基于多类别的镉稻米近红外光谱识别分析
2019-08-12朱向荣李高阳谢运河
朱向荣 李高阳 江 靖 谢运河 单 杨 *
(1湖南省农业科学院 湖南省农产品加工研究所 长沙 410125
2湖南大学研究生院隆平分院 长沙 410125
3湖南省土壤肥料研究所 长沙 410125)
水稻是全球重要的粮食作物,然而由于水稻自身拥有的某些独特基因,使水稻米粒吸收土壤中某些重金属,特别是吸镉能力明显强于玉米、大豆等其它作物品种。水稻镉污染对稻米生产、加工及质量安全构成了潜在威胁。目前,原子吸收光谱法[1]、原子荧光法[2]及电感耦合等离子体质谱法[3]等分析方法常用于稻米中镉含量的测定。这些方法准确性好、灵敏度高,然而存在着仪器设备昂贵、样品前处理繁杂以及环境不友好等缺点。近红外 (near infrared spectroscopy,NIR) 光谱具有快速、高效、环保等优点,在稻米的营养品质检测中均有应用[4-7]。无机元素在近红外光谱区并没有吸收,而蛋白质、淀粉、纤维素与半纤维素等有机物质与无机元素结合,形成的络合物和螯合物能够在NIR光谱区反映出来[8-9],这为NIR光谱检测镉稻米提供理论依据。国内外学者采用NIR光谱对动物源食品[10-12]、植物源食品[13-16]、农作物[17-19]以及水样[20-22]中的重金属元素进行定性、定量分析,而对镉污染稻米鲜有研究报道。稻米待检的Cd含量低,特征变量较难识别。作者在前期研究中,采用NIR光谱结合变量筛选方法对镉稻米进行二分类识别[23]、定量检测[24],取得满意的效果。
镉超标稻米中虽有镉超标较严重的稻米,但更多的是镉轻微超标稻米。后者镉含量超过现有国家标准0.2 mg/kg,普遍低于0.4 mg/kg。镉污染稻米可以通过淀粉提取工艺优化,提取到的淀粉中镉含量显著下降[25]。本文将镉污染稻米分为4类:合格稻米(小于 0.2 mg/kg),轻度污染(0.2~0.4 mg/kg),中度污染(0.4~1.0 mg/kg)以及重度污染(大于1.0 mg/kg)。首先采用主成分分析法(partial component analysis,PCA)对光谱进行解析,然后采用偏最小二乘识别分析 (partial least squares discriminant analysis,PLS-DA)、 径向基人工神经网络 (radical basis function-artificial neural network,RBF-ANN) 及支持向量机 (support vector machine,SVM)3种多分类模式识别算法进行识别分析,系统研究不同的光谱预处理方法对模型的影响,同时比较不同方法的建模效果差异,为稻米食用安全以及镉污染稻米加工利用奠定基础。
1 材料与方法
1.1 样本收集
2014年10月在湖南省湘潭、娄底、衡阳等地采集281个稻米样本,均为晚籼稻谷。所有样品在85℃烘干4 h,冷却至常温,用砻谷机脱壳,用粉碎机粉碎至40目,备用。
1.2 仪器与试剂
Nicolet AntarisⅡ傅里叶变换近红外光谱仪,配有积分球漫反射采样系统与铟镓砷(In-GaAs)检测器,Omnic7.3光谱采集软件,TQ Analyst v6.2.1分析软件,美国热电尼高力公司;Agilent 7700X电感耦合等离子体质谱仪,美国安捷伦科技有限公司;JLG-1砻谷机,国家粮食储备局成都粮食储藏科学研究所;,FW80高速万能粉碎机,天津泰斯特有限公司;SY-2恒温沙浴锅,江苏金坛市成辉仪器厂;BSA124S分析天平,赛多利斯北京科学仪器有限公司;实验用硝酸为优级纯,西陇化工有限公司;镉标准贮备液(1 000 mg/L)与大米粉中镉成分分析标准物质(GBW08511)(0.504 mg/L),国家标准物质中心提供。实验用水为18 MΩ去离子水,美国Millipore超纯水系统。其它试剂均为分析纯级。
1.3 试验方法
1.3.1 样品前处理 采用GB/T 5009/15-2003《食品中镉的测定》方法测定。准确称量0.5 g样品,置250 mL锥形瓶中,加入20 mL硝酸,加盖浸泡过夜。采用沙浴加热进行消化,加热至锥形瓶中的溶液澄清停止加热。冷却后,用去离子水溶解并定容25 mL容量瓶中,待上机。每批均采用含镉稻米标准物质进行质控,并以空白样品(仅试剂)消除背景。试验用玻璃器皿包括容量瓶、移液管、烧杯等均用(1+4)硝酸浸泡24 h,然后依次用自来水、蒸馏水、超纯水冲洗3次,烘干备用。
1.3.2 电感耦合等离子体质谱测定条件 仪器工作条件:高频发射功率1 500 W,蠕动泵0.1 rps,载气流量1.05 L/min,辅助器流量0.36 L/min,雾化室温度2℃,溶液提升比1.0 mL/min,等离子体气体15 L/min,采样深度8 mm,扫描方式为跳峰,每点积分时间0.3 s,重复测量2次。电感耦合等离子体质谱仪经调谐使仪器处于最佳状态,依次测定元素标准溶液,方法空白和稻米消解待测液,仪器自动绘制标准曲线,计算待测液中Cd元素的含量。
1.3.3 近红外光谱方法 近红外光谱扫描采用漫反射检测系统,NIR光谱扫描波数范围10 000~4 000 cm-1,优化光谱扫描条件,确定扫描次数32次,分辨率8 cm-1,增益2。内置背景为参照。每次试验前先扫描背景光谱,所有扫描得到的谱图都是扣除背景光谱后的样本NIR纯光谱。每批样品做3次平行试验,取其平均光谱,以消除样品不均匀性带来的干扰。
1.3.4 数据处理软件 所有程序均在Matlab7.1软件(Mathwork Inc.)实现,SVM算法由台湾大学林智仁(Lin Chin-Jen)提供“LibSVM”改编。 此外还使用classification_toolbox_3.0工具箱 (下载网址:www.disat.unimib.it/chm)进行分类模式识别,人工神经网络工具包由MATLAB7.1软件自带。其它程序为本实验室自行编制。
2 结果与分析
2.1 NIR光谱分析
图1为样本的近红外光谱图,记录了10 000~4 000 cm-1波数样本的NIR光谱曲线。所有样本的NIR光谱无明显差异,肉眼很难辨别,必须采用化学计量学方法进行数据预处理和建立模型。
2.2 样本集划分
采用Kennard Stone(KS)法从281个样本挑选出211个样本作为校正集,其余的70个样本作为预测集。图2为采用PCA法样本的主成分得分图,可以看出,校正集样本(“o”形)在主成分上分布均匀,预测集样本被包括在校正集样本(“*”形)的分布空间中,这使得校正集样本的光谱信息包括预测集样品的光谱信息。通过上述划分,能够提高鉴别模型的泛化能力。然而,样本的NIR光谱差异太小,PCA得分图重叠严重,很难采用PCA对不同污染程度的镉稻米进行区分。
表1列出4类样品在校正集与预测集中的分配情况。数据集211个样品被分配成4类,其中合格(qualified)样品所占比例较高,达到 146/281×100%=69%,轻度污染(lightly polluted)样品所占比例为64/281×100%=22.7%,中度污染(moderate-ly polluted) 所占比例为51/281×100%=18.1%,重度污染(severely polluted)较少,所占比例为 24/281×100%=8.8%。
图1 样本的近红外光谱图Fig.1 The near infrared spectra of representative samples
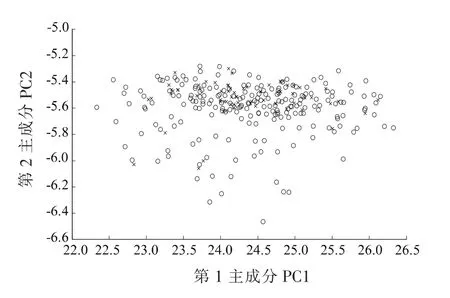
图2 样本的第1主成分与第2主成分分布图Fig.2 Distribution of PC1 and PC2 for the samples

表1 样本集中4类样本的划分情况Table1 The partition of four classes in data set
2.3 光谱预处理优化
采集的NIR原始光谱分别经过无处理(none)、范围归一化(range scaling)、均值中心化(mean centering)、自归一化(autoscaling)、多元散射校正(MSC)、一阶导数(D1)及其组合共11种预处理方法,如表2所示。以交叉验证准确率为指标,最终确定最优的预处理autoscaling方法。
2.4 PLS-DA模型的建立
采用PLS-DA建立稻米镉4种类别的分类模型。采用十折法(10-fold)交叉验证,确定了最佳的潜变量数为8。模型的校正集鉴别准确率为80.1%,模型的预测集鉴别准确率为77.1%。采用特异度(1-specificity)和灵敏度(sensitivity)为评价指标,对模型进行评价。图3左为4类样本的ROC曲线图,其中,第1类样本(图3左-a)与第4类样本(图3左-d)的ROC曲线下面积最大,识别率较高;第2类样本的ROC曲线下面积(图3左-b)最小,识别率最低。图2右为4类样本的阈值变化图,由于分配给每个样本分类阈值 (the class threshold)的灵敏度与特异度是发生变化的,在灵敏度线与特异度线交叉时,此时的假阳性与假阴性最小,分类阈值就可以确定[26]。以分类准确率最高的第4类样本为例(图3右-d),其分类阈值为0.05,而高于0.05的阈值都可以划分镉重度污染稻米。
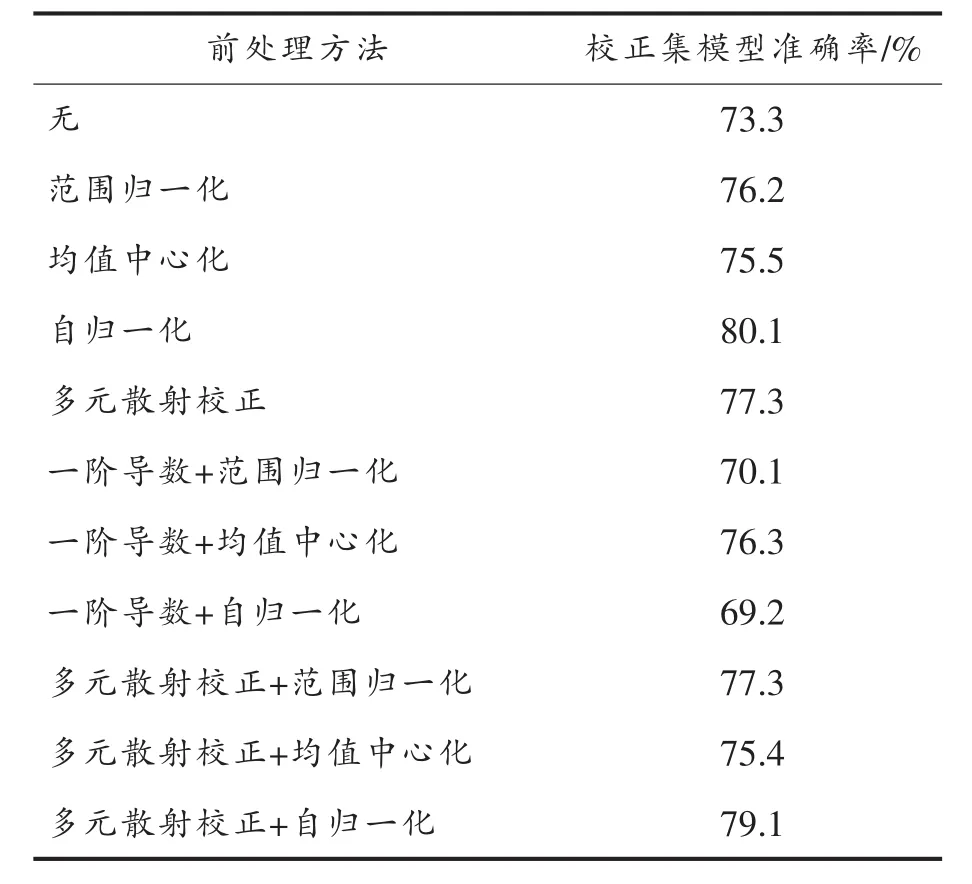
表2 PLS-DA模型光谱预处理优化Table2 The optimization of spectral pretreatment of PLS-DA models
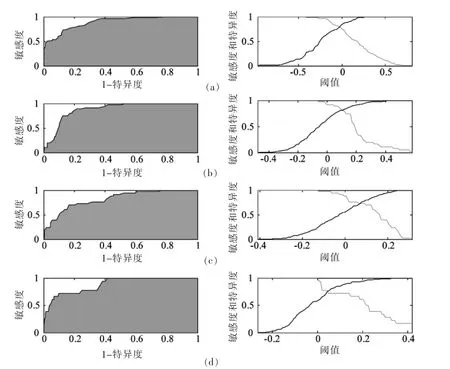
图3 4类样本的ROC曲线图(左)及阈值变化图(右)Fig.3 ROC curves (left) and plots of the class threshold change (right) for four classes
2.5 SVM模型的建立
采用RBF核时,要对惩罚参数cost(C)与径向核函数gamma(γ)这两个最重要参数进行选择[27-28]。本文采用SVM中的径向基核函数,利用五折交叉验证法(five-fold cross validation)进行交叉验证[29]。通过Python3.5软件自动参数优化,采用Gnuplot5.0软件画出等高线图。SVM校正模型的参数优化得到的径向基系数γ=0.036,惩罚参数C=256,交叉验证准确率为71.1%。对预测集进行验证,预测准确率为67.2%。
2.6 RBF-ANN模型的建立
在RBF-ANN网络训练中,如预定的最大神经元个数比指定的样本数量小很多,那么ANN达不到给定的误差,模型精度就会降低;而最大神经元个数又不能太大,如太大会导致模型输出结果错误[30]。本文将最大神经元个数设为其样本数211个,不会对运算造成负担。采用newrb函数对散布常数(spread)进行优化。采用多输出 RBF神经网络,将归一后的NIR光谱变量作为4类不同稻米镉样本的输出,其中(1001)为合格稻米,(0100)为轻度镉污染稻米,(0010)为中度镉污染稻米,(00 01)为重度镉污染稻米。通过优化确定,最佳的spread常数为3.5时,预测集的识别率最高,预测集中70个样本有48个预测正确,22个预测错误,正确识别率为68.5%。
2.7 建模方法的比较
表3比较了3种建模方法的鉴别正确率差异,其中PLS-DA的分类结果最好,优于SVM与RBF-ANN,校正集与预测集的鉴别准确率分别达到80.1%与77.1%。这是由于PLS-DA是基于PLS回归的模式识别方法,将NIR光谱数据与样本属性进行回归后,通过建立判定函数更容易得到精度更高的预测集鉴别结果。而在多分类SVM中,通过核函数构建可分的稻米镉多分类超平面非常困难,导致分类结果较差;训练样本的数量严重影响训练的速度与支持向量的数量,导致SVM模型的泛化能力下降。由于样本的NIR光谱数据特征并不具有完全的代表性和典型性,不能完全表征每类样本的属性状态,因此,样本的质量能够在很大程度上影响RBF-ANN的识别精度,导致RBF-ANN也难获得最优解。
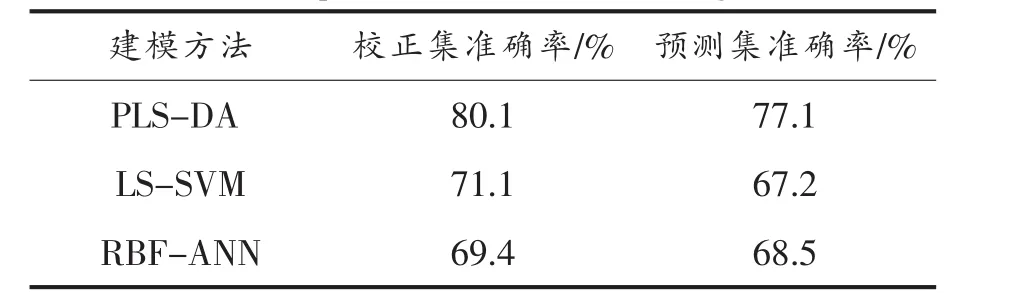
表3 3种建模方法的比较Table3 Comparisons of three modeling methods
3 结论
1)采用傅里叶变换近红外光谱结合模式识别分析方法,初步实现了不同污染程度的稻米多分类识别。
2)3种建模方法中,PLS-DA法建立的模型性能最优,预测集准确率为77.1%。对比3种判别分析方法,PLS-DA是最为经典、常用的线性判别方法。ANN与SVM均为非线性判别分析方法,这两种分析方法对于非线性数据来说,通常可取得较好的判别结果,而对于本研究中复杂的多分类数据却没有取得最优解,说明在特定的研究对象下,选择合适的建模方法尤为重要。
3)将扩大样品量,提高模型的稳健性与准确性。
本研究结果为近红外光谱技术在不同镉污染程度的稻米样品类型快速识别上提供试验依据。
