Collaborative Filtering Recommendation Algorithm Based on Multi-Relationship Social Network
2019-08-13ShengBinGengxinSunNingCaoJinmingQiuhiyonghengGuohuaYangHongyanhaoMengJiangandLinaXu
Sheng Bin,Gengxin SunNing Cao,Jinming Qiu,Ζhiyong Ζheng,Guohua Yang,Hongyan Ζhao,Meng Jiang and Lina Xu
Abstract: Recommendation system is one of the most common applications in the field of big data.The traditional collaborative filtering recommendation algorithm is directly based on user-item rating matrix.However,when there are huge amounts of user and commodities data,the efficiency of the algorithm will be significantly reduced.Aiming at the problem,a collaborative filtering recommendation algorithm based on multirelational social networks is proposed.The algorithm divides the multi-relational social networks based on the multi-subnet complex network model into communities by using information dissemination method,which divides the users with similar degree into a community.Then the user-item rating matrix is constructed by choosing the k-nearest neighbor set of users within the community,in this case,the collaborative filtering algorithm is used for recommendation.Thus,the execution efficiency of the algorithm is improved without reducing the accuracy of recommendation.
Keywords: Big data,recommendation algorithm,social network,recommendation efficiency.
1 Introduction
As an effective means to solve the problem of information overload [Liu (2016)],recommendation system is also one of the most common applications in the field of large data.According to the user’s history information,hobby and other characteristics,the recommendation system uses knowledge detection technology to filter users’ interesting information and products,so as to realize personalized recommendation.At present,the most commonly used recommendation system technology is recommendation algorithm based on collaborative filtering [Dong and Ke (2018)].The kind of algorithm calculates the similarity of users or commodities based on the user-item rating matrix,and then recommends the commodities that users may need.In addition,the real meaning of big data is not big but multiple sources [Zhang,Li and Tang (2017)].How to find out the inner relationship of multi-source data in the process of fusion through scientific analysis,and extract a unified,richer and more valuable information than a single data source,which is the real significance of using large data.Therefore,integrating the social relationship among users into the recommendation system can calculate the similarity of users more accurately.To a certain extent,it also solves the problems of sparse data and cold start [Margaris,Vassilakis and Georgiadis (2018)] in traditional recommendation algorithm based on collaborative filtering.Actually,there are many relationships among users of social networks,each of which has a different impact on recommendation.Therefore,simply introducing a certain social relationship will inevitably affect the accuracy of recommendation results.
In view of the above-mentioned facts,a collaborative filtering algorithm based on multi relational social networks is proposed in the article.Firstly,the multi-relational social network is constructed by the multi-subnet complex network model [Sun and Bin (2018)].Then,the algorithm divides the multi-relational social networks based on the multisubnet complex network model into communities by using information dissemination method,which divides the users with similar degree into a community.Next,the knearest neighbor set is composed of theKusers with the highest similarity with the recommended users in the community,which is used to construct the user-item rating matrix.Finally,the collaborative filtering algorithm is used for recommendation.Because of the sparse relationship between community organizations,the similarity between members of different community organizations is weak.Therefore,it is not necessary to analyze the user-item rating matrix constructed by the whole data set in the recommendation process,thus improving the execution efficiency of the algorithm without reducing the accuracy of recommendation.
2 Related works
Collaborative filtering technology is mainly divided into memory-based [Zhao (2013)]collaborative filtering and model-based [Jiang,Qian and Shen (2015)] collaborative filtering.Both of the two methods are based on user-item rating matrix.However,with the increase of the number of users and commodities,the user-item rating matrix will become larger and larger,resulting in the performance of collaborative filtering algorithm is decreasing.In order to improve the efficiency of recommendation algorithm,Roh et al.[Roh,Oh and Han (2003)] use hierarchical clustering algorithm to cluster users and commodities,then it is recommended based on the weighted summation of root nodes to leaf nodes.Zhang et al.[Zhang,Ding and Jiang (2005)] used fuzzy clustering method to classify users who like similar items and items that liked by the same user before recommending.Santhini et al.[Santhini,Balamurugan and Govindaraj (2015)] put forward the basic idea of collaborative filtering recommendation for big data by clustering method,which improves the efficiency of recommendation algorithm to a certain extent.However,clustering technology relies on the user-item rating matrix as the original data source to reflect personal preferences.It does not take into account the social relationships such as friendship and trust between users,nor does it consider the existence of implicit relationships between the scored commodities or items.Ignoring these important relationships will inevitably lead to the distortion of recommendation results.Accordingly,the introduction of social networks into the recommendation system to improve the rating matrix of the social recommendation system [Li,Li,Chen et al.(2018)] came into being.Chang et al.[Chang,Diaz and Hung (2015)] fused the trust relationship in social networks in the recommendation algorithm,and predicted the score by using trust between users as an alternative to the vacancy values in the user-item matrix.Pan et al.[Pan,Zhang and Wang (2016)] alleviated the problem of the sparse data and cold start by using the trust relationship in social network,which proved that social network can greatly improve the performance of recommendation system.As a typical complex network [Sun and Bin (2017)],social networks have the characteristics of community structure,which can divide the network members into groups with close relationship within the group and sparse relationship between groups [Jiang,Sun and Bin(2018)].Wang et al.[Wang,Li and Zhang (2016)] used weighted label dissemination algorithm to divide the citation cooperative network into communities,and then used recommendation algorithm to recommend academic papers in the same community.Zhang et al.[Zhang,Zhen and Zhang (2018)] mapped the user-item rating matrix to the user similarity network and combined with the community in the network to recommend the sorted Top-n commodities to users,which improved the accuracy and efficiency of the recommendation.Although the existing recommendation algorithms based on community partitioning in complex networks have made some progress in the accuracy and efficiency of recommendation,they are all based on single-relational social networks,in which only one relationship exists.In fact,social network is actually a multirelationship network,for example,there are user trust,similar interests and other relationships among users of social network.These explicit or implicit relationships determine the interaction characteristics between users together,which have different impact on the recommendation results.Therefore,the social network introduced into the recommendation system should be a multi-relational complex network with heterogeneous nodes,while the traditional complex network model cannot describe these complex relationships well,nor can it describe the interaction between heterogeneous nodes.Based on that,the article constructs a multi-relationship social network based on the multi-subnet complex network model which can describe the multi-relationship between different types of individuals,and divides the social structure of the network by information dissemination method.When predicting users’ rating,the similarity of users’rating is calculated according to the degree of users’ preference,and then the k-nearest neighbor set is selected for the recommended users in the community by combining the revised similarity of users’ rating and the similarity of user social interaction,thus greatly reducing the computational complexity of the recommendation algorithm.
3 Construction of multi-relationship social network based on multi-subnet complex network model
In the recommendation system,its elements can be divided into two sets:user andcommodity.Suppose there are users and commodities,the user set can be expressed as,and the commodity setcan be expressed as.Based on that,the user's rating matrixfor commodities is composed ofelements,which is represented by,whererepresents the userrating for the product,and the user-item rating matrix is shown in Fig.1.
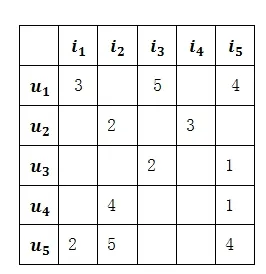
Figure1:User-item rating matrix
In reality,the recommendation process is usually accompanied by the integration of social information,such as the user's behavior of inquiring about friends’ shopping opinions,the sharing of shopping information between friends and so on.Actually,if there is a trust relationship between users,the similarity of their interest preferences will be significantly higher than that of strangers [Guo,Li and Zhao (2016)],that is,if one makes a high rating on a commodity,then another user is likely to show a high rating on the commodity.
The trust relationship in social networks can be represented by the trust-rating matrix,which is expressed as,whererepresents the userrating on user,it reflects the degree of trust between users.The trust-rating matrix is shown in Fig.2.

Figure2:Trust-rating Matrix
In order to effectively integrate the social feature,the user-item rating network and the user trust relationship network are combined into multi-relational social network based on the multi-subnet complex network model.
3.1 Construction of user-item rating network and user trust relationship network
The multi-subnet complex networkmodel is a quaternion satisfying the followingconditions:,where denotes the set of nodes in the network,is the number of nodes in the set;is the set of edges between nodes;and,denotes the set of interaction relations among nodes,is one of them,n is the total number of interaction relations,and if,the network is a multi-relationship network;denotes that the mapping of the edge setis projected by a functionto find a unique corresponding mapping in,which represents the type of relationship on edge.
Single-relationship complex network is a special case of multi-subnet complex network.By using multi-subnet complex network model,user-item rating network R_G and user trust relationship network T_G are constructedbasedon user-item rating matrix and trust-rating matrix respectively,and thresholdand are set.If the user rating ofcommodityis greater than or equal to the threshold ,it is considered that the commodity satisfies the user’s preference..Similarly,if the usertrust rating of another useris greater than or equal to the threshold,it is considered that there is a trust relationship between users.In the user-item rating network R_G,each nodesymbolizes a user or a commodity,andindicates the preference relationship between users and commodities.Similarly,in the user trust relationshipnetwork T_G,each node represents a user,andrepresents the trust relationship between users.
The network is constructed according to the user-item rating matrix and trust-ratingmatrix given in Fig.1 and Fig.2,where the thresholdand are both set to 2,then the network topology is constructed as shown in Fig.3 and Fig.4.
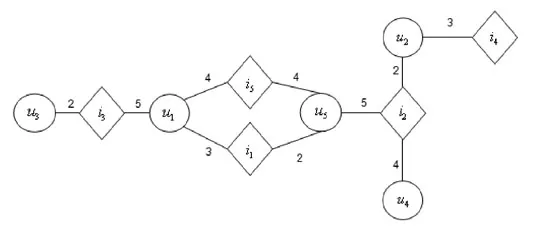
Figure3:User-item rating network

Figure4:User trust relationship network
3.2 Construction of multi-relationship complex networks
Multi-subnet complex network can compose two or more complex networks by subnet loading operation.In the process of loading,the network is mapped to vector space,and the relationship between nodes is mapped to multidimensional vector in vector space.Therefore,the process of subnet loading can be transformed into the base transformation of vector space,and the change of the relationship between the related nodes is accomplished by the correlation operation of the space vector.Due to the inheritance of the nature of each subnet,the dimension of the relationship vector space of the constructed multi-relational complex network increases correspondingly.
The user-item rating network and user trust relationship network are loaded into a multirelational complex network by subnet loading operation.The loading process of subnet is as follows:Suppose there are vector composite networksand,where,,and the set of relation is,is the base network.Loadingtounder load mappingand relation strength mapping,which generates a new composite network,where,is called the set of loading relations,represents the external edge,andrepresents the boundary node.
Compared with the traditional complex network,the topological properties of the composite network after loading have changed differently.Under the circumstances,the edges associated with the nodes contain all the relationships of the subnet.Therefore,the mixing weight and mixing degree of the nodes in the composite network are defined as follows:Mixing weight of node:if,the ratio coefficient of relationship strength expressed as,and the mixing weightof nodeis expressed as:


The user-item rating network R_G of Fig.3 and the user trust relationship network T_G of Fig.4 are loaded into a composite recommendation network,where the relationship strength parametersandof relation and are set to 1,the edge weight set of subnet R_G is,the edge weight set of subnet T_G is,and the composite network of sub-network is constructed as shown in Fig.5:
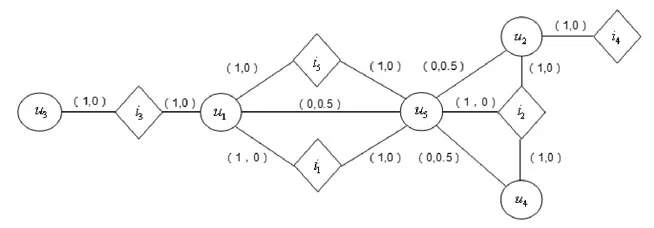
Figure5:Composited recommendation network
4 Community structure detection in multi-relationship social networks
4.1 The process of information propagation on complex networks
Initially,all nodes in the network do not carry information.At the beginning of the first propagation,a node is set as the source node and given its non-empty information quantity,and the set of neighbor nodes of the node is set as .At this time,the information in the network is distributed as,source nodes transmit information to nodes inby connecting edges.After receiving information,the neighbor nodes will continue to transmit information to their neighbor nodes of the set.However,the node as the receiver does not receive the information from the source node completely,but receives it with a certain probability.In the second propagation,represents the set of nodes carrying information,and the nodes in the setcan either transmit information to neighboring nodes or receive information from their neighboring nodes.Because the receiving node cannot receive all the foreign information,when the network scale is large,it only relies on a single dissemination,and some nodes far from the source node receive less information,which cannot adequately express the impact of the source node on these nodes.Accordingly,the distribution of information carried by all nodes in the network can represent the influence of source nodes on the information dissemination of thewhole network only after the process iterates fortimes.Thus,the similarity between nodes can be calculated according to the distribution vectors of information of the network when each node acts as the source node.


The elements in the adjacent mixing weight matrix are the weighted summation of the strength of the relationships between nodeand,wheredenotes the proportional coefficient of the strength of relationbetween nodeand,anddenotes the strength of relation.
On the basis of adjacency matrix,the mixing weight of nodecan also be expressed as:

In turn,the nodes of the network are selected as the source nodes and given 1 unitofinformation,and the information quantity of the remaining nodes is 0.Taking node as an example,assuming that nodeis the source node,its carrying information quantity is 1,and the vector of nodeis initialized to.The first process is that the node transmits information to its neighbors,which can be expressed asby mathematical formula,and the element in vectoris the information quantity carried by each node after the first dissemination;in the second process,the nodes have receiving information transmits the information to its neighboring node,and if the neighboring node has information,it can also receive the information from its neighboring node,thus the process can be expressed as,and the element in vectoris the information quantity carried by each node after the seconddissemination;Similarly,the information after each dissemination canbe expressed as;Before the nextinformation dissemination,assume that,whichmeans that the informationquantity of the source node is always 1 at the beginning ofprocess.In this way,the information distribution matrix which represent the influence of nodes can be obtained by using the information distribution vector of each node aftertimes dissemination.

Further,the vector of first dissemination is obtained as follows:
4.2 Community detection algorithm for multi-relationship social networks based on information propagation
After the nodes of network are represented by vectors,their data structure is suitable to be processed by clustering algorithm,and the similarity between nodes is calculated according to the information dissemination,thus the mature data mining clustering algorithm is applied to the community detection for multi-relational social networks.
In previous studies,CSDM algorithm [15] was proposed based on classical K-means clustering algorithm to discover the community structure of multi-relational social networks.The biggest disadvantage of K-means algorithm is that it is sensitive to the selection of initial clustering centers,since the initial value of the cluster center will directly affect the final clustering result.
Generally,the importance of nodes in complex networks is called centrality,which is the basic index of describing the importance of nodes.Degree centrality considers that the influence of nodes is related to the number of neighbor nodes,which means that the more neighbor nodes,the greater the influence of the node in thenetwork.Assuming that the path length of nodeandwith respect to relationis ,and the centrality of nodewith respect to relationis defined as:

Where the m?olecular part represents the minimum sum of the path lengths of therelationship with the remaining nodes,and the denominator part represents the sum of the path lengths of the nodeand other nodes with respect to the relationship.Specifically,the closer the value of centralityis to 1,the smaller the sum of the path length of the node and the remaining nodes is,the stronger the centrality will be;conversely,the closer the value of centrality is to 0,the weaker the centrality will be.
Further,the CSDM algorithm chooses the nodes with larger centrality as the initial clustering centers,and then divides the multi-relational social networks into communities according to classicalK-means clustering algorithm.
5 Collaborative filtering recommendation algorithm based on community structure detection
Through information dissemination,it solves the problem that the social network composed of users of recommendation system is difficult to calculate similarity due to multi-relationship,and the information quantity carried by each member after dissemination reflects the similarity degree of different nodes in the network.By dividing these users with high similarity into a community,members of the community will share information such as rating preferences and interest preferences.On the one hand,the social preference vector can be obtained from the trust relationship of users contained in the community structure,which represents the user's social preference and can be measured by social similarity;on the other hand,users' interest preferences can be obtained from the rating information contained in the community structure,and the similarity of interest preferences can be determined by extracting interest preference vectors.Finally,the social similarity and interest preference similarity are synthesized in a certain proportion,and a new comprehensive similarity index,recommendation degree,is obtained,which is used to rank and recommend commodities.
5.1 User social similarity and rating similarity
Assuming that there is a social relationship between userand user,and the interest betweenandis closer,thus their preference similarity is higher than that of strangers [Wang and Ma (2016)].The kind of social relationship with promoting recommendation effect can be expressed as trust relationship between users.In this way,users in the same community are mapped to a new user trust network,and they are mapped to vectors by information dissemination method,then Pearson similarity is used to measure the social similarity between usersand,the formula is as follows:

In fact,users’ common rating items and rating preference also reflect users’ interests to a certain extent.In addition to Pearson correlation to measure the user’s rating preference,the user preference degree [11] is defined,and the more consistent the rating preference is,the closer the user's interest preference is,the formula is as follows:

where the threshold value ofis consistent with the threshold value when constructing user-item rating network.In Section 3.1,the user’s rating below the thresholdindicates that the user does not have a preference relationship for the commodity.While,in this case,it is used to indicate that the user’s rating is positive or negative.If the rating isgreater than the threshold ,it meansthat the rating is positive;and represent theset of commodities scored by user and respectively.When user preference is integrated into the process of calculating the rating similarity,the user’s rating of commodities in the community constitutes a new rating vector,is the Pearson correlation between the rating vector ofand the rating vector of.Thus,user rating similarity based on rating preference is obtained:

In order to improve the reliability of user similarity,the following formulas are used to integrate user social similarity and user rating similarity:
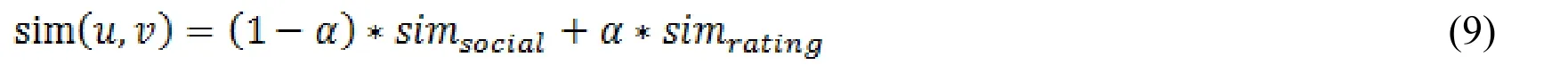
5.2 Prediction of rating
The recommendation system mainly relies on the prediction of the items that are not scored by the recommended users,and finally the top-n with the highest rating will be recommended.It is not necessary to use all users in the community when predicting.Usually,sets of nearest neighbors with the highest similarity of current users are selected.In the process of selecting the nearest neighbor users,if the value ofis too large,additional noise will be broughtto the prediction when the neighbors with lowsimilarity are added;if the value of is too small,it will lead to deviation due to insufficient nearest neighbors used to predict.The prediction rating of userabout commodity is calculated by the following formula:

6 Experiment and result analysis
In the process of experiment,the effectiveness and recommendation quality of the proposed algorithm are proved by comparing with different classical recommendation algorithms,and the influence of parameter setting on the recommendation results is analyzed as well.
6.1 Experimental environment and dataset
In order to analyze big dataset,a Hadoop cluster platform composed of 5 nodes is built,and the specific configuration of each node machine is Intel (R) Core (TM) i7-7700 CPU@3.60 GHz,8 GB memory,64-bit operating system.
Epinions dataset [Lauw,Lim and Wang (2012)] commonly used in recommendation system is used in the experiment.The dataset contains users’ rating information and social information.There are 40163 users and 139738 commodities in the dataset,and the rating records reach 664824 items.The user's rating of commodities is expressed by 1 to 5.If there is trust relationship between users,it is expressed by 1;if there is no trust relationship,it is marked as 0;and other statistical information in the dataset is shown in Tab.1:In order to use the algorithm proposed for rating prediction,it is necessary to determine the relationship coefficients and strength between rating relationship and trust relationship.For this reason,users with number 2 and number 10004 are chosen as seed nodes.After eliminating some obvious outliers,150 sample data were selected as the sample set of linear regression analysis data for calculating the proportional coefficients of the tworelationships.The linear regression model was constructed for ratingrelationship and trust relationship in multi-relational social networks as follows:
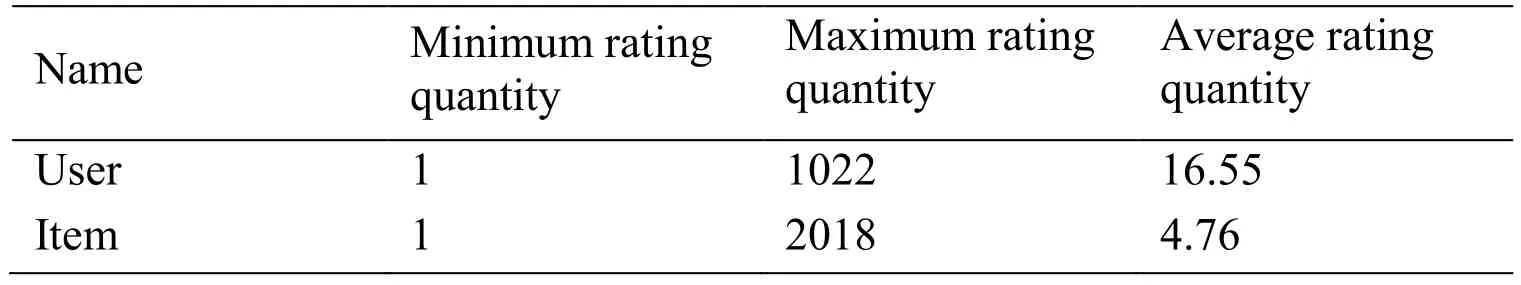
Table1:The statistics of Epinions dataset

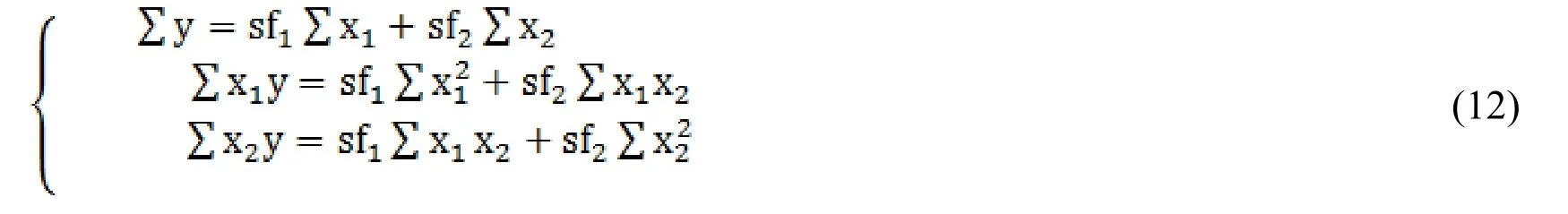
The average value of the parameter estimation is obtained as follows:.
Therefore,when dividing the community of the multi-relationship social network constructed in the experiment,assumed that the ratio coefficient of the two relationships is,the strength of the relationship is 1,the parameter of the K-means clustering algorithm is,and the community partition is shown in Fig.6.

Figure6:Result of community detection
6.2 Analysis and comparison of experimental results
Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) are selected as evaluation indicators to evaluate the accuracy of recommendation results,which evaluate the accuracy of recommendation algorithm by comparing the errors between the real rating and the predicted rating.The smaller the value,the better the recommended effect is.The specific definitions are as follows:
Mean Absolute Error (MAE):

Root Mean Squared Error (RMSE):

The selection of the nearest neighbor numberswill affect the experimental results,and too small or too large of the ?nearest neighbor set will increase the uncertainty ofprediction.In the experiment,of the proposed algorithm are set to be 10 and 30,respectively.As shown in Tab.2,it is clear that MAE and RMSE ofat 30 are significantly lower than 10.Accordingly,the nearest neighbor numbersis set in the following comparison experiments of kinds of recommendation algorithms.In the experiment,the proposed algorithm (CDRec) is compared with three commonly used social recommendation algorithms TDSRec [Guo,Wang and Hou (2018)],Social MF [Forsati,Mahdavi and Shamsfard (2014)] and TDRec [Park,Kim and Oh (2016)],and the results are shown in Fig.7.

Table2:Influence of different neighbor numbers on algorithm
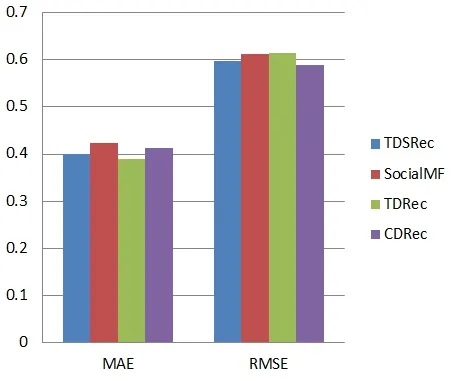
Figure7:The results comparison of four recommendation algorithms
From Fig.7,it is can be seen that the proposed algorithm is similar to other social recommendation algorithms on MAE and slightly better than other algorithms on RMSE,which means that the proposed algorithm can predict ratings of the recommended items more accurately.
In view of the datasets vary in scale,the execution comparison of four social recommendation algorithms is shown in Fig.8.

Figure8:The execution comparison of four recommendation algorithms
As can be seen from Fig.8,with increase of the scale of dataset,the execution of the proposed algorithm is significantly less than that of the other three social recommendation algorithms.
In conclusion,the proposed algorithm can improve the recommendation efficiency on the basis of guaranteeing the accuracy of recommendation when dealing with big sample datasets.
7 Conclusion
For recommendation system in big data,the efficiency of recommendation al-gorithm is very important.In this paper,a collaborative filtering algorithm based on multi-subnet complex network model is proposed to construct multi-relationship complex network.By using community structure detection,similar users can be partitioned into a community,which greatly reduces the computa-tional complexity of recommendation algorithm.Experiments on real data sets show that the proposed algorithm can improve the efficiency of recommendation algorithm on the basis of guaranteeing the accuracy of recommendation.
Acknowledgement:This work is supported by the Humanity and Social Science Youth foundation of Ministry of Education of China under Grant No.15YJC860001.This research is also supported by Shandong Provincial Natural Science Foundation,China under Grant No.ZR2017MG011 and Shandong Social Science Research Project under Grant Nos.17CHLJ16 and 18BJYJ04.This work is also supported by the Grant of Fujian Middle-aged and Young Teachers’ Educational and Scientific Research Projects in 2018,Grant No.JZ180469.
杂志排行

Computers Materials&Continua的其它文章
- Design and Performance Comparison of Rotated Y-Shaped Antenna Using Different Metamaterial Surfaces for 5G Mobile Devices
- A Comparative Study of Machine Learning Methods for Genre Identification of Classical Arabic Text
- Improved Enhanced Dbtma with Contention-Aware Admission Control to Improve the Network Performance in Manets
- Analysis of Bus Ride Comfort Using Smartphone Sensor Data
- Heterogeneous Memristive Models Design and Its Application in Information Security
- Drug Side-Effect Prediction Using Heterogeneous Features and Bipartite Local Models