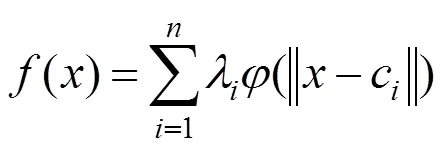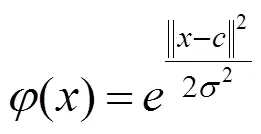面向虚拟化身的人脸表情模拟技术
2019-08-08姚世明李维浩李蔚清苏智勇
姚世明,李维浩,李蔚清,苏智勇
面向虚拟化身的人脸表情模拟技术
姚世明1,李维浩1,李蔚清2,苏智勇1
(1. 南京理工大学自动化学院,江苏 南京 210094;2.南京理工大学计算机科学与工程学院,江苏 南京 210094)
为了实现基于增强现实的电子沙盘环境中的异地可视化交互功能,提出了一种面向虚拟化身的三维表情模拟技术。首先,使用RGB摄像头跟踪异地作业人员的表情,基于约束局部模型(CLM)提取人脸特征点数据后传输到本地;然后,采用基于径向基函数的插值算法计算虚拟化身面部网格点的坐标,驱动模型模拟出与异地作业人员相同的表情;最后,为了提高变形算法的精度和效率,提出一种基于贪心算法与人脸肌群分布的插值控制点选取和分区域插值方法。实验结果表明,该算法能够满足实际应用对实时性和真实感的需求。
表情模拟;径向基函数;形变模型;肌肉模型
电子沙盘是一种虚拟化的信息显示手段,可以模拟三维、动态、可交互战场态势环境。基于增强现实(augmented reality, AR)的电子沙盘在态势展现的直观性、交互操作的便捷性以及协同研讨的高效性方面都优于传统的电子沙盘。在AR电子沙盘的异地协同研讨作业中引入虚拟化身技术,以虚拟人物的形式将身处异地的指挥员“投射”到同一环境,“面对面”进行沟通交流,大大提升了指挥人员交流的充分性和高效性。人与人交流中,人脸表情是最主要和最直观的表现形式,具有逼真表情的虚拟化身,使观看者更有沉浸感。
三维人脸表情模拟技术主要包括表情动画的跟踪和模型驱动2部分。从上世纪70年代PARKE[1]建立第一个脸部模型到现在,三维人脸表情动画跟踪技术已经较为成熟,但实现高实时性和高真实性的人脸动画重构技术仍是目前研究的难题。对于异地交互来说,表情模拟的实时性和真实感是重要指标,本文重点研究如何提高表情重构方法的效率和精度,从而满足应用所要求的实时性和真实感。
在人脸特征点跟踪领域,国内外研究人员提出了很多有效方法。WILLIAMS[2]提出在用户面部贴有反光特性的标记点来跟踪人脸特征点运动信息。此方法精度高,但用户体验差。何钦政和王运巧[3]采用Kinect实现三维人脸表情参数的捕捉。但其像素较低,要求拍摄距离较近。此外,目前研究较多是基于RGB视频的特征点检测方法。CRISTINACCE和COOTES[4]提出了基于CLM形状模型的特征点检测法。BULAT和TZIMITOPOULOS[5]采用基于卷积神经网络的深度学习方法实现了基于RGB视频的三维人脸特征点实时跟踪,由于训练数据的限制,检测精度不高。考虑到本文应用对表情模拟的实时性和真实感要求较高,且表情采集者处在小范围移动中。以上方法中,采用高像素RGB摄像头跟踪特征点的方案较为合理。
在基于数据驱动的表情重构技术领域,常见方法包括基于肌肉模型、基于表情基合成和基于形变算法等来实现表情动画。基于肌肉模型的方法虽真实感强,但实时性差。而基于表情基合成的方法存在个性化特征不明显的缺点。PIGHIN等[6]提出一种基于视频的人脸表情模拟技术,采集到特征点运动数据后,采用三维曲面插值算法驱动模型产生表情动画。目前常用的人脸模型变形的算法有拉普拉斯变形算法和径向基插值变形算法。拉普拉斯变形算法的效率高,局部细微表情的变形效果差[7]。径向基插值变形算法的平滑性好,但应用于复杂拓扑结构的人脸曲面时会出现局部失真现象,并且计算量较大[8]。SUWAJANAKORN等[9]提出了基于语音数据的表情重构方法。GUO等[10]使用基于卷积神经网络的深度学习方法实现了利用单张图片对人脸实时重构。但是该方法需要大量工作去建立带三维特征点数据的数据库,且对硬件性能要求较高。综上分析,实现高实时性和高逼真度的人脸动画重构仍然是一项具有挑战性的工作。
经过对以上方法的对比分析,结合应用背景,本文提出基于单目RGB视频驱动的人脸表情模拟技术。首先基于约束局部模型CLM 跟踪人脸特征点的运动信息;然后采用基于径向基函数(radial-basis function,RBF)的变形算法驱动人脸网格模型来输出表情动画;并基于人脸肌肉模型和贪心算法对RBF插值变形算法的效率和精度进行了优化,提出了基于人脸肌群分布的分区域插值算法和插值控制点选取算法,实现了AR电子沙盘环境中面向虚拟化身的表情模拟功能。
1 系统框架
本系统用于AR电子沙盘异地可视化交互中虚拟化身的表情模拟,主要实现跟踪和重构人脸的表情动画。系统总流程如图1所示:第1部分为数据预处理。读取并记录人脸网格模型顶点的索引和坐标,选取插值控制点并与模型对应网格点绑定,计算并保存各控制点与其他网格顶点的欧氏距离;第2部分为特征点的运动跟踪。基于CLM形状模型在RGB摄像头采集的视频图像中搜索定位出特征点坐标;第3部分为插值出所有人脸网格模型顶点坐标。用检测到的插值控制点坐标训练插值函数,插值出网格模型中除控制点以外的面部顶点坐标;第4部分为模型的驱动。插值的结果传递给模型驱动脚本,驱动模型产生形变来输出表情动画。

图1 系统总体流程
2 基于CLM模型的人脸特征点跟踪
本文采用基于CLM形状模型的特征点检测方法,主要工作包括模型的训练和特征点定位,具体流程如图2所示。特征点检测工作一定程度上建立在SARAGIH等[11]工作的基础上,采用了其训练好的CLM形状模型。特征点定位包括人脸区域定位和特征点搜索定位2部分。采用经典的VIOLA和JONES[12]人脸检测器检测出图像中的人脸区域,以此缩小后续的特征点搜索范围;然后基于CLM形状模型对人脸区域中的特征点进行拟合定位;最后采用mean-shift算法[13]跟踪人脸特征点的运动数据。
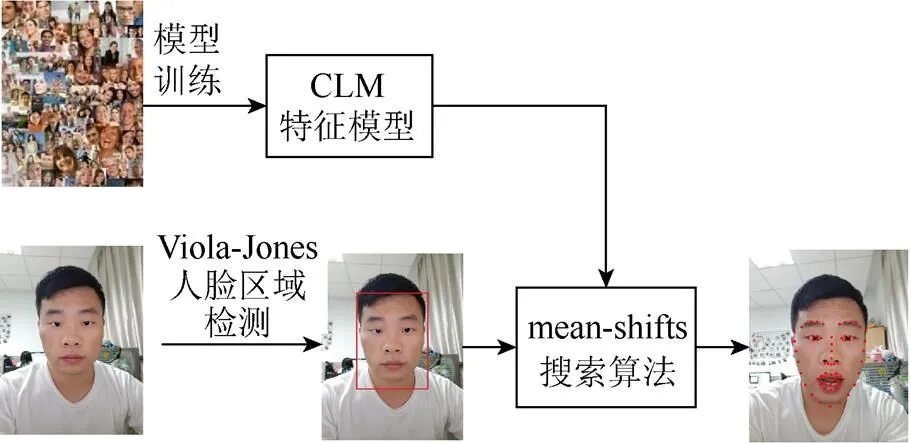
图2 人脸特征点运动的跟踪过程
3 基于RBF插值的变形算法
如何利用检测到的少数特征点运动信息驱动具有大量网格点的人脸模型是本文主要解决的问题。本文选用RBF插值算法驱动模型形变产生表情动画,插值控制点从检测到的人脸特征点中选取,训练出人脸曲面插值函数,然后根据前一帧的模型顶点坐标插值出当前帧的顶点坐标数据,生成平滑的人脸表情动画。
3.1 RBF插值函数介绍
RBF[14]是一种3层的前向神经网络,包括输入层、隐含层和输出层。RBF的基本思想:以核函数构成隐含层空间,并对输入数据进行变换,将低维非线性数据变换到高维空间,使其在高维空间线性可分。RBF具有结构简单、学习收敛速度快、能够逼近任意非线性函数、有效克服局部极小值问题等优点。RBF插值函数的数学表示为