基于降噪自动编码器的僵尸网络检测模型
2019-08-13徐文龙
肖 琦,徐文龙
(中国计量大学 信息工程学院,浙江 杭州 310018)
随着互联网服务的普及和活跃使得用户数量的不断增加,以致互联网安全越来越受到重视。在诸多问题中,僵尸网络已经成为其中最严重的威胁之一[1]。僵尸网络是由一组被恶意软件攻击的主机组成,在远程主机的控制下执行不同类型的攻击活动,例如:发起分布式拒绝服务(DDoS)攻击,窃取敏感信息,发送垃圾邮件等等[2]。僵尸网络一般由三个组件构成,分别是受控主机、远程主机和命令与控制(C&C)服务器。受控主机指被恶意软件感染过的主机;远程主机则是由拥有僵尸网络并控制僵尸网络的恶意操控者组成;命令与控制服务器用于建立操控者和受控主机之间的联系,以便控制者顺利开展相关恶意活动。
僵尸网络的非法活动对很多组织或企业造成了重大损害和财务损失。在最近的一项调查中,1 000家被调查企业中有300家遭受了DDoS攻击,65%的攻击每小时造成高达1万美元的损失。根据全球数据统计,中国成为遭受DDoS攻击的重灾区,每年承受DDoS攻击数量占全球总量的百分之八十多[3]。由于这些损失,使僵尸网络检测受到了相当多的关注。因此,有效地检测出僵尸网络成为亟待解决的问题。
近年来,僵尸网络检测是的一个主要研究课题,学术界已经提出了不同的解决方案。大致可以分为五种:基于特征码的检测方法[4],基于异常的检测方法[5-7],基于域名系统的检测方法[8-10]和基于机器学习的检测方法[11-12]。最近出现的基于机器学习的检测方法,对比于其他方法,它们表现出了不错的效果。
WANG[13]等人提出了一种分析DNS查询的僵尸网络检测框架,分析了DNS流量中的NXDOMAIN查询,并且DNS查询通常在时间和数量上相关。因此可以使用聚类算法找到异常且高度相关的NXDOMAIN查询,这种方式不需要历史数据,但是依赖于组活动。
WU[14]等人通过僵尸流量和正常流量之间的相似性分析,并使用多种聚类算法进行测试和实验,可以准确地检测出是哪种僵尸网络感染。但是该方法误报率很高。
MCKAY[15]等人使用三种机器学习算法检测僵尸网络,实验用到了多个数据集。其中,扩展的ID3决策树分类器获得了最高准确率。
目前,研究人员大部分使用的是传统的机器学习检测方式,准确率不是很高,其次,这些检测模型在训练过程中使用的特征往往都是手工提取的,为了获得更好表达网络流量数据中的高级特征,需要工作人员具备大量的专业知识,以及消耗相当多的时间成本。对于这种手工特征工程既不容易获取真实反映样本的特征,也不够灵活,难以适应新兴且复杂的网络攻击。
随着计算机硬件的发展,计算机能够给我们提供更为强大的计算能力,其中深度学习技术取得了令人难以置信的成果[16-17],它最有价值的一部分是能够从大量未标注的数据中进行特征提取,降噪自动编码器(Denoising auto-encoder, DAE)就是其中一员。降噪自动编码器只需要给出目标函数和输入数据,就可以学习到原数据的简化维度表示,用于相关监督学习方法的输入。在大多数常见的自然语言处理和计算机视觉任务中,这些学习到的表示已经被证明明显优于基于传统手工提取特征的模型[18]。因此,将相关深度学习技术用于僵尸网络检测模型的构建,对于改善僵尸网络检测模型效果具有重大意义。
本文研究了如何利用深度学习技术来获得支持僵尸网络检测的网络数据的抽象表示,提出了基于降噪自动编码器的僵尸网络检测方法。该方法利用降噪自动编码器自监督地学习到离散特征的连续抽象表示,能够更好地表达网络流量数据中存在的高级特征。我们提出的方法一方面能够减轻人工特征工程带来的负担,另一方面可以有效改善僵尸网络检测的效果。
1 相关方法
本章首先介绍基于降噪自动编码器的僵尸网络模型的整体设计。然后详细描述降噪自动编码器技术细节以及在模型中所扮演的角色。最后,介绍数据集的构建及特征选取。
1.1 模型设计
僵尸网络检测模型结构如图1。原始的网络流量数据保存在PCAP文件中,在输入模型之前需要经过数据处理。数据处理模块负责将原始数据按照选取的特征转换成数值型特征向量。在特征提取模块,使用降噪自动编码器提取原始数据中的抽象特征。最终,将提取到的特征输入基学习器进行分类。这里选取的基学习器分别为:逻辑回归,决策树,朴素贝叶斯,K近邻,AdaBoost和随机森林。
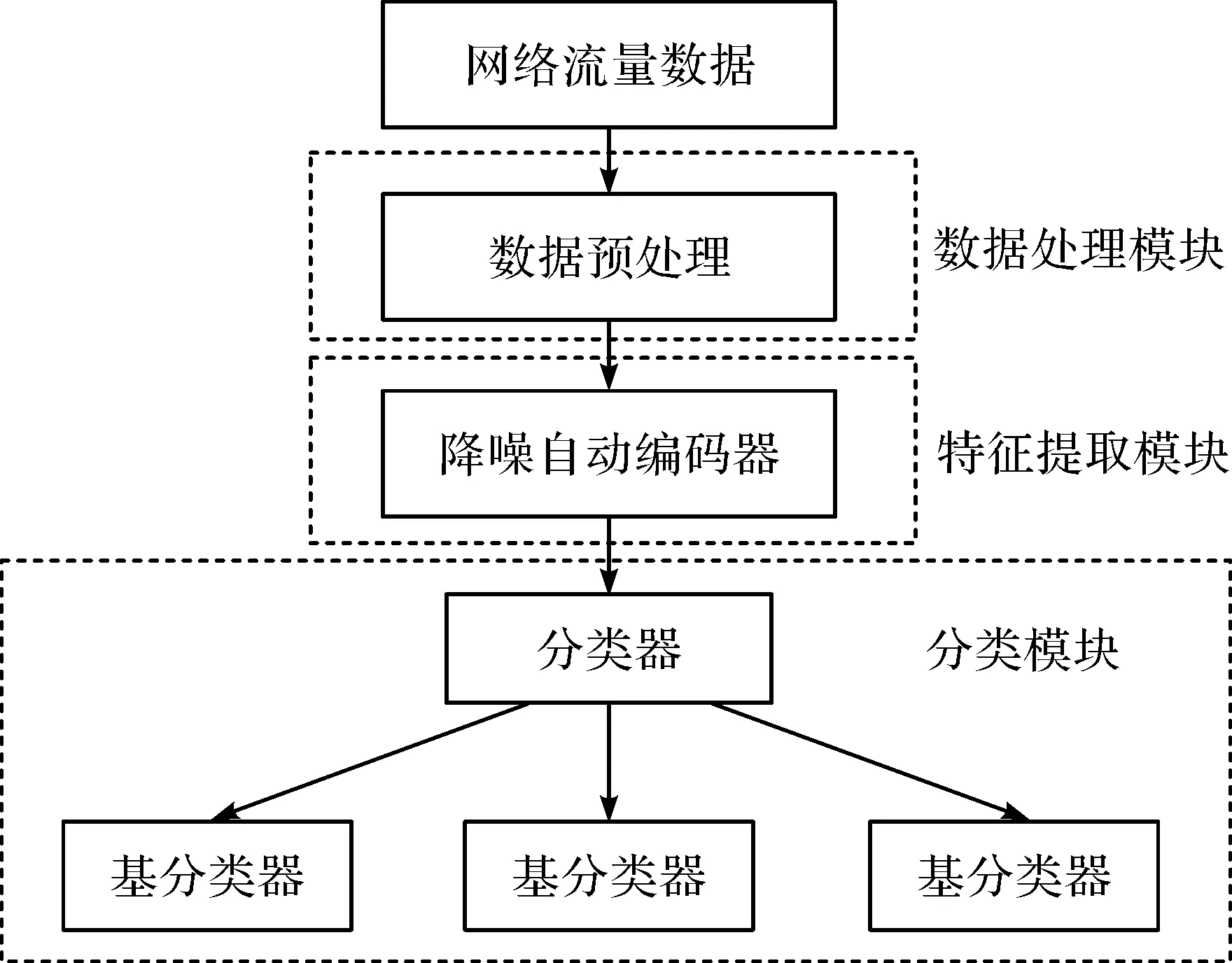
图1 基于降噪自动编码器僵尸网络检测模型结构Figure 1 Botnet detection model structure based on denoising auto-encoder
1.2 降噪自动编码器
自动编码器是一种无监督学习的神经网络,分别由编码器和解码器组成,一般用作高维度数据的降维和特征提取。降噪自动编码器是自动编码器的一类扩展[19-20]。与自动编码器不同的是,降噪自动编码器在输入数据中引入噪声,通过其中的编码器将融合噪声的数据进行编码,最后通过解码器将编码后的特征向量还原至原始输入数据的样式,以消除噪声对输入数据的影响。通过这种方式,降噪自动编码器较原始的自动编码器具有更好的鲁棒性,能够更好地提取未知数据中所蕴藏的抽象特征。这就是我们选取降噪自动编码器用作僵尸网络检测的重要原因之一。图2是包含两层隐藏层的降噪自动编码器结构图。

图2 降噪自动编码器结构图Figure 2 Denoising auto-encoder Structure diagram
假设有包含m个样本的训练集合D={x(1),x(2),…,x(m)},其中每个样本x(i)∈Rn均是n维向量。降噪自动编码器向原始输入数据中加入噪音,获得受损的输入数据,即

(1)


(2)


(3)
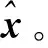
(4)
选取合适的梯度下降方法,就可以将降噪自动编码器训练完毕。通过降噪自动编码器自动学习到的隐式表示h代替手动选取的特征向量x,用作基分类器的输入。
1.3 数据集及特征选取
在僵尸网络检测任务中,数据集的选取往往尤为关键。有研究表明[21-22],一些公共的数据集中的确包含有僵尸网络的异常数据,但是由于数据集已经过时,包含的异常数据并未反映当前僵尸网络的行为。所以我们选用了Garcia等人最近发布的CTU-13数据集(CTU-13数据来自于https://www.stratosphereips.org/datasets-ctu13)用于实验。
该数据集是捷克理工大学从恶意软件捕获设施项目中收集的混杂着正常流量和背景流量的真实僵尸网络流量数据。CTU-13包含了13种不同的网络场景。在每个场景中都执行了一个特定的恶意软件,恶意软件使用多种协议并执行不同的行为,例如端口扫描,DDoS等等。实验选取了13个场景中僵尸网络流量数据最多的场景9、10,即CTU-13-9和CTU-13-10。数据集中每一条网络流量数据对应的特征信息统计如表1。有关数据集大小的具体信息如表2。

表1 网络流量数据相关特征统计
表1一共包含了9项特征。分别为协议、持续时间、方向、总流量包数、主机字节数、总字节数、状态、主机IP地址和端口号。其中,协议、方向和状态为离散特征,所以对其进行独热编码表示,维度分别为12、6、166。最终每一条网络流量数据特征总维度达到188。由于网络流量数据中IP地址及端口号在真实的网络世界里很容易被伪造,所以在实验过程中未被选用。
表2 CTU-13场景9和10数据相关特征统计
Table 2 CTU-13 scene 9 and 10 data related feature statistics

场景僵尸流量样本数正常流量样本数总样本数CTU-13-9184 987190 000374 987CTU-13-10106 352110 000216 352
2 对比实验
2.1 实验设置
降噪自动编码器中编码器的两层隐藏层神经元个数分别为128和64。编码器的输出层,即网络流量数据的隐式表示维度设置为32。于是,解码器中输入层的维度为32,两层隐藏层的维度分别为64和128。而解码器的输出层维度与编码器输入层维度相同,即为处理前的特征向量维度。神经网络层中的激活函数选取的是ReLU,该激活函数在提供了非线性变换的基础上能够帮助模型快速收敛,因此在应用深度学习技术的众多领域被广泛采用。在降噪自动编码器训练过程中,所选用的优化函数为Adam,该函数是当前最为流行的优化函数,在帮助模型快速收敛的同时,还能防止模型陷入局部最优。优化函数中的学习率设置为0.001。由于用于训练的数据集规模较大,为了加速训练,我们将批大小设置为512,训练轮次设置为5。训练用于提取网络流量潜在特征的降噪自动编码器的损失函数选用的是交叉熵函数。
实验阶段,对于基于集成学习的分类器,我们将其中的基分类器数量设置为100,并且将其中的决策树深度设置为20。
2.2 评价标准
实验选用了准确率、精确率(AC)、召回率(R)、F值(F)四项评价标准来评价检测模型的性能。以上四项评价标准由真正例(TP),真反例(TN),假正例(FP)和假反例(FN)所定义。真正例及真反例表示的是模型预测出的结果同实际样例类别一致的数量。相反,假正例及假反例则反映了模型预测结果不同于样例实际类别的数量。以下列出了四项评价标准的具体公式:
准确率用于表示模型预测出正确的结果与总样本数的比值:
AC=(TP+TN)/(TP+TN+FP+FN)。
(5)
精确率用于表示模型预测出的正例中真正例的占比:
P=TP/(TP+FP)。
(6)
召回率用于表示模型所预测出的真正例占实际样本中正例的比值:
R=TP/(TP+FN)。
(7)
F值综合了准确率和召回率,更加直观展示模型的好坏:
F=2PR/(P+R)。
(8)
2.3 实验结果分析
实验中使用的基学习器为逻辑回归、决策树、朴素贝叶斯、K近邻、AdaBoost和随机森林。实验结果数据如表3和表4,图3直观地展现了不同基分类器下基于降噪自动编码器的僵尸网络检测模型的准确率和F值。

表3 CTU-13-9分类器的比较结果
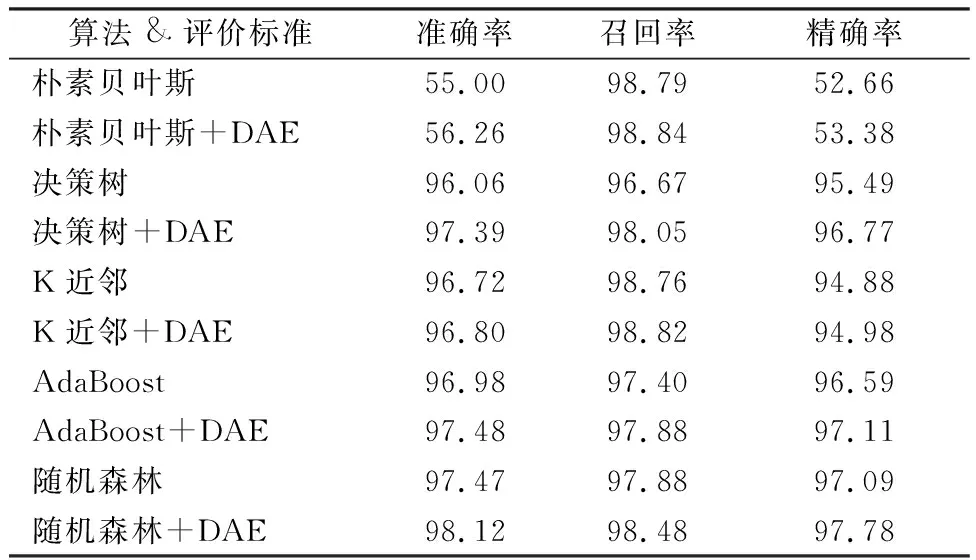
表4 CTU-13-10分类器的比较结果

图3 不同场景下准确率和F值对比Figure 3 Comparison of accuracy and F value in different scenarios
从图3中可以看出,无论在哪个数据集下,使用了降噪自动编码器提取原始网络流量特征的分类器F值要高于直接对原始网络流量数据进行分类的分类器。值得注意的是,随机森林算法加上降噪自动编码器的僵尸网络检测模型在实验中获得了最高的F值。并且,在CTU-13-10数据集中,决策树加降噪自动编码器模型F值要高于原始基于集成学习的AdaBoost模型。同样,AdaBoost加降噪自动编码器模型F值要高于原始的随机森林模型。
在准确率方面,可以看出结合降噪自动编码器的模型准确率方面普遍高于原始模型。随机森林加降噪自动编码器模型的准确率在不同数据集下提升平均1个百分点。
综上所述,基于降噪自动编码器的僵尸网络检测模型具备自动提取隐式特征向量,并帮助基学习器提升僵尸网络检测效果的能力。
2.4 不同隐式维度对模型的影响
本章研究降噪自动编码器隐式特征向量的不同维度对模型的影响。编码器的隐藏层大小固定为128和64,解码器的隐藏层则镜像设置。将隐式维度依次设置为4,8,16,32,进行对比试验,实验结果如图4。

图4 不同隐式维度对模型的影响Figure 4 Impact of different implicit dimensions on the model
从图4中可以看出,对于有着不同基学习器的基于降噪自动编码器僵尸网络检测模型来说,随着隐式维度的不断增加,模型对僵尸网络检测的效果在逐步提升。当隐式维度为4时,维度过于低而导致不足以表达原始网络流量潜在信息,并且几乎所有模型的准确率和F值都要低于不加降噪自动编码器的原始模型。而随着隐式维度增加到8,各模型的准确率和F值接近原始模型。而当隐式维度增加到16和32,各个模型的评价指标趋于稳定,并且表现已经优于原始模型。于是,隐式维度的大小能影响降噪自动编码器对原始网络流量特征的表示效果。在本模型中,我们将隐式维度大小设置为32,就能获得理想的结果。
3 结 论
本文将深度学习技术应用于僵尸网络检测领域,提出了基于降噪自动编码器的僵尸网络检测模型。该模型利用降噪自动编码器自动有效地提取了网络流量数据中包含的高级隐式特征,能够更好捕捉当前僵尸网络的异常行为。并在最近提出的CTU-13数据集下的不同场景中进行了大量的实验。实验结果表明,我们提出的模型能够从原始网络流量数据中自动地提取相关特征,不同程度上提升了传统基于手动特征工程的机器学习方法在僵尸网络检测领域的效果。
当然,本文还存在值得研究和改进的地方,具体如下。
对于本文提出的基于降噪自动编码器的僵尸网络检测模型,考虑到结合了深度学习方法,对训练数据的规模有一定的要求。针对小规模的数据集可能不足以在训练过程中使模型成功收敛,导致模型达不到预期精度。同时,选取合适的基学习器也会影响模型精度。接下来的工作是尝试将深度学习模型用于基学习器,再结合降噪自动编码器实现基于深度学习的僵尸网络检测模型。
