理,截取语音信号中存在语音的部分。
图4展示了三组经过预处理后的图,分别为同一词汇的纯净语音、混响语音以及去混响后的语音;每组图片由两张图构成,分别为语音的时域图与语谱图。语谱图是语音的频谱图,其横坐标是语音持续的时间,纵坐标为语音的频率,坐标点值为语音的能量。通过观察可以发现,经过复倒谱滤波后,时域信号的振幅有所降低,对比语谱图可以发现,0.2~0.4 s的语音混杂程度有所降低。

图4 同态滤波去混响方法的时域图与语谱图
系统分训练和识别两个阶段。在语音识别中Mel频率倒谱系数(Mel frequency cepstrum coefficient,MFCC)将线性频标转化为Mel频标,能屏蔽大部分高频噪声的干扰,有利于识别信息。因此在训练阶段提取训练语音信号的MFCC参数,对10条语音分别建立HMM。
在识别阶段,将带混响的语音信号输入采集器,使用卷积同态滤波去除混响,提取语音信号的MFCC参数,建立待识别语音的HMM,将测试语音的HMM模型与训练库中的各个模型应用Viterbi算法进行搜索,找到输出概率最大的训练模型。
表1展示了基于HMM的语音识别结果,测试了该模型对正常语音、混响语音的识别情况。其中混响语音测试又分为a,b两个步骤,步骤a单纯测试该模型对混响语音的识别情况,步骤b则是将混响语音通过卷积同态滤波器后再进行识别。

表1 基于HMM的语音识别结果
可以看出,该模型在识别正常语音时具有较高的可靠性,实现了短词汇非特定人的语音识别,对比使用卷积同态滤波器前后的结果,能发现该系统对于混响语音的处理也具有一定的效果,识别准确率有所提升。
4 结束语
文中基本实现了混响语音的语音识别,实验结果表明,单纯使用复倒谱滤波的方法去混响,效果并不是特别明显。虽然HMM在语音识别方面用途广泛,但其浅层学习结构在海量数据下性能会受到限制[15-16],因此单纯使用HMM进行语音识别也遇到了很大阻力。随着机器学习的兴起,神经网络声学建模与传统手段相结合,将进一步推动语音识别技术的发展。
