基于感知哈希和视觉词袋模型的图像检索方法
2019-08-08杨文娟王文明王全玉汪俊杰
杨文娟,王文明,王全玉,汪俊杰
基于感知哈希和视觉词袋模型的图像检索方法
杨文娟,王文明,王全玉,汪俊杰
(北京理工大学计算机学院,北京 100081)
针对移动增强现实中图像检索技术耗时长导致的实时性不高的问题,提出了一种基于感知哈希和视觉词袋模型结合的图像检索方法。图像检索过程中,在保证一定正确率的基础上加快了检索速度。首先,对数据集图像使用改进的感知哈希技术处理,选取与查询相似的图像集合,达到筛选图像数据集的作用;然后,对相似图像集使用视觉词袋模型进行图像检索,选取和查询图像中目标一致的目标图像。实验结果表明,该方法相比较视觉词袋模型算法检索的平均正确率提高了3.2%,检索时间缩短了102.9 ms,能够满足移动增强现实中图像检索的实时性要求,为移动增强现实系统提供了有利的条件。
图像检索;感知哈希技术;视觉词袋模型;特征点提取
增强现实技术的目标是增强用户对真实世界的感知[1],方式是通过3D模型或文字提示信息与用户所观察的真实环境进行融合。随着网络质量提升和移动智能终端处理能力增强,增强现实技术在移动智能终端的实现成为可能,促进了移动增强现实的发展。通过移动智能终端的摄像头获取查询图像,利用图像检索算法获取目标图像,进而加载相应的增强信息与真实场景进行虚实结合,最后输出显示到移动终端屏幕。图像检索是移动增强现实应用中的关键技术之一。
根据描述图像内容方式的不同,图像检索分为基于文本的图像检索和基于内容的图像检索。基于内容的图像检索重点是利用图像特征来进行检索。用户图像检索的过程是用户提供一个查询图像,首先获取查询图像的特征,接着与数据库中图像数据集的特征集合进行比较,最终将与查询图像相似的图像返回给用户[2]。常用的图像检索方法有视觉词袋模型(bag of visual words,BoVW)[3]、局部特征聚合描述符[4]以及Fisher向量[5]。BoVW算法[6]被广泛使用,该算法有离线训练和在线检索2个过程。离线训练需要完成训练图像集的码本训练和保存;在检索阶段,检索时间不会随着样本数目增加而发生大幅增长,但是其检索正确率相对较低[7]。针对小规模样本集的图像检索,在保证一定检索正确率的前提下需要找到一种耗时少且能满足实时性的图像检索方法。因此通过结合感知哈希算法( perceptual hash algorithm,PHA)和BoVW算法,本文提出了一种基于感知哈希和视觉词袋模型的图像检索方法。
PHA-BoVW方法包括2部分:①预处理,对训练集进行图像哈希技术处理,每张图像用哈希序列表示,通过查询图像与训练集图像的哈希序列计算相似度排序,筛选出相似图像集;②图像识别,对相似图像集提取特征点和计算描述子,并对图像特征点进行聚类构建词典,根据已建立的词典,对相似图像集的图像建立对应码本,通过查询图像的码本与相似图像集的码本之间汉明距离计算找到最小值,确定集合中的目标图像。
1 整体架构
随着移动智能终端的处理能力的增强,移动终端可以实现部分复杂的图像处理工作,于是本文采用图1的客户端/服务器(C/S)架构[8],在移动终端计算查询图像的特征点、哈希编码,上传特征点信息和哈希编码到服务器端,在服务器端进行图像检索,发挥移动终端的图像处理能力,能在服务器端实现快速图像检索。最终找到目标图像及其对应的增强信息,将增强信息返回客户端与查询图像融合展示给用户,实现移动增强现实应用。
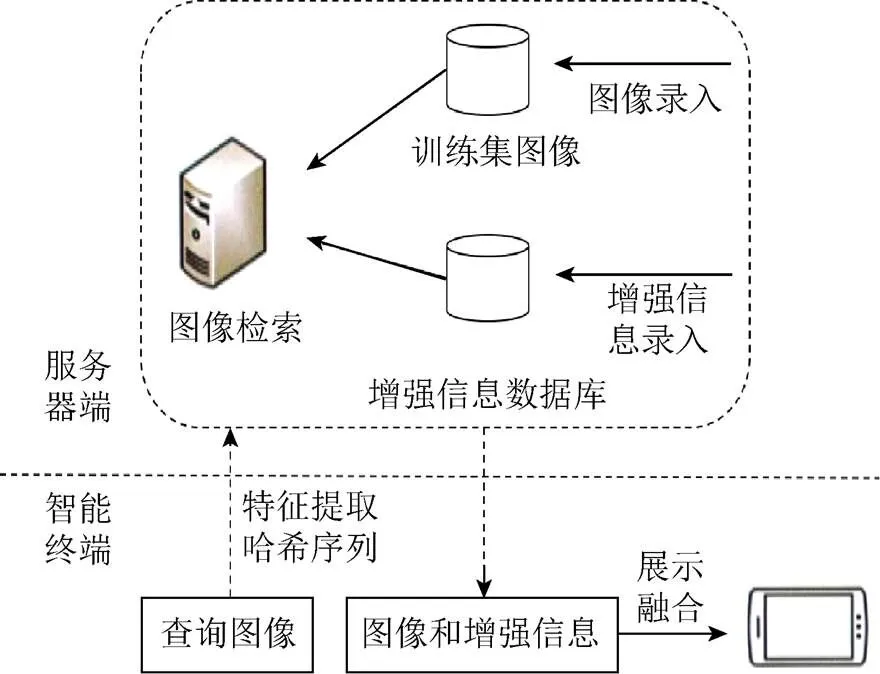
图1 C/S架构
2 算法介绍
2.1 感知哈希算法
任意分辨率的图像经过感知哈希技术处理,可用几十位或几百位的二进制序列表示一张图像,这个二进制序列称为哈希编码。哈希编码的二进制形式大大节省了内存空间,而且加快了检索速度,同时感知哈希技术简化了图像检索[9]。在检索阶段只需计算查询图像哈希编码,计算查询图像哈希编码与训练图像哈希编码之间的汉明距离,按距离排序并返回相似图像集[10],该过程如图2所示。此过程实现缩小检索范围的目的。
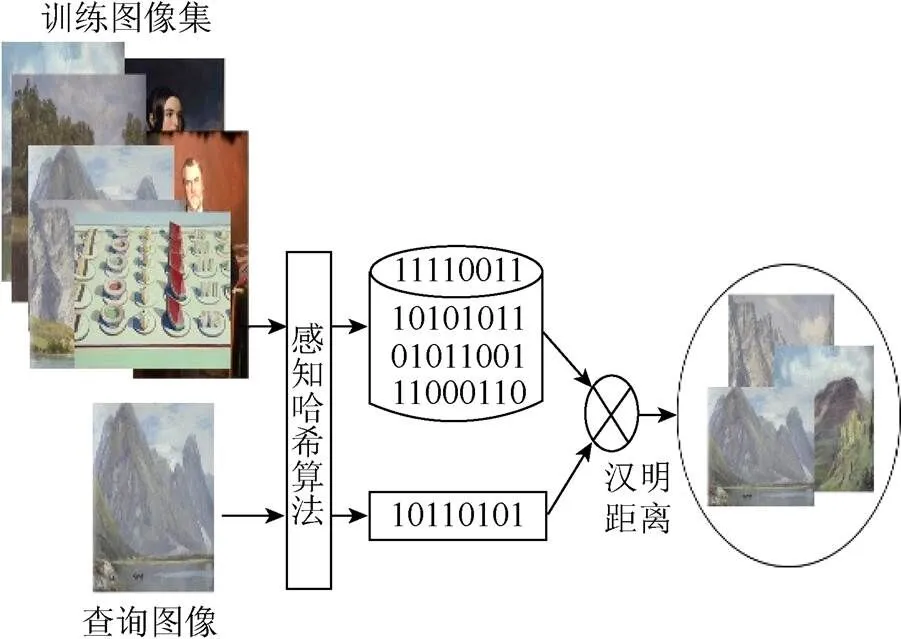
图2 图像感知哈希技术
图像感知哈希技术的步骤如下[11]:
步骤1.缩小尺寸。将图片统一缩小尺寸,变成×的像素。主要目的是快速去除高频、细节、不同尺寸和比例带来的差异,只保留结构明暗。
步骤2.简化色彩。将步骤1处理的图片转为×级灰度,也就是图像中包含最多×种颜色。
步骤3.计算平均值。计算×个像素的灰度平均值。
步骤4.比较像素的灰度。像素灰度平均值与所有像素点的灰度值依次比较作差。差值大于或等于0像素记为0;小于0记为1。
步骤5.计算哈希编码。将步骤4每个像素得到的结果组合,组成一个×位的二进制序列,也就是该图片的指纹。二进制序列的位置排序没有限制,但是所有图片应该采用一致的次序[12-13]。
2.2 视觉词袋模型
视觉词袋模型属于基于内容的图像检索中的算法,其实现主要依赖于图像特征提取和词典构建[14]。
视觉词袋模型算法的步骤如下[15-17]:
步骤1.特征提取。在训练阶段,将一个图像划分为“块” (patch)。其中选取特征提取算法是关键步骤,提取的每个图像关键点都是一个patch,每一个patch用128维特征向量表示[15]。
步骤2.词典构建。假设有幅训练图像,提取图像集合中全部的patch,用K-means++算法对patch集合进行聚类,当K-means++收敛时,得到类相当于词典中有个不同的单词,代表单词的数量,过程如图3所示。
步骤3.词典表示。首先设置一个维数、值全为0的直方图,代表词典中的单词量,计算查询图像所有patch与词典中各个单词的距离,根据距离排序大小,找到与每个patch距离最近的单词,在直方图上找到对应单词的坐标,对应计数上加1,所有patch计算完毕后进行归一化处理,得到的归一化的直方图,即图像的向量化,使得图像可用维向量表示。
步骤4.图像检索。训练图像同样使用维向量表示,对用户给出的查询图像,计算查询图向量与所有训练图向量之间距离,并返回距离值排序最小的若干幅。

图3 BOVW词典构建
特征提取是BoVW算法的关键步骤之一,在很大程度上决定了算法的性能[18]。选用4张1200×801的图像场景(图4),分别用尺度不变特征变换[19]、加速鲁棒特征[20]和ORB (oriented FAST and rotated BRIEF)算法[21]提取特征点,对比常用的3种特征提取算法(表1),ORB算法既保证了提取特征点的数量,又加快了提取速度,而且描述符占用空间小,因此本文选取ORB算法作为本文特征提取的算法。

图4 4张场景图例
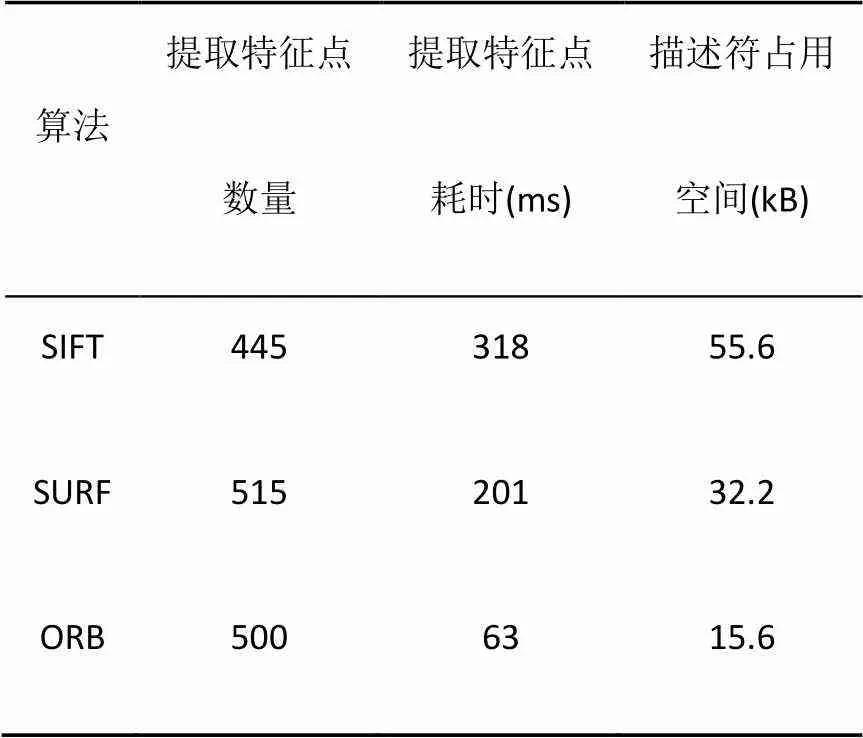
表1 3种特征提取算法对比
2.3 ORB算法
ORB特征是基于oFAST关键点检测和rBRIEF描述符提取2部分改进组成[22]。
2.3.1 oFAST
图像特征点检测:采用图像的尺寸金字塔,每层都需要提取FAST特征,完成特征点的多尺度不变性。Harris角点检测[22]方法是对所有特征点计算排序,取前个点为特征点。
灰度质心法定位:灰度质心法计算角点的灰度与质心之间的偏移向量,并将偏移量的方向设定为关键点的方向,该向量可用于定位[23]。在一个小的图像块中,定义图像块的矩为

通过矩可以找到图像块的质心[19],即

