信息融合理论研究进展:基于变分贝叶斯的联合优化
2019-08-21潘泉胡玉梅兰华孙帅王增福杨峰
潘泉 胡玉梅 兰华 孙帅 王增福 杨峰
信息融合技术以各类软/硬传感器为基础,通过数学方法和技术工具对获取的多源信息进行关联、估计和融合,以实现目标系统的协调优化和综合处理的目的.信息融合技术作为信息科学的一个热门领域,起源于20世纪70年代的军事应用.美军在采用多个独立的声呐自动探测某海域敌方舰艇位置时首次提出数据融合的概念,随后开发了战场管理和目标检测系统BETA[1−3],进一步证实信息融合的可行性和有效性,并促进了多源信息融合学科的形成和发展.经过20世纪80年代初直到现在的持续研究高潮,信息融合理论和技术进一步得到了飞速发展,信息融合逐渐作为一门独立学科被成功应用于军事指挥自动化、战略预警与防御、多目标跟踪与识别和精确制导武器等军事领域[3−6],并逐渐辐射到智能交通、遥感监测、医学诊断、电子商务、人工智能、无线通信和工业过程监控与故障诊断等众多民用领域[7−12].作者逐年查阅2015年∼2017年国际信息融合大会(FUSION)论文集,分别以研究背景和数学方法为分类依据给出近三年大会论文研究内容比例的统计数据(如表1和表2所示).
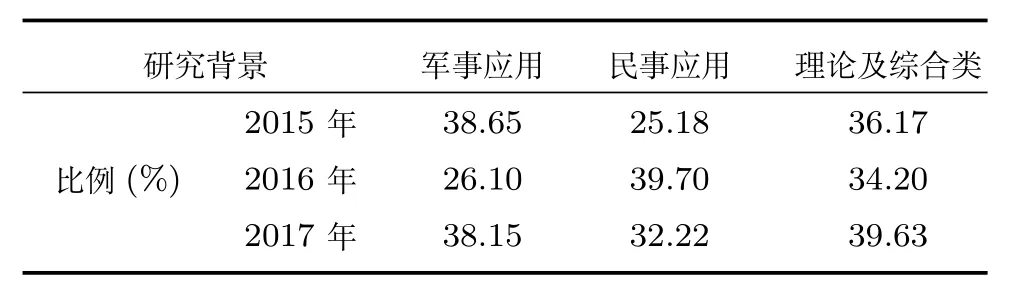
表1 研究背景统计比例表Table 1 Statistical proportion of research backgrounds
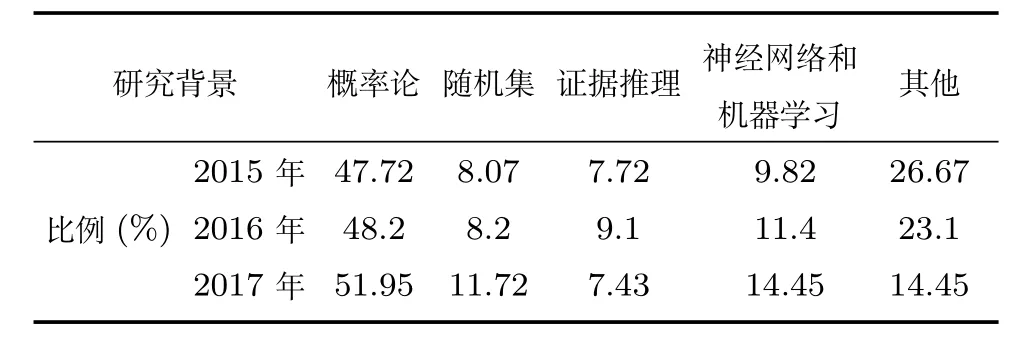
表2 数学工具统计比例表Table 2 Statistical proportion of mathematics tools
作者在文献[13]中对信息融合在军事和民用领域的应用分布情况、所采用的各种不同数学工具和研究方法所占的比例、融合系统建模方法、算法、发展动向以及存在的问题和解决思路等方面给出了系统性综述.在文献[13]的基础上,作者在文献[14]中首先提出了信息融合所面临的挑战和问题,而后针对这些挑战和问题进一步梳理和综述了在近几年间信息融合的进展,包括信息融合模型与系统设计、不确定信息融合、多模态信息融合、高冲突信息融合、相关信息融合及网络化信息融合;并给出了未来的研究方向,包括信息一体化融合处理、以人为中心的信息融合、信息获取与融合的联合优化、复杂多传感器信息融合系统体系结构设计、信息融合系统仿真与性能评估以及借助更多的数学理论方法等.本文主要对文献[14]中提到的信息融合一体化在目标跟踪领域的发展进行综述.
信息融合本身是一种形式框架,本质是多元变量的估计与决策.以信息融合技术为基础的目标跟踪系统越来越多地涉及到信号处理、统计估计与推理、机器学习、大数据等多领域,并且不断地遇到多种不确定问题,比如,非线性、多模式、深耦合、网络化、高维数和未知扰动输入等问题.
1)非线性:在实际目标跟踪系统中非线性问题是普遍存在的.不同坐标、传感器及平台间的转换导致系统中存在非线性;同时,实际动态系统自身衍化往往也是非线性的.由于非线性系统难以获得后验概率的全概率函数,并且具有多峰性和不对称性等不良特征,非线性估计问题只能通过近似解决.
2)多模式:在实际工程应用中,动态系统参数总是随着外部环境、系统组成等的改变而改变.在某些时候,利用单一模型对系统进行刻画很难满足实际需求,往往借助于多个标称或常用模型,以涵盖整个系统可能的衍化方向.多模式通常被建模为跟踪系统的多选择行为,包括跳变马尔科夫系统中多子模型切换,杂波环境或多目标跟踪情况下量测与目标的关联,多检测系统中量测与模式的关联,多传感器融合中航迹与航迹的关联.
3)深耦合:在存在未知参数的系统中,为了获得需要的目标状态,参数必须被准确辨识,而辨识问题在于解决多假设下与目标状态有关的系统模式、量测与航迹关联问题.鉴于辨识风险与估计误差是耦合的,必须联合考虑状态估计和参数辨识,以便在状态估计与参数辨识之间建立闭环反馈回路,解决估计与辨识间的耦合问题.
4)网络化:随着实际环境复杂多变,系统规模与日俱增,估计精度需求的日益提升,利用单平台、单传感器或集中式多传感器提供的量测信息对复杂系统状态估计已很难满足要求,往往需要利用多传感器构成大规模感知系统对动态系统状态进行网络化协同估计.多传感器的网络化可能存在网络阻塞、随机延迟、随机丢包、系统误差时空配准以及信道衰减和信道噪声问题.
5)高维数:在复杂环境中未知变量较多时,后验概率密度函数(Probability density function,PDF)的维数大大增加.如果未知变量具有离散形式,则边缘化过程包括对隐变量所有可能的排列求和,可能导致隐状态以指数形式增长.同时,伴随着感知系统的网络化和多模式发展,高维问题及其复杂性日益凸显.比如,由多平台、多传感器组成的上述网络化中心站在杂波环境中进行多目标跟踪任务.
6)未知参数:主要指未知的建模误差,通常存在于复杂外部环境下目标系统模型和量测系统模型中.例如,在目标跟踪系统中传感器偏差、欺骗干扰、杂波、未知分布的量测噪声和系统噪声等.特别是非合作目标强机动的情况,由于很难对其进行精确建模,导致跟踪系统得到间断的航迹,甚至无法正常起始航迹.
在信息融合领域中,针对上述问题的主要解决方法有:跳变马尔科夫系统(Markovian jump system)近似方法和交互式多模型(Interacting multiple model,IMM)处理机动目标跟踪问题[15];扩展卡尔曼滤波器(Extended Kalman filter,EKF)[16]、不敏卡尔曼滤波(Unscented Kalman filter,UKF)[17]和粒子滤波(Particle filter,PF)[18]等滤波器解决非线性滤波问题;鲁棒滤波器(Robustfilter)、期望最大化 (Expectation-maximization,EM)等方法解决未知参数问题;当多目标跟踪需要解决杂波等未知扰动时,主要有三类方法:1)数据关联算法[19−23];2)基于有限集统计(Finte sets statistics,FISST)的滤波器[24−27];3)对称量测方程(Symmetric measurement equation,SME)法[28−29].
1 目标跟踪理论及算法
在目标跟踪系统中,上述多种问题大部分情况下相伴相生,相互耦合.本节从目标跟踪应用出发,总结信息融合在多目标跟踪,非线性滤波,参数估计和网络化4个方面的主要理论和方法进展.
1.1 多目标跟踪
随着预警系统中各种高新技术的发展,目标跟踪问题发生了前所未有的深刻变化,特别是强非线性、非高斯、多模多路径、低检测概率、低数据率、低测量精度以及高容量等问题的出现给多目标跟踪技术带来严峻的挑战.近年来,多目标跟踪方法有了进一步的发展,根据采用的数学理论可分为三类,分别是基于数据关联、FISST和SME的方法.
基于数据关联方法的联合概率数据关联(Joint probabilistic data association,JPDA)和多假设跟踪(Multiple hypothesis tracker,MHT)是通过对量测的分配和数据关联技术将多目标问题转化为并行的单目标问题,以处理杂波环境下的目标跟踪问题[30−31].都是基于量测与目标关联的“硬关联”模型,在一个量测至多源于一个目标,一个目标至多产生一个量测的假设下枚举量测和目标之间可能的关联.其不同点在于MHT不仅考虑虚警的可能性,还考虑新目标出现的可能性,需遍历每个量测来源的可能性,因此计算量大,当目标较多时容易出现“组合爆炸”问题.与JPDA和MHT不同,概率多假设跟踪(Probabilistic MHT,PMHT)采用了量测与目标关联的“软关联”模型.假定量测之间相互独立,一个目标可产生多个量测,且量测与目标的关联相互独立(可将所有量测分配给任一目标).算法通过最大化量测分配模型的对数似然函数的条件期望获得目标状态的最大后验估计,其计算量是处理步长、量测个数和目标个数的线性函数[32].PMHT的实现主要包括两种形式:一种是采用基于最大似然估计的EM 方法[19−32],此类实现形式忽略每个目标只有一个量测条件的限制,其计算量的减少是以牺牲精度为代价的.Ruan等[33]基于Turbo编码的思想,提出了另外一种有效实现形式,即Turbo PMHT.Turbo PMHT具有良好的跟踪性能和较低的计算复杂度.此外,针对多机动问题,Ruan等[34]将多模式与PMHT算法结合来处理多机动目标跟踪问题,并与交互式多模型框架下的IMM-PDA和IMM-MHT进行对比,分析在跟踪精度和计算量方面的性能表现.
在随机有限集框架下学者们发展了多种新型滤波器,主要包括:概率假设密度(Probability hypothesis density,PHD)滤波器[25,35]、势概率多假设密度(Cardinality probability hypothesis density,CPHD)滤波器[25,36]、贝努利滤波器(Bernoulli filter)通常也称作联合目标检测与跟踪(Joint target detection and tracking filter,JoTT)滤波器[37]、多目标多贝努利(Multi-target multi-Bernoulli,MeMBer)滤波器[26]、势均衡多目标多贝努利(Cardinality-balanced MeMBer,CBMeMBer)滤波器[27]和标签多贝努利(Labeled multi-Bernoulli,LMB)滤波器[38].PHD和CPHD滤波框架是将目标状态和量测信息分别作为一个随机集,通过集合的积分微分等运算得到目标的状态信息及目标个数估计,实现对目标的联合检测与跟踪.PHD和CPHD规避了数据关联所带来的组合爆炸问题,其实现主要有基于序贯蒙特卡罗(Sequential Monte Carlo,SMC)框架和基于混和高斯(Gaussian mixture,GM)框架的两种形式.贝努利滤波器是一类能够随机切换on/o ff的最优贝叶斯滤波器,它能够同时估计目标存在概率和状态[37].目前的应用主要集中在目标跟踪领域,其中的on/o ff二元切换模块代表目标在监视区域的出现或消失.这种出现和消失的随机切换概念具有广泛意义,可适用于不同的动态现象,如传染病、污染和社会趋势等.PHD滤波器的状态估计值是孤立的点,无法形成完整的航迹.文献[39−40]对PHD滤波器进行了详细综述.
对称量测方程法是20世纪90年代Kamen在量测方程对称转换的基础上提出的一种多目标跟踪滤波器.它避免了所有多目标跟踪场景下所有目标/量测的可能关联问题.起初,Kamen仅考虑了一维空间内量测数目与目标真实数目相等的情况,并且构造的新量测也只有乘积和形式[28],随着研究的深入,学者们不仅将SME滤波器的适用范围推广到多维场景[29],以及存在虚警、漏警的情况[41],而且分别基于泰勒展开、Unscented变换(Unscented transform,UT)和SMC采样实现了多种形式的SME滤波器[42−44].SME方法虽实现简单,但由于对称变换方程的非内射容易造成“鬼点”坐标问题.文献[45−46]综述了对称量测方程方法.
1.2 非线性估计
在实际的目标跟踪系统中常常面临非线性甚至是强非线性的估计问题,其后验PDF的积分通常难以获得解析解.因此,将PDF积分难以解析的问题转化为非线性优化问题或者近似分布的优化问题成为必然.
常用非线性滤波器种类划分的一种方法是将其分为基于线性化的非线性滤波器和采样型非线性滤波器.EKF[16]和迭代扩展卡尔曼滤波器(Iterative EKF,IEKF)[47]作为线性化方法的代表,通过泰勒展式将非线性状态函数和量测函数进行线性化,从而能够直接采用卡尔曼滤波(Kalman filter,KF)框架,但是由于其只保留一阶项而忽略高阶项,在系统非线性特征较强时容易造成滤波发散.采样型非线性滤波器常见的采样机制分为随机性采样和确定性采样.粒子滤波器(Particle filter,PF)[18]是一种SMC方法,通过随机采样服从建议分布的大量粒子近似真实状态的PDF,可应用于非线性非高斯状态空间模型.Cappe、Schn、Dahlin 等利用马尔科夫链蒙特卡罗(Markov Chain Monte Carlo,MCMC)和SMC方法在非线性状态估计方面做了深入研究[48−52].由于SMC和MCMC方法固有的随机采样实现机制,需要足够的粒子以保证滤波精度,而导致计算开销较大.最近,Daum等借鉴物理学中的粒子流方法首次提出粒子流滤波器的概念[53],通过粒子流实现贝叶斯准则,而不是函数之间的逐点相乘的形式,避免重采样和建议分布函数选取过程中导致的粒子滤波器采样粒子“溃退”问题,并且在计算量和精度方面与粒子滤波相比均具有优势.随后,Bunch等发展了通过采用粒子流方法生成状态估计的后验样本点[54],并给出基于高斯流的确定采样型滤波器[55].确定性采样型滤波器主要包括UKF、容积卡尔曼滤波器(Cubature Kalman filter,CKF)和中心差分卡尔曼滤波器(Central difference Kalman filter,CDKF)[56−57].UKF 和 CDKF 分别通过UT变换和Sterling插值近似非线性状态转移矩阵和量测矩阵,然后结合采样点和PDF计算状态估计和估计误差方差.而CKF采用容积法则将获得的容积点作为PDF的采样样本,继而根据样本点的PDF估计系统状态.
另一种非线性滤波器划分依据为后验PDF近似的全局性和局部性[58].全局性指PDF的近似分布随着递归更新的进行而传递,即在估计过程中PDF的近似分布不变.全局性近似滤波主要包括点估计和SMC方法.局部性近似方法在每个滤波时刻均生成不同的PDF的近似分布,继而递归实现近似分布精度的提升.局部性近似滤波主要包括线性化方法和确定性采样方法,例如EKF、UKF、CDKF和CKF等滤波器及其衍生算法.
针对非线性系统量测噪声相关,噪声有色、量测丢失、时延、多速率、未知输入、扰动及多源量测等具体问题,文献[59−65]给出一系列相应问题的解决方法.另外,考虑离散时间马尔科夫跳系统,文献[66]给出一种杂波环境下状态估计和数据关联一体化机动目标跟踪框架.
1.3 多坐标系/平台/传感器网络化
多坐标系/平台/传感器的大规模网络化结构感知系统实现对动态系统状态协同估计与融合,并且具有可扩展性、快速可执行性和鲁棒性.然而,由于网络阻塞及附加路由等因素,导致网络化结构数据传输中存在随机时滞.针对网络传输阻塞,一部分学者认为存在量测丢包,在量测方程中引入伯努利随机参数对丢包事件进行建模.文献[67]假设每一时刻量测是否获得是已知的,当前时刻量测未获得时采取状态一步预测,在修正的Ricatti方程基础上,分析了相应估计器的稳定性.文献[68]将丢包推广到多步情况,并设计了相应的状态估计器.在H∞准则下,文献[69−70]分别探讨了量测丢包时序相关系统的控制和估计.与量测丢包不同,另一部分学者针对网络拥塞给出了随机延迟意义下的量测方程.针对多步量测随机延迟离散时间线性系统,文献[71]通过重构新息的方法,探讨了多步随机时延下的线性最小方差估计.另一方面,由于实际通信器件、环境及负载能力等的影响,使得数据在信道传输中可能会伴随信道衰减及信道噪声.文献[72]证明了相应的时变Kalman滤波的期望误差协方差阵是有界的,且收敛于稳态值.进一步,由于传统的针对多不确定耦合系统的估计算法仅仅适用于单传感器或通过量测扩维的多传感器处理,复杂环境下多传感器多不确定参数耦合系统的状态估计及融合问题受到越来越多的关注,例如,分布式框架下结合消息传递方法解决传感器网络中的定位和跟踪问题.
1.4 参数辨识
在许多实际状态系统中,例如目标跟踪系统,一般假设状态转移和量测模型是先验已知的.然而,实际情况是模型参数或模型结构本身是未知或者部分未知的.在此类场景下,假设模型参数信息完全已知的标准估计算法,如KF和EKF等,往往不能精确估计系统状态.解决此类问题的经典方法是基于贝叶斯估计理论的自适应滤波器,其实现未知扰动辨识的同时进行目标状态估计,主要包括状态扩维、鲁棒滤波、多模型(Multiple model,MM)滤波、MCMC和EM方法.
状态扩维方法是将未知参数看作状态变量的附加变量并将其扩充至状态向量中,文献[73]对此类方法作了综述.鲁棒滤波的目的是最小化未知扰动到估计误差的转移矩阵增益,从而获得鲁棒的参数化最小方差滤波器以达到最优无偏最小方差滤波器和鲁棒卡尔曼滤波器之间的折衷.然而由于在理论推导过程中参数往往被假设为具有约束的常数[74],鲁棒滤波器比较保守,对时变未知扰动的估计精度不高,甚至无法辨识.在MM 方法[15,75]中,未知扰动输入被建模为服从Markov Chain的随机切换的参数,相关的状态和未知扰动的估计问题转化为模型辨识和基于此模型的滤波的联合实现,其常见实现形式包括IMM和变结构多模型(Variablestructure MM,VSMM).文献[15]给出此类方法的综述,并分析其在机动目标跟踪系统中的优越性.但是当未知输入的个数增多时,IMM的计算量快速增加,并且MM方法对模型不确定的处理能力局限于可得到的“模型字典”,即预设模型类型与个数.在采用随机采样方法进行参数辨识方面,文献[49−51]利用MCMC和SMC采样解决非线性状态空间参数估计问题.文献[52]综述了SMC方法和具体的实现策略(例如Metropolis Hastings采样、最大似然(Maximum likelihood,ML)准则和Gibbs采样等)在系统辨识中的应用.
近年来在解决系统辨识与状态联合估计问题方面,纳入统一框架的反馈迭代联合优化方法成为主流.常用的统一框架主要包括EM 和变分贝叶斯(Variational Bayes,VB).EM通过建立反馈环实现状态估计与参数的联合优化,是变分的一种特殊实现形式[76].其迭代过程分为期望步(E-step)和最大化步(M-step).首先E-step根据给定的参数值,对似然函数求条件期望,实现缺失数据的估计;然后在M-step步最大化条件期望,获得未知参数的辨识值.E-step和M-step步不断交替迭代直至收敛,最终得到迭代优化的估计及辨识值.目标状态与隐变量在迭代循环中分别被估计与辨识.但如果隐变量的维数太高,E-Step和M-Step的实现仍然是一个问题[77−78].而结合平均场(Mean field)理论的VB方法可以克服这个缺点.相比EM算法,VB能够在复杂图模型下推理,在某些情况下性能有很大改善,尤其适合处理高维大尺度问题.
值得一提的是,现有的估计器绝大部分都属于模型驱动型.所谓模型驱动型,即以建立运动方程模型和量测方程模型为前提,依据贝叶斯准则实现状态的预测和更新.但是,对于非合作目标的状态估计和跟踪问题,容易出现建模不准的问题.例如,在目标跟踪中,非合作目标往往进行强机动运动,导致跟踪系统得到断续的航迹,甚至无法正常起始航迹.随着机器学习、深度学习的快速发展和计算能力的提升,数据驱动型方法备受关注.其基本思想是采用机器学习或深度学习的方法从大量原始量测中学习并生成估计器或者跟踪器,以实现非合作目标的状态预测和跟踪.Thormann等[79]首次尝试采用随机森林回归的方法学习从状态到量测之间的映射关系,以实现径向距–角度量测下的目标跟踪问题.其文中通过概率模型仿真产生大量的目标状态和量测,分析在不同数量的训练数据,每个森林具有不同数目的树情况下的算法性能,并且分别在低/高量测噪声水平下分别与卡尔曼平滑器和粒子滤波器进行对比.在应用方面,文献[80]采用高斯过程和支持向量机(Support vector machine,SVM)的方法学习目标运动模型预测弹道系数,结合动态方程进行一系列的预测迭代实现高速弹道目标在量测时刻瞬间的状态预测.文献[81]基于历史自动识别系统数据生成相应的路线模式,实现舰船轨迹的预测.
复杂环境下非线性、多模式、深耦合、网络化、高维数和未知扰动输入等问题可能多种组合相伴相生,相互耦合.例如,在天波超视距雷达等探测装备对舰船目标探测过程中,通过电离层传播的目标散射信号受电离层随机调制的影响而存在多路径等复杂特性,导致量测方程中存在非线性,多模不确定等,并且受海况影响舰船目标信号极容易被海杂波等扰动输入淹没.因此,有必要采用联合优化的方法实现复杂系统的解耦、降维、参数辨识、状态估计与融合等一体化处理.
2 目标跟踪联合优化问题
对于一般的跟踪问题,建立目标运动方程和量测方程
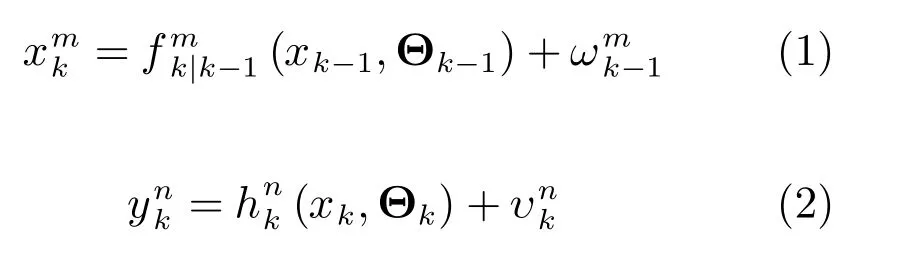

贝叶斯推理下的目标跟踪问题就是寻找后验分布p(xk|yk).当Θk已知时,目标跟踪问题转化为计算条件概率密度函数p(xk|yk,Θk);当Θk未知时,即目标存在性Sk,关联假设参数αk,βk,γk和δk及扰动输入ak和bk是不可直接观测的变量时,后验PDF可以表示为混合高维积分,式(3)给出了相应表达式.
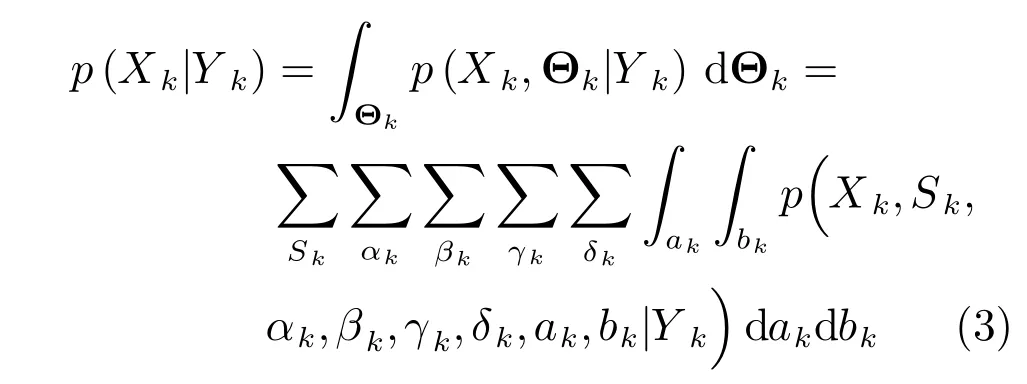
联合优化处理方式的目标跟踪就是解决一个连续/离散混合系统(1)和(2)的估计和辨识问题,包括连续变量的状态(Xk)估计和未知扰动输入(ak,bk)估计和隐变量参数空间k下多离散变量(Sk,αk,βk,γk和δk)辨识的总和.在连续变量情况下,所需积分可能没有封闭解析解,同时由于被积函数的复杂性,可能难以进行数值积分.在离散变量情况下,边缘化包括对隐变量所有可能的排列求和,可能导致隐状态以指数形式增长,以至难以在实际中准确计算.
在多种不利现实因素共存且相互耦合的情况下,如果仍采用上述单一方法只能解决某一特定问题.例如在传统的目标跟踪序贯处理方式中(如图1所示),首先由各类传感器检测目标信号,经过点迹聚类后将源于同一目标的量测依概率关联,从而在滤波器中实现目标状态估计的更新,最后根据估计结果将目标按不同属性分类.这种序贯“分而治之”的串行处理方式容易造成误差的累积传播;同时,开环的处理结构无法利用闭环反馈自动地进行系统调整,鲁棒性能差.在传感器有较好的模型描述、数据有较精确的统计特性、融合系统有较稳定的拓扑结构以及较明确的任务需求等条件下,其估计与融合问题一般可以得到较满意解决.但是在上述复杂应用背景多种不确定因素条件下如何实现高维计算、闭环反馈、智能优化、网络化、鲁棒性等联合处理一体化架构的多源信息处理与融合,已成为国内外学者研究的焦点和难点.

图1 序贯处理方式示意图Fig.1 The diagram of the sequential processing
针对信息融合中联合优化问题,Peter Willett、李晓榕等著名学者分别提出一系列的解决方法,主要包括联合检测与估计(Tracking-before-detect,TBD)[82]、联合聚类与估计(Joint clustering and estimation,JCE)[83]、联合关联与估计(Joint association and estimation,JAE)[84]和联合决策与估计(Joint decision and estimation,JDE)[85]等.
TBD:利用目标的运动特性,经过多帧积累目标的能量、幅值或后验概率等信息,以达到抑制噪声,联合优化检测与状态估计的目的.针对弱小目标检测与跟踪的过程中存在大量与目标相似的噪声、杂波等干扰并造成目标信号信噪比低的现象,这种联合处理结果一般可以提高3dB的信噪比.图2给出TBD框架示意图.
JCE:将点迹聚类、数据关联与状态估计进行统一处理.利用估计的目标状态和多传感器量测进行点迹聚类,聚类量测–航迹数据关联,最后进行状态更新,从而实现对未知目标数目的多目标状态估计与跟踪.图3给出JCE框架示意图.
JAE:将数据关联与状态估计进行联合处理,在一系列不确定观测值基础上进行数据关联–状态估计间的闭环反馈,即数据关联的输出用于状态估计,而估计结果反馈调节数据关联中新息的大小,从而实现估计精度的提升.图4给出JAE框架示意图.
JDE:基于贝叶斯风险的联合决策与估计方法,将估计风险与辨识风险进行统一考虑,以解决数据的离散不确定性或连续不确定性,避免了“先估计后决策”方法中决策依赖估计和“先决策后估计”方法中估计次优的缺点.图5给出JDE框架示意图.

图2 TBD框架示意图Fig.2 The diagram of TBD

图3 JCE框架示意图Fig.3 The diagram of JCE

图4 JAE框架示意图Fig.4 The diagram of JAE

图5 JDE框架示意图Fig.5 The diagram of JDE
文献[32]认为目标跟踪是联合估计与辨识问题.由于未知扰动输入、多模式、非线性以及高维数等情况的出现,导致原有的“先辨识/决策后估计”或“先估计再辨识/决策”的策略难以实现参数的正确辨识,目标状态的准确估计和点/航迹的准确关联.上述联合优化方法分别在不同属性级间建立反馈环,实现了状态估计与目标跟踪其他不同阶段的联合优化.这种信息联合处理与融合方式的主要优势[32]:1)建立估计与辨识的联合优化处理框架,适合处理多种问题耦合更为复杂的情况;2)采用闭环迭代的处理结构,充分挖掘原始信息,有效处理耦合问题;3)在统一的算法框架进行联合求解,实现全局优化.然而,由于上述非线性、多模式、网络化、高维数和未知扰动输入等问题的存在,在最优贝叶斯估计意义下后验PDF的积分难以获得解析解,需要探索近似贝叶斯推理方法.EM 和VB的迭代处理框架恰好与目标跟踪中的估计与辨识问题相契合,便于在状态估计与参数辨识之间建立闭环反馈回路,以解决估计与辨识间的耦合问题.EM算法对于高维复杂分布下的隐变量估计问题,E-Step在很多情况下都无法得到对隐变量统计信息的解析解[86−87].针对此问题,通过对耦合高维隐变量进行一定的弱可分解近似推导得出的变分贝叶斯期望最大化(Variational Bayesian EM,VBEM)[78]算法能够近似获得E-Step隐变量统计信息的解析解,进一步推广了EM算法在多目标跟踪中的应用.
3 变分贝叶斯方法
变分贝叶斯是一种采用简单分布近似隐变量的真实后验分布的推断方法,通常假设隐变量之间相互独立[88].变分学习主要有两个目的:一是逼近边缘似然函数p(Y|X)以实现模型的选择,二是逼近包含所有参数的后验概率分布p(X|Y)以实现隐变量的预测.假设隐变量的全贝叶斯模型中所有参数的先验分布已知,变分的目的是寻找后验PDF的一个变分分布使其与真实后验PDF之间的KL散度(Kullback-Leibler divergence,KLD)最小.变分贝叶斯原理如下:
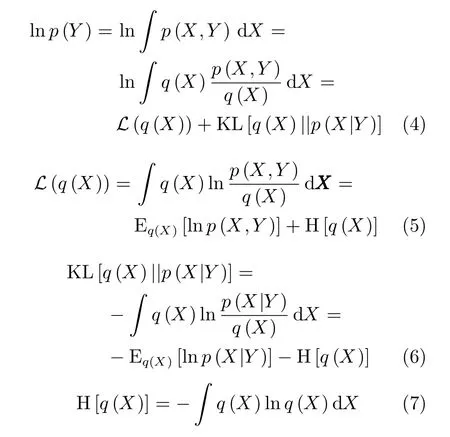
其中,L(q)表示变分置信下界,KL(q||p)表示两个概率分布q(X)和p(X|Y)差异的非对称度量,即KL散度.通过变分分布q(X)最大化置信下界L(q)(等价于最小化KL散度)以获得后验PDF的近似.即对任意的变分分布q(X),当KL散度为0时,下界L(q)取得最大值,此时的变分分布q(X)等于真实后验分布p(X|Y).Eq(X)[lnp(X,Y)]表示隐变量和量测的联合PDF的对数期望,H[q(X)]为变分分布的熵.
变分方法成为目前确定性近似推理的主流方法归功于变分方法本身具有统一而有效的问题求解框架,同时也与概率图模型和指数分布簇有着密切的联系[89]:概率图模型为变分推理提供了很好的结构框架,能够直观地表示变分近似对于系统结构引起的变化[90−91];指数分布簇包含了一大类常用的概率分布[76].许多实用的图模型都可以看作是指数分布簇的具体实现,当模型中随机变量的概率分布位于指数分布簇中时,在贝叶斯框架下往往可以根据共轭特性得到闭环的解析解,因而便于算法设计和程序实现.
3.1 变分的分类
Jordan等[90]认为,由于指数分布簇在统计理论中所暗含的凸性为设计多种变分优化近似方法提供了理论依据,同时许多现有的变分近似在图模型框架下得到了较好的基于图的迭代解法,因而目前构建变分方法论最为有效的办法是建立变分分析和指数分布簇之间的联系.经过几十年的发展,目前变分理论主要包括如下以下几个方面.
平均场理论变分推理.如果各隐变量之间存在相互依赖的关系,可采用平均场理论将隐变量的近似后验分布分解为多个互不相交因子的概率分布之积,具体解耦合的方式往往根据实际系统的图模型结构进行.许多变分算法在近似过程中都对原系统的结构进行了一定的近似调整[86],即在原有图模型的子图模型下进行优化,因而也被称为结构化变分近似.从直观上来讲,近似准则在保证系统可解的情况下尽可能地解除随机变量之间的耦合关系,从而保证变分近似的精度.现有的基于平均场理论的变分方法多被用于贝叶斯推理问题中,因而被称之为变分贝叶斯推理,然而就变分方法本身而言,其应用并不只局限于贝叶斯推理.
参数化变分近似.Bishop在文献[76]对变分近似的讨论中曾提到过参数化分布变分推理方法,即假设隐变量的真实后验分布在可用参数概率分布模型描述的可解子空间当中,因而优化的目标即是从该参数化分布模型中寻找最接近真实后验概率分布的变分分布,使得真实后验分布和近似分布的熵最小.常采用共轭指数簇模型将隐变量的后验PDF建模为其共轭先验分布,通过优化求取共轭先验分布的超参数获得后验PDF的近似.
随机变分贝叶斯方法.对于超大规模数据集的推理问题,Hoffman等[91]提出的随机变分推理算法基于随机优化方法进行推理,打破了传统变分推理对于模型的约束,允许使用更复杂的贝叶斯模型对海量数据进行快速学习[92],是目前变分推理发展的一个很有前景的分支.另外,通过引入辅助变量构建了蒙特卡罗法和变分推理结合的桥梁,从而综合二者的优势,在降低计算量的同时保证计算精度[93],并且对于非共轭模型和非参数模型具有较好的适应性.
Bethe近似变分推理.置信传播(Belief propagation,BP)算法是一个解决基于Bethe近似的变分问题的拉格朗日方法.BP算法最早由Pearl[94−95]在1988年正式提出,通过在图模型上进行消息传播求解概率计算问题,随后被广泛应用到通信领域的解码问题中[96−97].后续研究表明,包括卡尔曼滤波和平滑算法、隐马尔科夫前后向算法、贝叶斯网络概率传播算法以及一系列编码纠错算法都可以看作是BP算法的具体实例化[98].关于BP算法与VB之间的相关性研究要归功于Yedidia等[99−100]对于BP算法和Bethe近似之间内在联系的详细论述,才使得BP算法得以进一步推广[101].
3.2 VB在参数辨识中的应用
基于VB的现代信息融合方法通过建立状态估计与高维未知参数的联合优化框架,构建闭环迭代处理回路,充分挖掘原始信息,可以有效处理耦合问题,适合处理高维未知参数下的联合估计问题.由于VB能够结合指数簇、BP算法、图模型和平均场等[76,88,102]理论,使其在估计与辨识方面得到了广泛关注.
针对共轭模型参数辨识问题,常用逆伽马分布和逆威沙特分布等指数簇分布作为被估计量的共轭先验分布.Srkk等[103]在共轭条件下采用指数簇的共轭先验分布近似未知量测噪声的后验PDF,结合贝叶斯滤波理论实现时变噪声方差和目标状态的联合估计,达到与交互式多模型算法相接近的估计精度,并且由于VB对高维问题的处理能力,使其在解决多未知扰动问题方面更具有优势.随后,文献[104]给出非线性条件下采用逆威沙特分布的先验信息近似多变量噪声后验PDF,并给出其一般实现形式.变分贝叶斯方法在未知量测/系统噪声的估计方面得到了进一步的发展[105−106],并应用于多目标跟踪环境[107].文献[108−109]假设量测噪声和系统噪声均未知,文献[108]采用批处理的方式对未知噪声矩阵进行估计,而文献[109]给出两种噪声均未知的条件下噪声方差的在线估计,并且为了避免系统噪声和系统状态相互独立假设的不合理性,采用独立于当前状态的前一时刻的状态预测方差代替系统噪声,以便在平均场理论的基础上分别求其变分边缘PDF,获取期望的解析解.
针对非共轭模型的参数辨识问题,Wang等[110]在机器学习领域提出拉普拉斯变分推断(Laplace variational inference)和Delta方法变分推断(Delta method variational inference).两者皆采用坐标上升方法优化变分参数,并且在变分参数和变量间交替迭代直至满足优化条件.不同点在于拉普拉斯变分推断采用拉普拉斯近似方法近似后验PDF,而在Delta方法变分推断中采样泰勒展式近似.并且文中指出,拉普拉斯变分推断一般在实时性和精确性方面均优于Delta方法变分推断.状态估计领域中,文献[111−112]采用学生t-分布近似噪声分布以求其对数边缘分布.文献[113]采用莱斯分布近似非共轭指数簇变换点检测模型,并将其应用于雷达目标跟踪系统.
3.3 VB与EM的关系
通过变分分布的构建,VB算法保证参数和隐变量联合分布的目标函数L(q(X,Θ))(即下界)是单调递增的如图6所示.EM 的下界也是单调递增的,如图7所示.但是在迭代中逼近最大似然函数的过程是不同的.在有限制的情况下,EM算法的似然函数是动态变化的.迭代初始与当前似然函数相差一个KL散度.在E-Step,下界逼近最大似然值,KL散度减小;然后在M-Step中,根据更新的参数重新确定新的似然值.如此往复,直到收敛.而在VB算法中,最大似然函数是不变的.作者认为其中主要原因是在VB算法中已知先验分布的未知参数被吸收为随机隐变量处理其概率模型为全贝叶斯模型p(X|Y)[76],并且所有隐变量的联合PDF的期望是一个常数,如式(4).而在EM算法中,未知参数是显性的,其似然函数是p(X|Y,Θ).此外,当未知参数满足点(离散量)估计的约束条件时,在最大似然准则估计下VB退化为EM.然而,在最大后验估计准则下由于参数和状态固有的条件相关关系,则不然.
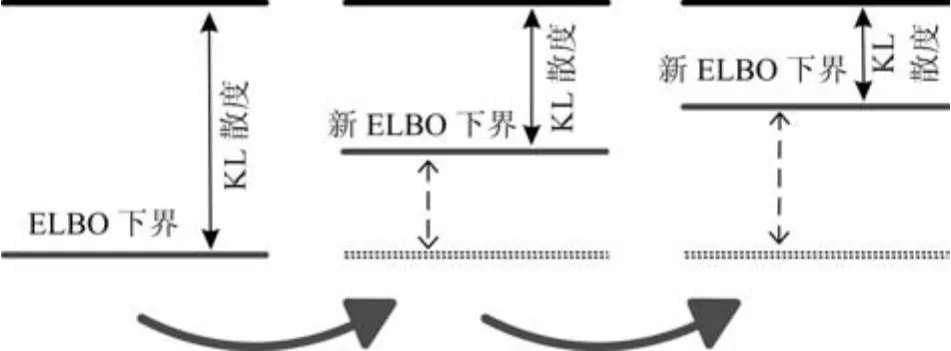
图6 VB原理示意图[88]Fig.6 The diagram of VB principle[88]
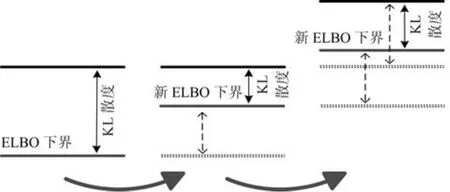
图7 EM原理示意图[88]Fig.7 The diagram of EM principle[88]
由于整体考虑未知参数和隐变量必然导致VB的计算量增加,但是在最大似然准则下VB的后验更新步骤与EM的E-Step具有相同的计算量[88].因此,EM较VB更为简单,适合处理低维隐变量下的估计问题;VB较EM算法更为鲁棒,适合处理高维隐变量问题.
4 基于变分贝叶斯理论的目标跟踪联合优化方法
根据上文分析知,EM和VB均是基于后验分布的确定性解析近似方法,将状态和参数迭代优化以获得似然函数的最大上界,并解决辨识风险与估计误差耦合的问题.然而,当联合概率密度维数较高(即较多参数Sk,αk,βk,γk和δk及扰动输入ak和bk)时,VB算法则表现出高于EM 算法的优越性.因此,研究基于VB的目标跟踪联合优化方法能很好地解决上述复杂环境中的状态估计和多参数共存且耦合的问题.特别指出:第3.3节已说明在VB中未知参数被吸收为隐变量处理,其概率模型为全贝叶斯模型p(X|Y).但是为了方便读者阅读,文中隐变量和未知参数分别采用X和Θ表示.
4.1 联合优化方法一般性描述
根据式(1)和式(2)的系统模型和量测模型,下面给出基于VB的联合优化方法.变分贝叶斯算法的核心思想是使用变分分布q(X1:K,Θ1:K)近似状态的真实后验分布p(X1:K,Θ1:K|Y1:K),即
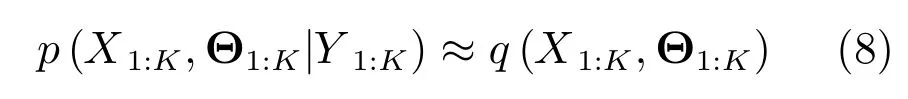
其中,根据平均场理论,q(X1:K,Θ1:K)可近似解耦分解如下:
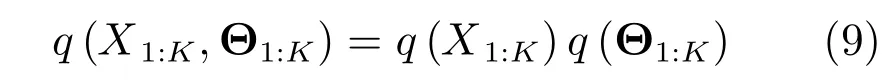
在变分贝叶斯框架下,相应变量的边缘PDF表示为
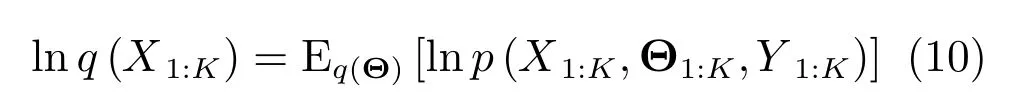
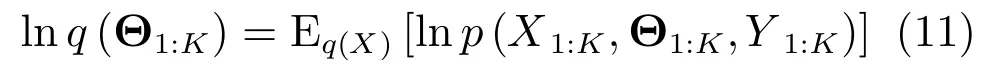
由于上述公式是相互耦合的,因此基于VB的后验更新概率需要进行迭代求解.并且,对于一般的跟踪问题,参数Θk不是完整已知的,比如,机动目标跟踪中模型的不确定性,杂波环境多目标跟踪的数据关联等.因此,解决典型的联合跟踪问题在于根据量测估计目标状态的同时还必须辨识参数.另外,在VB算法框架下,可根据问题实际情况设计参数数目.多未知参数与目标状态联合优化的应用将在第4.2节给出.
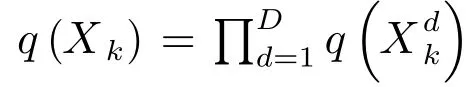
注2.q(X1:K)和q(Θ1:K)的形式.在某些情况下,状态和参数的联合后验PDF因子分解后依然无法得到解析解,还需要更进一步的后验分布近似.例如,假设参数的后验分布是高斯分布q(Θ1:K|ζΘ),而超参数ζΘ=(ηΘ,ϕΘ)是未知的.因此,我们需要对参数构造简单的超参数空间,常采用的分布是高斯分布和狄利克雷分布.鉴于篇幅有限本文不做讨论,请参照文献[76,88,114].
4.2 联合优化方法在多路径多模式多目标跟踪中的应用
以多目标概率数据关联为应用背景的变分贝叶斯方法综合平均场理论和BP算法在多目标跟踪中的优势,在统一框架下解决多目标跟踪中面临的航迹管理、数据关联和状态估计问题.Lzaro等[115]采用高斯过程建模目标运动轨迹,并利用变分贝叶斯算法进行数据关联和超参数学习,很好地解决了多目标跟踪中的目标间航迹交叉时出现的混批问题.Turner等[116]提出了一个完全变分跟踪器,考虑了数据关联中目标与量测之间的约束关系,在变分框架下对目标状态估计,数据关联概率计算和航迹管理三方面进行联合优化,并仿真验证了该算法在雷达目标跟踪和视频跟踪中的有效性.文献[117]基于BP算法变分求解边缘关联概率,从理论方面进行了收敛性和时间复杂度分析,证明了BP算法求解关联概率在计算时间和精度方面具有较好的折中效果.另一方面的应用主要集中在分布式多传感器多目标跟踪状态估计与融合[118],这类方法结合图模型的消息传播机制为建模分布式传感器节点之间的依赖和交互关系提供了有效框架的同时,也为BP算法及其扩展方法的推理提供了便捷,对于实际系统中目标、量测和传感器数目的扩展具有良好的适应性,从而进一步推广了变分近似推理方法在目标跟踪中的应用.
本节以天波超视距雷达(Over-the-horizonradar,OTHR)的多路径多模式多目标跟踪问题为例给出联合优化的解决方法.OTHR依靠电离层反射传播对目标进行探测,其探测的责任区面临复杂的地海杂波及多种目标,同时电离层的多层特性使得OTHR信号通过多条路径传播.此外,OTHR还具有低量测精度、低检测概率、低数据率、高虚警等复杂探测特性.这使得OTHR复杂环境下目标跟踪面临如下挑战[119]:1)高维数问题,需要近似估计方法.首先,多目标产生高维状态空间.在OTHR大范围监视区域内,可能会出现大量目标.其次,多量测回波产生高维量测空间.OTHR下视工作方式使其探测的回波中除了感兴趣的目标,还包括大量地/海杂波.再次,多路径传播产生高维参数空间;2)耦合问题,需要联合优化方法.OTHR目标跟踪同时包含估计及辨识.其中,估计问题包括目标状态估计,辨识问题包括数据关联、模式关联.这两个问题相互耦合相互影响,即估计误差会引来辨识风险,而辨识风险又会带来估计误差.
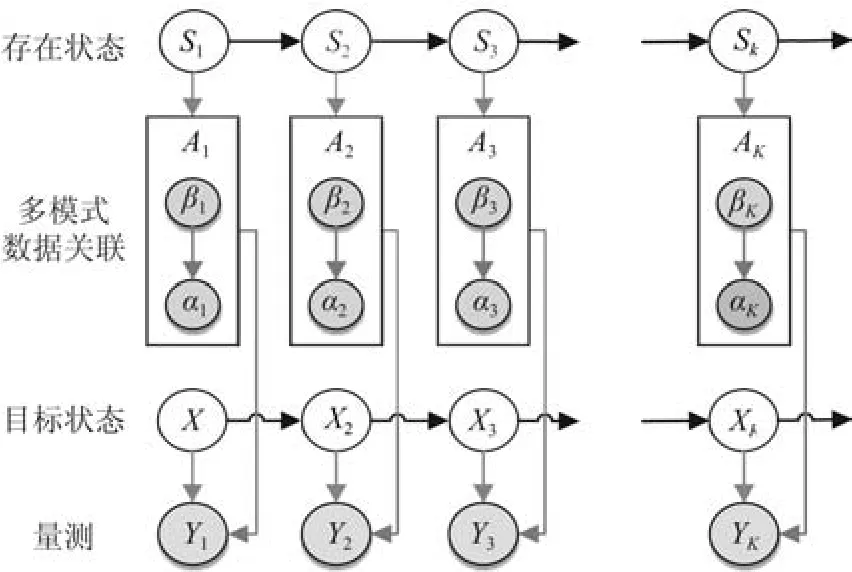
图8 OTHR联合检测与跟踪概率图模型[120]Fig.8 The probability graph model of joint detection and tracking of OTHR[120]
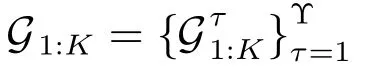
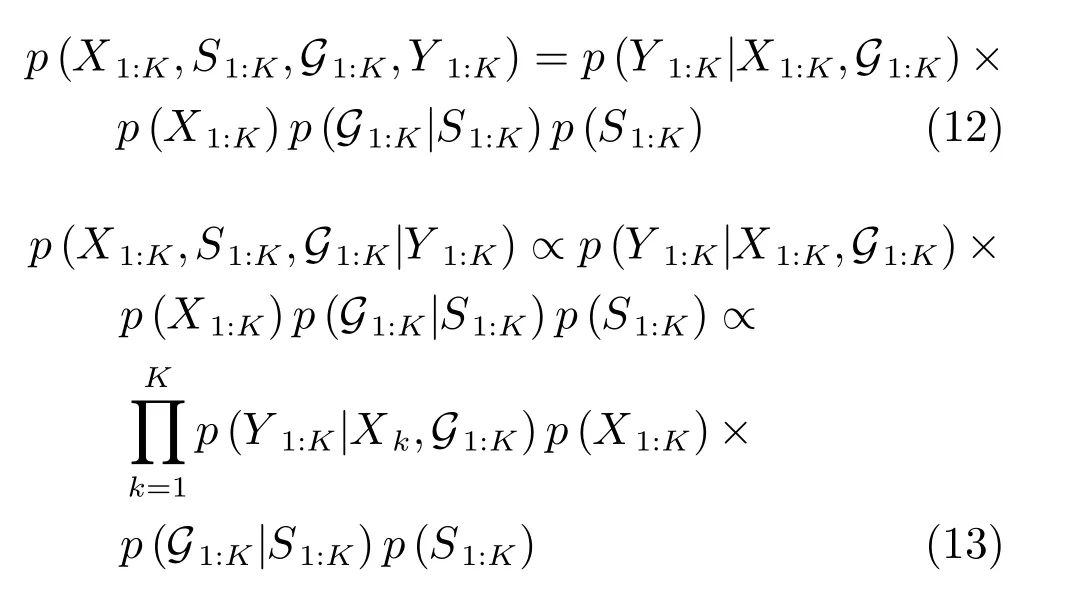
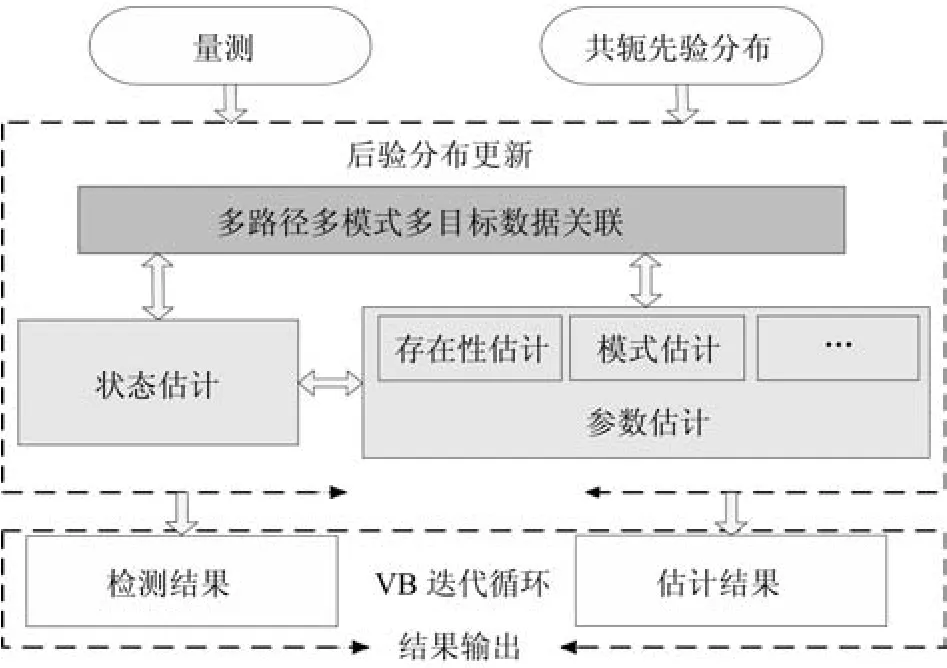
图9 多路径多模式多目标跟踪的联合优化框架[120]Fig.9 The joint optimization framework of multi-path multi-mode multi-targat[120]
采用VB框架的联合跟踪方案示意图见图9.利用隐变量的先验PDF、目标存在性、目标运动状态、多模式数据关联的后验PDF通过卡尔曼平滑器和LBP(Loopy belief propagation)更新,其实现步骤如下:
1)构建先验信息模型.构建具体的参数先验是VB的关键环节.方便且具有解析解的一类常用先验是指数分布簇中的共轭先验分布.即当参数的先验分布p(Θ1:K)与完整数据的似然函数p(Y1:K|X1:K)是共轭关系时,似然函数与先验分布具有相同的指数分布簇形式.
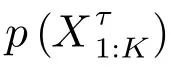
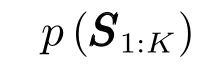
4)多模式数据关联后验PDF更新.假设给出第i次迭代的目标存在状态概率分布p(S1:K),目标运动状态PDFp(X1:K)和量测似然函数p(Y1:K|X1:K),通过LBP算法近似计算多模式数据关联.继而通过计算边缘分布辨识数据关联和传播模式,更进一步,计算每个模式的后验分布及其相关的等效量测.
5)迭代.重复上述2)∼4)模块直到两次迭代间的估计性能足够接近或者达到设定的最大迭代次数.
4.2.1 先验分布模型
1)目标存在状态模型:假设二元存在状态Sk∈{0,1}M服从离散马尔科夫过程,则
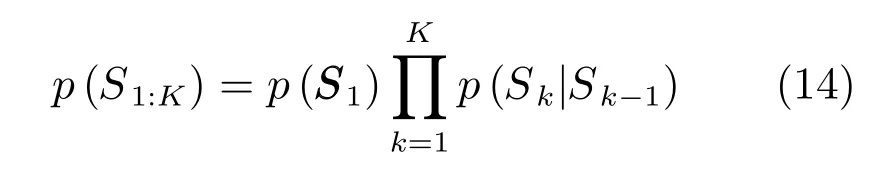
2)目标运动状态预测模型:目标运动状态服从一阶马尔科夫过程,则
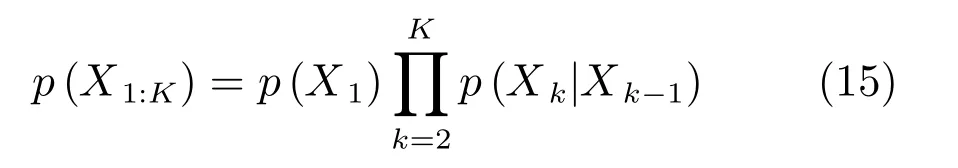
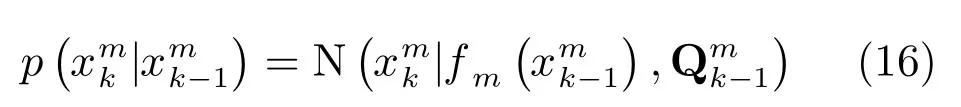
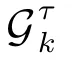
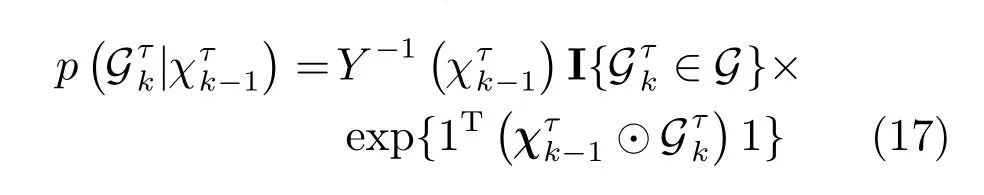
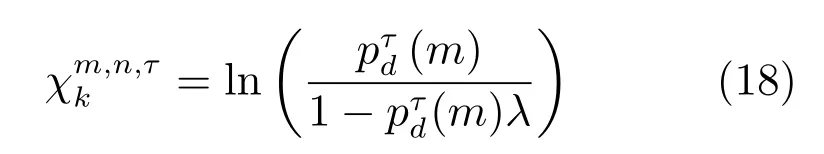
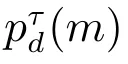
4)量测模型:根据各量测条件独立的特性,量测似然函数p(Y1:K|X1:K,G1:K)可被分解为:
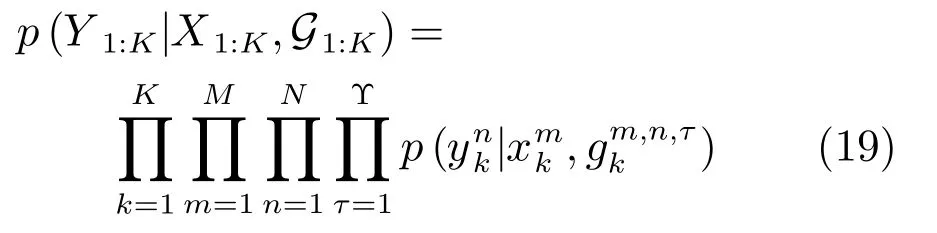
根据数据关联结果,目标m在k时刻τ模式下的量测模型可进一步表示为:
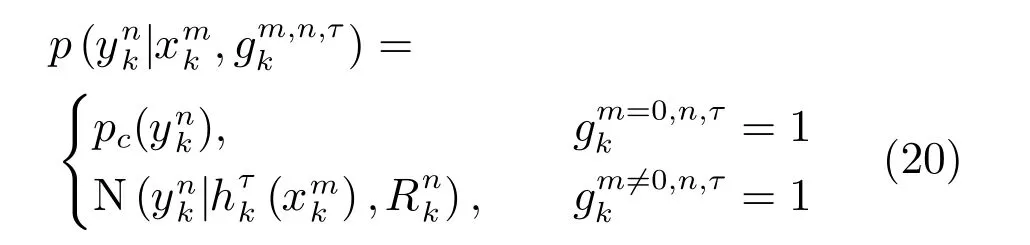
4.2.2 后验概率更新
采用变分分布q(X1:K,S1:K,G1:K)近似隐变量和参数的PDFp(X1:K,S1:K,G1:K|Y1:K).
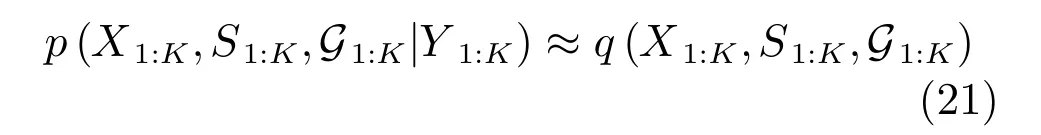
其中,根据图8中所建图模型和平均场理论,q(X1:K,S1:K,G1:K)可分解如下:
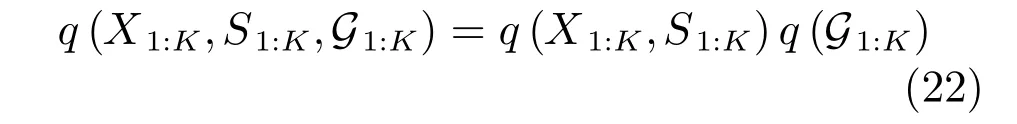
根据目标运动状态X1:K,目标存在状态S1:K和多模式数据关联G1:K之间的逻辑关系,G1:K被看作“参数”,而{X1:K,S1:K}为“隐变量”,其置信下界为:
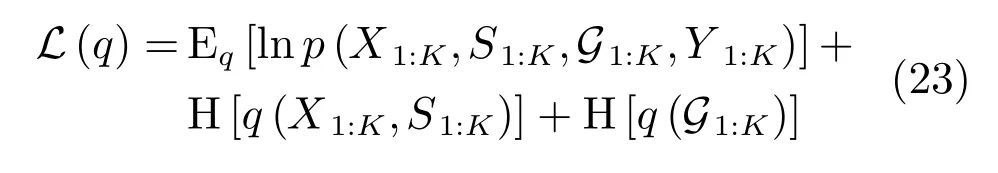
目标运动状态的近似后验PDFq(X1:K),目标存在状态的近似后验PDFq(S1:K)和多模式数据关联的后验PDFq(G1:K)的自然对数公式为:
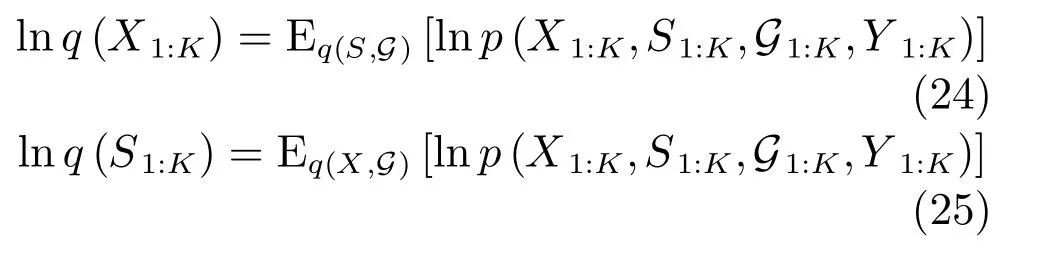
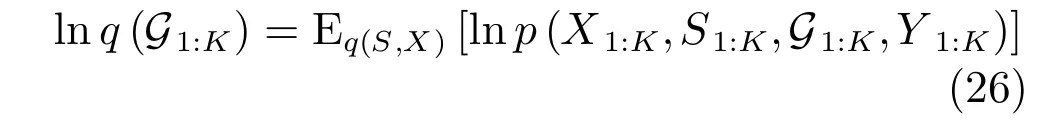
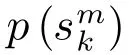
5 总结与探讨
本文中,首先回顾近年信息融合理论在研究背景和数学工具应用方面的统计数据.然后通过分析复杂目标跟踪系统中存在的非线性、多模式、深耦合、网络化、高维数和未知扰动输入等问题,指出现阶段目标跟踪系统中多参数和状态联合估计与优化的必要性.继而,讨论了解决联合优化问题的主要方法,包括联合检测与估计,联合聚类与估计,联合关联与估计和联合决策与估计等.同时,着重介绍了变分贝叶斯辨识、估计和优化的统一框架和以其为基础的目标跟踪联合一体优化方法,并以天波超视距雷达为应用背景,给出在多路径多模式多目标跟踪场景下算法的一般性描述.
由于基于变分理论的一体化方法在解决复杂系统的概率推理问题和耦合参数的估计问题通常具有可接受的近似精度和较低的计算量.由不同的近似策略以及局部极小值等特性导致的精度降低问题和变分方法在非参数、非共轭、网络化、大数据和一体化等新型复杂问题的应用是目前基于变分理论的联合优化方法发展的主要趋势.
估计精度和实时性矛盾问题.由于VB可借助图模型和平均场理论进行问题的近似解耦分解与简化,使其在处理高维问题中具有较好的实时性优势.而MCMC作为近似后验PDF的另一种方法,在大量样本的保证下具有更高的精度但是计算量较大,尤其在处理高维数据的过程中这一缺陷更加明显.在机器学习领域中,有学者尝试利用VB方法解决MCMC样本的聚合函数问题[93],以同时提升精度和实时性.因此,考虑VB理论与MCMC方法有机结合,有望解决状态和参数一体化估计过程中高精度和实时性矛盾的问题.同时,基于随机优化的随机变分和不依赖系统模型的“黑盒”变分[121]将有助于实现和提高未知模型系统的状态估计.
传感器网络化和智能化下的变分理论.在网络化的多传感器系统中往往需要交换局部信息已达到比单一传感器更精确的估计,分布式结构有助于减小传感器网络中的计算代价.变分贝叶斯方法结合图模型的消息传播[118]机制,为传感器网络节点之间的依赖和交互关系提供有效框架的同时,也为BP算法及其扩展方法的推理提供了便捷,对于网络中传感器个数的增减具有良好的适应性.同时,在智能化的认知雷达[122]应用方面,由于发射波形的优化设计和对外界认知的参数是体现认知雷达智能化的重要组成部分,如何将认知雷达的自适应波形优化和参数优化与目标跟踪过程中的中间变量和待求变量之间通过图模型建立联系,并采用平均场理论和VB方法对认知雷参数和波形优化,以提高认知雷达对环境的感知能力和智能化,将具有较高的理论和工程研究价值.
概率建模和数据驱动相结合的联合优化框架.基于数据驱动的机器学习方法(比如判别式学习和递归神经网络等)在图像和视频跟踪领域得到了广泛的应用.而现有目标跟踪均是基于概率建模机制.文献[79]采用随机森林方法在仿真场景中实现了目标轨迹的学习,但是当系统参数(例如系统噪声)改变时需重新训练跟踪器,这将大大增加跟踪过程中的计算量,并且只能获得目标状态的点估计,难以获取状态的后验PDF.因此,如何将概率建模和数据驱动有机结合,实现先验信息较少或未知的条件下目标的检测、聚类、关联、状态估计、参数辨识、跟踪与融合、分类与识别等一体化框架,将是信息融合研究领域的挑战.
另外,变分算法的迭代处理精度依赖于其初始化的精度,在实际应用中,初始化精度过低往往会导致算法发散,因而如何寻找稳定的初始化方法或评估初始化精度对算法的影响目前也是一个未解决的问题.
