基于热词语义聚类的领域特征挖掘方法
2019-08-13庄建昌顾兴全洪彩凤
庄建昌,武 娇,顾兴全,洪彩凤
(1.中国计量大学 理学院,浙江 杭州 310018;2.中国计量大学 标准化学院,浙江 杭州 310018)
一个充分发展的领域必然充斥着大量的文本数据,对于关注领域现状和未来发展的人们,需要对领域内海量文本数据进行分析。然而,领域内的信息往往具有冗余性,并且具有各个子领域分布不平衡的特点。因此,复杂领域内的关键词提取并不容易[1]。
领域关键词的研究大致可分为领域关键词提取技术以及领域关键词的应用。领域关键词的应用研究广泛,存在于领域主题提取[2-3]、医学肿瘤领域[4-5]、纳米技术领域[6]、情报学领域[7]以及交叉学科领域[8-9]。这反映出研究领域关键词提取技术的重要意义。高继平等人[10]提出使用多词共现技术提取领域关键词,并用关键词的共现技术刻画领域的研究热点。潘玮等人[11]提出一种数据清洗方法,结合词共现技术提取领域关键词。词共现技术提取领域关键词能够反映出关键词的耦合性,但是其多以词频为特征,在多文本中提取关键词的效果并不好。Luo[12]等人提出了一种基于词频逆文档频率的多文本域关键字提取方法TDDF,该方法比以词频逆文档频率作为特征项的关键词提取方法更有效。
然而,上述方法还存在以下问题:1)提取的关键词不含有语义信息,这不利于进一步分析领域特征。为此,文献[13]和文献[14]提出了基于word2vec模型[15]的领域关键词提取方法。由于word2vec模型能够表征语义信息,因此这些方法提取的领域关键词的可解释性得到了提高。2)没有考虑领域语料分布的不平衡造成的影响。语料分布不平衡可能导致关键词分布不平衡,进而影响关键词对领域的代表性。3)这些方法大多用于对标注有“关键词”的学术类文本语料的领域关键词提取,而通常文本是不标注“关键词”的,这影响了方法的推广应用。由此,文献[16]提出了一种基于Wikipedia的提取领域关键词的方法进行文本过滤,虽然该方法不依赖于带有“关键词”标签的文本,但仍依赖于外部的文本资源。综上所述,研究能够在未标注“关键词”的文本中提取具有语义信息的领域关键词,并能克服语料分布不平衡带来的负面影响的领域关键词提取方法具有重要的应用价值。
为了解决上述问题,本文提出一种基于局部热词模型(Local buzzword model, LBM)的领域特征挖掘方法。该方法由多种机器学习技术集成。首先,本文提出二次关键词提取策略(Two-step keyword extraction strategy, TKES)提取领域关键词。其次,结合word2vec模型获得领域的热词;最后,基于热词的语义进行聚类得到LBM。利用LBM,能够挖掘领域特征并且实现领域特征可视化。在实验部分,本文将该方法应用于旅游评论语料的特征挖掘和可视化,以验证方法的有效性。
1 LBM构建
1.1 LBM构建流程
LBM构建流程如图1。从图1可得,LBM的构建比较复杂,我们将之分为4个步骤进行说明:1)获取领域语料库;2)训练word2vec模型;3)基于TKES和word2vec模型提取领域的热词;4)热词聚类获得LBM。

图1 LBM构建流程Figure 1 Constructing process of LBM
1.1.1 获取领域语料库
领域语料库是指在某一领域内,包含着众多子领域的语料库,而各个子领域包含着数量不均的语料。针对不同的研究对象,人们需要从不同的途径去获取相应的领域语料。领域语料的结构如图2所示。其中Θ={A,B,C}表示某个研究领域,A、B、C分别代表Θ的三个子领域,Ai、Bi、Ci(i=1,2,…)为各子领域的语料。设|A|为领域A的语料个数,则图2中,|A|>|B|且|C|>|B|,这表明领域语料分布是不均衡的。

图2 领域语料结构Figure 2 Corpus structure of the research field
1.1.2 训练word2vec模型
Word2vec模型,是一种基于Bayes假设,通过w相邻词的集合C(w)的信息预测w的信息,或者通过w的信息预测w相邻词的集合C(w)的信息的模型。其通过某种训练将语料中的每一个词映射成一个固定长度的向量,所有的词向量组成一个向量空间,这样就可以把词向量对应成空间中的一个点。
一般的,根据不同的目的,word2vec优化目标为(1)或(2):
(1)
(2)
其中,C(w)={vi(w)∈Rm|i=-c,-c-1,…,-1,1,2,…,c},vi(w)是离w距离为i的词的初始向量,且i为正数是w右侧第i个词;反之,i为负数是w左侧第i个词,D是语料字典,由领域语料Θ通过预处理得到,m是用于训练的词向量vi的维度。
求解(1)、(2)的两种常用的网络结构分别为CBOW模型和Skip-gram模型,更具体的求解可参考文献[15]。本文中使用gensim[17]包所提供的方法训练word2vec模型。
1.1.3 提取领域热词
关键词提取方法有许多种,大多是对特征进行基于规则的排序,本文将词频-逆文档词频[18](Term frequency inverse document frequency,TFIDF)作为权值,通过对权值的排序提取关键词。其数学表示如公式(3):
δ(wij)=δTFIDF(wij)=TF(wij)×IDF(wij),
(3)
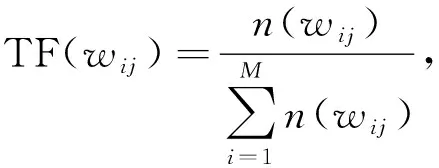
其中wij表示第i个文档的第j个词,δ(wij)是wij的权重函数,δTFIDF(wij)表示使用TFIDF计算wij的权重,TF(wij)表示wij的词频,n(wij)表示wij的频数,IDF(wij)表示wij的逆文档数;di表示第i篇文档,M表示Θ中的文档个数。
需要注意的是,无论选择哪一种关键词提取方法,都不能直接作用在语料上。上文已经提到,领域语料分布是不平衡的,如果对领域语料直接提取关键词,会导致在较大的子领中获取的关键词的权值较大,而较小的子领域中获取的关键词的权值较小,而最终导致较大的子领域中提取的关键词占比大,如图3。
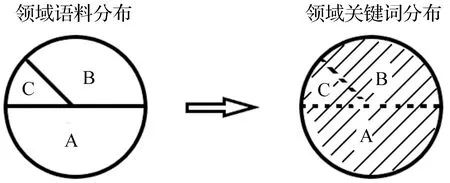
图3 直接提取关键词Figure 3 Direct extraction of keywords
这种大的子领域关键词“吃掉”小的子领域的关键词的问题如何解决呢?本文提出二次关键词提取策略(Two-step keyword extraction strategy,TKES)来解决此问题,其提取步骤如图4所示。图4中A,B,C,表示原始领域Θ的三个子领域,其各个子领域元素大小的排名是|A|>|B|>|C|,如图4(a)。
TKES经过以下三个步骤实现对领域关键词的提取。
1)如图4(b)所示,使用(3)式计算子领域H(H∈Θ)中的词的权重并进行排序,
δ(wH1)≥δ(wH2)≥…≥δ(wH|H|)。
(4)
得到按(4)式,排序的词集KH,
KH={wHj|j=1,2,…,|H|}。
(5)
其中wHj表示子领域H中的第j个词。
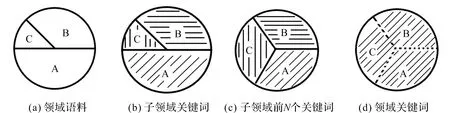
图4 二次关键词提取策略Figure 4 Two-step keyword extraction strategy
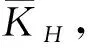
(6)
其中wHj表示子领域H的第j个关键词,N满足N≤minH∈Θ|H|。
(7)
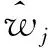
(8)
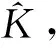
G={aj={n(wj),v(wj)}|j=1,2,…,T}。
(9)
其中n(wj)表示热词aj的频数,v(wj)是aj对应的词向量。
一般情况下,在模型G中热词数量T较大,人们难以直接对领域的特征进行分析。因此,下面对热词向量进行聚类,进一步构造能够刻画领域局部特征的局部热词模型。
1.1.4 热词聚类获得LBM
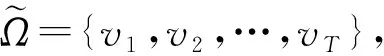
通过上面的方法对热词向量进行聚类,就得到LBM,其数学模型如下:
GL={aij={n(wij),v(wij)}|i=1,2,…,l;
j=1,2,…,|Li|}。
(10)
其中,aij是第i个簇的第j个热词,n(wij)表示aij的频数,v(aij)是aij对应的词向量。
通过上述方法构建的LBM,模型中的每一个簇的热词在体现领域的整体特征的同时,具有表征领域局部特征的能力。
1.2 LBM的应用
在获得局部热词模型之后,我们可以将其应用于领域特征的进一步分析与挖掘。本文主要考虑以下两种应用:
1.2.1 基于热词频率划分的领域特征挖掘
通过GL中aij的频数n(wij),可以计算aij在每个簇Li中的热词频率pi(wij)。
(11)
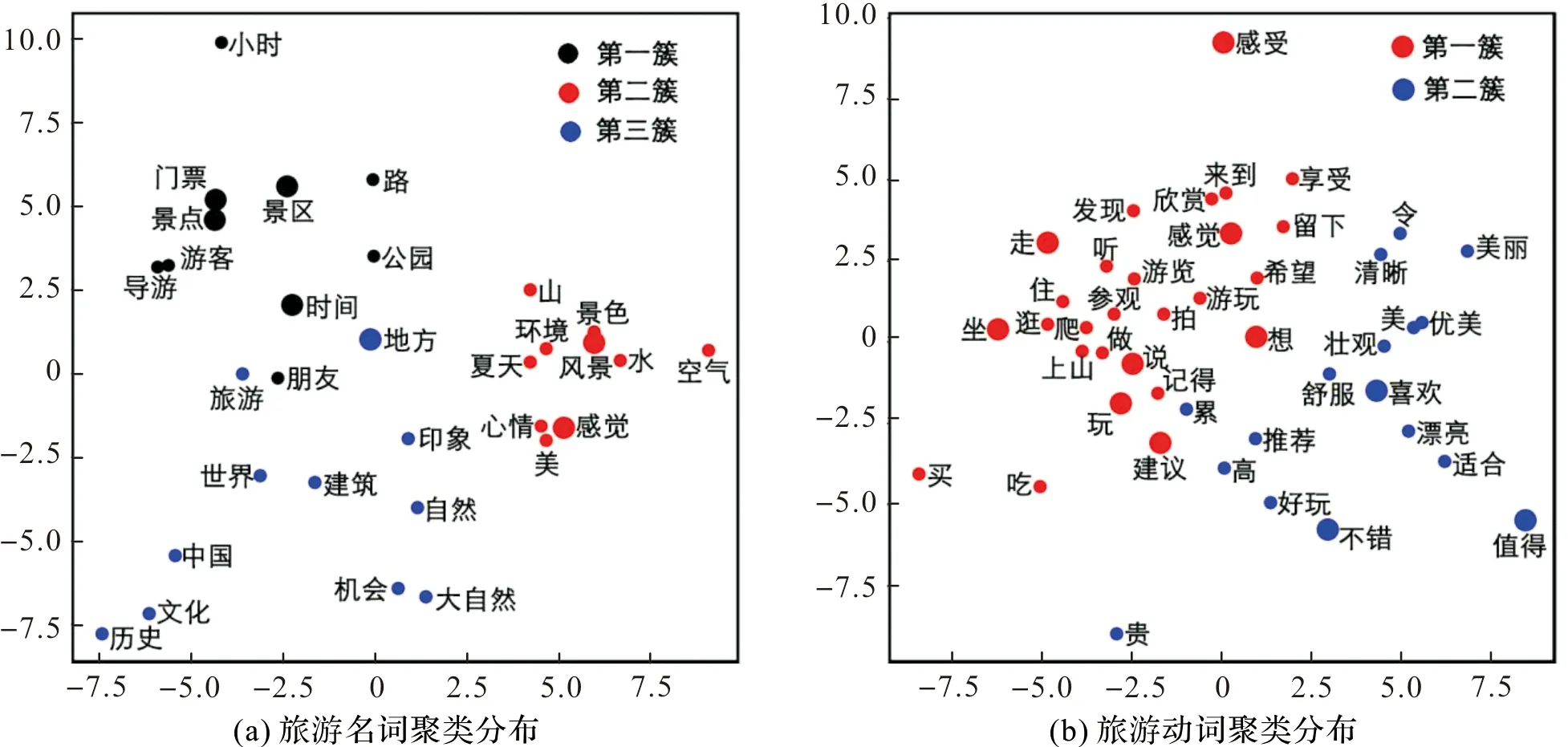
pi(wij)越大,表示aij出现在簇Li的频数越大。于是可以规定满足t1≤pi(wij)≤1的词aij为Li的高频词,满足t2≤pi(wij) 高频词与中频词更能够反映Li的整体特征,而低频词可能反映了Li较新的或部分的特征[19]。因此通过对热词频率的划分,可以更加清楚地了解每个簇中热词的分布,进而推断热词在领域中的作用。 1.2.2 领域特征可视化 使用主成分分析(Principal component analysis,PCA)[20]对GL中的词向量进行降维,以实现领域特征可视化。 对GL所有元素的词向量vij(i=1,2,…,l;j=1,2,…,|Li|)计算均值和协方差矩阵。 (12) (13) (14) 其中,zij∈Rn是降维后的向量。 取n=2,由公式(14),可以将原m维的词向量降至2维,绘制热词在二维空间中的分布图,实现领域特征可视化,从而更加清楚地表现领域内各个特征之间的联系。 本文使用了旅游评论数据作为领域语料进行LBM的实验。旅游语料是基于爬虫技术从“猫途鹰”旅游网站爬取,语料数据统计量见表1。从表1中可以发现,最大评论数的景区与最小评论数的景区评论数量差距很大,而语料的标准差达到了859.74,这说明语料中各景区评论数量的分布非常不均衡。 表1 景区数据统计 实验运行在CPU型号为Intel(R)Core(TM)i7-7500U,内存为8 GB,操作系统为Windows 10企业版的笔记本电脑上。 实验涉及的所有程序代码均采用Python 3.6.5进行实现,并在Spyder 3下进行编译与运行。程序中主要使用的软件包以及相应的版本如下:机器学习包scikit-learn[21](0.19.1),数值运算包numpy(1.14.3),数据处理包pandas(0.23.0),斯坦福自然语言处理工具包stanfordcorenlp(3.9.1.1)。 本文根据图1所示的流程构建旅游语料的局部热词模型,其中所用的停用词(该停用词表已经上传到了网上,网址:https://pan.baidu.com/s/1l61_rAh1XLxB4WfnKdyK2g。)是由多个停用词词集结合而得。 得到热词之后,为了解领域的局部特征,接下来对热词进行聚类,构造局部热词模型。 本文使用几种基于不同距离测度的聚类算法进行实验,包括Kmeans算法[22](欧式距离)、超球Kmeans算法[23](余弦距离)、Agglomerative算法[24](各种链接模式和距离测度),通过比较聚类Calinski-Harabaz Index(CHI)[25]得分,最终确定使用K-means算法对名词词向量进行簇为3的聚类,对动词词向量进行簇为2的聚类。聚类结果见表5和表6。 2.4.1 热词词频分布 本文取t1=70%,t2=30%,对于每个簇i,i=1,2,…,l,满足pi(wij)≥70%的热词aij为该簇的高频词,满足70%>pi(wij)≥30%的热词aij为该簇的中频词,满足pi(wij)<30%的热词aij为该簇的低频词。由于本文的目标是挖掘领域特征,因此本文主要考虑中频词和高频词,同时为了保证热词在整个领域中具有代表性,本文还要求aij满足n(wij)≥0.3×max{n(wij)|aij∈GL}。所提取的旅游热词的词频分布见表4。 表2 旅游领域名词 注:由于数据过多,表格只展示部分结果。 表3 旅游领域动词 注:由于数据过多,表格只展示部分结果。 表4 热词分布 2.4.2 热词聚类结果分析 对于热词的聚类结果,我们选择部分高频词和中频词进行分析,见表5和表6。 2.4.3 领域特征可视化 本文构建LBM模型后,对GL中高频词和中频词的词向量vij使用PCA降维到2维,并在二维空间中绘制vij的分布图,见图5。 表5 旅游领域名词-热词聚类分析 续表5 注:表5和表6中,括号内的数表示该词出现在子领域中的次数,其中加粗的词表示该簇的高频热词。 图中不同颜色的圆点表示不同的簇,小圆点表示中频词,大圆点表示高频词。通过图5可以得到: 1)图5(a)中名词的三个簇被明显的区分开。从整体上看,第一簇位于图的左上角(黑色圆点),主要是描述游览要素的名词;第二簇位于图右侧(红色圆点),主要是描述景区景色的名词;第三簇位于左下角(蓝色圆点),主要是描述自然和人文景观的名词。说明游客的关注点主要集中在这三个方面。由此,旅游管理者不仅可以通过游客评论对旅游景区总体服务水平进行评价,而且可对旅游景区的游览要素,景区景色,旅游景观属性三个方面的服务水平进行评价。这将为提高管理者监测和改进旅游景区服务水平的针对性提供了一种有效途径。 图5 旅游热词聚类分布Figure 5 Cluster distribution of buzzwords 2)图5(b)中第一簇热词(红色圆点)描述的主要是游客行为,而第二簇热词(蓝色圆点)描述的主要是游客体验。景区服务人员借助于此可有重点地改善景区服务过程质量,提高游客对景区的满意度。 3)如果图中的两个圆点距离相近,那么它们对应的语义相近。例如,图5(a)的“景色”和“风景”,图5(b)中的“优美”和“美”。这说明LBM继承了词向量模型能够刻画词的语义信息的能力。 4)通过周边词的分布缩小关注范围。通过图5(a),可以看到“门票”一词周边紧密分布着“景点”“景区”,再远一点是“游客”“导游”“路”“小时”“时间”这说明“门票”与这些因素有较强的关联性。通过图5(b),发现“喜欢”周围分布着“舒服”“漂亮”“壮观”“美”“优美”。这反映出景区可以通过建设更加舒适的基础设施和更加优美的景区环境来提高游客对景区的喜欢程度。 本文提出二次关键词提取策略(TKES)来提取热词。TKES可降低由领域语料分布不平衡带来的负面影响,只要保证最小子领域语料的数量足够大,就能使提取出来的热词对整个领域具有代表性。 局部热词模型LBM是依据TKES结合word2vec模型和文本聚类技术得到。将其应用于:1)基于热词频率划分的领域挖掘特征,2)领域特征可视化。通过对旅游评论语料挖掘的应用,验证了LBM在1),2)两种场景下的有效性,以及使用TKES所提取的热词在体现领域共性特征的同时,具有表征领域局部特征的能力。 提出的LBM也可作为其它文本挖掘工作的基础,比如自动文本摘要、文本分类。LBM与其它文本挖掘技术相结合,处理更加复杂的文本挖掘任务,是进一步的研究工作。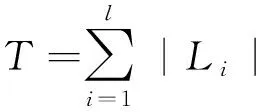

2 基于LBM的旅游评论挖掘
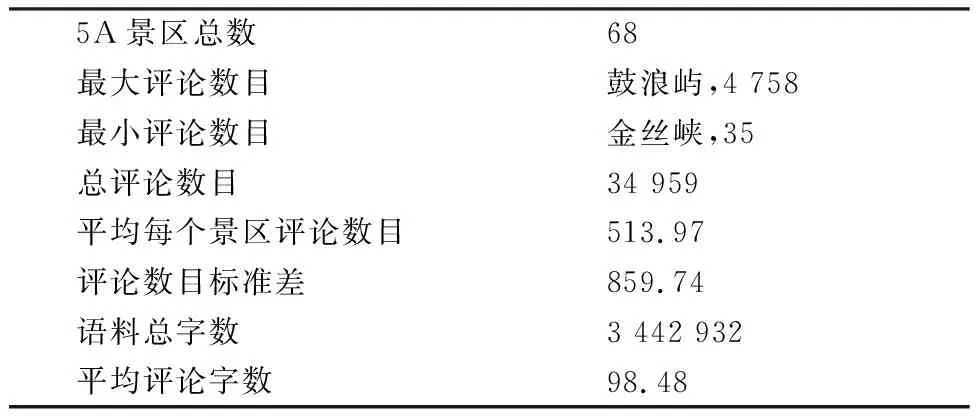
2.1 语料概况
2.2 实验环境及工具
2.3 热词提取和聚类
2.4 领域特征挖掘





3 结 论
