基于模糊运算的电商客户数据挖掘研究
2019-08-14童百利吴晓兵
李 眩,童百利,吴晓兵
(安徽省铜陵职业技术学院 经管系,安徽 铜陵 244061)
0 引言
互联网经济环境下,电子商务快速发展,交易过程产生的客户数据规模不断扩大,维度不断增加,且数据类型变得十分复杂,呈现出大数据特征,但其蕴含的巨大商业价值能否最大限度利用,取决于数据挖掘和分析的方式.因此设计一种高效合理的数据挖掘方法对电商客户数据进行分析,这已经成为电子商务应用中研究的热点问题.对电商客户进行聚类,挖掘客户购买行为等方面的特征,针对不同客户群体提供量身定做的服务,进而实现高效精准的个性化服务和差异化营销.同时,也可为站点结构改进、网页推荐、发掘潜在价值客户等提供决策依据.
聚类过程是指将一组物理的或者抽象的对象,根据它们之间的相似程度,分为若干类.其中,特征相似的对象构成一类.[1]传统的聚类方法是基于经验或者简单的统计方法,聚类主观性强,效果不理想.其聚类方法一般都是硬划分,将对象进行严格区分,分类界限分明.而电子商务客户群具有多样性的特点,往往不能用某一严格界限对其进行具体类的划分,采用传统方法聚类不理想.模糊理论的出现为聚类提供新的思路,聚类思想由硬划分中的“要么属于,要么不属于”变化为“用属于程度来描述”.[2]客观事物之间没有一个截然区别的界限,不是严格分明的,是带有模糊性的,因此用模糊方法解决聚类问题必然更符合实际.模糊聚类结果不是说事物绝对地属于或不属于某类,而是指属于某类的程度有多大,其在聚类分析的基础上,引入“隶属度”来度量每个样本与各类的隶属程度,聚类结果比较科学合理.
1 模糊聚类算法
1.1 模糊聚类的原理
模糊聚类算法是基于目标函数优化基础上的一种数据聚类方法,[3]每项数据是哪类是比较模糊的,不能精确断定,只是在某些方面有相似性,这相似性聚类结果是每个数据对聚类中心的隶属度来度量得出的,该隶属程度用一个数值来表示 .[4]
模糊聚类算法执行步骤如下:
模糊聚类分析的目标函数:
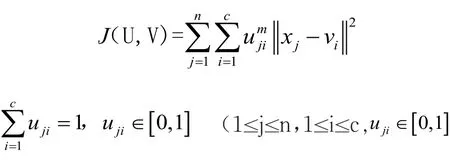
其中,uji表示样本 xj对应第i类中心 vi的隶属度,m是模糊权重因子(m>1),是样本 xj到第i类中心 vi的欧氏距离,c为分类数目(1<c<n),是n× c矩 阵 ,V = [ v1, v2…vc]是s×c矩阵,s代表维数.
(1)设定聚类数目c和模糊权重参数m,随机初始化聚类中心;
(2)计算所有样本数据的隶属度矩阵,并且是每列元素之和满足恒等于1的约束条件;
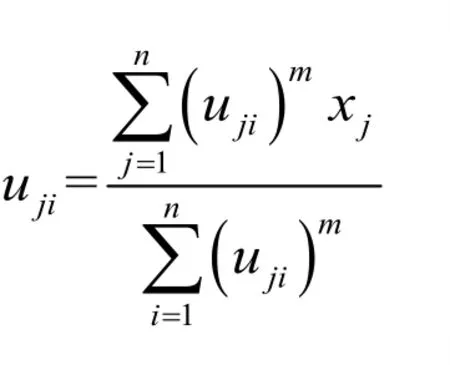
(4)计算 Vk+1,则有:

1.2模糊聚类的实现代码
模糊聚类的MATLAB程序[5]代码共包括三个函数,通过相互调用能实现聚类的过程和结果输出,代码如下:
function[U,V,objFcn]=myfcm(data,c,T,m,epsm)
c=4
if nargin<3
T=100;
end
if nargin<5
epsm=1.0e-6;
end
if nargin<4
m=2;
end
[n,s]=size(data);
U0=rand(c,n);
temp=sum(U0,1);
for i=1:n
U0(:,i)=U0(:,i)./temp(i);
end
iter=0;
V(c,s)=0;U(c,n)=0;distance(c,n)=0;
while(iter<T)
iter=iter+1;
Um=U0.^m;
V=Um*data./(sum(Um,2)*ones(1,s));
for i=1:c
for j=1:n
distance(i,j)=mydist(data(j,:),V(i,:));
end
end
U=1./(distance.^m.*(ones(c,1)*sum(distance.^(-m))));
objFcn(iter) =sum(sum(Um.*distance.^2));
if norm(U-U0,Inf)<epsm
break
end
U0=U;
end
myplot(U,objFcn);
function d=mydist(X,Y)
d=sqrt(sum((X-Y).^2));
end
function myplot(U,objFcn)
figure(1)
subplot(4,1,1);
plot(U(1,:),'-k');
title('隶属度矩阵值')
ylabel('第一类')
subplot(4,1,2);
plot(U(2,:),'-k');
ylabel('第二类')
subplot(4,1,3);
plot(U(3,:),'-k');
ylabel('第三类')
subplot(4,1,4);
plot(U(4,:),'-k');
xlabel('样本数')
ylabel('第四类')
figure(2)
grid on
plot(objFcn);
title('目标函数变化值');
xlabel('迭代次数')
ylabel('目标函数值')
2 电商客户数据模糊聚类
2.1电商客户模糊聚类的MATLAB实现
本文运用网络爬虫软件获取某电商网站的历史交易数据后,采用其中16位客户数据进行聚类来验证算法的可行性和有效性.每位用户数据包含6项指标值:商品购买量、交易总金额、单次交易均额、消费频率、网站登录次数、消费商品类目数,上述指标数据均为同段时间内的交易数据,能较全面描述消费者自身及消费行为的特征,[6]16位客户数据如表一所示.MATLAB程序中,聚类数目设定c=4,n参数为16,data为16位待聚类客户的6维数据矩阵,模糊度m=2.在MATLAB环境中运行上述程序,得到每位用户划类的隶属度值如表2所示,图1为隶属度矩阵值的示意图,根据隶属度值的大小和图1能得知每位客户的最佳聚类,图2为目标函数变化值示意图,经过8次迭代运算,模糊聚类算法收敛,目标函数值已经非常稳定,说明聚类迭代计算已达到要求.

16 100 10000 5000 2 6 2
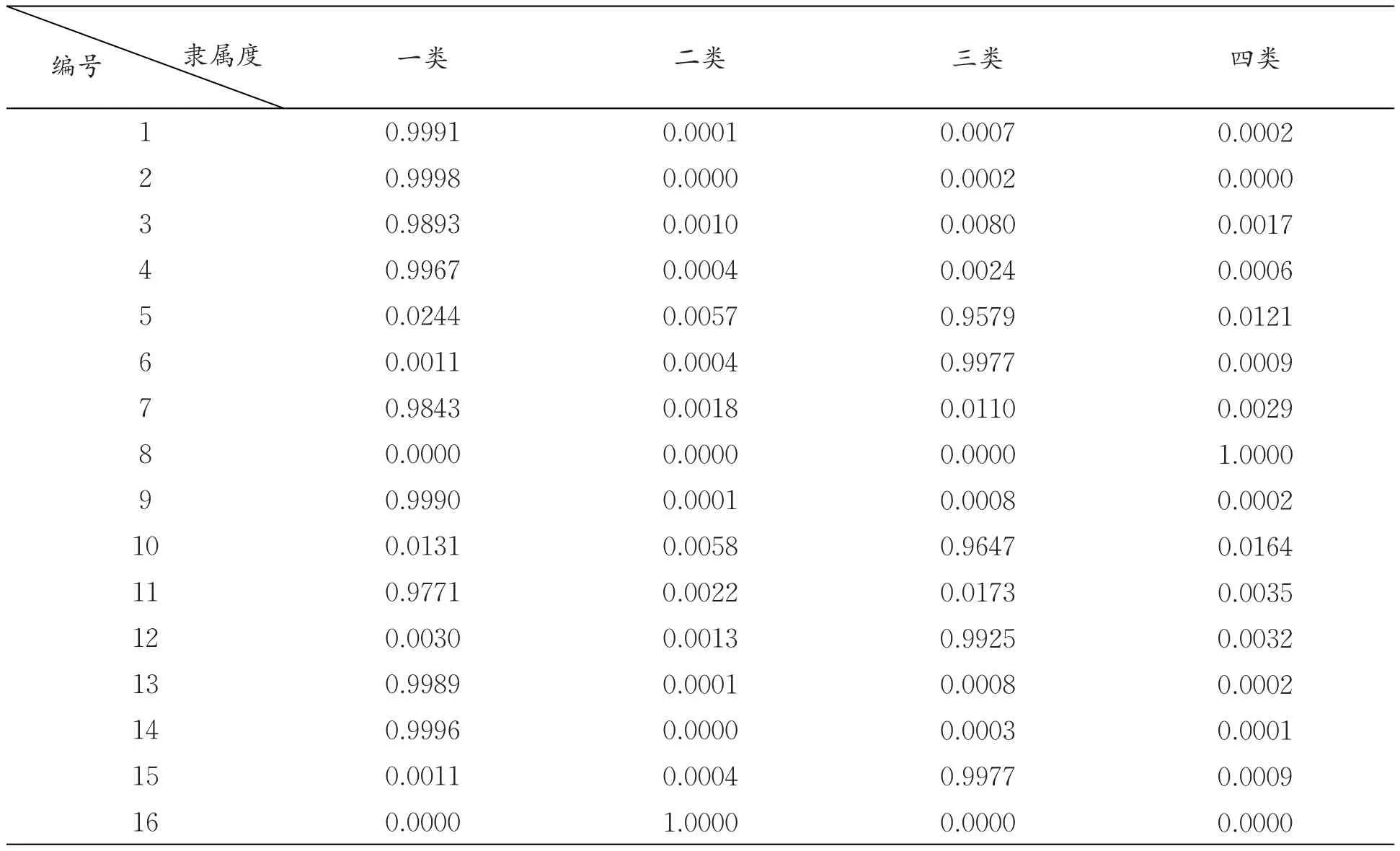
表2 模糊聚类隶属度

图1 隶属度矩阵值
2.2实验结果及其分析

图2 目标函数值变化
从MATLAB聚类实验结果看出:序号为1、2、3、4、7、9、11、13、14的客户,该类客户群虽单次消费额不高,企业从这客户群获利不大,但他们消费频率高,交易会持续稳定,是企业稳定生存的基础客户;序号为5、6、10、12、15的客户聚为一类,该类客户群消费频率高,交易总额和单次交易均额都较大,且购买数量多,可以从他们的交易中获得较高利润,是电商的优质客户,应重点维护;序号为8的客户,消费频率高,交易总额大,但购买商品数量大,平均到每次交易的交易额不高,他们需求量大,极可能为网络渠道的进货商,也很在乎价格,他们对电商具有一定价值,应该通过适当的营销策略转变优质客户;序号为16的客户消费频率低,但交易额高,单次交易给企业带来的利润也高,是电商的潜在客户,应通过营销和维护使其转变为稳定的优质客户.
结 语
在商业市场中,市场客户种类和需求日益繁多,如何有效细分、规划客户群,并制定针对性的营销策略,是激烈市场竞争的成功所在.本文提出了基于模糊理论的数据聚类方法,来实现电商客户聚类特征提取提供了很好的解决思路,实验结果表明,该算法是可行的合理的.同时,该方法对于其他专业领域如模式识别、模糊控制亦有一定的实际指导意义,为问题的突破提供好的思路.
