深度学习目标检测算法在行车记录仪上的应用
2019-08-15王新雨汪驰升舒齐奇柯君卓
王新雨 汪驰升,3* 舒齐奇 柯君卓 高 青
(1.深圳大学城市空间信息工程广东省重点实验室,广东 深圳 518060;2.深圳大学海岸带地理环境监测自然资源部重点实验室,广东 深圳 518060;3.国土资源部城市土地资源监测与仿真重点实验室,广东 深圳 518000;4.深圳市南山区教育科学研究中心,广东 深圳 518000)
随着社会的发展,行车记录仪已经得到了广泛的应用。在交通管理规划方面,行车记录仪也起到了重要的作用,可以记录驾驶全过程的视频图像和声音,实现了车辆驾驶的实时视频监控、交通信息的采集和监控录像的回放,为交通安全和交通事故来提供证据,提高了规范的驾驶行为和行车安全,在这一方面已经有很多应用的说明[1-2]。自从2012年,AlexNet模型以绝对优势在Imagenet竞赛中取得胜利,迅速盖过了传统目标检测算法DPM (Deformable Part Model) 的风头,计算机视觉开始转向深度学习,此后深度学习在物体识别、检测等方面取得了重大的突破性进展和很多的成果,就备受学者们的重视,已经成为人工智能重点研究之一,各大科技公司也都投身于深度学习领域进行研发。
深度学习是一种利用深度神经网络框架的机器学习技术,其中卷积神经网络 (ConvNet) 是专门做图像识别的深度神经网络,它是模仿大脑视觉皮质进行图像处理和识别图像的深度网络,将人工设定特征提取转变为自动生成特征提取是卷积神经网络的主要优点,还具有局部连接和权值共享的特点,在目标检测方面已经远远超过传统的检测算法[3]。还有一个很重要的硬件因素就是GPU提供了强大的并行运算架构,训练速度比CPU快数10倍[4]。基于以上思想,提出一种利用行车记录仪记录的运动车辆的周围环境数据信息结合深度学习的目标检测功能对道路的车辆进行检测识别,然后得出行车过程中的道路上车的位置和数量。总而言之,即将深度学习的目标检测模型引入到行车记录仪的监控视频中,给智能交通监控、道路设计、交通管制和行车安全提供信息。
1 深度学习目标检测算法的原理
目标检测是指在特定环境下找出目标进行检测(where) 和识别 (what),基于深度学习的目标检测发展起来后,其实效果也一直难以突破,一直到R-CNN (Regionbased Convolutional Neural Networks) 出现后,它是第一个真正可以工业级应用的解决方案,后来经过不断地改进卷积模型,让大量的卷积层实现共享以提升效率,就出现了一系列的基于区域建议的方法:R-CNN 、SPP-net、Fast R-CNN、Ross B.Girshick[5]在2016年提出了新的Faster R-CNN,成为经典的模型。基于区域建议的目标检测算法发展过程如下:
R-CNN结构框架如图1所示[6],R-CNN的区域建议采用的是选择性搜索 (Selection Search) 代替传统的滑动窗口检测方法,从原始图片提取2 000个左右的候选框,再把所有候选框缩放到固定大小进行区域大小归一化、用卷积神经网络对这些候选框进行提取特征,将提取到的特征送入到SVM分类器中进行识别,再用线性回归来修正边框位置与大小[3]。但存在很多缺点:重复计算导致计算量很大,分类回归的SVM模型是线性模型无法将梯度向后传播给卷积特征提取层、训练分为多步,训练的空间和时间代价都很高。

图1 R-CNN框架
Fast R-CNN主要是解决了2 000候选框带来的重复计算问题,卷积变成对整张的图片进行,减少了很多的重复计算,其思想为使用一个简化的SPP层,训练和测试不再分为多步,不再需要额外的硬盘来存储中间层的特征,梯度能够通过RoI池化层直接传播;此外,分类和回归用Multi-task的方式一起进行,使用SVD分解全连接层的参数矩阵,压缩为两个规模小很多的全连接层[5]。Fast R-CNN比R-CNN的训练速度快8.8倍,测试速度快213倍,比SPP-net训练速度快2.6倍,测试速度快10倍左右。但是Fast R-CNN使用选择性搜索来进行区域提名,速度依然不够快[3]。
Faster R-CNN算法主要由两大部分组成:RPN候选框提取部分和Fast R-CNN检测部分[7]。在结构上已经将特征抽取、区域建议、区域判定和回归、分类都整合在了一个网络中,使得网络的综合性有了较大的提高[8-10]。它的主要思想为抛弃了选择性搜索,引入了RPN (Region Proposal Networks),从而让特征区域建议图、分类、回归一起共享卷积特征,在检测速度方面尤为明显[7]。RPN的网络结构如图2所示[7],以一张任意大小的图片为输入,输出一批矩形区域提名,使用的是滑动窗口加anchor的结合,每个区域对应一个目标分数和位置信息,且RPN网络能和整个Fast R-CNN检测网络共享卷积层[7],使得区域建议阶段在GPU上完成,且几乎不花费时,所以,Faster R-CNN 比Fast R-CNN 在速度和精确性上有明显的提高,尽管在后来的发展中,SSD和YOLO这些模型能够在检测速度得到提升,但是它们的精度却没有能超越Faster R-CNN的,例如:Tensorflow 应用Inception ResNet打造的Faster R-CNN,是速度最慢,但却最精准的模型[9-10]。

图2 RPN结构
整个Faster R-CNN网络的流程图如图3所示,分为4部分内容。
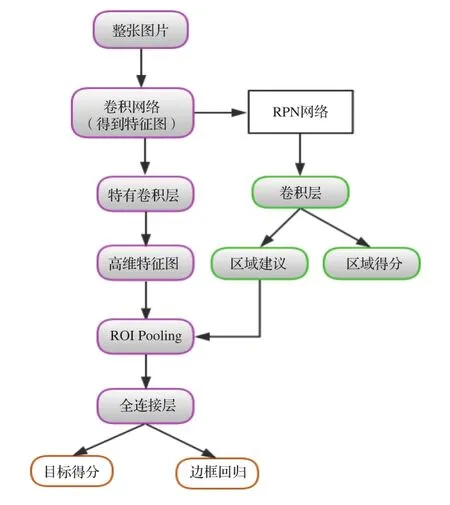
图3 Faster R-CNN流程图
(1) 先输入一副任意大小的图像,使用一系列的conv+relu+pooling层提取特征图,被用于的RPN层的输入和继续向前传播到特有卷积层得到高维特征图用于全连接层。
(2) RPN网络用第一步得到的特征图进行两部分的计算,分别为区域建议与区域得分,最后得到的区域建议用于下一步。
(3) ROI池化层是通过输入的高维特征图和区域建议提取一系列的特征区域建议图 (proposal feature maps) 送入后续的全链接层进行目标识别。
(4) 最后是利用全连接层与分类层计算这一系列的特征区域建议图通每个具体属于那个类别,同时再次利用边框回归获得每个目标的位置偏移量,从而获得目标检测框的精确位置。
最后,再由不同目标检测方法的指标得出[3](见表1):在不在乎时间的前提下Faster R-CNN是准确率最高的,所以,本文使用Faster R-CNN算法。
我的第五次辞工申请终于获准。离开大发厂时,我久久回眸。三步一叹息,五步一回首,牵强的笑容牵动了几滴清泪,在风中飘然落下。

表1 不同检测方法的指标对比
2 实验过程
本文使用matlab的深度学习工具Faster R-CNN实现进行车辆检测,实验环境:MATLAB R2018a (自带深度学习工具);CPU:i7-8750HQ;显卡:GTX1060;内存容量:8 G。
2.1 数据集的建立
本文采集的数据是在白天的情况下,从行车记录仪导出的100多个不同道路的行车视频 (mp4) 文件,然后把视频转化为一帧帧的图片 (jpg),每隔100帧提取一张的图片,共1 500张,都是驾驶在城市道路,其中,小汽车数目居多,800张为训练的图片,100张为测试的图片,600张为验证图片,用于标记的图像样本示例,如图4所示。
2.2 数据集的标注
使用了matlab自带的trainingImageLabeler.m这个M文件来对图片进行标注,图片标记界面如图5所示,全部标注好后导出一个table的data.mat文件,得到标注信息,如图6所示,一共包含1 400张图片的车辆数据集,每个图片有1个或多个标记的车辆实例。

图5 图片标记界面
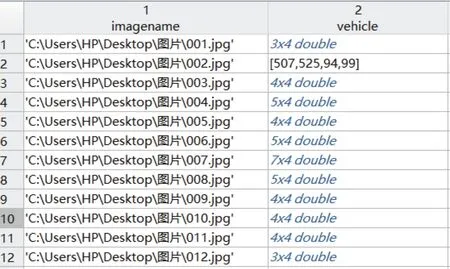
图6 图片标注信息
2.3 训练过程
由于CNN检测模型的训练需要大量的标记好的图片且训练的时间太长,所以,本次实验采用迁移学习,把训练好的模型进行微调来进行目标检测,因为是检测车辆,所以只有有车和无车两个类别,变成二分类问题[11],将全连接层改为2,然后再接上softmax和classification层,开始想使用ResNet50模型,但是在尝试训练过程中发现trainFasterRCNNObjectDetector这个函数不支持 DAG networks,像ResNet-50、 Inception-v3和 GoogLeNet这些模型就都不能用了。其实各网络就是在卷积层提取特征时有细微差异,对于后面的RPN层、池化层、全连接层的分类和目标定位基本相同。后来选择使用VGG16Net这个模型进行迁移学习,VGGNet网络是从ImageNet 数据库上的100万多张图像进行训练的,可将图像分类为1 000个对象类别,如键盘、鼠标、铅笔和许多动物,因此,网络为各种图像学习了丰富的功能制图表达,网络共有41层,有16层可学权重,13层卷积层和3层完全连接层。在训练过程中如果要使用GPU训练需要 Parallel Computing Toolbox这个工具箱,在附加功能资源那里下载即可,还需要用到Computer Vision System Toolbox、Image Processing Toolbox和Deep Learning Toolbox这几个工具箱。在训练参数中:选择了一个最小的16像素×16像素的窗口,网络误差算法使用的是动量随机梯度下降算法,学习率设置的0.001,每次输入的最小批次的大小是32,迭代次数20次,其余选项为默认[12-13]。训练用trainFasterRCNNObjectDetector
这个函数训练目标检测器,在训练过程中,从训练图像中处理多个图像区域,每个图像的图像区域数由NumRegionsTo Sample控制,PositiveOverlapRange和NegativeOverlapRange名称-值用于控制训练的图像区域,正面训练样品是那些与地面真相箱子重叠由0.6到1.0,由联合度量的边界框相交测量,负训练样本是重叠的0到0.3。
Faster RCNN训练分为以下四个步骤:
第一步是单独训练RPN网络,用预载入的模型来初始化。
用第一步的RPN 网络提供的区域建议来单独训练Fast R-CNN目标检测网络。
用第二步训练好的Fast R-CNN网络的权重来重新训练第一步的RPN模型,继续训练RPN。
用第三步训练好的RPN网络输出的区域建议图作为输入,再次训练Fast R-CNN,微调Fast R-CNN中的参数,得到目标检测模型。至此网络训练结束。
2.4 测试过程
车辆检测模型训练好以后进行保存,把100张的测试数据集循环到检测模型里进行检测,从检测的图片可以得到前方车辆的个数、位置 (bboxes) 和得分 (scores),车辆检测结果示例如图7所示,只显示检测出的车辆得分 (scores) 0.9以上的图片。

图7 车辆检测情况示例
2.5 验证过程
matlab的计算机视觉工具箱提供了目标检测器的评估功能,在这里用平均精度指标 (evaluate detection precision),Precision-recall曲线来验证模型的准确率,评估结果如图8所示,从评估结果来看,模型的平均精度达到0.92,满足检测的需求。

图8 模型的评估结果
3 实验结果分析
本次实验结果的分析是在行车视频中依次转化的一帧帧图片上面进行的,通过检测出的车辆可以得出标记框(bboxes) 的信息,bboxes是一个N×4矩阵,用于表示对象的边界框,前两列x、y代表了边界框的位置,后两列为w、h代表边界框的宽和高,w、h相乘得出标记框的像素面积,除了面积通过从bbxoes中的参数n可以得到检测到的标记框的个数既车辆个数,图片的视野像素面积为图片分辨率1 287×724=931 788,通过以上信息,本文进行以下分析。
3.1 基于行车舒适性的分析
在道路上交通量较小车速较快时,车头间距较大,交通密度小,驾驶员可以自由选择行驶车速,行车比较舒适;交通量较大车速较慢时,车头间距缩小,密度加大,车辆行驶时相互制约,产生拥挤情况,行车过程中不再舒适。根据行车的舒适性这个概念,本文对于多个不同路段的视频进行了检测,计算出每帧图片上检测到所有车辆标记框的像素面积占视野面积的比例和车辆个数,计算得出:当每帧图片的面积比超过0.4这个临界值时,车辆个数较多,密度较大,行车不再舒适。然后用百度地图测出每个行车视频中起点和终点的距离,得到的距离除以行车记录仪记录的时间求出行车速度,用行车速度进行验证,判断是否合理。以其中记录深圳市的香梅路、南海大道、新洲路、安托山一路、侨香路、深南大道六条道路的行车视频为例,每个行车视频记录时间为65 s,统计过程如表2所示。根据表2的验证:面积比保持在0.4以下,车速较快,行车比较舒适。所以这个指标合理。我们可以根据这个指标测出每个路段的行车是否舒适,然后为道路的交通规划和设计提供参考。
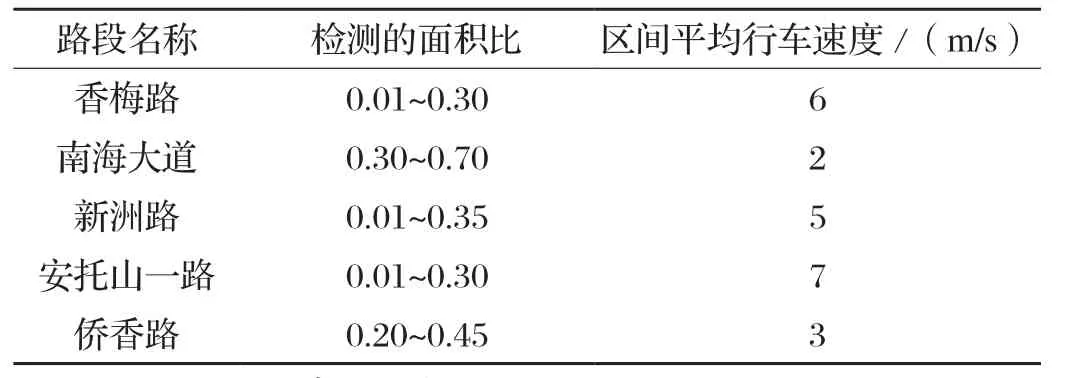
表2 面积比与行车速度的对比
3.2 基于车间距离的分析
目前常用的车间距离测量方法主要包括超声波、雷达、激光等,这些测量手段基本都是成本比较高的,如果行车记录仪可以测量辆车之间的距离,那么成本就会降低很多,也会非常的便捷[14]。 在道路行驶过程中为了保证车辆间的安全距离,驾驶员在驾驶过程中需要时刻注意周围的车辆运动情况,以免发生追尾碰撞的问题。据网上调查,车辆追尾事故中80%是因为行驶时跟车太近引发的,据交警介绍,很多追尾事故是因为车速过快,未与前车保持安全距离引起的[15]。本文中每帧图片上面标记框的面积大小代表了道路上的车辆和驾驶车辆之间的距离,距离近的标记框的像素面积较大,距离远的标记框的像素面积较小,所以本文提出根据标记框的面积大小计算出道路上各个目标车辆与驾驶车辆之间的距离,显示在行车记录仪上,距离过近时给出警报,也可以给驾驶员的行车安全距离提供参考。由于本文是采集了前方车辆的数据和小汽车这类车型,所以只计算前车车距并且不适用于公交车和卡车等车型,测量方法借鉴[16]中的车距模型并修改得出:当相机焦距固定时,两车之间的实际距离的平方与车辆在图片中的标记框像素面积的乘积是个定值,如公式1所示。实验先采集大量的数据,实际测量两车之间的距离和对应的标记框的像素面积的大小,代入公式1计算,然后统计得出大概的定值为18左右,再根据这个定值和标记框的像素面积求出前方车距。求出车间距离后,再用实际的距离做验证,如表3所示,可以看出检测距离和实际距离虽存在误差,但是大概相符。车间距离和像素面积拟合的曲线如图9所示,随着车间距离的增加,检测到的车辆标记框的像素面积在减小。所以,根据像素面积大小来大概判断车间距离时可行的,可以为驾驶员提供参考。

式中:L—两车的实际距离 (m) ;
S—标记框的像素面积 (10-5) ;
F—定值。

表3 实际距离与检测距离的对比
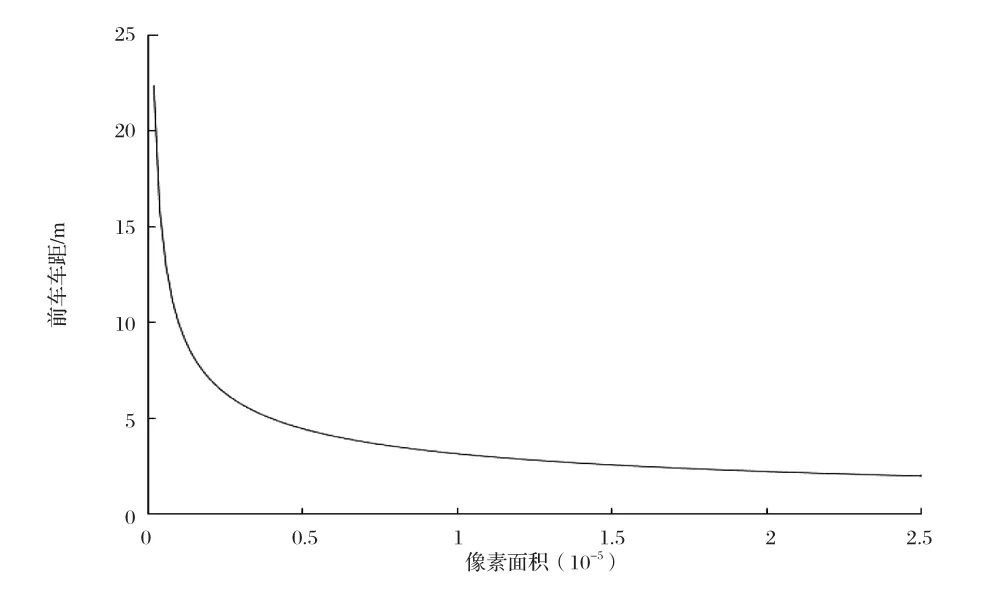
图9 像素面积大小和车间距离的关系
4 结语
本次实验是将深度学习的目标检测功能引入到了行车记录仪中,侧重点是深度学习的应用上面,所以没有对已有的算法进行改进和各类已有框架精度的比较。模型训练算法为主要分析图像区域的Faster R-CNN算法,标记的数据均来自白天,标记的车型比较全面,还需考虑夜晚的情况。实验得出模型的检测准确率为0.92,说明准确性较高,但是过小的目标车辆检测不到,同时存在由于处理的数据量较多而不能实现实时检测的要求,所以检测算法有待优化,接下来的工作打算用海量的无标注的行车视频数据来训练,从而达到实时检测的要求。检测出目标车辆后,根据检测到的标记框获得前方车辆的信息,提出行车舒适性和驾驶车与前方车辆的车距,本次实验由于车型、角度、道路场景和计算方法的欠缺[16],所以提供的指标、参数存在一定的误差,只供大概的参考,还需进行更详细的工作,但是希望通过行车记录仪得出的这些信息能给智能交通监控、交通管理规划设计和辅助驾驶提供帮助。
