煤矿领域知识图谱构建
2019-08-14潘理虎张佳宇张英俊谢建林
潘理虎 张佳宇* 张英俊 谢建林
1(太原科技大学计算机科学与技术学院 山西 太原 030024)2(太原科技大学环境与安全学院 山西 太原 030024)
0 引 言
煤矿的安全生产和管理一直是该领域研究的热点,虽然近几年国家采取一系列政策使得煤矿安全形势有所好转[1],但事故发生率及事故总量仍高于世界其他主要煤炭生产国,面临的安全隐患不容小觑。且因信息化智能应用的增多,当前行业数据产生速率加快,累计了大量的数据。这些数据形式多样,数量庞大,传统的数据管理方式已无法满足行业数据管理需求[2]。
本体通过对领域知识的组织和管理,不仅能够有效地对矿井情景进行形式化描述,而且通过Jena推理机和自定义规则对知识的推理,还能充分挖掘其中的隐含信息。知识图谱是一种结构化的语义知识库,可以将网络信息、数据资源关联为语义知识,以备后续研究利用,是目前大数据时代知识的表示方式[3]。因此,将本体与知识图谱相结合,能够更加有效地对煤矿领域知识之间的联系进行分析,特别是在煤矿安全监测监控方面。目前存在的煤矿安全监测监控系统大多侧重于对人员及设备信息的监测监控,忽略了人员、设备、操作及环境等信息之间的内在联系,知识图谱能够将井下设备、环境状态、操作状态等信息进行关联,使得相关工作人员快速高效全方位地掌握矿井信息,在事故防治以及安全管理方面均有一定意义。
知识图谱的构建方式有两种[4],一种是自顶向下的构建方式,一种是自底向上的构建方式。前者指的是预先为知识库定义好本体或数据模式,然后再将实体加入到知识库中,即利用一些现有结构化知识库作为基础知识库,Freebase项目就是采用此方式[5]。后者指的是先利用相关技术把开放链接数据和在线百科数据中有用实体提取出来,从中选择置信度较高的添加到知识库中,从而构建出顶层本体模式[6]。
本文采用的是自顶向下的知识图谱构建方式。在分析比较常用的几个本体建模方法后,结合煤矿数据特点,采用七步法与METHONTOLOGY法相结合的本体构建方法对煤矿领域本体进行建模。并基于该本体构建煤矿领域核心知识图谱,具体可分为三步:(1) 对本体与图数据库的映射匹配机制进行分析,并制定映射规则;(2) 根据具体规则将本体数据进行存储,并补充实体内容,实现初始知识图谱构建;(3) 在前两步的基础上,设计并开发煤矿安全监测监控原型系统,使得相关工作人员能够及时对矿井信息进行全面了解,以此减少事故发生量,保障人员和设备安全性。
1 煤矿领域本体建模
本体的构建方法各异,最常见的有七步法[7]、骨架法、METHONTOLOGY法[8]、TOVE法[9]、IDEF5法、SENSUS法和KACTUS法。其中,七步法、骨架法、TOVE法及METHONTOLOGY法的生命周期较为完整,但溯本追源,七步法、骨架法和TOVE法均未有真正的生命周期。从其配套的相关技术角度看,七步法和METHONTOLOGY法有其相关配套技术,只是METHONTOLOGY法相对不全,而其余方法配套的相关技术皆不确定。就方法说明的详细程度而论,七步法、METHONTOLOGY法及IDEF5法较多,而其余方法相对较少。除此之外,每种方法的构建形式不一,除七步法采用半自动方式构建,其余大多数为人工方式构建。由此可知,七步法和METHONTOLOGY法较为成熟。
煤矿领域数据是指煤炭生产和管理过程中所产出的数据,具有数据量大、种类多、价值密度低及数据产生变化快的特点[10]。在煤炭生产过程中会有瓦斯监测数据、设备运转数据、事故发生因素及工作人员个人信息等不同种类数据产生。且矿井员工在工作过程中会使用多种监测设备与传感器,以实现对员工的实时监控,在这过程中会有海量数据产生,但真正有用的数据却很少,因而数据价值密度并不高。与此同时,该领域中信息化应用逐渐增多,伴随着数据的产生量与速度也在急速增长。利用本体能够有效地组织和管理煤矿领域数据,但由于七步法在构建本体的过程中往往会忽略内容的更新,而煤矿领域数据更新速度快,倘若在构建途中有新知识出现,或知识发生变化,该方法则不再适用。METHONTOLOGY法在每一步操作完成后都能对其进行修改,恰好弥补以上不足。因此,本文提出了一种将两者相结合的本体构建方法,具体开发流程如图1所示。
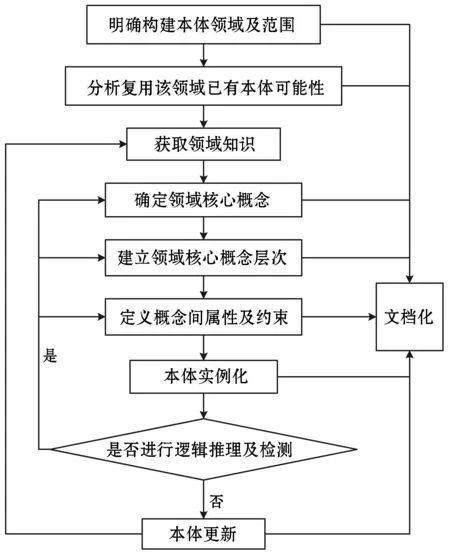
图1 本体开发流程
1) 明确构建本体领域及范围 本文从煤矿安全的角度出发,通过书籍、文献、电子资料等途径获取信息,抽象出煤矿安全监测的相关对象,了解设备、环境、操作、工种、灾害(事故)之间的关联关系,确定了构建本体的领域范围包括:采煤工作面、掘进工作面、井下通风、井下运输及安全监测监控。
2) 分析复用该领域已有本体可能性 通过查阅、调研已有本体模型,对郭华的瓦斯监控系统本体[11]、药慧婷的煤矿掘进工作面本体[12]、刘婷的采煤工作面本体[13]、李婉婉的通风系统本体及运输系统本体[14]进行分析复用。
3) 获取领域知识 通过实地调研及对领域专家的访谈,以国家安监局制定的规程为主要知识源,《中国分类主题词表》中的矿山词表、CNKI文献以及《煤矿机电设备操作技术工人》、《通风安全技术工人》等书籍为辅,并结合领域术语标准,完成对煤矿领域知识的获取。
4) 确定领域核心概念 对获取数据进行分类、分析、归并整理,提取出核心概念,如表1所示。
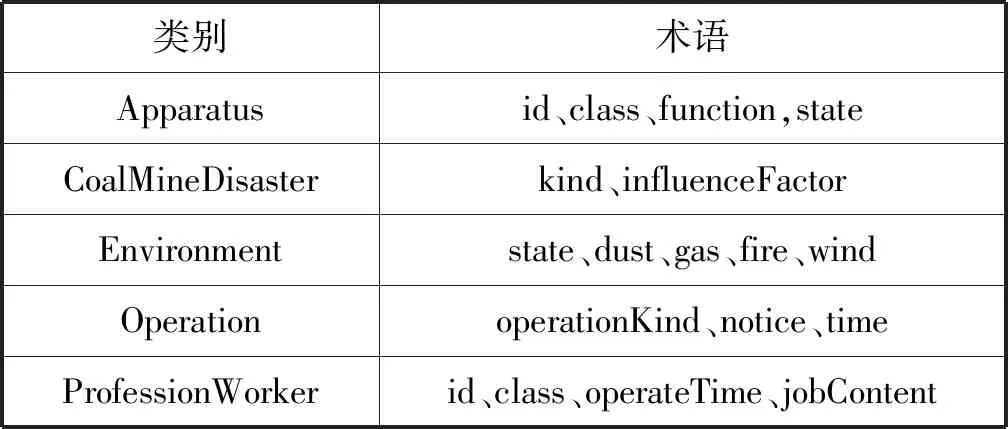
表1 煤矿领域数据术语(部分)
由于上述概念存在语义重复、表达不规范等问题,因此,以上术语并不是最终本体中的概念,接下来本文将对其进一步整合,使其具有唯一性。
5) 建立领域核心概念层次 通过分层的形式可对领域中概念有一个明确的认识,例如:高层的类代表最高抽象层次的概念,而低层的类是高层类的子类,其继承了高层类所有的属性,实体概念更加具体。且在Protégé中,最顶层的类是Thing,本文中定义的五大类:设备、灾害、环境、操作以及工种均为该类的子类,例如操作(Operation)类,详情见图2。

图2 煤矿领域本体中操作类
6) 定义概念间属性及约束 只定义煤矿领域知识中的类和类的层次结构还无法完整地表达煤矿领域知识,还需通过属性及属性约束来详细描述类的结构及特征。属性包括两类:对象属性、数据属性。其中,对象属性是指对类之间的关系进行描述,如图3所示,hasApparatus可以表示在某个工作地点有一个仪器。而数据属性是指对类本身所具有的特质进行描述,如4所示,hasGasConcentrationValue指气体的浓度值。

图3 煤矿领域本体中部分对象属性
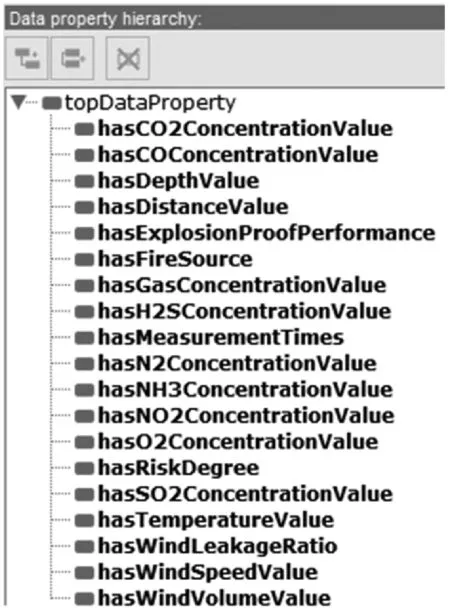
图4 煤矿领域本体中部分数据属性
7) 本体实例化 为了能够将构建的本体模型应用到实际问题中,需要给本体中的类添加相应的实例和属性,以扩充本体内容。例如在图5中,为钻眼工(DrillingWorker)添加了属性和实例。
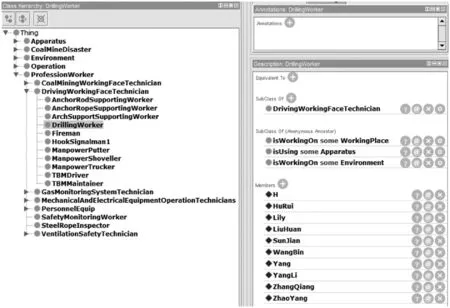
图5 钻井工人的属性及实例
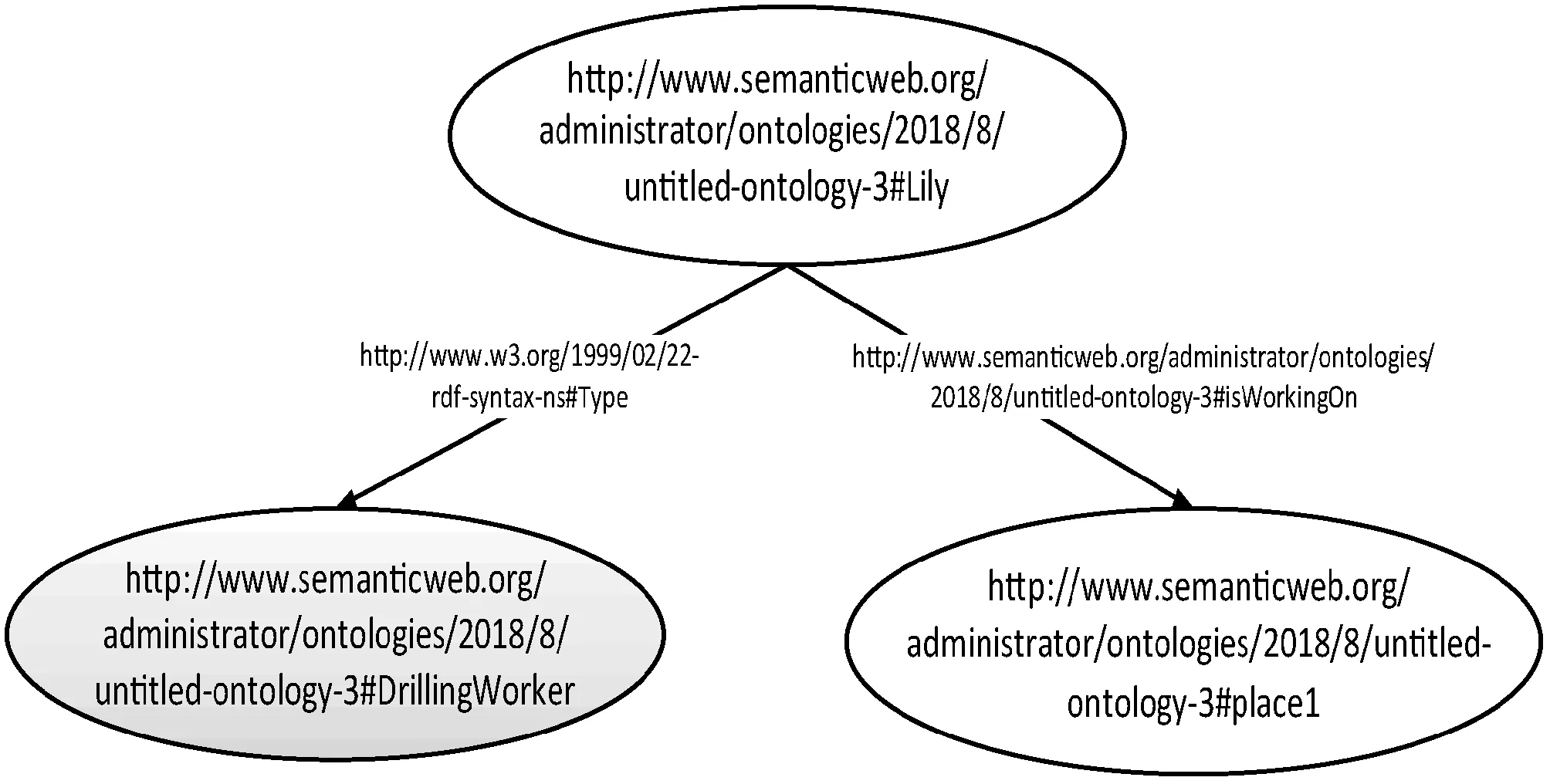
钻眼工是工种的一个子类,具备使用设备(isUsing some Apparatus)、工作环境(isWorkingOn some Environment)、工作范围(isWorkingOn some WorkingPlace)属性,而HuRui、Lily等为钻眼工的实例(Members),能够继承上述属性。如图6所示,Lily是一名钻眼工,在Place1工作,同时在这里工作的还有HuRui、LiuHuan等。
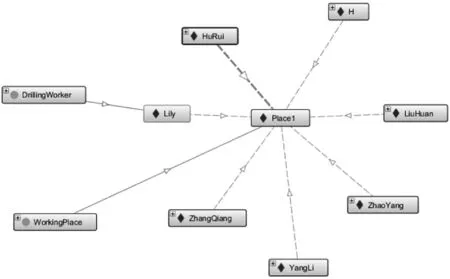
图6 钻井工人Lily的属性描述
8) 逻辑推理及检测 逻辑推理是指根据现有材料按逻辑思维的规律、规则形成概念、从而作出判断,达到推理的目的。Protégé自带推理机制,可以对实例进行一致性检测,消除语义差异,即其可以保持本体逻辑关系的一致性,避免本体出现语义矛盾,能够为后续本体推理提供保障。例如,为工作地点添加一个实例Place2,且满足hasGasConcentrationValue some float[>=0.05],hasO2ConcentrationValue some float[<=0.2],hasTemperatureConcentrationValue some integer[>=650]三个属性中任意一个,那么,就代表Place2不安全,需要相关工作人员采取对应措施处理。如图7、图8所示,给工作地点添加实例Place1和实例Place3,并将其数据属性hasGasConcentrationValue分别设定为0.08f和0.02f,经一致性推理后可知,Place1是一个危险工作地,而Place3安全。
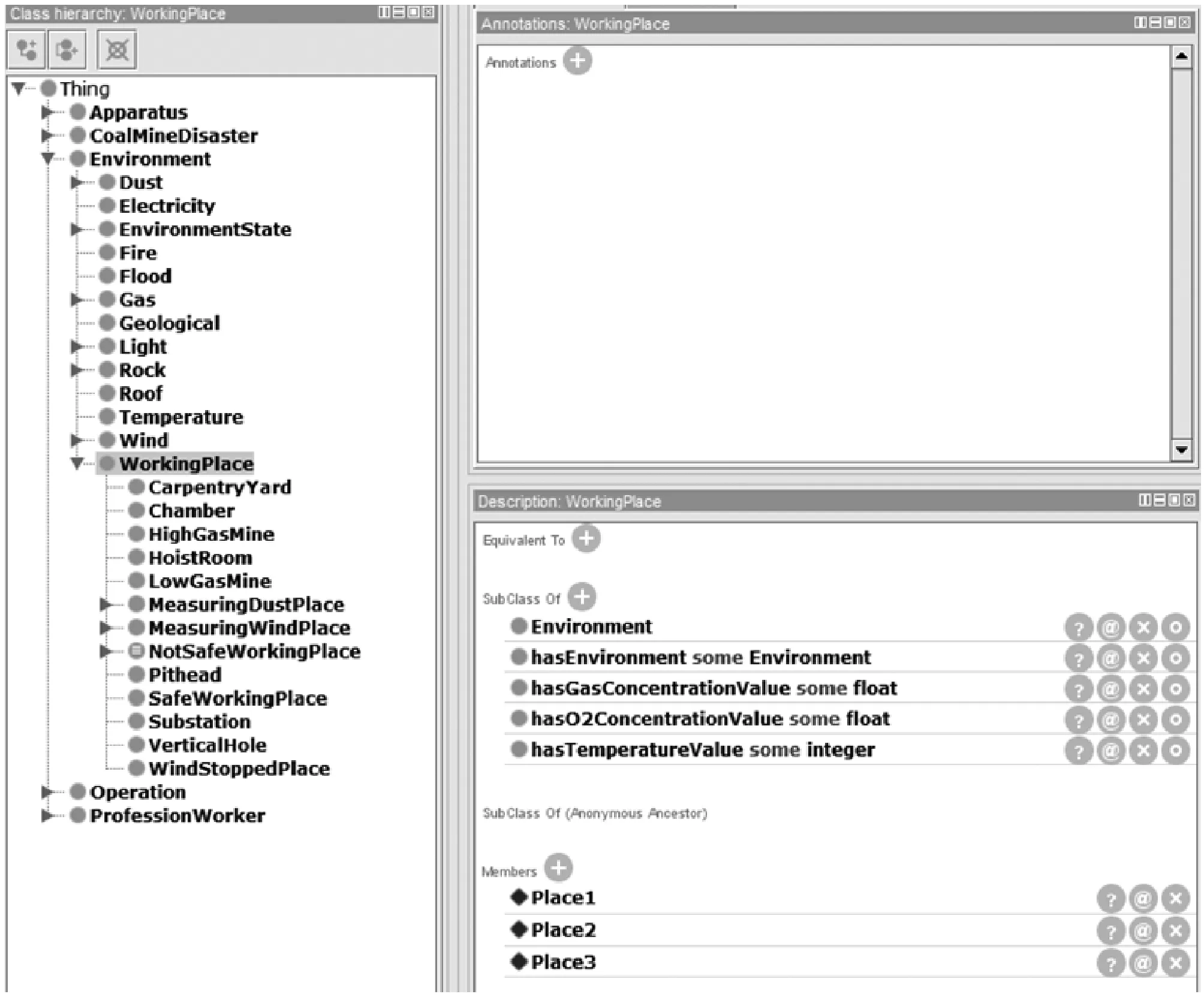
图7 添加实例Place1、Place2、Place3
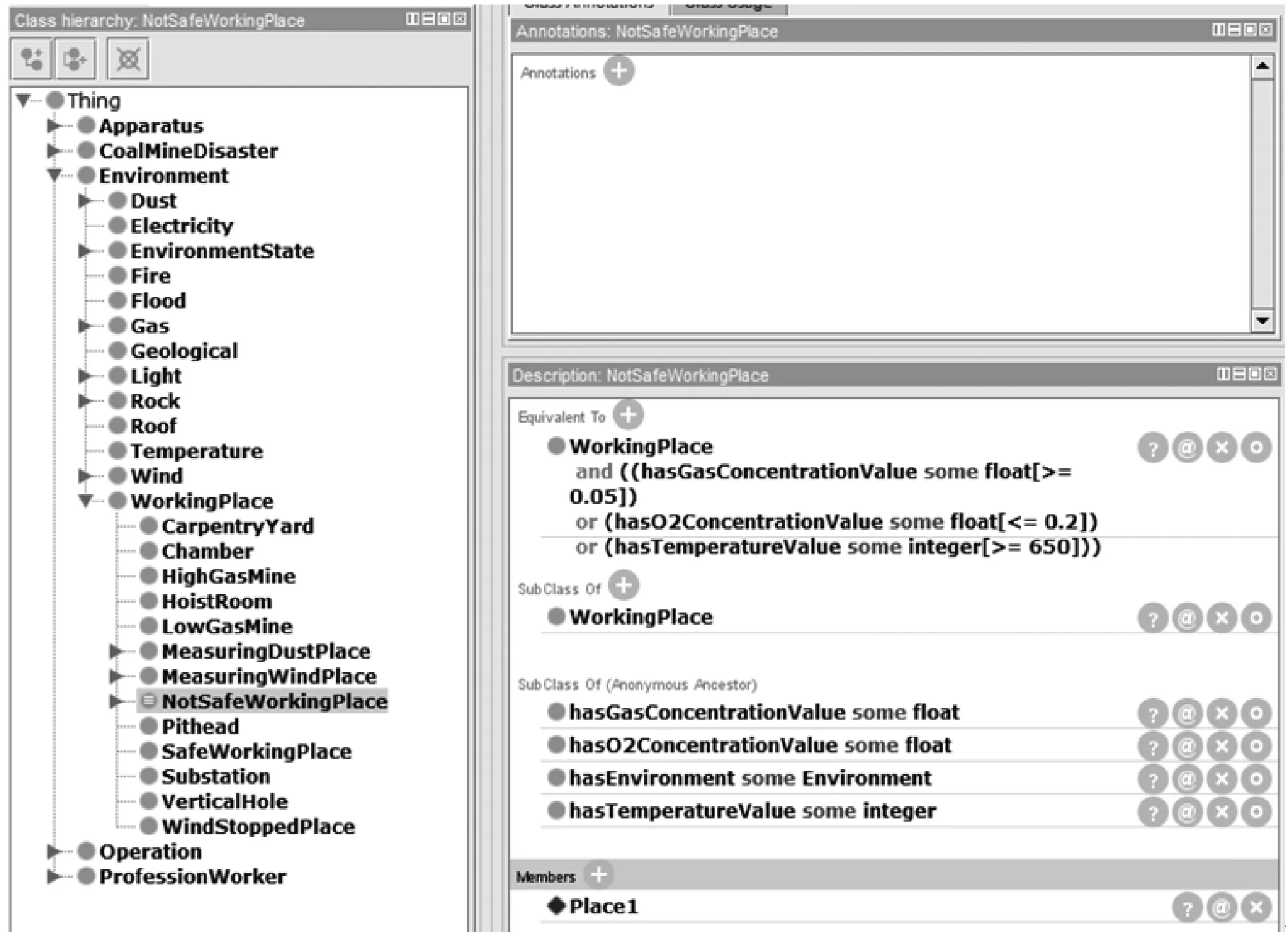
图8 一致性检测后
9) 本体更新 本体更新的数据来源主要有两个:一是经过逻辑推理和一致性检测后所得数据;二是煤矿领域出现的新数据。本文从CNKI数据库检索到1999年-2017年间有关煤矿领域文献2 564篇,对其进行数据抽取,并按煤矿领域本体的概念分类对本体内容进行补充,实现本体更新,更新后本体如图9所示。
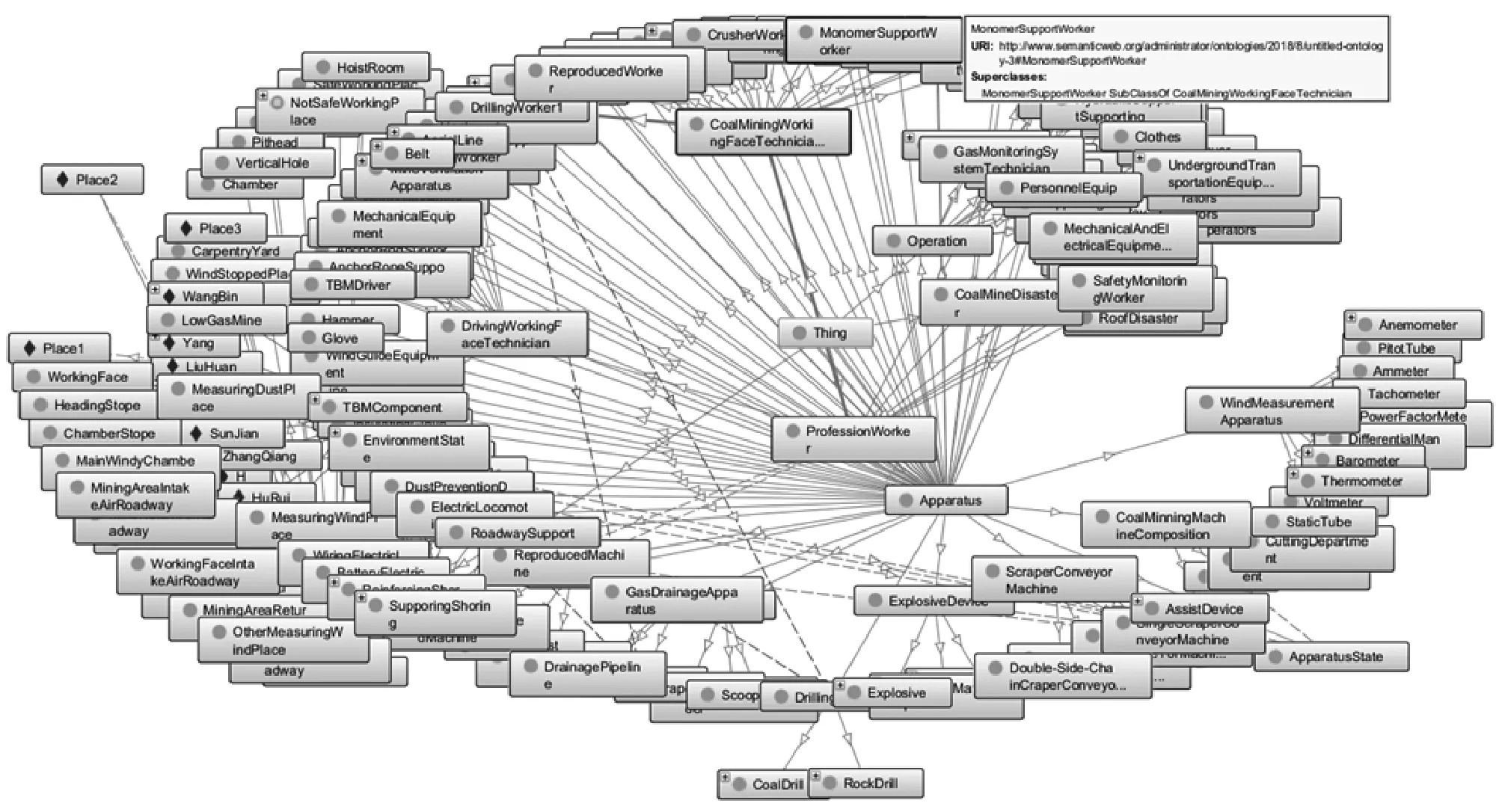
图9 煤矿领域本体模型
10) 文档化 通过以上步骤,本文煤矿领域本体模型基本构建完成。本体描述语言OWL能够实现本体模型的形式化表示,为后续数据实例化、本体推理等提供标准、统一的语言规范。煤矿领域本体OWL文件部分内容如下:
(1) 类的存储:
(2) 对象属性的存储:
(3) 数据属性的存储:
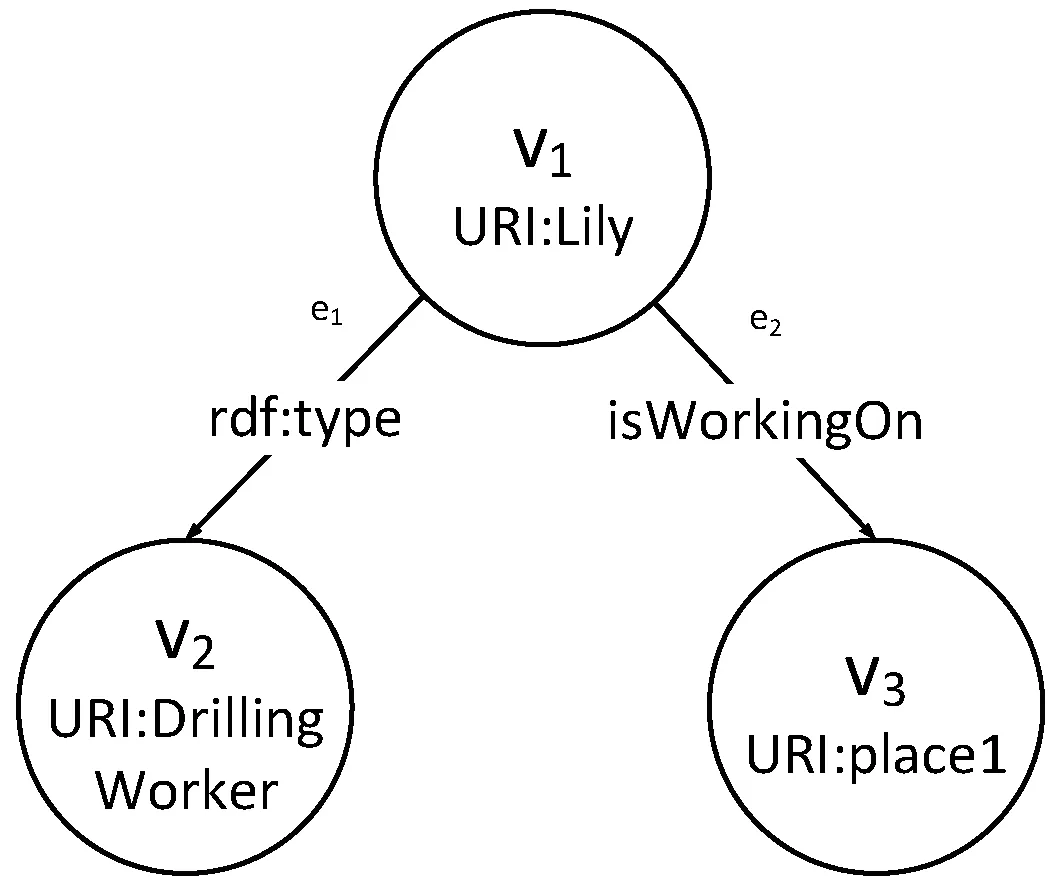
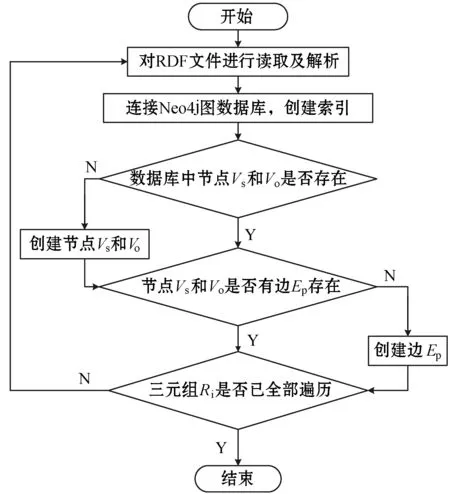
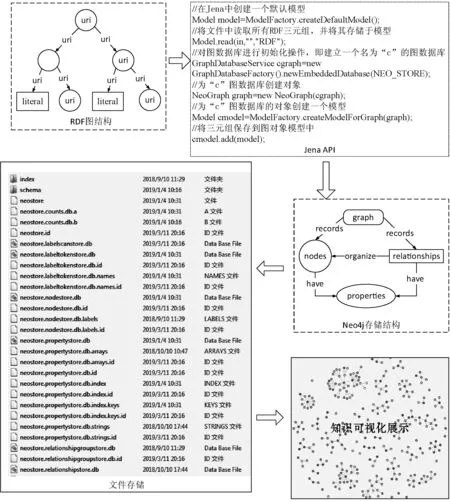
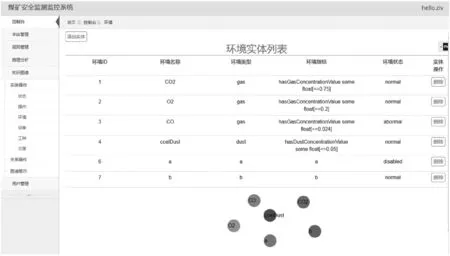
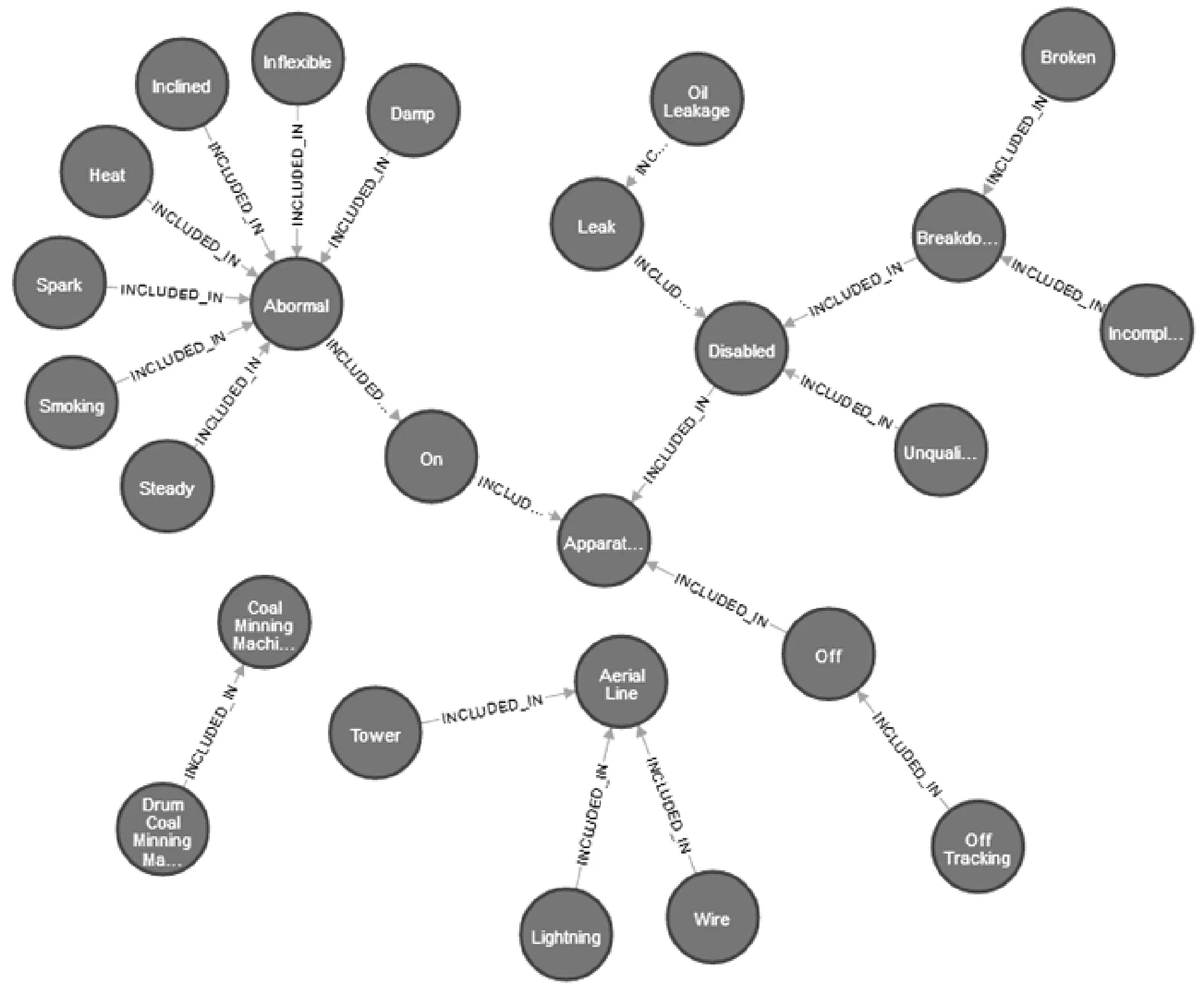
对于特色农产品而言,要想实现其标准化翻译,不仅要提高企业的重视程度,更要政府加强对农产品英文翻译的规范。同时,也要对特色农产品的名称以及中英文简介进行明确规范。在实际中,不同的农产品企业对于同一种农产品的简介并不相同,这样既不利于外国友人对中国特色农产品进行了解,也不利于特色农产品向国际化方向发展。由此可见,要提高政府对农产品英文翻译的重视程度,严格规范英汉名称与简介信息,培养专业的农产品英文翻译团队,增加专业的农产品翻译人员,鼓励相关人员进行市场调研,推动市场经济快速发展。 rdf:about="#hasCO2ConcentrationValue"/> (4) 一般公理的存储: rdf:about="#ThreeChainScraperConveYorMachine"/> 本体通常使用OWL语言描述,其保存格式为RDF三元组。而RDF图[15-16]由多个三元组构成,三元组=<主语,谓语,宾语>。图数据库中的节点可由主语和宾语转化,节点之间的边可由谓语转化,表示主语和宾语之间的关系。因此,本体文件能够映射到图数据库实现知识的存储。 本文中,对此有如下定义: 定义1将RDF的存储模型定义为: r= (1) 式中:s表示主语,p表示谓语,o表示宾语。 定义2图数据库中的图结构形式化为: G= (2) 式中:V为图数据库中节点集合;E为边集合;P为属性键值对集合;src、tgt和lbl都表示函数关系,分别表示为图中每条边都有一个起点,图中每条边都有一个终点,图模型中每一个节点/边都可以设置零个或多个标签来标识。 考虑到RDF具有空节点、数据类型不同等问题,制定具体的映射规则来约束存储关系的映射,包括节点映射规则、边映射规则。 1) 节点映射规则: (1)S为RDF的主语集,O为RDF的宾语集,V为图数据库的节点集,S和O都可以映射成V,且V不重复出现,即主语s、宾语o及节点v之间存在一个映射函数,能够将主语s和宾语o映射为图数据库中的节点v。 (2)U为RDF中的URI集合,是三元组中的主语或者宾语,则有u∈U∩u∈(S∪O)。在图数据库中为其设置一个属性,构成属性集f(vu),且以“uri”为标签。 f(vu)={("URI",str(u))} lbl(vu)="uri" 式中:vu为u在图数据库中的对应节点,str(u)为代表该URI的字符串。 (3)B为空节点集合,b在RDF中为空节点的主语或者宾语,则有b∈B∩b∈(S∪O)。在图数据库中为其设置一个属性,构成属性集f(vb),且以“bnode”为标签。 f(vb)={("URI",str(b))} lbl(vu)="bnode" 式中:vb∈V,str(b)表示唯一标识该空节点的字符串。 (4)L为文字节点集合,l在RDF三元组中为Literal的主语或宾语,则有l∈L∩l∈(S∪O)。在图数据库中为l设置三个属性,构成属性集f(vl),且以“Literal”为标签。 f(vl)={("value",str(l)),("datatype",type(l))("lang",t(l)} lbl(vl)="literal" 式中:str(l)为文本值,type(l)为文本的数据类型,t(l)为文本的语言。 2) 边映射规则: (1) 存在一个从RDF三元组到图数据库的边映射函数,能够实现三元组谓语P到图数据库边E的映射。 (2) RDF三元组可表示为 lbl(e)=str(p)src(e)=vstgt(e)=vo 式中:vs为边e的开始节点,vo为边e的结束节点。 (3) 若RDF三元组中的谓语P都为URI,那么,就不需要设置额外的属性,设置标签lbl即可确定。 以图6中的钻井工人Lily为例,其相应RDF图表示见图10。 图10 工人信息RDF图 采用以上映射规则,可以将图10中各元素表示为: V={v1,v2,v3}E={e1,e2} src(e1)=v1tgt(e1)=v2lbl(e1)="rdf:type" src(e2)=v1tgt(e2)=v2lbl(e2)="isWorkingOn" f(v1)={("URI",Lily)} f(v2)={("URI",DrillingWorker)} f(v3)={("URI",place1)} 按映射规则映射后,得到对应的图数据存储图如图11所示。 图11 工人信息RDF图映射后的图数据存储 Neo4j是一个典型的、高性能NOSQL图数据库,用Java语言实现,存储方式不同于一般数据库的表格存储,以网络的方式对结构化数据进行存储。与其他非关系型数据库相比,Neo4j支持ACID事务,支持海量数据存储,具有成熟数据库的所有特性,能够很好地解决煤矿领域数据价值密度低、数量大、更新速度快的问题。因此,本文选用Neo4j图数据库来进行研究。 根据第2节对本体与图数据库的映射匹配分析,本文采用知识存储映射算法将煤矿领域本体内容映射到Neo4j图数据库中,实现本体数据到图数据的转换与煤矿领域知识的存储,即先读取已存储的RDF文件,并对每一个三元组进行遍历,最后根据存储映射规则实现知识的存储。涉及到的知识存储映射算法[17-18]如下。 输入:RDF文件,Neo4j图数据库地址(dbURI) 输出:Neo4j图数据库中存储的本体内容 (1) 用Jena API读取RDF文件进行读,获取全部三元组R,并将三元组Ri(共n个三元组,i≤n)解析得Triple={s,p,o}。 (2) 经RestAPIFacade访问连接Neo4j图数据库(dbURI),使用Transaction开启事务,并为节点和边建立索引RestNode、RestRelationship。 (3) 从RestNode中获取Triple.s及Triple.o的对应节点Vs和Vo,判断Vs和Vo是否已经存在于数据库中,若不存在,则创建新节点并将其添加到RestNode中。 (4) 从RestRelationship中获取Triple.p的对应边Ep,判断Ep是否已经存在于数据库中,若不存在,则创建一条由Vs指向Vo的有向边,并将其加入到RestRelationship中。 (5) 判断三元组Ri是否已全部遍历,若i≥n,则已全部遍历,继续下一步操作;若i (6) Neo4j图数据库中得到已存储的本体内容。 存储算法流程如图12所示。 图12 知识存储算法流程 知识存储具体实现过程见图13。 图13 本体数据到Neo4j图数据库的存储实现过程 (1) 采用Jena API对煤矿领域本体文件(cms.rdf)进行读取及解析,并在Neo4j图数据库中建立一个名为“c”的图数据库,然后将解析后的所有RDF三元组数据存储于此图模型中,该过程核心代码如下: //对RDF文件进行读取 InputStream in=FileManager.get().open(inputFileName); //在Jena中创建一个默认模型 Model model=ModelFactory.createDefaultModel(); //将文件中读取所有RDF三元组,并将其存储于模型 Model.read(in,"","RDF"); //对图数据库进行初始化操作,即建立一个名为“c”的图 //数据库 GraphDatabaseService cgraph=new GraphDatabaseFactory().newEmbeddedDatabase(NEO_STORE); //为“c”图数据库创建对象 NeoGraph graph=new NeoGraph(cgraph); //为“c”图数据库的对象创建一个模型 Model cmodel=ModelFactory.createModelForGraph(graph); //将三元组保存到图对象模型中 cmodel.add(model); (2) 图13中Neo4j存储结构部分指的是,nodes和relationships除了两者间映射关系外,还可以结合实际情况为其自身添加properties。 (3) 经前两个步骤,Neo4j中会产生相应的存储文件,主要有三部分构成:nodes存储文件、relationships存储文件以及properties文件。 (4) 通过Neo4j将存储的煤矿领域知识进行可视化展示。 目前,我国采取的安全管理模式仍以“事后管理”为主,主要是因为领域数据分析工具稀缺,无法做到“事前预防”。且大多数煤矿安全监测监控系统只能满足于对井下数据进行监测监控需求,并不能对其搜集的数据进行分析与推理。基于知识图谱的煤矿安全监测监控系统不仅可以清晰地展示数据的具体信息,给用户传达更加多维的知识,帮助用户决策。而且,能够对知识信息进行推理与分析,及时发现矿井中的隐含信息,有助于事故的提前预防和治理,对煤矿安全生产和安全管理有着重要意义。 根据以上需求,本文设计并开发了煤矿安全监测监控原型系统,实现对煤矿资源的合理利用及增加数据公开透明性。 该煤矿安全监测监控系统平台的知识图谱是基于煤矿领域本体构建的,具体系统架构如图14所示。 图14 煤矿安全监测监控系统架构图 (1) 数据层 数据层主要是为了给系统提供数据与规则,是系统运行的意义所在。本文数据主要来自煤矿领域本体、相关文献提取知识等。 (2) 技术层 技术层引入Jena推理机制、知识存储方法等,能够对数据进行读取、存储和查询等操作,进而实现知识推理与知识展示。 (3) 应用层 应用层主要为用户提供交互操作,能够使用户在自己权限允许的范围内进行操作。例如,普通用户可以对本体模型及规则进行上传、补充、修改、查看及推理,也可以在系统内对实体、实体关系进行添加、删除,以及关系的查询。 (4) 展示层 展示层主要的目的是通过网页的形式能够向用户直观地展示系统中所有功能模块,便于用户管理与使用。 煤矿安全监测监控系统能对煤矿井下设备、人员、环境状态等信息进行展示,用户能够很直接地了解煤矿井下安全状况。以环境状态为例,描述一个环境,需要知道环境名称、环境类型、环境指标及环境状态,而其中的环境状态必须在状态实体构建好的基础上才能创建成功。即对环境状态进行了约束,构成环境与状态之间的依赖关系,如图15、图16所示,只有创建了normal、abnormal状态实体,才能在创建CO2环境实体时选择对应环境状态,否则环境实体无法顺利建立。 图15 状态实体信息展示界面 图16 环境实体信息展示界面 该系统还可以对已有数据进行关系查询,在关系类型中选择对应关系,即可得到对应实体及实体间关系。例如,选择被包含的关系(INCLUDED_IN)后,查询结果如图17所示,对应图谱展示如图18所示,Apparatus State仪器状态包含on运行状态、off关闭状态和Disabled无法使用状态,而on运行状态又包含Abnormal异常状态,Abnormal异常状态包含Smoking烟雾、Heat热量、Damp潮湿、Spark火花等状态。 图17 INCLUDED_IN关系查询结果(部分) 图18 对应INCLUDED_IN关系查询图谱(部分) 本文在分析比较几种常见的本体构建方法后,提出一种基于七步法和METHONTOLOGY法的本体构建方法,并用该方法构建了煤矿领域本体模型。通过对本体与图数据库映射匹配机制的分析研究,将煤矿领域数据存储于Neo4j图数据库中,实现煤矿领域核心知识图谱的构建。并进一步设计开发了煤矿安全监测监控系统,实现了对矿井设备、人员等隐含信息的推理、部分图谱展示及关系查询功能,有助于煤矿事故防治与应急救援,为矿井安全生产与管理提供基本保障。2 本体与图数据库的映射匹配分析
3 煤矿领域知识存储的实现
3.1 图数据库Neo4j
3.2 基于Neo4j的知识存储
4 煤矿安全监测监控系统
4.1 系统设计
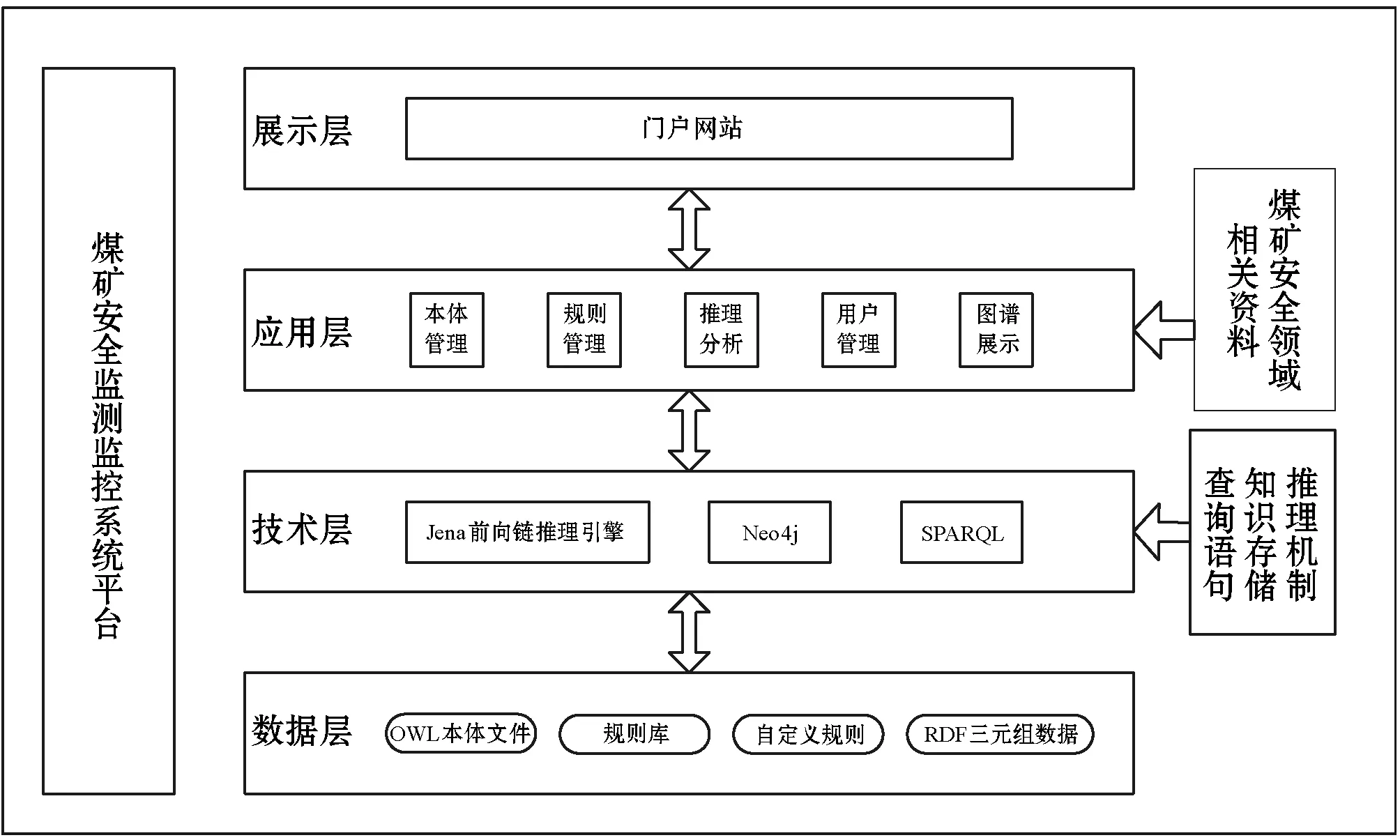
4.2 系统实现


5 结 语
