基于Halcon的车牌识别系统设计
2019-08-17段莉
段 莉
(重庆科创职业学院智能制造学院,重庆永川 402160)
基于Halcon的车牌识别是指通过识别车辆车牌来认证车辆身份的技术,它是智能交通系统的技术基础,是计算机视觉、图像处理技术与模式识别技术的融合,是智能交通系统中重要的研究课题。基于Halcon的车牌识别技术是集人工智能、图像处理、数据融合、计算机视觉、模式识别等技术为一体的复杂系统,要求识别精度高、处理时间短。
1 基于Halcon的车牌识别系统
1.1 车牌识别的原理
车牌识别分为车牌定位、车牌校正、车牌分割、车牌识别和软件平台实现几部分。车牌的定位就是通过对图像进行处理,使得车牌区域从拍摄的整张车辆图相中分离出来。车牌定位主要是通过边缘限定,面积限制等方法实现。车牌图像往往由于摄像机的摄像角度不同,使得拍摄的车牌图像产生一些倾斜,形成梯形或平行四边形的车牌。这就需要对车牌进行校正。校正主要是将这些定位好的车牌区域进行坐标变换,变换后的车牌图像编程规则的矩形。车牌分割就是将校正好的车牌图相内的每一个字符进行单独分割。分割主要是采用车牌区域内的文字的宽度进行距离上的划定。每个字符都将按距离被划分出来,这样实现了车牌的分割。车牌的识别是将分割好的文字进行识别。一般都是通过程序调用已有的工具包,通过类比来实现文字的读取识别。最后通过C#程序搭建处车牌自动识别的软件平台。
1.2 基于Halcon的车牌识别系统实现
系统实现的硬件环境以个人计算机为核心,数码相机通过USB端口直接与电脑相连。由数码相机拍摄采集到的原始图像为JPEG位图格式,分辨率640×480,需要将图像存储在PC机硬盘上,作为实验的原始数据。
系统的软件运行环境为MicrosoftWindows10操作系统。通过Halcon生成的程序都是以C#编程语言为基础,在VisualStudio2017集成开发环境下完成的。车牌识别系统结构如图1所示:
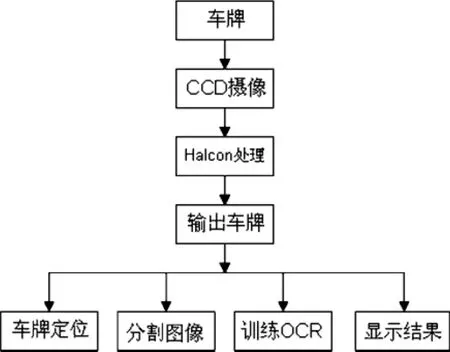
图1 车牌识别系统结构图
2 车牌识别算法
Blob是Halcon中的分析算法。Blob分析的思想是非常简单的,即在一个图像中相关物体的像素可以通过其灰度值来识别。Blob分析的优点是灵活性非常好。
Blob分析算法思想在车牌定位识别的过程中。首先通过对初始彩色图像进行三通道处理,得到蓝通道图像。然后对图像进行二值化处理,然后应用Blob分析,通过阈值限定,得到初步的车牌区域。最后经过阈值限定、膨胀处理及查找坐标,除去不相干区域,最后实现车牌的定位,得到的最终的车牌区域。
3 基于Halcon的车牌识别软件设计
基于Halcon的车牌识别的实现,其每一步都是通过充分利用内部提供的大量算子实现的。
(1)采集图像。图像获取是在所有的机器视觉的应用中都必须要解决的一个任务。图像获取设备有图像采集卡和工业相机等。Halcon提供了与大量图像获取设备交互的接口。在Halcon里,图像获取只有简单的几行代码,即几个算子调用即可实现图像的获取。
(2)处理图像。读取的图像需要做一定处理,图像中的车牌为蓝底白字牌照,所以选择将RGB彩色图像分成红色,绿色,蓝色三个通道,以便能够单独处理其中的明显的蓝色通道。
(3)分割图像。分割图像是整个车牌识别过程中非常关键的一步,分割质量的好坏直接影响后续对车牌区域的处理。图像的分割又分成以下几步:①阈值选择对于每一幅图来说,阈值可以被动态地提取。对于上步选择出来的红色分量通道图片R进行灰度处理,阈值范围160~255。②区域相联。车牌图像中被分割出来的区域有后车窗部分,车牌区域等干扰区域。运用connection算子将选择出来的区域进行相联,形成相连区域ConnectedRegions。③初步选择车牌区域。对于处理后的图像除了车牌区域外,其他的都为干扰区域。在阈值处理后的图像中,这些区域的形状和大小都不一样,于是用算子select_shape通过限定面积area和列column将车牌区域选择出来。④车牌区域膨胀。对于得到的车牌需要进行膨胀处理,膨胀半径一般为3或5.5。⑤车牌区域的最终选定。车牌区域膨胀后,车牌区域的信息虽然没丢失。但是仍存在一些边缘不整齐的凹凸。所以要对图像进行进一步的处理。⑥选定车牌字符。对于上一步得到的车牌区域还需要做进一步的处理,即将车牌内的字符选择出来。用算子reduce_domain把图像和区域结合起来,把区域当作图像的域来使用。然后用算子threshold对车牌区域进行分割,得到车牌字符。阈值范围为160~255。到此,图像分割才算结束。从最后得到的结果可以看出,处理结果比较理想。这为下一步文字训练以及文字识别提供了很好的准备工作。
(4)训练OCR。训练分为两个重要的步骤:首先对每个字符选择大量的样本并存储到所谓的训练文件,然后将这些文件输入到新创建的OCR分类器中。
(5)显示结果。经过训练,得到训练结果并最终显示车牌图像。在利用for循环时,首先利用算子set_tposition指定显示位置,然后利用算子write_string将文字写在指定的位置上。这样当for循环结束后,文字也最终显示在窗口指定位置上。
(6)创建和训练分类器对于训练后的文字,需要创建一个新的分类器,存储训练结果以便以后车牌的识别。
4 实验结果分析
经过实验和实时的图像效果显示,表明车牌的识别研究基本成功。下面主要从几个最重要的方面分析一下该车牌识别算法通用性和可靠性。
(1)车牌定位。在车牌定位中,最关键的是图像二值化后车牌区域的阈值范围以及面积的限定。对于每一张不同的车牌图像,可能受天气情况、摄像机与车的距离、车的颜色以及周围环境的影响,使得阈值参数和面积参数有些不同。这只需要修改threshold和select__shape算子中的部分参数即可准确实现车牌的准确定位。
(2)车牌分割。在车牌分割过程中,要求能够将车牌区域与整张图像完全分割出来。其中要求分割出来的车牌区域既不能有多余区域,又不能丢失必需的车牌区域。在实验处理过程中,可以看出车牌的分割利用字符最左上角和最右下角两个对角点的坐标将ROI区域框选出来。使用的算子是gen rectangle1,它能将车牌号码以矩形框的形式分割显示出来。如果选择的车牌区域不太理想,只需要修改其中的坐标参数即可很容易地重新选定区域,使分割达到最理想效果。
(3)文字训练。文字训练过程其实是一个简单的程序循环,是一个大量的重复性的丰富分类器的过程。对于每张不同的车牌图像,只要单独写入要训练的文字内容即可,当所有车牌号码包含的汉字、字母和数字训练完成后,便能识别所有的车牌号码。
4 结 论
本文主要对汽车牌照识别系统中车牌定位、字符分割、训练与字符识别的算法进行研究。编程实现了车牌的定位、字符分割、训练与字符识别。本文的处理都是针对车辆的灰度图像,灰度图像数据量比彩色图像小,运算比较简单,但是彩色图像二值化后会丟失丰富的信息。对整个系统的软件还需做进一步优化设计,提高程序的模块化、标准化水平,使软件设计更加合理、可靠和高效。
