动态路由胶囊网络的可视化研究
2019-08-22范文豪吴晓富张索非
范文豪,吴晓富,张索非
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 物联网学院,江苏 南京 210003)
0 引 言
传统的卷积神经网络比较擅长检测图像特征[1-2],但由于CNN中神经元的输入和输出都是标量,标量只能用来表示所提取到的特征存在的可能性,不能表示特征的空间信息,这就导致CNN探索特征间的空间关系能力欠佳[3]。同时CNN中的下采样层降低了图像的空间分辨率,一些空间信息就会丢失,使得CNN对于输入的一些小变化不敏感。例如当输入图像为人脸时,如果将他的鼻子和嘴巴位置互换,通常CNN会误认为这是一张人脸。这正是由于CNN特征的弱空间关联性造成的[4]。
为了解决CNN的这一缺陷,Sara Sabour等提出了动态路由的胶囊网络(capsule network)[5]。它与传统CNN的最主要区别在于,胶囊网络提出了一种由神经元组成的胶囊结构,它的输入输出都是矢量[6],不仅能够通过矢量的模长来表示某个特征出现的可能性,还能够通过矢量来表示特征的空间信息,包括位置、方向、大小、形变等。这样胶囊网络就能够学习到同一个特征的不同变体,还能很好地表达特征间的空间关联。
文中先对CNN中各层提取到的特征进行可视化,验证CNN中提取到的特征空间关联性的强弱。之后对胶囊网络中DigiCaps层最终提取到的矢量特征的不同维度分别进行改变,将得到特征的不同变体进行可视化[7]。通过可视化方法判断出提取到的矢量化特征是否包含空间信息,并通过不同变体的变化得出具体的空间信息,从而加深对胶囊网络所提取到的矢量化特征的理解。
可视化实验结果表明,CNN中提取到的特征空间的关联性较弱,而胶囊网络的矢量化特征确实包含了所提取特征的姿态、形变等空间信息[8-10],能够很好地表达特征之间的空间关联。
1 CNN的特征可视化
CNN主要由卷积层和池化层组成,对于多层的CNN,每一层所提取到的特征都是不完全相同的。为了验证CNN提取到特征的空间关联性的强弱,可以通过反池化和反卷积[11-12]的操作对每一层提取到的多个特征进行可视化,从而观察所提取到的特征间空间关联性强弱。
使用MNIST数据集[13-14]训练一个4层的CNN,其中每一层的卷积核尺寸都为5×5,卷积时所采用的padding为SAME模式,并在第二层和第四层卷积后加上大小为2×2的max pooling层。训练完成后对CNN每层所提取到的特征进行可视化,可视化结果见表1。从每层的多个特征中抽取出部分特征的可视化图像放入表中,表中包括输入图像以及CNN前3层特征的可视化。
从表1可以看出:CNN第一层提取出的特征主要是图像中数字的边缘和轮廓,第二层提取到的特征主要是数字边缘的颜色分布与数字内容,第三层则能够提取到数字一些局部特征以及少量的空间信息。可视化结果表明,普通的CNN提取空间信息的能力较弱,并不能够学习到同一个特征的多种不同变体,所以提取到特征的空间关联性也就较弱。
表1 CNN特征可视化

2 动态路由胶囊网络的特征可视化
2.1 胶囊网络的结构
胶囊网络中最重要的组成部分是胶囊。胶囊是由神经元组成的一个向量,能表征检测类型的多维实体的实例化参数和存在性。

图1 胶囊之间的转换结构
图1是胶囊网络中两层胶囊之间的转换关系,其中胶囊i和胶囊j都是矢量,ui为胶囊i的激活值,Wij,cij为两个胶囊之间的转换矩阵和权重:

通过非线性“压缩”函数(Squash函数)得到胶囊j的激活值vj:
胶囊网络中使用动态路由[15]迭代算法,迭代步骤如下:
1.令:bij←0(i∈l,j∈l+1)
2.forriterations do
ci←softmax(bi)(i∈l)
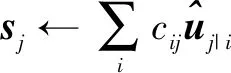
vj←squash(sj)(j∈l+1)
returnvj
图2为整个胶囊网络的结构。本次实验使用的是MNIST数据集,图中第一层为输入层,输入图像的尺寸为28×28×1;第二层为卷积层,使用卷积核尺寸为9×9×1×256,进行步长为1的VALID型卷积,这层把像素强度转换成局部特征检测信息;第三层为PrimaryCaps层,使用卷积核仍为9×9×1×256,进行步长为2的VALID型卷积,将得到结果组合成32×6×6个胶囊,每一个胶囊为8维的向量;第四层为DigiCaps层,共10个胶囊,每个胶囊为16维的向量,第三层输出经转换矩阵Wij和动态路由过程得到第四层输出;最后三层全连接层用来对图像进行复原。

图2 胶囊网络结构
2.2 胶囊网络特征可视化
实验使用MNIST数据集来训练胶囊网络[16-18],数据的预处理过程进行了简单的归一化处理,具体的训练参数见表2。其中DigiCaps层的维度是会随着实验改变的。

表2 胶囊网络主要训练参数
本次实验目的是研究出DigiCaps层胶囊提取到的矢量化特征所能代表的空间信息。实验的主要内容是改变DigiCaps层提取到的特征的某一维大小(其余维不变),按训练好的参数通过全连接层复原图像进行可视化,得到的复原图像会是同一个特征的不同变体,对比多个复原图像判断出所改变的那一维代表的空间信息。然后将DigiCaps层中胶囊特征的维数改变做同样的实验。
2.2.1 DigiCaps层胶囊中矢量化特征维数为16的可视化
当DigiCaps层胶囊中向量维数为16时,按照表2中的参数训练图2的网络后得到的loss值见图3。经过300个epoch之后,loss下降到0.003 5左右,最终测试得到的准确率在99.25%左右。
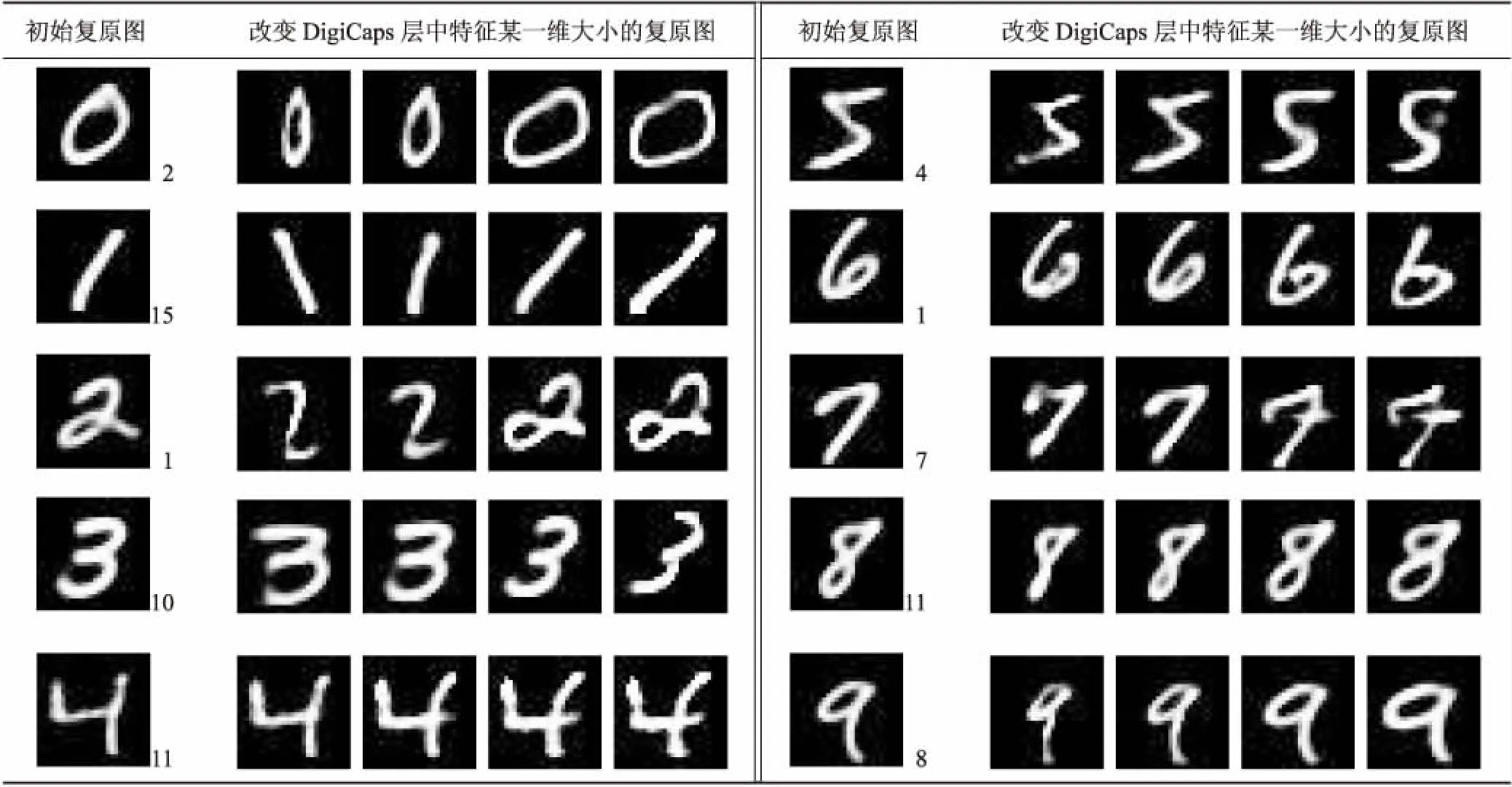
参数训练完成后,通过全连接层将输入的图像进行复原。表3中包括初始复原图和改变特征某一维大小得到的复原图。这里的改变某一维大小是指在特征某一维上加或减去一个小于1的合适的常数,多次改变大小将得到的复原图像进行对比。表3中初始复原图像的右下角数字代表修改的矢量化特征的维度。
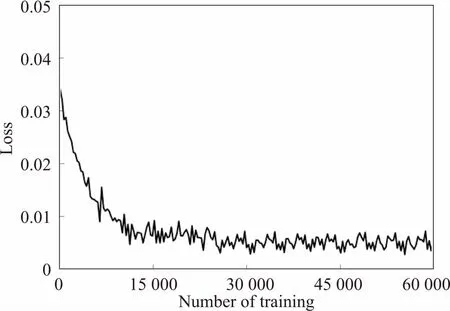
图3 维数为16时网络的loss
对比表3中复原图像可知,当改变特征某一维的大小后,会对数字的大小、旋转、局部形状、笔画的弯曲、粗细等产生影响。例如输入为0时改变特征的第2维发现数字的大小发生了变化,输入为1时改变特征的第15维时数字发生了旋转,输入为2时改变特征的第1维时数字的局部形状发生了改变。说明胶囊网络的矢量化特征是可以表示特征的空间信息的。从可视化结果可以看出,矢量化特征所提取到的空间信息主要是来源于同一类别的训练数据集的多样化。当DigiCaps层胶囊中矢量化特征维数为16时,对于MNIST数据集而言,16个维度足够提取出输入图像的绝大部分的空间信息,并且对同一类别16个维度所表示的空间信息有少部分是类似的。如果同一类别的训练数据集中数字图像的变化不是非常大,那么提取到的特征的部分维度所表示的空间信息有一些会比较相似,但是对于不同类别的输入,提取到的空间信息大多数是不相同的。
2.2.2 改变DigiCaps层胶囊中矢量化特征维数
将DigiCaps层胶囊中特征维数下降为8时,同样按表2中的参数训练图2网络,最终训练得到的loss值和维度为16时的loss值比较接近。测试得到的准确率在98.75%左右,相较于维度为16时的准确率稍有下降。
当矢量化特征维数下降为8时,仍然能提取到数据集的部分空间信息,它们与维数为16时提取到的空间信息基本相同,但是没有16维时提取的空间信息全面,并且在这8个维度所表示的空间信息中相互类似的越来越少。说明维数下降为8时也能够提取MNIST数据集的大部分空间信息,使得在复原图像过程中能够逼近原图像,维数为8时的loss值接近于维数为16时的loss值也从侧面说明了这一点。
将DigiCaps层胶囊中特征维数下降为4时,同样按表2中的参数训练图2网络,最终训练得到的loss值比之前的维度为16和8时都要大很多,大约在0.008左右,测试得到的准确率在98.5%左右,比之前维度为16和8时的准确率都要低。当矢量化特征维数下降为4时,只能够提取到数据集的一小部分空间信息,且4个维度所表示的空间信息一般各不相同。由于提取的空间信息较少,使得复原出的图像与原图像差距相对较大,因此矢量化特征维数为4时的loss值相对于维数为16和8时的loss值较大。
表3 维数为16时的特征可视化
根据以上实验得出,在选取DigiCaps层胶囊中矢量化特征维数时,应该根据训练数据集中同一类别所有图像所包含的空间信息的多少,也就是同一类别图像的多样化来判断适合的维数。维数过少会导致提取到的图像的空间信息较少,在复原图像时就会与原图有较大的差距,维数过多虽然能提取到更多的空间信息,但同时也会增加网络的参数量。
3 结束语
通过特征可视化的方法验证了CNN中提取到的特征空间关联性较弱,而胶囊网络提取到的矢量化特征确实包含了多种空间信息,这使得特征之间具有空间关联性,可解释性也更强。相比于CNN,胶囊网络不仅可以学习到输入图像的绝大部分空间信息,同时提取到特征的多种不同变体也可以通过改变DigiCaps层矢量化特征得到。但是CNN只能够提取到输入图像的少量空间信息,能够提取到的特征的不同变体也很有限。使得对于每个类别的输入,胶囊网络比传统的卷积网络能学习到一个更加鲁棒的表示。并且随着DigitCaps层特征维数的降低,矢量化特征所能提取到的空间信息越来越少,胶囊网络复原出的图像与原图差距也就越大。
对于MNIST数据集,胶囊网络只需要更少的训练数据就可以得到较高的准确率。并且胶囊网络比较擅长分割任务,在识别高度重叠的数字时,其效果要明显好于卷积神经网络,说明胶囊网络是一个值得探索的方向。
